Docker 安装FileBeat、Elasticsearch及Kibana详细步骤
一、ELK简介
二、docker安装Elasticsearch
2.1 创建Docker网络
2.2 拉取镜像
2.3 创建挂载目录
2.4 添加配置文件
2.5 创建es容器
2.6 测试Elasticsearch是否安装成功
三、docker安装Logstash
3.1 拉取镜像
3.2 创建挂载目录
3.3 添加配置文件
3.4 创建Logstash容器
四、安装 Filebeat
4.1 下载 filebeat
4.2 配置 filebeat.yml
4.3 启动 filebeat
4.4 效果展示
五、docker安装Kibana
5.1 拉取镜像
5.2 创建挂载目录
5.3 添加配置文件
5.4 创建kibana容器
5.5 验证 Kibana 是否安装成功
5.6 查看索引管理
5.7 创建数据视图
一、ELK简介
Elastic Stack(也称为 ELK Stack)是公认的日志监测领域的领导者,拥有业界最广泛、最全面的系列日志数据源,是备受欢迎的免费开放日志平台。官网地址为:Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Kibana:数据的探索、可视化和分析 | Elastic
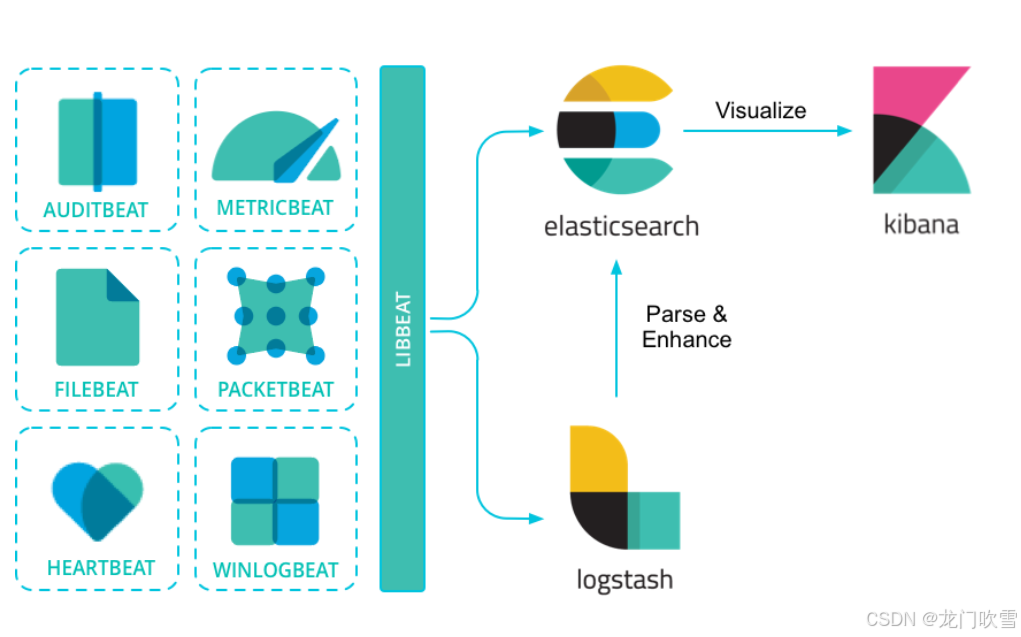
ELK Stack是软件集合Elasticsearch、Logstash、Kibana的简称,用于对日志文件数据进行抽取、分析、存储、展示的日志引擎。
- Elasticsearch:
支持全文索引的分布式存储和索引引擎,用于存储从Logstash或Beats接收到的数据
- Logstash:
日志分析工具,用来对日志数据进行分析和过滤,将处理后的数据发送给Elasticsearch
- Kibana:
可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业务方
- Beats:
通过配置文件指定数据源和输出目标,然后定期从数据源采集数据,并将数据发送到Logstash或Elasticsearch。 Beats比Logstash更轻量、性能更高,常用工具包括:FileBeat、Metricbeat、Packetbeat等
ELK框架如下:
二、docker安装Elasticsearch
官网安装说明:
Install Elasticsearch with Docker | Elasticsearch Guide [8.15] | Elastic
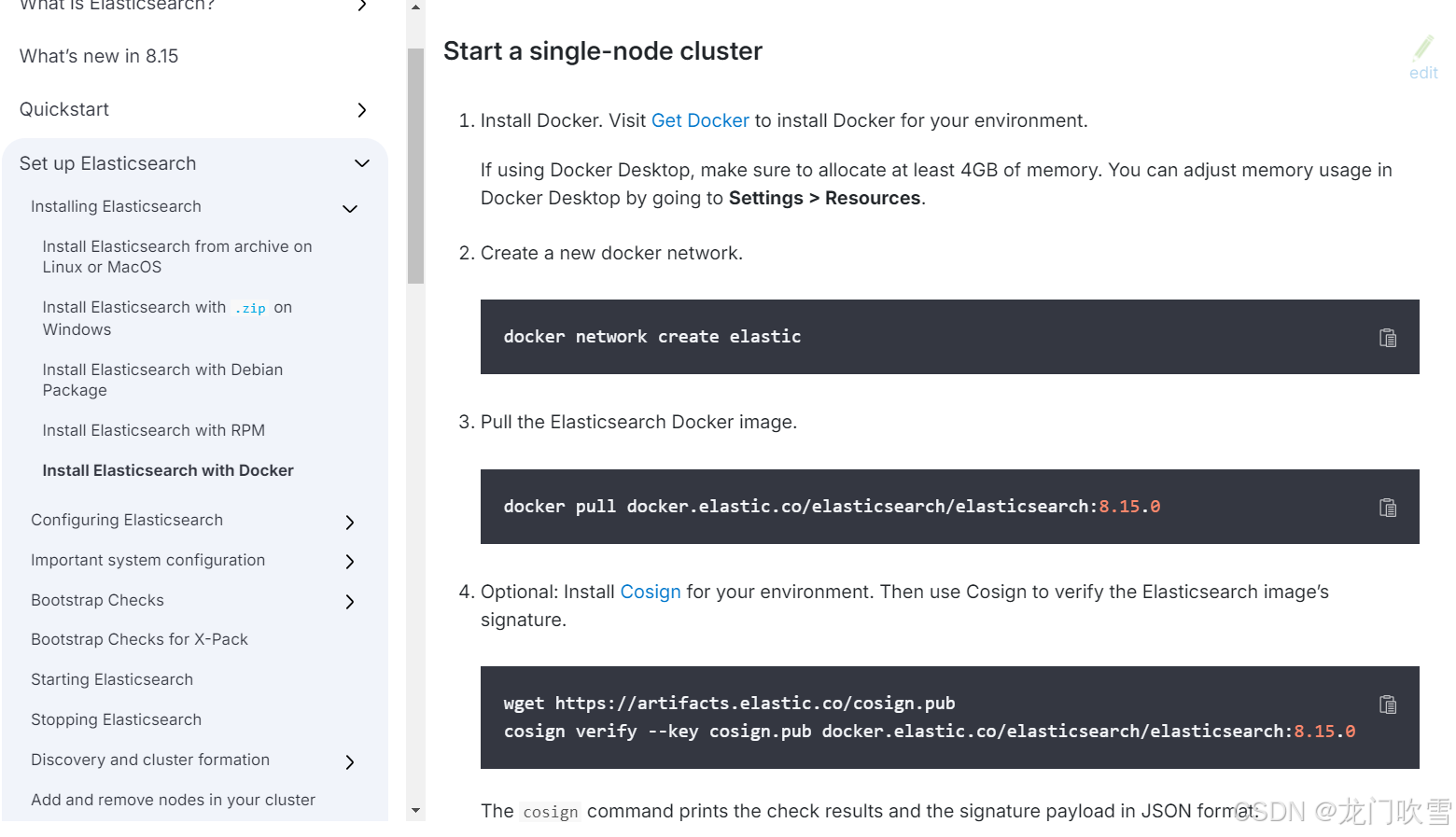
注意:首先看官网安装步骤及说明。我之前在docker中直接拉取的 elasticsearch 镜像,安装后容器总是在重启中,可能是环境配置项与elasticsearch版本不符(发现是5年前创建的版本)。最后拉取最新的8.15.0版本才解决,所以首先根据官网说明操作,避免无谓的踩坑!
2.1 创建Docker网络
需要Elasticsearch与Kinaba容器互联,因此首先创建网络,以便能直接通过容器名相互访问:
docker network create elk_net2.2 拉取镜像
在Elasticsearch官网中查找最新版本,以目前的8.15.0版本为例:
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.15.0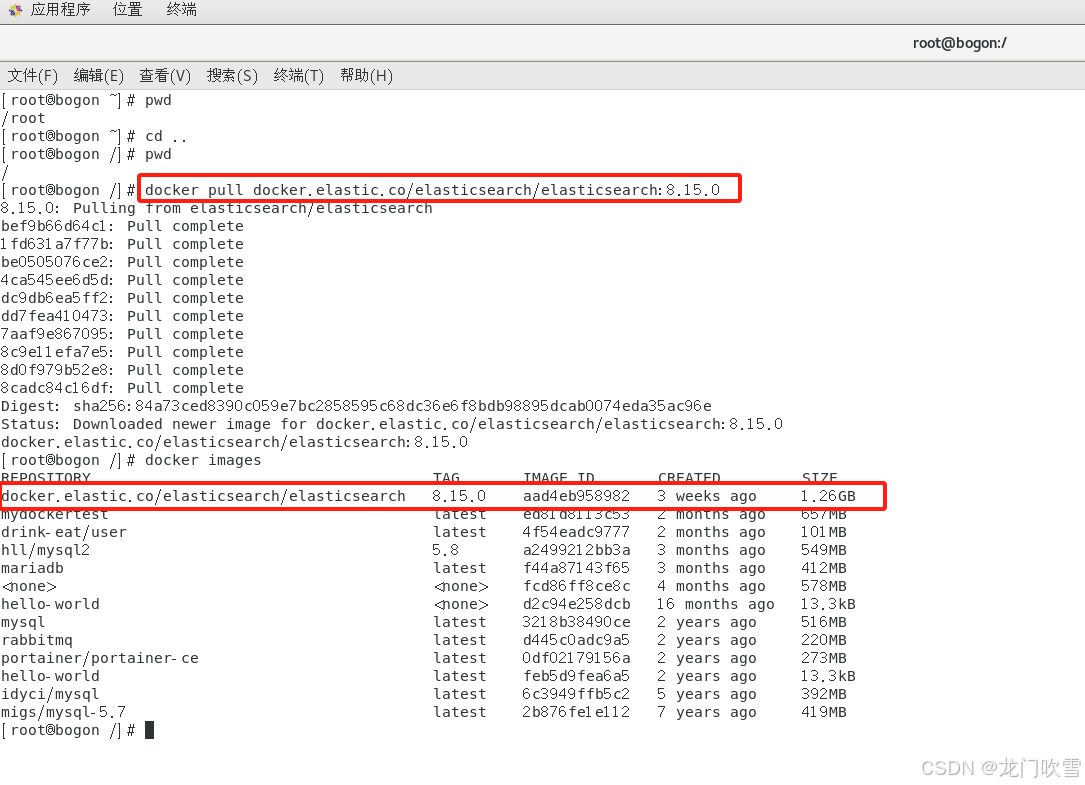
2.3 创建挂载目录
# 新增宿主机目录,用于保存es配置文件及数据
mkdir -p /usr/local/es/data /usr/local/es/config /usr/local/es/plugins
# 增加读写权限
chmod 777 /usr/local/es/data
chmod 777 /usr/local/es/config
chmod 777 /usr/local/es/plugins2.4 添加配置文件
新建elasticsearch.yml文件
vim /usr/local/es/config/elasticsearch.yml在编辑框中输入以下配置内容,然后按esc键退出编辑模式,输入:wq保存并退出
cluster.name: "elastic" # es集群名称
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
#开启密码校验,若开启就必须要设置密码
xpack.security.enabled: false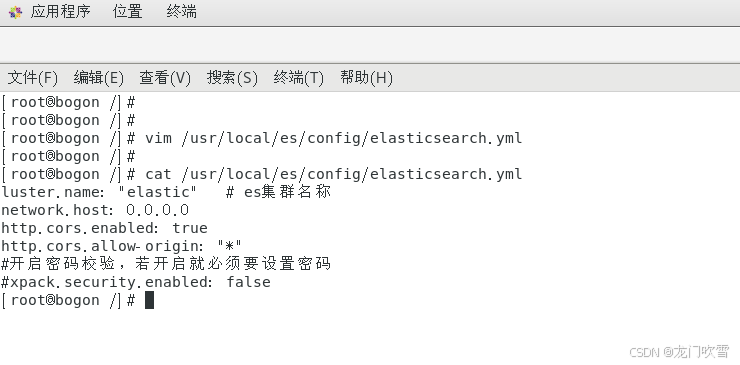
2.5 创建es容器
docker run --name es -p 9200:9200 -p 9300:9300 \
--network elk_net \
--restart=always \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
--privileged \
-v /usr/local/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/es/data:/usr/share/elasticsearch/data \
-v /usr/local/es/plugins:/usr/share/elasticsearch/plugins \
-d docker.elastic.co/elasticsearch/elasticsearch:8.15.0上述命令的解释:
docker run -d:设置容器后台运行
--name es:给es容器取的名字
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置堆内存大小,这里是因为我的虚拟机内存总共只有2G,所以设置的比较小,你自己设置不要低于这个内存大小,否则会出现内存溢出的报错
-e "discovery.type=single-node":设置的启动模式为非集群模式
-v /usr/local/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml: 挂载数据卷,绑定es的配置目录
-v /usr/local/es/data:/usr/share/elasticsearch/data:挂载数据卷,绑定es的数据目录
-v /usr/local/es/plugins:/usr/share/elasticsearch/plugins:挂载数据卷,绑定es的插件目录
--privileged:授予数据卷访问权
--network elk_net:加入elk_net的网络中,就是我们刚刚创建的,如果你不是这个名字根据你的实际情况去修改
-p 9200:9200:端口映射,9200暴露的是用户访问的http端口
-p 9300:9300:端口映射,9300暴露的是es各个节点互联的端口,这个端口我们单点模式现在用不到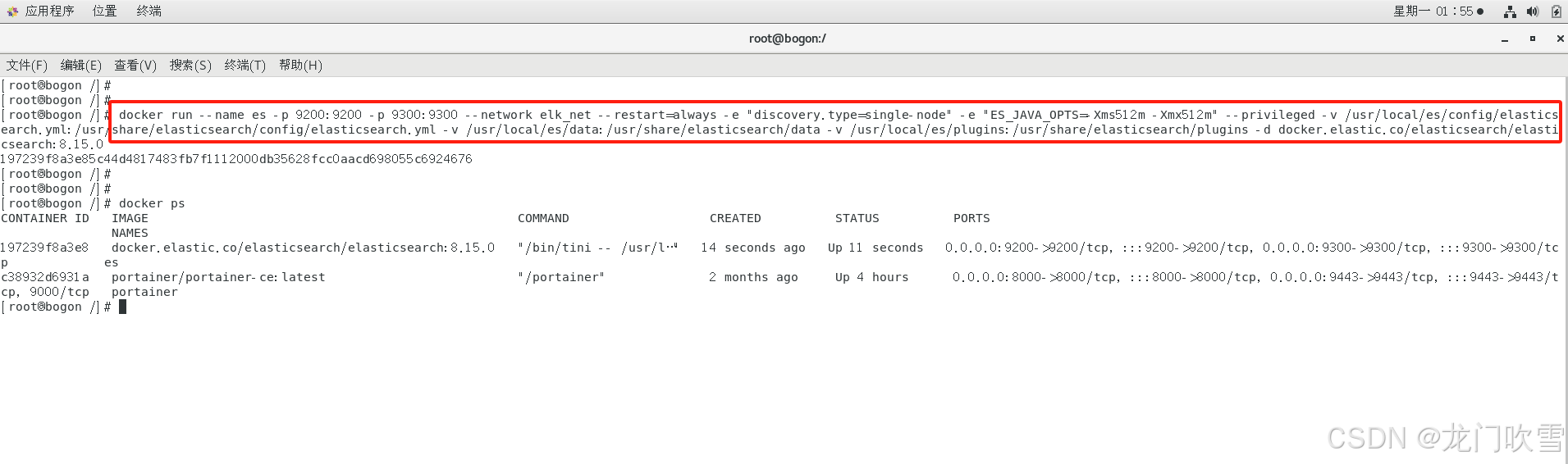
2.6 测试Elasticsearch是否安装成功
在浏览器中输入宿主机IP及端口9200(第5步中映射的elasticsearch端口),返回如下内容,表示安装成功。
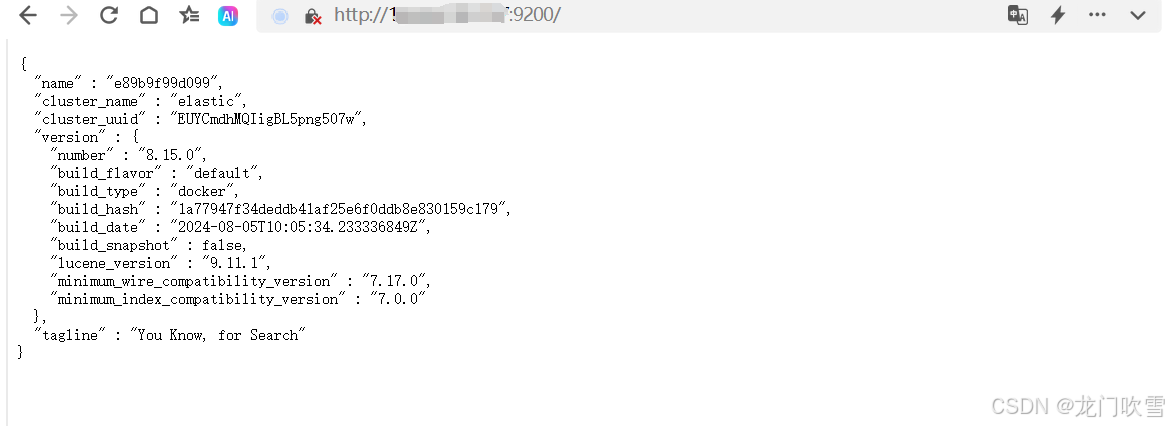
注意:如果是在阿里云上部署,需要将9200、9300等端口添加到安全组
三、docker安装Logstash
3.1 拉取镜像
docker pull docker.elastic.co/logstash/logstash:8.15.03.2 创建挂载目录
# 新增宿主机目录,用于保存es配置文件及数据
mkdir -p /usr/local/logstash/data /usr/local/logstash/config
# 增加读写权限
chmod 777 /usr/local/logstash/data
chmod 777 /usr/local/logstash/config3.3 添加配置文件
①logstash.yml:设置logstash运行参数等
vim /usr/local/logstash/config/logstash.yml在文件logstash.yml编辑框中输入以下配置内容,然后按esc键退出编辑模式,输入:wq保存并退出
node.name: "logstash001" #节点名称
http.host: "0.0.0.0"
xpack.monitoring.enabled: false #设置禁用X-Pack监视功能
②pipelines.yml:用于指定在一个logstash中运行多个管道的配置文件,在启动logstash时他会自动加载 pipelines.yml 中指定的path.config下的所有的管道配置文件conf合并成一个整体的配置文件
vim /usr/local/logstash/config/pipelines.yml在文件pipelines.yml编辑框中输入以下配置内容,然后按esc键退出编辑模式,输入:wq保存并退出
# This file is where you define your pipelines. You can define multiple.
#For more information on multiple pipelines,see the documentation:https://ww.elastic.co/guide/en/logstash/current/multiple-pipelines.html
#可以在这个配置文件中定义多个管道,用于从多个数据源中获取信息
- pipeline.id: pipeline001 #管道id
path.config: "/usr/local/logstash/config/*"
③pipeline001.conf:配置管道的输入及输出
vim /usr/local/logstash/config/pipeline001.conf在文件pipeline001.conf编辑框中输入以下配置内容,然后按esc键退出编辑模式,输入:wq保存并退出
#获取/usr/share/logs/*下的文件输出到es中
input {
file {
path => ['/nginxproxymanager/data/logs/*']
type => "nginx-log"
}
}
filter{
#json{
#将message作为解析json的字段
#source =>"message
#}
}
output{
if [type] == "nginx-log"{
elasticsearch {
hosts => ["es:9200"]
inde x=> "nginx-log-%{+YYYY-MM-dd}"
user => "root"
password => "123456"
}
}
}
3.4 创建Logstash容器
docker run -d --privileged=true \
--restart=always \
--name=logstash \
--network elk_net \
-p 5047:5047 -p 9600:9600 \
-v /usr/local/logstash/config:/usr/share/logstash/config \
-v /usr/local/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /usr/local/logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml \
-v /nginxproxymanager/data/logs:/usr/share/logs \
docker.elastic.co/logstash/logstash:8.15.0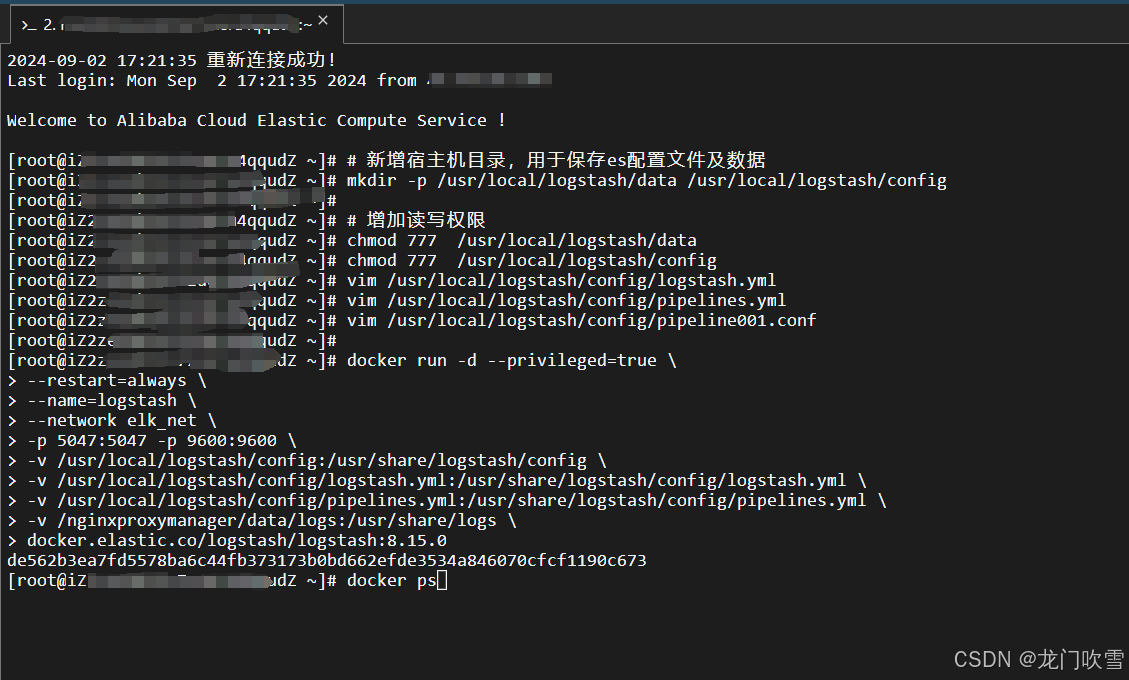
四、安装 Filebeat
官网安装指南:
Filebeat quick start: installation and configuration | Filebeat Reference [8.15] | Elastic
4.1 下载 filebeat
首先以在windows下安装为例,
①点击下载 filebeat-8.15.0-windows-x86_64.zip,注意下载与 elasticsearch 对应的版本
②解压到 C:\Program Files\filebeat 文件夹
③进行到window命令窗口,并执行下面的命令
> cd 'C:\Program Files\Filebeat'
> .\install-service-filebeat.ps1
linux环境下安装:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.15.0-linux-x86_64.tar.gz
tar xzvf filebeat-8.15.0-linux-x86_64.tar.gz
4.2 配置 filebeat.yml
在filebeat根目录下打开filebeat.yml,按如下步骤配置:
①配置Filebeat inputs
filebeat.inputs:
- type: filestream #输入类型,包括log、filestream等
id: my-filestream-id
enabled: true #默认false,需要写为true
paths: # 采集日志的目录,可以添加多个
- D:\HLLPos25\log\*
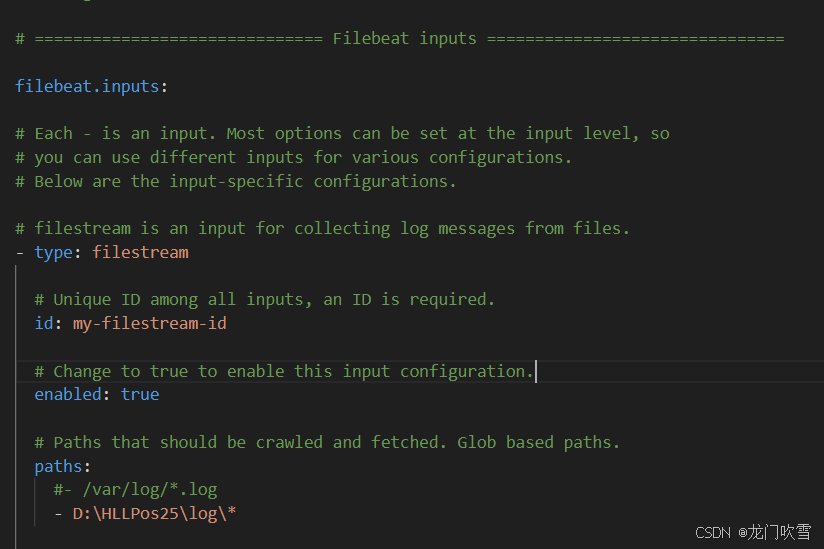
日志内容示例:
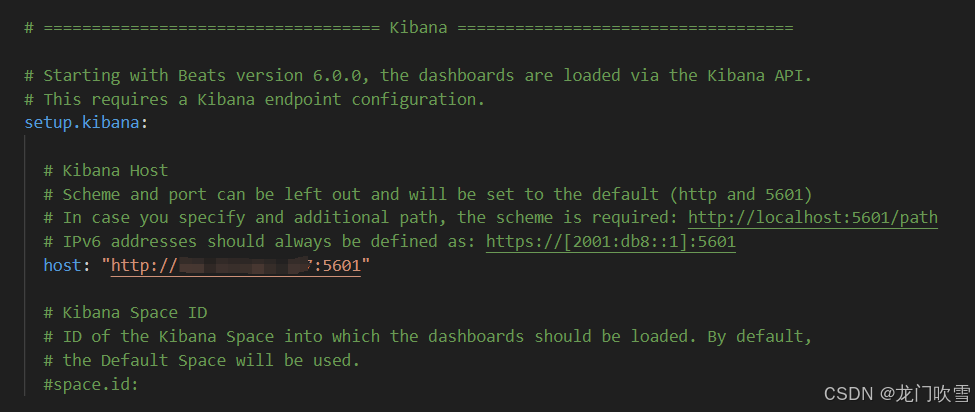
②配置Kibana
配置kibana地址(需先按第五大步骤安装好kibana),以便日志可视化。
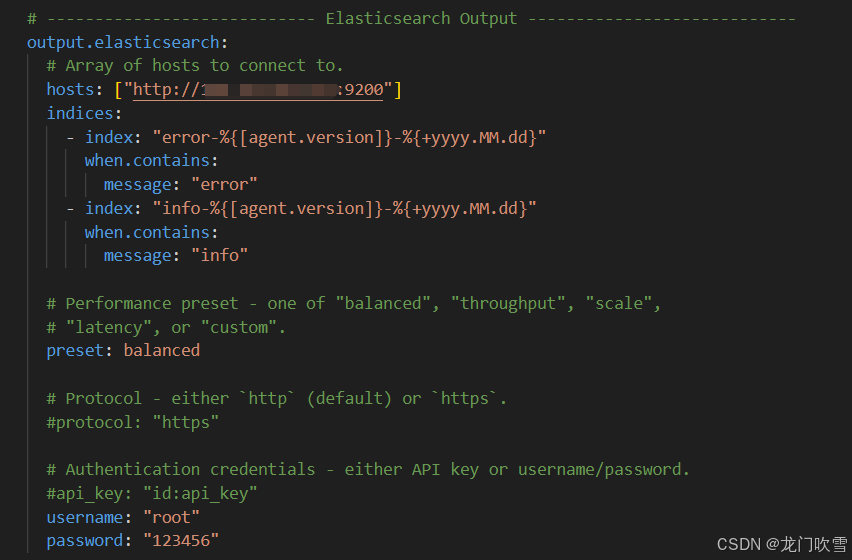
③配置Outputs
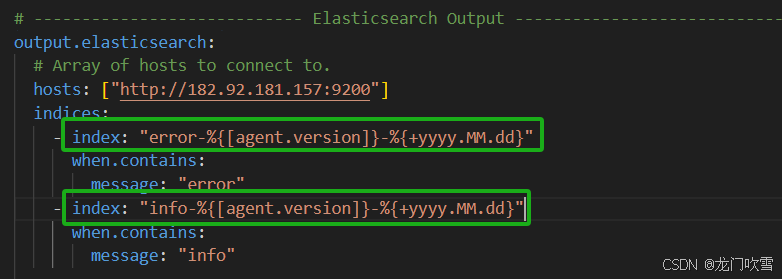
配置filebeat采集的日志的输出路径,可输入到:elasticsearc、logstash、kafka、redis等。以输出到 elasticsearch 为例:
output.elasticsearch:
hosts: ["http://182.92.181.157:9200"] #elasticsearch服务地址
indices: #索引列表,如果不添加索引,则默认计入形如filebeat-8.15.0-2024.09.03索引中
# 日志内容中含有 error 字符串的日志都被划分到error-8.15.0-2024.09.03 索引中
- index: "error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "error"
- index: "info-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "info"
4.3 启动 filebeat
windows命令窗口中运行(注意在filebeat根目录下):
.\filebeat -c filebeat.yml -e
或者将 filebeat 安装为window服务,当监控的日志目录下日志发生变化时,filebeat将采集日志上传到elasticsearch等
linux下启动:
./filebeat setup -e
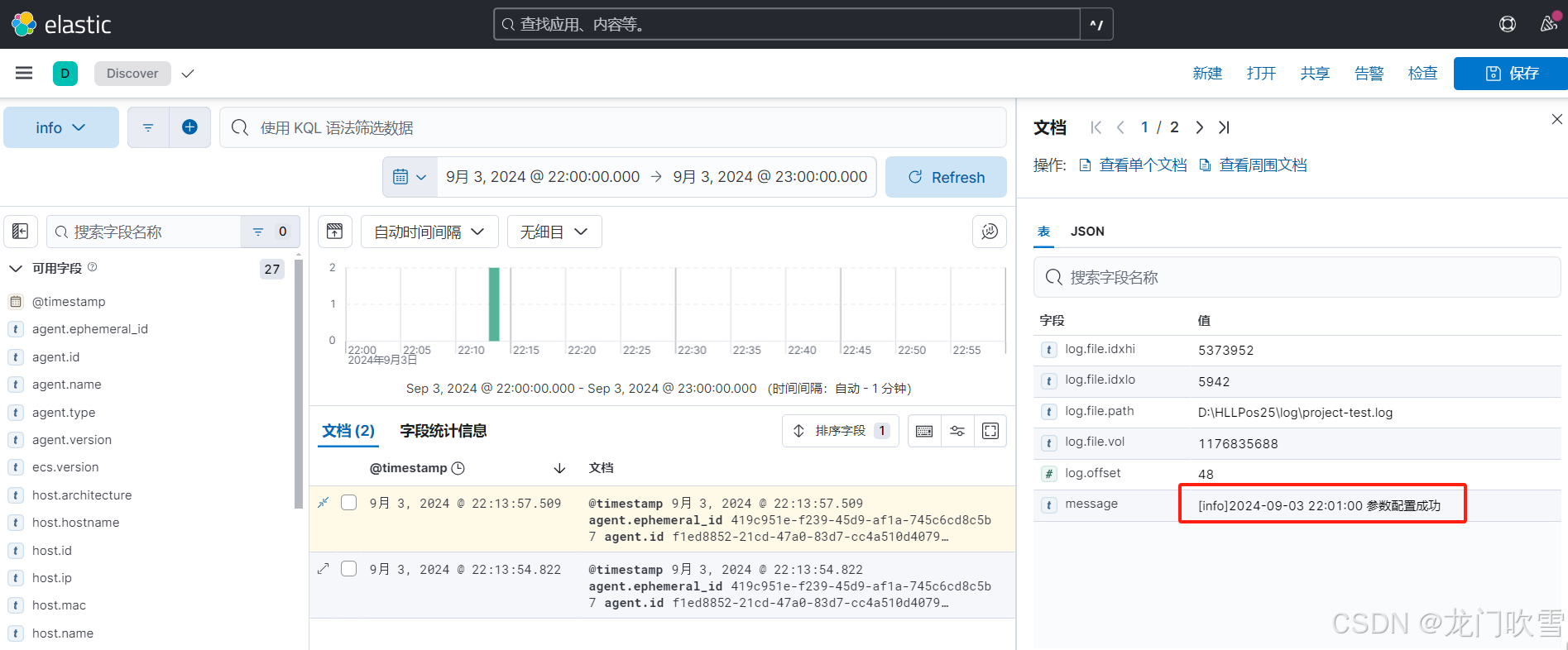
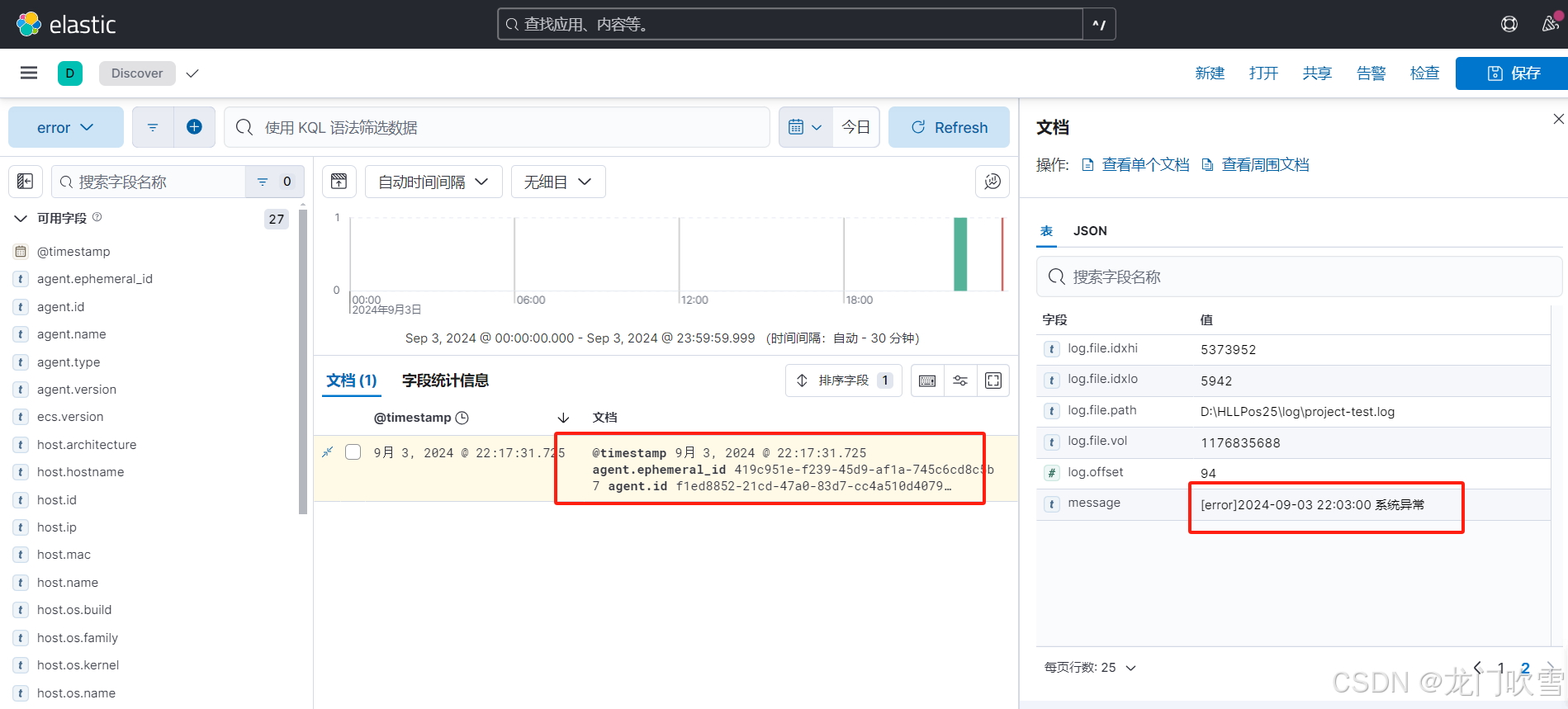
4.4 效果展示
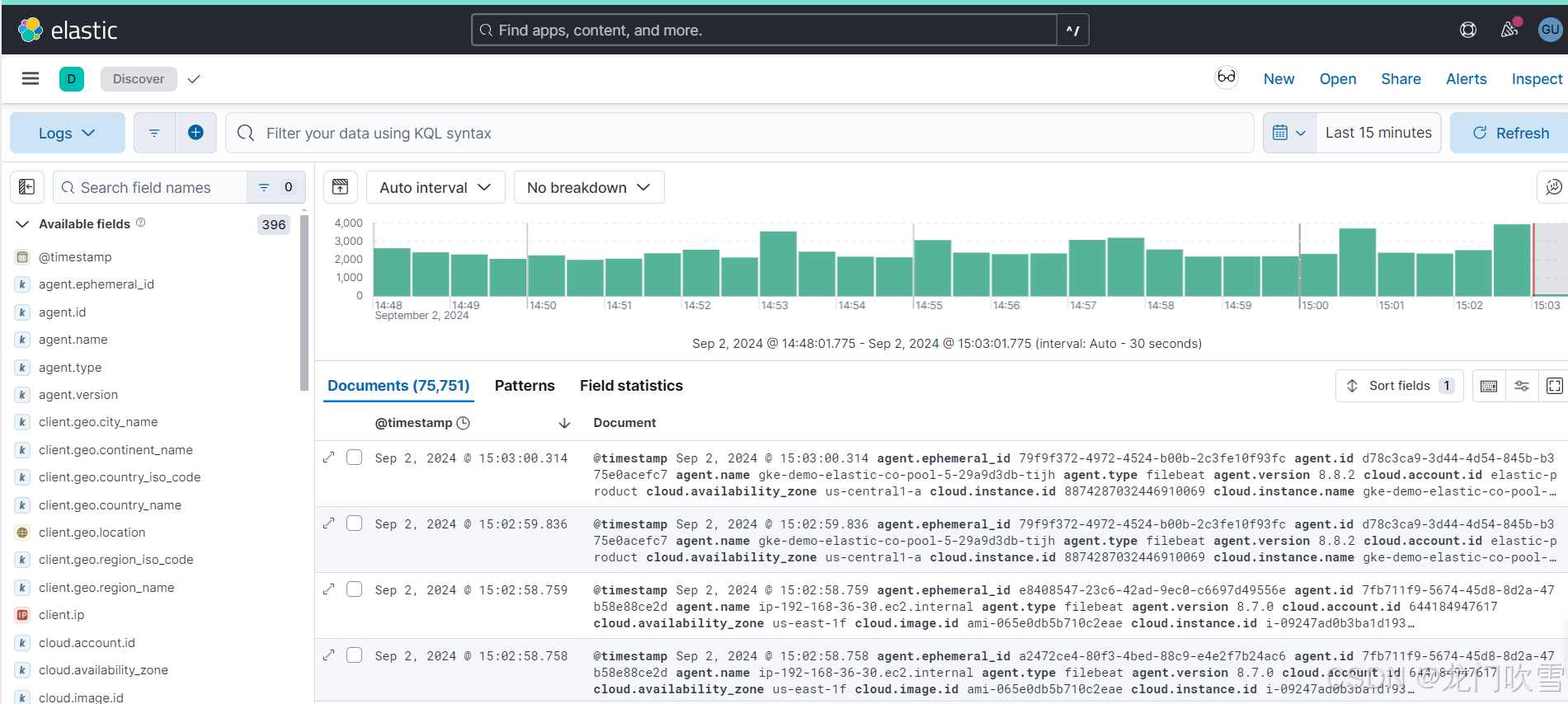
在kibana中查询日志(具体操作见5.6),如下图显示:
五、docker安装Kibana
5.1 拉取镜像
docker pull docker.elastic.co/kibana/kibana:8.15.05.2 创建挂载目录
mkdir -p /usr/local/kibana/config /usr/local/kibana/data
chmod 777 /usr/local/kibana/data
chmod 777 /usr/local/kibana/config5.3 添加配置文件
vim /usr/local/kibana/config/kibana.yml在文件kibana.yml编辑框中输入以下配置内容,然后按esc键退出编辑模式,输入:wq保存并退出
server.name: kibana
server.host: "0.0.0.0"
xpack.monitoring.ui.container.elasticsearch.enabled: true
elasticsearch.hosts: ["http://es:9200"] #elasticsearch服务地址
elasticsearch.username: "root"
elasticsearch.password: "123456"
elasticsearch.requestTimeout: 50000
i18n.locale: "zh-CN" #中文ui界面
5.4 创建kibana容器
docker run -d \
--restart=always \
--name kibana \
--network elk_net \
-p 5601:5601 \
--privileged \
-v /usr/local/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
docker.elastic.co/kibana/kibana:8.15.0其中 e ELASTICSEARCH_HOSTS=http://es:9200 表示Kibana的数据来源为http://es:9200,即在第二步中安装的容器名为 es(es和kibana设置了相同的network网络,所以可以通过容器名相互访问) 的 Elasticsearch。

5.5 验证 Kibana 是否安装成功
在浏览器中输入docker容器宿主机IP及Kibana默认端口5601,用户名为root,密码为123456,出现如下内容表示安装成功:
注意:
1、如果是在阿里云上部署,需要将5601等端口添加到安全组
2、kibana.yml配置文件中增加 i18n.locale: "zh-CN" ,会显示为中文界面,否则默认为英文界面
5.6 查看索引管理
进入Kibana的管理->数据->索引管理,可查看到如下索引列表:
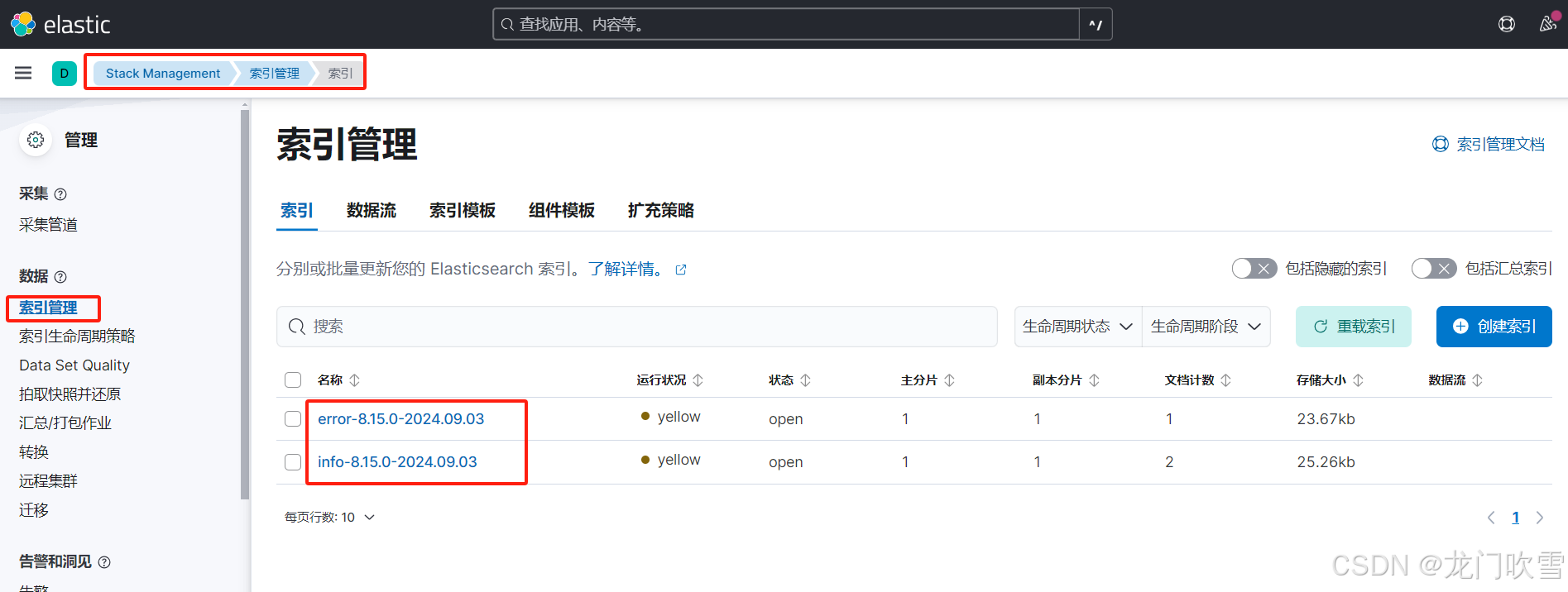
这是因为在4.2步骤中配置了output 索引,当含有info、error的日志内容通过filebeat上传后,在kibana索引管理中可查看到对应的索引;如果没配置output索引,这里默认出现 filebeat-8.15.0-2024.09.03 索引。
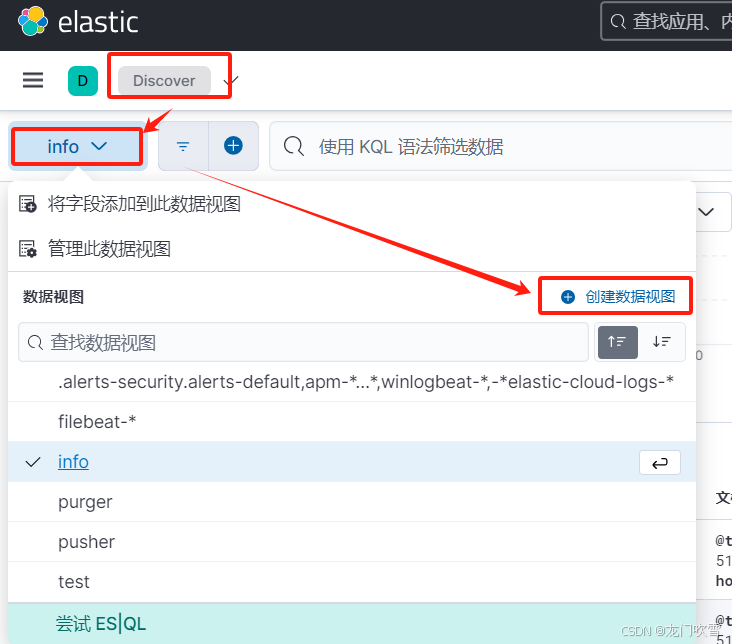
5.7 创建数据视图
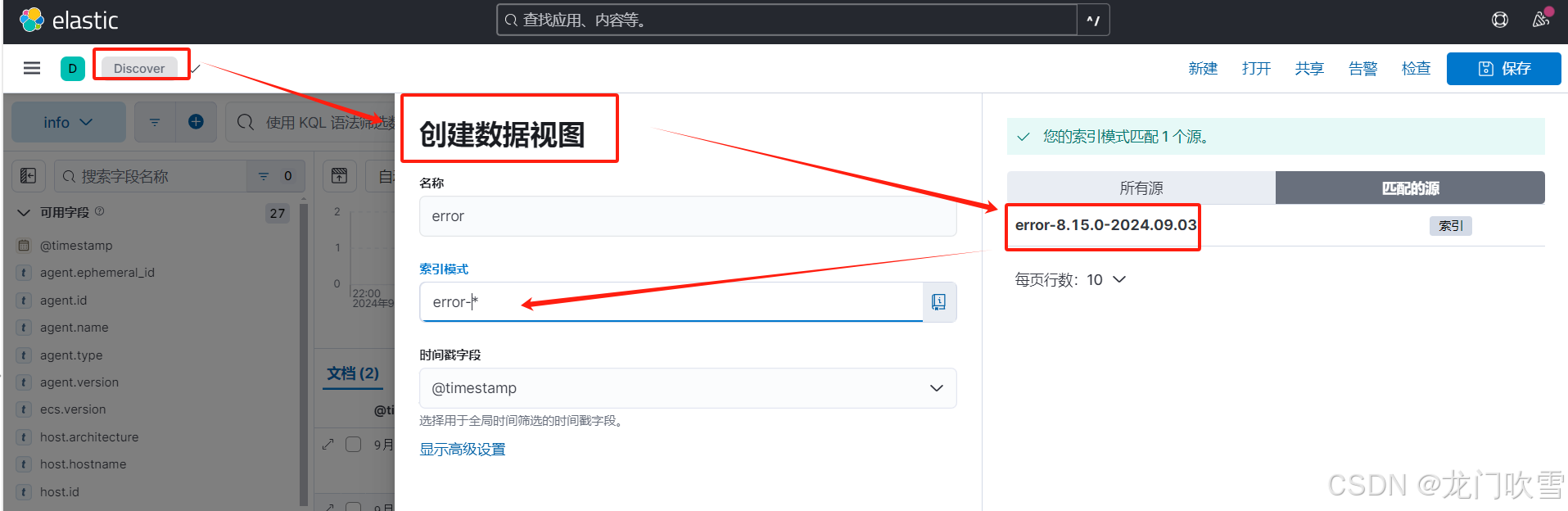
kibana查询日志需要先创建数据视图,匹配上一步中的索引,步骤如下:
Discovery->创建数据视图->保存视图:
总结:本文总只配置了 ELK Stack 中的基本功能,Filebeat 输出到kafka、redis等功能还未进行探索,有时间或项目需求时再根据官网进行研究。