微调语言模型前,需要考虑这三个关键方面
:随着大语言模型 (LLM) 的迅速发展,越来越多团队希望针对特定领域进行模型微调。但是实践运用中总是存在一些困难,直接应用并不总是能达到理想效果。
本文着重探讨了三个关键问题:
- 利用强大模型 (如 ChatGPT) 的输出结果来微调较弱模型是否有效?
- 如何选择是采用低成本的上下文学习还是对模型进行微调?
- 如何处理超过模型上下文限制的长文本,让模型理解并回答关于长文本的复杂问题?
此篇文章探讨了构建特定垂直领域语言模型时需要考虑的关键因素,能够帮助读者在微调大语言模型时做出明智的决策。我们衷心期望本次内容分享能帮助更多团队高效地获得所需的垂直领域大模型。
以下是译文,enjoy!
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

目前,市场正处于 LLMs(大语言模型)和生成式人工智能的风口上。IBM 的一项数据显示,将近三分之二的企业高管感受到了来自投资者的压力 —— 要求他们加快使用生成式人工智能。自然而然,这种压力也传导到了数据科学和机器学习团队,他们肩负着抓住机遇、成功应用生成式 AI 的重任。
随着形势的发展,LLMs 的生态系统迅速分化为开源和商业化两种模式,“护城河” 正被迅速填平。这一前所未有的局面促使许多团队思考一个问题:我们如何使 LLM 更贴近我们的具体需求?
在本文中,我们细致探讨了构建一款特定垂直领域的 LLM 所需考虑的一些关键因素,包括投入时间和工程周期等,这些因素我们应该牢记在心。在这一过程中,必须了解最新的相关研究,特别是针对微调大语言模型的潜在局限性和最佳实践方面的研究。阅读完本文后,您将掌握更多的决策思路,从而引导公司做出正确的决定:训练还是不训练,以及如何训练。
01 可能无法通过开源模型来模仿 GPT
众所周知,OpenAI 凭借其最新版本的 GPT 在 LLM 领域处于领先地位。因此,出于各种原因(速率限制、数据隐私、成本等),许多利益相关方可能会要求开发团队开发部署比 GPT 效果更好的模型。这自然而然地使开发人员产生疑问:我们能否从 GPT 中生成输出结果,并利用它们对模型进行微调?
对于这个问题的答案仍不确定,因为其似乎取决于多个因素。这项特殊的任务被称为模仿学习(imitation learning),其涉及到使用来自更高级模型(如 GPT)的响应结果来微调、训练一个全新的语言模型。虽然这看起来是一种从下游模型(downstream model)中提取良好性能的好方法,但这种方法也存在一些不明显的问题。
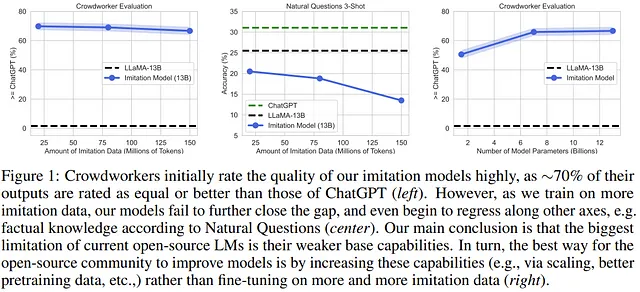
最近一篇题为《The False Promise of Imitating Proprietary LLMs》[1] 的论文揭示了使用这种方法可能会存在的一些隐患。作者通过进行实验证明,增加许多 “模仿” 数据可能会导致模型性能下降。观察上图,我们可以在中间的图表中发现:随着 tokens 数量的增加,基准任务的准确性确实在下降。但是,为什么会出现这种情况呢?
作者认为这是因为模仿模型(imitation models)学习的是其所模仿的模型的内容风格,而不是学习和理解模型输出的内容。从上图左侧的图表可以看出,人类评审员更喜欢模仿模型的输出结果,而非 ChatGPT。经过探讨可以发现,评审员明显更喜欢模仿模型(imitation models)的内容风格,但并没有仔细审查输出内容。值得注意的是,模仿模型产生的内容往往缺乏事实依据,导致作者总结道: “模仿模型实际上体现的是 AI 助手最糟糕的一些方面:它们的回答听起来很自信,但比 ChatGPT 的回答更缺乏事实依据。”
值得注意的是,在某些情况下,模仿模型(imitation models)可以取得出色的表现。作者指出,在本地任务或者复制教师模型(teacher model)的特定行为的任务上,模仿模型可以取得良好的性能。在一项名为 “NQ-Synthetic” 的研究任务中,作者要求大语言模型根据给定的语境生成 10 个相关问题和答案。令人惊讶的是,模仿模型的得分接近于 GPT 的得分。这表明,在尝试模仿教师模型的行为时,更加专注于特定领域的模型可能会取得更好的表现。
文章中提到的一个有趣的推论,使用教师模型对模型进行微调实际上有助于降低模仿模型的 toxic(内容毒性)分数。这对于那些希望快速推出一款开源 LLM(大语言模型),而不想费力围绕输出构建内容过滤器的公司来说非常有用。相较于手动构建内容过滤器,公司可以选择使用经过精心处理的数据集,通过从教师模型获取的输出进行训练,以获得一个可靠的基座。
值得一提的是微软研究院最近发布的 Orca 模型,它将来自 GPT 的信息或指导(signals)作为训练数据的一部分。两者的区别在于模型所使用的训练数据的大小。Orca 模型在 500 万个示例的基础上进行微调,而全面的模仿模型仅在大约 15.1 万个可观测数据上进行了调优。由于我推测大多数读者不会花费 16000 美元来进行一个随意的 LLM 实验,所以我更倾向于参考构建模仿模型相关的论文而非 Orca 模型进行陈述。然而,我们仍需等待更多研究结果,以明确确定模仿学习作为用于更全面任务的可行方案所需的最少示例数量。
总结:由于任务的复杂程度不一,尝试用一个性能较弱的模型去模仿 GPT 或其他高级模型的输出可能导致模型性能不佳。
02 仅凭上下文学习就足够了吗?
上下文学习 (In-context learning),也称为少样本学习,是一种在 prompt 中加入需要完成的特定任务示例的过程。这种方法主要适用于复杂的大语言模型,因为大部分小型开源模型尚未具备所需的灵活性(flexibility)来完成上下文学习。通常情况下,通过这种方法可以取得很好的效果,但是你是否曾想过为什么会这样呢?
Dai 等人 [3] 的论文探讨了这个问题的答案,他们在论文中研究了在 prompt 中加载示例和使用相同示例对大模型进行微调之间的数学联系。作者证明,prompt 示例会产生元梯度(meta-gradients),这些元梯度会在推理时的前向传播过程(forward propagation)中得到反映。而在微调时,这些示例产生了用于更新权重的真实梯度(real gradients)。因此,似乎上下文学习可以实现与微调类似的效果。如果想要更深入地了解这些内容,我建议阅读这篇论文,其中详细介绍了这些数学联系的具体细节。
虽然上下文学习的方法很好,但确实存在微调所不具备的局限性。在我们拥有大量训练数据时,微调后的模型会在训练过程中使用真实梯度更新模型,从而利用所有数据。而在上下文学习过程中,我们只能提供有限数量的可观测数据。于是,一个新问题便出现了:在给定大量训练数据的情况下,我们如何才能利用与我们的输入最相关的示例来获得最佳模型响应?
解决该问题的一种有效方法是使用启发式算法来选择示例,目前 LangChain 提供了对此算法的支持。LangChain 是一个 Python 模块,基本上包含了预构建的提示(pre-built prompts),可以简化语言模型的工作。我们现在需要重点关注的 LangChain 工具是 ExampleSelector(https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/)。
def get_similarity(seq_a: str, seq_b: str) -> Union[float, int]:
"""
Make a similarity heuristic,
here we use Jaccard similarity or IOU
seq_a: First sequence to compare
seq_b: Second sequence to compare
Returns:
Similarity score (float or int)
"""
# Tokenize
set_a = set(seq_a.split(' '))
set_b = set(seq_b.split(' '))
# Calculate IOU/Jaccard similarity
return len(set_a.intersection(set_b)) / len(set_a.union(set_b))
def example_selector(examples: List[str], input: str, examples2use: int) -> List[str]:
"""
Pseudo code for an example selector
examples: List of training corpus
input: Target sequence to translate
examples2use: Number of examples to use
Returns:
List of selected examples
"""
scores = [get_similarity(example, input) for example in examples]
sorted_idx = [i for i, _ in sorted(enumerate(scores), key=lambda x: x[1], reverse=True)]
return examples[sorted_idx[:examples2use]]
ExampleSelectors 是一种 prompt 操作器,该工具允许我们在推理时动态地改变使用的示例。有许多启发式算法可以使用。上面我给出了一些伪代码,是想要告诉大家 LangChain 的选择器本质上是如何工作的。我在输入序列和示例序列之间使用了 Jaccard 相似度。(译者注:Jaccard 相似度是衡量两个集合的相似度一种指标,本质上是集合的交集与集合的并集的比例)
采用该种方法有两个主要优点。首先,可以根据给定的输入,有选择性地选择最相关的示例,从而使 LLM 更高效的利用数据。这有别于为所有可观测结果(observations)静态加载几个示例的做法。如果通过托管服务进行调整,另二个优点是可以节约成本。截至目前,使用经过微调的 Davinci 模型的成本为每 1000 个 token 0.12 美元。相比之下,使用 instruct Davinci 的价格为 0.02 美元,前者价格为后者的 500%!还不包括模型训练费用。
需要注意的是,正如一篇现已删除的博文 [5] 所透露的那样,由于 OpenAI 尚未使用 LoRa 或 Adapters,这些价格后续可能会发生变化。尽管如此,由于必须为每个用户维护自定义的权重,微调模型的价格可能仍然会更高。此外,这还没有考虑到上下文中示例的成本。您的团队需要从成本和准确性等角度,去评估是上下文学习(ICL)还是微调(fine-tuning)对完成目标任务更有意义。
Takeaway:使用动态示例加载的上下文学习在某些场景下可以达到与微调相同的效果,相对成本会更低。
03 在进行最终的推理步骤之前,执行目标任务是否需要一个或多个中间步骤?
比方说,要求模型尝试回答关于长文档的复杂问题。这种任务一般都要求大语言模型具备良好的语言掌握能力和理解能力。这样又会引出一个问题:如果我们帮助语言模型将推理过程分解为多个子任务执行,类似于人类分析文档并按顺序执行任务,会怎么样呢? 
这正是微软公司的研究人员想要实现的目标,他们解决这一问题的方案是 PEARL [4]。PEARL 是 Planning and Executing Actions for Reasoning over Long documents 的缩写,意为 “长文档推理的规划和操作执行”。这个通用框架主要分为三个步骤:
- 行为挖掘(Action Mining) :首先,通过 prompt 让语言模型阅读文档,并提取可用于回答特定领域问题的可行行为。为了提取这些行为,语言模型通常会给出一些示例的行为方式。后续我将给出关于 “行为 action” 的示例。
- 规划生成(Plan Generation) :在生成一组用于目标任务的操作方案之后,需要要求 LLM 根据问题和上下文生成一系列需要按顺序执行的操作流程。LLM 会提供一些其他目标任务的规划样例,以帮助构建高质量的操作流程规划。更多技术细节可以在论文中找到。
- 执行规划(Plan Execution) :模型有了操作流程规划之后,将用户输入提供给模型并执行操作流程规划。
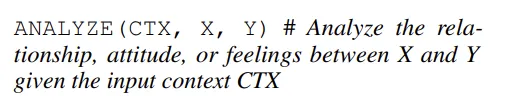
在上述各个阶段之间,还有一些中间步骤被用来确保目标任务的执行效果质量。作者们设置了一个自纠正步骤(self-correction step),确保计划符合所需的格式。还有一个自完善步骤(self-refinement),用于确定此操作流程规划是否可以作为后续用于【规划生成】流程的小样本示例使用。
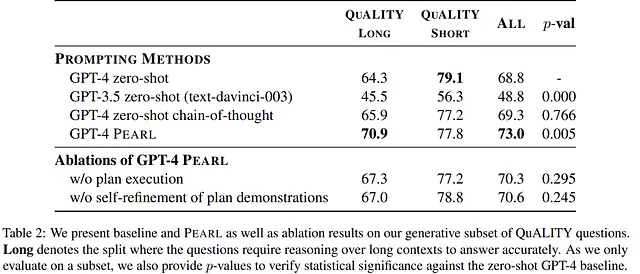
在进行评估时,发现 PEARL 相较于其他 GPT 模型拥有明显的性能改进。于是可以得出结论,在某些情况下,将目标任务的解决方案划分为多个步骤可以较明显地帮助模型提升性能。
还有另一个情况,当上下文中的文档数量超过语言模型所支持的数量时,设置一些中间步骤也被证明是有利的。 目前,OpenAI 使用的注意力机制的计算复杂度为 O (n²),暂时还没有解决这一问题的具体方案 [5]。因此,大家都对如何将上下文减少到尽可能最小的形式十分感兴趣。
对于不同的目标任务,有不同的处理方法。例如,如果目标任务完全围绕实体展开,就有机会提取相关实体及其相关属性。(译者注:在处理文本时,可以识别出文本中的特定实体(如人名、地点、组织等),并提取这些实体的相关属性(如年龄、地址、职位等)。通过这种方式,可以将文本中的信息转化为结构化的形式,使得对实体和属性的理解更加明确和系统化。这样可以为后续的任务提供更准确和有用的信息。)可以将这种方法看作是一种有损压缩,这种方法允许用户将更多上下文输入到 LLM 中。这一中间步骤的另一个好处是,可以将非结构化数据转换为结构化格式,这使得用户可以在不使用 LLM 的情况下也能进行明智的决策。下面是 Fei 等人的论文中展示的一个示例任务图表 [6]。 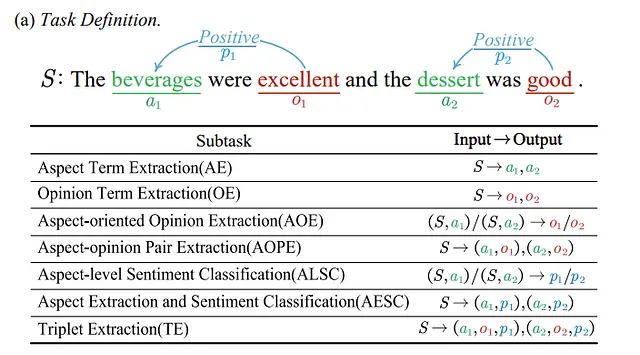
Takeaway:将目标任务分解成较小的子任务,有助于将较复杂的问题简化为更易管理的部分,还可以利用这些较小的任务来解决与模型限制相关的性能瓶颈问题。
04 结束语
以上是研究人员在 LLM 性能和效率这一新领域探索的一些总体思路。这并非微调模型时需要考虑的所有事项,却是一个很好的起点,可以给我们提供一些参考。
如需进一步了解,Hugging Face 发表的这篇有关 LLM 训练的文章 [7] 非常有趣,对于在特定领域的问题上探索模仿模型来说是一个很好的开始。
再次概括本文要点:
- 由于任务的复杂程度不一,尝试用一个性能较弱的模型去模仿 GPT 或其他高级模型的输出可能导致模型性能不佳。
- 使用动态示例加载的上下文学习在某些场景下可以达到与微调相同的效果,且成本较低。
- 将目标任务分解成较小的子任务,有助于将较复杂的问题简化为更易管理的部分,还可以利用这些较小的任务来解决与模型 Token 限制相关的性能瓶颈问题。
END