大模型微调:RHLF与DPO浅析
大模型应用性能的提升不仅在于其预训练,而微调的作用也非常显著。对于多数从事大模型应用领域的团队而言,微调是一个核心的工作之一,为专门任务完善大模型并确保其产出符合我们的预期。
1. 关于微调
微调涉及调整预训练的LLM ,以更有效地执行特定的功能,提高其在不同应用程序中的效用。尽管LLM通过预训练获得了广泛的知识基础,仍需要定制以在特定领域或任务中表现出色。例如,对一般数据集上训练的大模型进行微调,以理解医学语言或法律术语的细微差别,使其在这些环境中更相关、更有效。关于微调的更多内容可以参考《解读大模型的微调》。
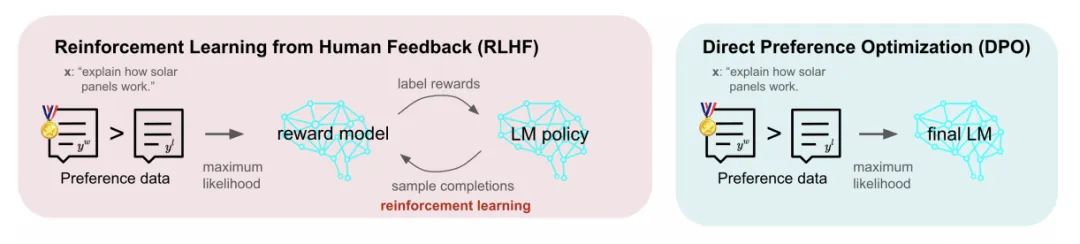
在众多的微调技术中, RLHF 利用复杂的反馈回路,结合人工评估和奖励模型来指导人工智能的学习过程。而DPO 采用了更直接的方法,直接运用人的偏好来影响模型的调整。这两种策略的目的都是提高模型的性能,确保产出符合用户的需要,但它们的运作原则和方法各不相同。
2. RLHF
关于RLHF 的基本原理可以参考《解读ChatGPT中的RLHF》一文,这里做一下回顾。首先澄清的是,强化学习是一种用于微调人工智能模型的技术,目的是根据人类的反馈来提高模型的性能。而RLHF 的核心组成部分包括被微调的语言模型,评估语言模型输出的奖励模型,以及通知奖励模型的人类反馈。这个过程确保语言模型产生的输出更符合人的偏好。
RLHF 以强化学习为基础,模型从动作中学习,而不是从静态数据集中学习。不像监督式学习那样,模型从标记的数据或非监督式学习中学习,模型识别数据中的模式,强化学习模型从他们行为的后果中学习,受到奖励的指导。在 RLHF 中,“回报”是由人的反馈决定的,这意味着模型成功地产生了理想的输出。
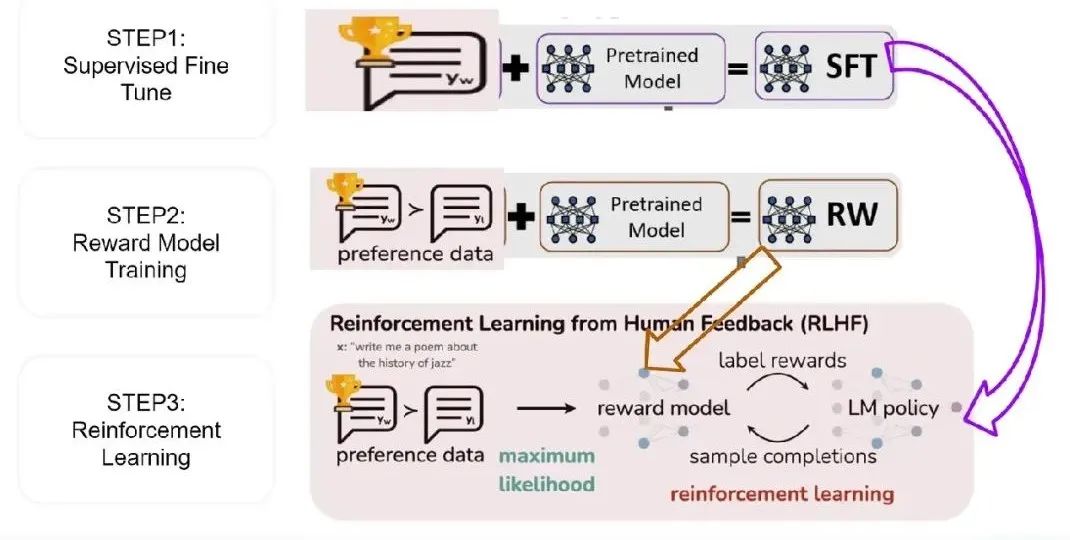
2.1 大模型的自我监督预训练
从收集一个庞大而多样化的数据集开始,通常包括广泛的主题、语言和写作风格。这个数据集作为语言模型的初始训练场。
利用这个数据集,模型进行自我监督学习。在这里,模型被训练来预测给定其他部分的文本部分。例如,它可以根据前面的单词预测句子中的下一个单词。这个阶段帮助模型掌握语言的基础知识,包括词法、语法和一定程度的上下文理解。成果是一个基础模型,可以生成文本并理解某些上下文,但缺乏针对特定任务的专门化微调。
2.2 基于人工反馈对模型输出排名
一旦预训练完成,模型开始生成文本输出,然后由人进行评估。这可能包括完成句子、回答问题或进行对话等任务。人类评估者使用评分系统对每个输出进行评分。他们考虑的因素包括文本的相关性、连贯性或吸引力。这种反馈至关重要,因为它将模型引入到人类的偏好和标准中。
注意确保评价人员的多样性并减少反馈中的偏见。这有助于为模型的输出创建一个平衡和公平的评估标准。
2.3 训练奖励模型来模仿人类评分
人类评估者的得分和反馈被用来训练一个单独的模型,称为奖励模型。该模型旨在理解和预测人类评估者对语言模型生成的任何文本的评分。这个步骤可能涉及反馈收集和奖励模型调整的几个迭代,以准确捕获人的偏好。
2.4 使用来自奖励模型的反馈来微调语言模型
从奖励模型中获得的见解被用来微调语言模型。这包括调整模型的参数,以增加生成与奖励行为一致的文本的可能性。
采用近似政策优化(PPO)等技术有条不紊地调整模型。该模型被鼓励去“探索”生成文本的不同方式,但是当它生成的输出可能从奖励模型中获得更高的分数时,它会得到更多的“奖励”。这个微调过程是迭代的,可以通过新的人工反馈和奖励模型调整来重复,不断改进语言模型与人类偏好的一致性。
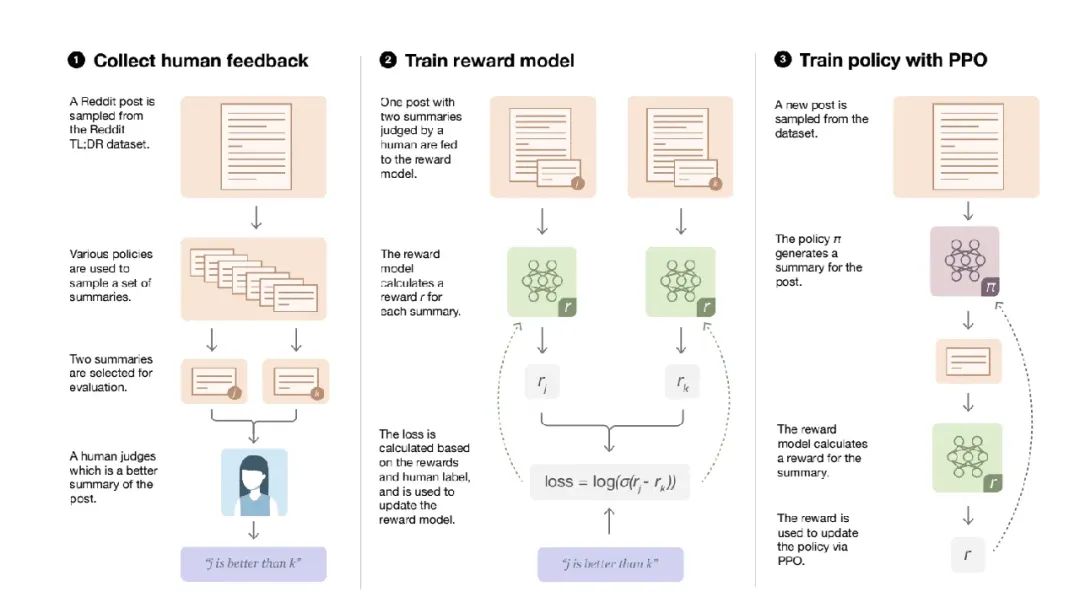
RLHF 的迭代过程允许不断改进语言模型的输出。通过反馈和调整的反复循环,该模式完善了生成文本的方法,更好地生成符合人类质量和相关性标准的产出。
3. DPO
DPO 是基于人类直接反馈可以有效地指导人工智能行为发展的原理而提出的。通过直接利用人的偏好作为训练信号,DPO 简化了校准过程,将其框定为一个直接学习任务。这种方法被证明是高效和有效的,提供了优于传统的强化学习方法。
简而言之,直接偏好优化(DPO)是一种通过将人的偏好直接纳入训练过程来调整大型语言模型(LLM)的简化方法。这种技术简化了人工智能系统的适应性,以更好地满足用户需求,绕过了与构建和利用奖励模型相关的复杂性。
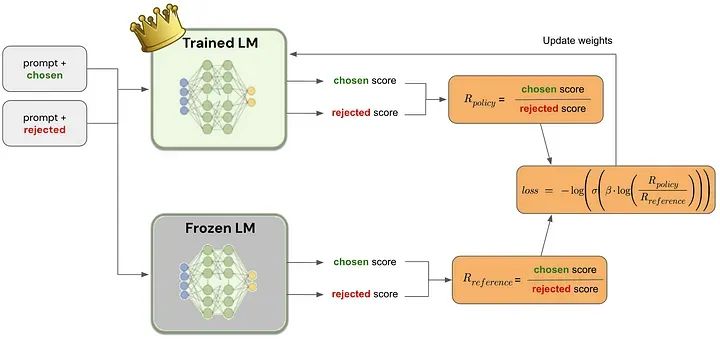
3.1 模型的自我监督预训练
从自我监督学习开始,接触到大量的文本数据。这可以包括从书籍和文章到网站的所有内容,包括各种主题、风格和上下文。模型学习预测文本序列,基本上填充空白或根据前面的上下文预测后续的单词。这种方法有助于模型掌握语言结构、语法和语义的基本原理,而不需要明确的面向任务的指令。
建立一个基本语言模型,能够理解和生成连贯的文本,可以根据具体的人类偏好进一步专门化。
3.2 收集问答对并获取人工评分
模型生成一对文本输出,这些输出可能在语气、风格或内容焦点方面有所不同。然后,这些对以一种比较格式呈现给人类评估者,询问两者中哪一个更符合某些标准,如清晰度、相关性或参与度。
评价者提供他们的偏好,这些偏好被记录为直接反馈。这一步对于捕捉人类的细微判断是至关重要的,这些判断可能不会从纯粹的定量数据中看出来。评价者提供他们的偏好,这些偏好被记录为直接反馈。这一步对于捕捉人类的细微判断是至关重要的,这些判断可能不会从纯粹的定量数据中看出来。
3.3 使用基于交叉熵的损失函数训练模型
使用成对的例子和相应的人类偏好,使用二元交叉熵损失函数对模型进行微调。这种统计方法将模型的输出与首选结果进行比较,量化模型的预测与所选择的首选结果的匹配程度。
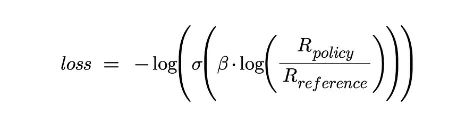
调整模型的参数,以最小化损失函数,有效地使优先输出更有可能在未来几代。这个过程迭代地改进了模型与人类偏好的一致性,提高了产生与用户产生共鸣的文本的能力。
3.4 约束模型以保持其生成性
尽管模型正在进行微调,以便与人类的偏好紧密一致,但确保模型不会丧失其生殖多样性是至关重要的。这个过程包括仔细调整模型,以纳入反馈,而不是过于适合具体的例子或限制其创造能力。技术和保障措施已经到位,以确保模式仍然能够产生广泛的反应。这包括定期评估模型的输出多样性和实施机制,以防止其生成能力收窄。
最终模型保留了其产生多样化和创新文本的能力,同时显著更符合人的偏好,表明增强了以有意义的方式吸引用户的能力。
DPO 将语言模型的调整视为基于人类反馈的直接最佳化问题,从而消除了单独奖励模型的需要。这种简化减少了模型训练通常涉及的复杂性层次,使得过程更加有效,并直接侧重于根据用户偏好调整人工智能输出。
4. RLHF 与 DPO的对比分析
RLHF能够处理多种反馈,这使得 RLHF 在需要详细定制的任务中占据优势。这使得它非常适合需要深刻理解和细微调整的项目。它的复杂性和对奖励模型的需求,这使得它在计算资源和设置方面更加苛刻。此外,反馈的质量和多样性可以显著影响微调工作的效果。
RLHF 擅长于需要定制输出的场景,如开发聊天机器人或需要深入理解上下文的系统。它处理复杂反馈的能力使它在这些应用中非常有效。
DPO 的流程更直接,这意味着调整更快,对计算资源的需求更少。它直接集成了人的偏好,从而与用户的期望保持紧密一致。DPO 的主要问题是,对于需要更多细微差别反馈的任务,它可能做得不够好,因为它依赖于二进制选择。此外,收集大量的人工注释数据可能是具有挑战性的。
当您需要快速人工智能模型调整并且计算资源有限时,DPO 是您的选择。它特别适用于调整文本中的情绪或归结为“是”或“否”选项的决策等任务,在这些任务中,可以充分利用其直接的优化方法。
RLHF 与 DPO的特性对比如下:
| 指标特性 | RHLF | DPO |
|---|---|---|
| 数据需求 | 需要不同的反馈,包括数字评分和文本注释,需要综合的反馈组合。 | 通常依赖于人工评分的样本对,简化了偏好学习过程,减少了复杂的输入。 |
| 训练特点 | 奖励模型的迭代引入,多步骤且计算密集型。 | 通过直接使用人的偏好,更加直观并提升计算效率,往往导致更快的收敛。 |
| 性能表现 | 能够提供适应性和微妙的影响,可能导致在复杂情况下的优越性能。 | 有效地快速调整模型输出与用户偏好,但可能缺乏多种反馈的灵活性。 |
| 策略优势 | 灵活处理不同的反馈类型; 适合于详细的输出形成和复杂的任务。 | 简化和快速的微调过程; 以较少的计算资源直接结合人的偏好。 |
| 局限约束 | 复杂的设置和较高的计算成本; 反馈的质量和多样性会影响结果。 | 除了二分选择之外,可能还会遇到复杂的反馈问题; 收集大量带注释的数据是一项挑战。 |
| 典型场景 | 最适合需要个性化或定制输出的任务,如会话代理或上下文丰富的内容生成。 | 非常适合需要快速调整的项目,并与人的偏好密切结合,如情绪分析或二元决策系统。 |
5. 策略选择
RLHF 是一个详细的,多步骤的过程,通过使用奖励模型提供深度定制的潜力。它特别适合于微妙的反馈至关重要的复杂任务。
DPO 通过直接应用人的偏好简化了微调过程,为模型优化提供了更快、更少资源密集的路径。
RLHF 和 DPO 之间的策略选择应遵循以下几个因素:
任务复杂性: 如果您的项目涉及到复杂的交互或者需要理解细微的人类反馈,RLHF 可能是更好的选择。对于更直接的任务或需要快速调整时,DPO 可能更有效。
资源考量: 考虑计算资源和人工注释器的可用性。DPO 通常在计算能力方面要求较低,在收集必要数据方面可以更直接。
期望控制水平: RLHF 提供了更多的细粒度控制微调过程,而 DPO 提供了一个直接的路径,以调整模型输出与用户的喜好。评估在微调过程中需要多少控制和精度。
6. 一句话小结
通过强化学习,利用人类反馈(RLHF)和直接偏好优化(DPO)微调大模型,能够保证相对准确地产生一些关键的见解,使人工智能在适应性、高效率和符合人类价值观方面发挥重要作用。
【参考资料与关联阅读】
"Comparing the RLHF and DPO", https://arxiv.org/pdf/2312.16682.pdf
大模型应用的10种架构模式
7B?13B?175B?解读大模型的参数
“提示工程”的技术分类
大模型系列:提示词管理
提示工程中的10个设计模式
Chunking:基于大模型RAG系统中的文档分块
大模型应用框架:LangChain与LlamaIndex的对比选择
在大模型RAG系统中应用知识图谱
面向知识图谱的大模型应用
让知识图谱成为大模型的伴侣
如何构建基于大模型的App
Qcon2023: 大模型时代的技术人成长(简)
论文学习笔记:增强学习应用于OS调度
LLM的工程实践思考
大模型应用设计的10个思考
基于大模型(LLM)的Agent 应用开发
解读大模型的微调
解读ChatGPT中的RLHF
解读大模型(LLM)的token
解读提示词工程(Prompt Engineering)
解读Toolformer
解读TaskMatrix.AI
解读LoRA
解读RAG
大模型应用框架之Semantic Kernel
浅析多模态机器学习
深度学习架构的对比分析
老码农眼中的大模型(LLM)