Apache DataFusion查询引擎简介
01
简介
DataFusion是一个查询引擎,其本身不具备存储数据的能力。正因为不依赖底层存储的格式,使其成为了一个灵活可扩展的查询引擎。它原生支持了查询CSV,Parquet,Avro,Json等存储格式,也支持了本地,AWS S3,Azure Blob Storage,Google Cloud Storage等多种数据源。同时还提供了丰富的扩展接口,可以方便的让我们接入自定义的数据格式和数据源。
特征
高性能:基于Rust,不用进行垃圾回收,其开发效率与 Java 或 Golang 相似,具有 C++ 的性能;基于Arrow内存模型,列式存储,方便向量化计算;
连接简单:作为 Apache Arrow 生态系统(Arrow、Parquet 和 Flight)的一部分,DataFusion 可以与大数据生态系统的其他部分很好地配合使用;
集成和定制简单:可以扩展用户定义的标量/聚合/窗口函数、数据源、SQL、其他查询语言、自定义计划和执行节点、优化器过程等;
奇麟数仓引入DataFusion目的
利用高性能的Rust语言和Apache Arrow列式存储特性,使奇麟数仓成为数据库、数据框库、机器学习等数据中心系统的首选查询引擎;
利用DataFusion高效灵活可扩展得用户接口,方便奇麟数仓自定义数据源,实现倒排索引功能,自定义索引查询函数,为查询加速;
DataFusion向量化式的查询引擎可以帮助提升奇麟数仓整体的性能;
02
Rust语言
连续多年成为全世界最受欢迎的语言、没有 GC 也无需手动内存管理、性能比肩 C++/C 还能直接调用它们的代码、安全性极高 。
Rust的最大优势之一是其内存安全性,在内存管理上,常见的方式有两种:要么如Java、Python一样使用垃圾回收算法,要么像C++一样手工管理内存。但垃圾自动回收必然影响性能,手工管理内存则可能会出现内存泄漏和悬停指针之类的问题。
rust内存安全保障,主要体现在以下几点:
所有权系统:Rust通过所有权(Ownership)、借用(Borrowing)和生命周期(Lifetimes)的概念来管理内存。每块数据在Rust中都有一个明确的所有者,当所有者(变量)离开作用域,这个值将被丢弃;数据可以被借用,但在任何时刻,要么只能有一个可变引用(写权限),要么有多个不可变引用(读权限),这避免了数据竞争和修改冲突。Rust 中的每一个引用都有其 生命周期(lifetime),也就是引用保持有效的作用域。大部分时候生命周期是隐含并可以推断的,当出现引用的生命周期以一些不同方式相关联的情况,Rust 需要我们使用泛型生命周期参数来注明它们的关系。
借用检查器:Rust编译器内置的借用检查器能在编译时检查引用是否遵守所有权和生命周期的规则,确保安全地访问内存。
无空指针:Rust通过Option<T> 枚举类型处理可能为空的情况,使得开发者必须显式处理None 情况,避免了空指针引用。
Rust的基本理念是 “零成本抽象”。这一理念让Rust具备高级语言表达能力的同时,又不会带来性能损耗。与其他系统级编程语言(如C或C++)相比,Rust不需要程序员将所有时间都花在细节上,而是通过添加更高层次的编程概念,确保使用的抽象几乎没有运行时开销,这种抽象与等效的手写代码具有同等的性能。
高性能:Rust作为一种编译型语言,其性能表现非常出色。与解释型语言相比,Rust代码在编译时会进行优化,生成高效的机器码。这使得Rust在系统级编程中能够发挥出更高的性能。
03
Apache Arrow 介绍
Apache Arrow 是 Wes McKinney 大佬在2016年开启的一个项目, 用于解决他创建的Pandas 的一堆问题:
缺少统一的内存数据管理方式, pandas每对接一个外部系统都需要单独实现一套数据转化工具, 比如将pandas的数据格式转为 spark的 dataframe, 性能极差.
内存数据处理无法高效利用现代计算硬件: CPU/GPU/FPGA, 比如向量化能力较差, 无法高效利用SIMD指令.
大数据集的支持度不高, 数据处理以及传递链路上存在较多的内存拷贝, 导致一份数据集在内存中会放大多倍。
Apache Arrow 是一种基于内存的列式数据结构,它的出现就是为了解决系统到系统之间的数据传输问题,在分布式系统内部,每个系统都有自己的内存格式,大量的 CPU 资源被消耗在序列化和反序列化过程中,并且由于每个项目都有自己的实现,没有一个明确的标准,造成各个系统都在重复着复制、转换工作,这种问题在微服务系统架构出现之后更加明显,Arrow 的出现就是为了解决这一问题。
Arrow 项目旨在开发一个多语言库(C++, JAVA,RUST)集合,用于解决与内存分析数据相关得系统问题,提高CPU计算效率
Arrow特性
Zero-copy shared memory and RPC-based data movement 零拷贝共享内存和基于 RPC 的数据移动
Reading and writing file formats (like CSV, Apache ORC, and Apache Parquet) 读取和写入文件格式
In-memory analytics and query processing 内存分析和查询处理
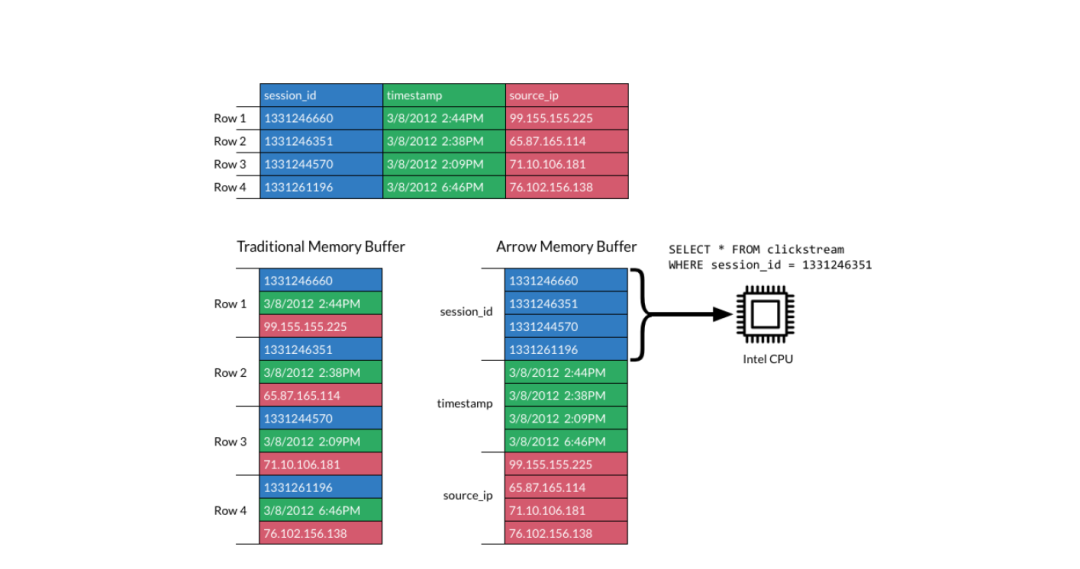
从上图中,我们可以很清晰的看出,传统的内存数据格式,数据在内存中各个字段的分布是以一行呈现,相同字段并未集中排列在一起,造成了计算时的不必要浪费。而通过 Arrow 格式化后的内存数据,可以将相同字段集中排列在一起,不仅减少了扫描内存的page数,降低了cpu Cache miss,还可以利用现在计算机SIMD(Single Instruction, Multiple Data)指令进行加速。
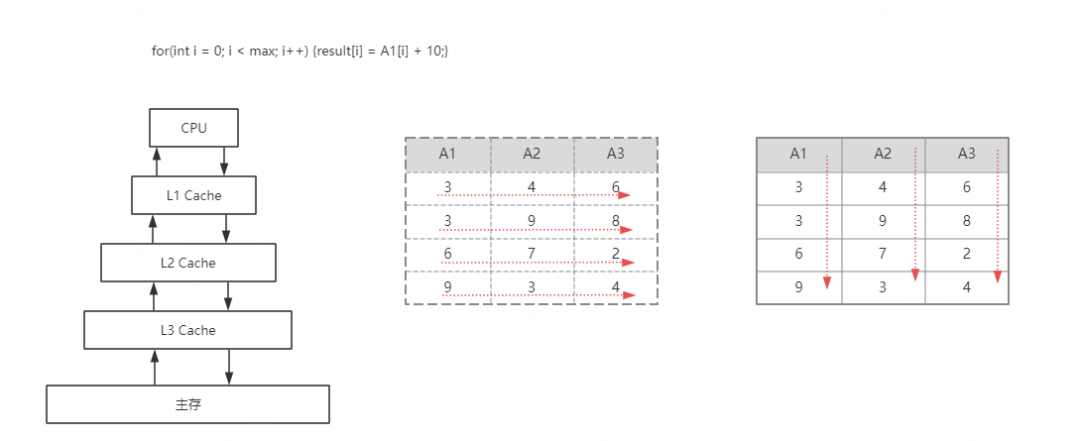
左边的图是当前的cpu以及组成的架构的一个抽象的图,离cpu越近,速度越快,容量也越小,数据首先先要进入到主存,一层一层的load到cpu的cache,然后cpu才能进行计算;
当我们在计算一个简单的例子,比如A1+10,按照行存的格式load到cpu cache中,一行的数据是紧密的排在内存中的,load的时候,是按照一个块一个块的load,那么A2、A3这些列的数据,也会被load到cpucache中的,当cpu cache满的时候,就需要和主存进行交互,这个时候就造成cpu cache miss情况变多,存在cpu等待数据的情况,使用arrow列式内存格式,需要A1的数据时,load到cpu cache的数据,完全都是A1的,减少cpu cache miss情况。
Arrow 在内存格式的设计中主要有几个数据结构
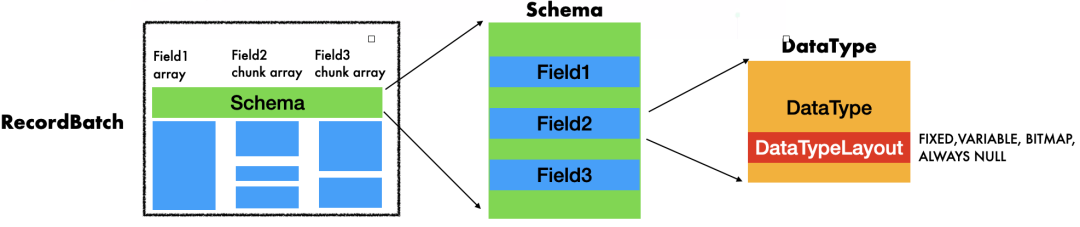
Buffer:数据内存格式存储实际数据的最底层数据结构, 主要维护了一段连续的内存区域.
类型系统 DataType 和 Array:DataType可以理解为数据的描述信息,数据类型, Array则直接保存列式的数据, 每一个Array对应一个 DataType描述的列式数据, Array的底层管理了一个或者多个Buffer
RecordBatch 和 Schema:RecordBatch 是一个或者多个 不同DataType 但是相同长度 Array 的集合,Schema 则是 RecordBatch 用来管理这一些Array类型的结构,
Table :构建在RecordBatchy基础之上的一个内存结构.
04
DataFusion
架构图如下:
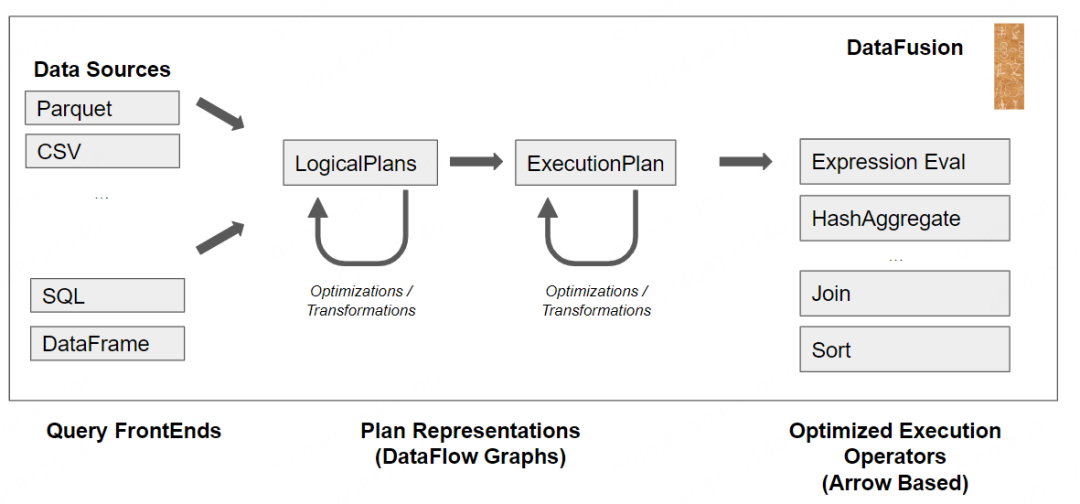
DataFusion查询引擎主要由以下几部分构成:
语法分析和语法解析,使用 sqlparser 将查询字符串解析为抽象语法树 (AST),然后AST被转化为逻辑计划和逻辑表达式.
查询中间表示:Expression/Query Plan/Relational Operatiors(关系算子)、Rewriters/Optimizations逻辑计划优化
根据AnalyzerRules检查并重写逻辑计划,强制执行语义规则
LogicalPlan被OptimizerRules重写,如 projection ,filter pushdown,等提升查询效率
LogicalPlan 由 PhysicalPlanner 转换为 ExecutionPlan
根据PhysicalOptimizerRules重写ExecutionPlan,例如排序Sort orders和连接选择(如Hash join和Merge join等),以提高其效率
执行
ExecutionPlans使用Apache Arrow 内存格式处理数据,调用execute生成1个或多个分区数据,例如,SendableRecordBatchStream实现了基于pull的执行API,调用 .next().await增量计算返回下一个RecordBatch,并行性是通过 RepartitionExec 实现的 Volcano 风格的 “Exchange” operations 来实现的。
Datafausion执行引擎特性
流式执行:所有的运算符都以Arrow 数组的形式递增输出,为了实现矢量化执行,每次拉取都是固定大小的RecordBatches。
并行执行:每个 ExecutionPlan 都使用一个或多个并行执行的 Stream来运行。大多数 Streams 只与它们的输入进行协调,但有些 Streams 必须与同级 Streams 进行协调,如 HashJoinExec 在构建共享哈希表时,或 RepartitionExec 在将数据重新分配到不同 Streams 时。为每个 ExecutionPlan 创建的流的数量称为其分区,分区在执行计划时确定。并行是使用多个Tokio任务实现的,这些任务由Tokio Runtime管理的线程执行
线程调度:使用tokio作为async-runtime
内存管理:DataFusion 使用 MemoryPool 管理内存,一个或多个并发运行的查询共享MemoryPool。当内存消耗发生重大变化时,Stream会通过调用grow and shrink API 记录。Stream使用一种实用的方法,准确跟踪最大的内存消耗(如用于hash merge的hashTable),但不跟踪小的短暂分配(如当前输出batch的内存)。DataFusion 有两种内置内存池实现。GreedyPool:会强制每个进程的内存限制,但不会试图在查询中将资源公平地分配给各个Stream。FairPool:在所有pipelinebreakingStreams之间平均分配资源
Cache管理:CacheManager 会缓存目录内容(如昂贵的对象存储 LIST 操作)和每个文件的元数据,如规划和剪枝所需的统计信息。
可扩展性
实现一个数据库很困难,通常包含很多模块,如查询计划,物理计划,执行计划等,一般一个数据库的实现背后都有一个公司,像spark, trino,starrocks,而DataFusion,核心是可扩展,几乎在任何地方都留有可扩展的接口,这使得目前有很多系统基于DataFusion进行定制构建。
更快的Spark运行时替换 blaze-rs,将 Spark 的物理优化计划转化为 DataFusion 的执行计划
LakeSoul :数元灵科技,云原生湖仓一体框架
专业分析数据库系统Ballista (Arrow): 和spark类似得分布式引擎
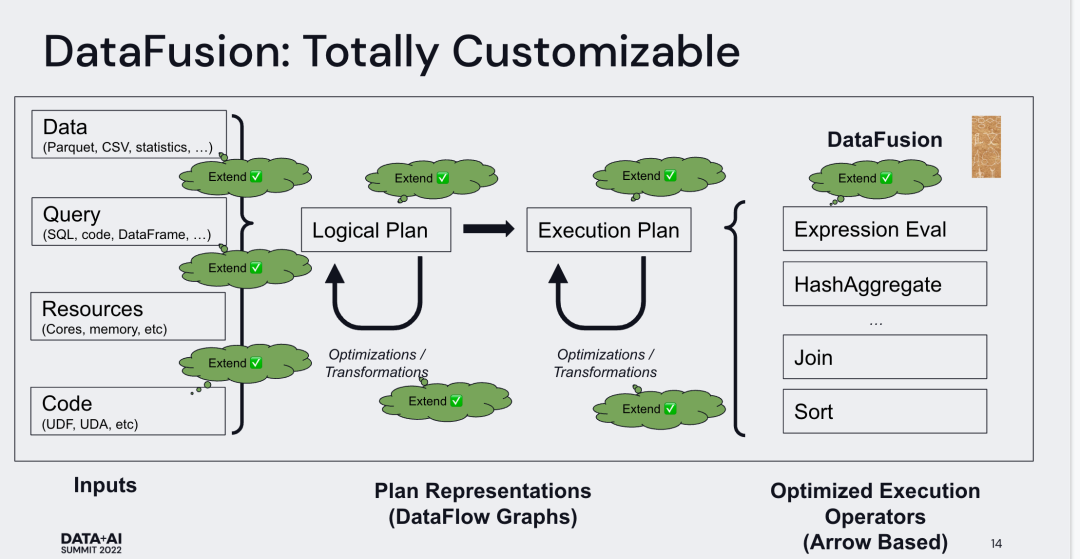
DataFusion 在很多方面支持扩展
从任何数据源读取DataSource( TableProvider )
定义自己的catalogs, schemas, and table lists ( catalog and CatalogProvider )
查询语言和计划query language or plans ( LogicalPlanBuilder )
声明和使用用户自定义函数 ( ScalarUDF , and AggregateUDF , WindowUDF )
自定义重写规则 custom plan rewrite passes ( AnalyzerRule , OptimizerRule and
PhysicalOptimizerRule )
用户自定义逻辑和物理计划( QueryPlanner )
用户自定义文件格式
用户自定义ObjectStore
DataFausion使用
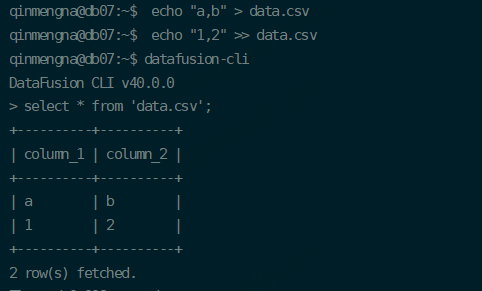
DataFusion CLI
交互式命令行实用程序,用于对任何支持的数据文件执行SQL查询,支持从本地文件、目录或远程位置(如S3)读取和写入CSV、Parquet、JSON、Arrow和Avro。
Rust编程
添加依赖
[dependencies]
datafusion = "40.0.0"
tokio = { version = "1.0", features = ["rt-multi-thread"] }1.直接执行sql查询
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
// register the table
let ctx = SessionContext::new();
ctx.register_csv("example", "tests/data/example.csv",CsvReadOptions::new()).await?;
// create a plan to run a SQL query
let df = ctx.sql("SELECT a, MIN(b) FROM example WHERE a <= b GROUP BY a LIMIT 100").await?;
// execute and print results
df.show().await?;
Ok(())
}2.使用DataFrame API
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
// create the dataframe
let ctx = SessionContext::new();
let df = ctx.read_csv("tests/data/example.csv", CsvReadOptions::new()).await?;
let df = df.filter(col("a").lt_eq(col("b")))?
.aggregate(vec![col("a")], vec![min(col("b"))])?
.limit(0, Some(100))?;
// execute and print results
df.show().await?;
Ok(())
}DataFrame表示一组具有相同命名列的逻辑行,类似于Pandas DataFrame或Spark DataFrame。
DataFrames通常是通过调用SessionContext上的方法(如read_csv)创建的,然后可以通过调用转换方法(如filter、select、aggregate和limit)进行修改,以构建查询定义的。
3.可扩展
用户自定义数据源的实现
自定义数据源其实就是生成一个对应的ExecutionPlan执行计划,这个执行计划实施的是扫表scan的任务。实现用户自定义数据源仅须实现如下,TableProvider的scan接口,scan接口返回一个ExecutionPlan执行计划。
ExecutionPlan 核心是获取批处理流的方法,返回Result,它应该是可以跨线程发送的 RecordBatch 流。
supports_filters_pushdown 方法也可以被重写,以指示哪些过滤器表达式支持被下推到数据源。
/// 自定义数据源需要实现的trait
pub trait TableProvider: Sync + Send {
...
async fn scan(
&self,
state: &SessionState,
projection: Option<&Vec<usize>>,
filters: &[Expr],
limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>>;
...
}
impl ExecutionPlan for CustomExec {
fn execute(
&self,
_partition: usize,
_context: Arc<TaskContext>,
) -> Result<SendableRecordBatchStream> {
...
}
}更多技术和产品文章,请关注👆

360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn
客服电话:4000052360