初始爬虫5
响应码:
数据处理: re模块(正则表达式)
re模块是Python中用于正则表达式操作的标准库。它提供了一些功能强大的方法来执行模式匹配和文本处理。以下是re模块的一些常见用法及其详细说明:
1. 基本用法
1.1 匹配模式
re.match(pattern, string):
功能:从字符串的开头开始匹配模式。
返回:一个匹配对象(Match对象)如果匹配成功,否则返回None。
示例:
python
import re
result = re.match(r'\d+', '123abc')
if result:
print(result.group()) # 输出 '123'
1.2 搜索模式
re.search(pattern, string):
功能:扫描整个字符串并返回第一个匹配的结果。
返回:一个匹配对象(Match对象)如果匹配成功,否则返回None。
示例:
python
import re
result = re.search(r'\d+', 'abc123def')
if result:
print(result.group()) # 输出 '123'
1.3 查找所有匹配
re.findall(pattern, string):
功能:查找所有匹配的子串并以列表形式返回。
返回:一个列表,其中包含所有匹配的字符串。
示例:
python
import re
results = re.findall(r'\d+', '123 abc 456 def 789')
print(results) # 输出 ['123', '456', '789']
1.4 替换文本
re.sub(pattern, repl, string):
功能:用指定的替换文本替换匹配的模式。
返回:替换后的字符串。
示例:
python
import re
result = re.sub(r'\d+', '#', 'abc 123 def 456')
print(result) # 输出 'abc # def #'
1.5 分割字符串
re.split(pattern, string):
功能:根据模式分割字符串。
返回:一个列表,其中包含分割后的字符串。
示例:
python
import re
result = re.split(r'\W+', 'hello, world! Python is great.')
print(result) # 输出 ['hello', 'world', 'Python', 'is', 'great', '']
2. 正则表达式的特殊字符
.:匹配除换行符外的任何字符。
^:匹配字符串的开头。
$:匹配字符串的结尾。
*:匹配前一个字符零次或多次。
+:匹配前一个字符一次或多次。
?:匹配前一个字符零次或一次。
{n}:匹配前一个字符恰好n次。
{n,}:匹配前一个字符至少n次。
{n,m}:匹配前一个字符至少n次,但不超过m次。
[]:匹配括号内的任意字符。
|:表示“或”操作。
\d:匹配任何数字,等同于[0-9]。
\D:匹配任何非数字字符。
\w:匹配任何字母数字字符,等同于[a-zA-Z0-9_]。
\W:匹配任何非字母数字字符。
\s:匹配任何空白字符,包括空格、制表符和换行符。
\S:匹配任何非空白字符。
3. 匹配对象方法
group():返回匹配的字符串。
groups():返回一个包含所有匹配组的元组。
start():返回匹配的开始位置。
end():返回匹配的结束位置。
span():返回匹配的起始和结束位置的元组。
示例:
python
import re
# 定义模式和字符串
pattern = r'(\d+)'
string = 'There are 123 apples and 456 oranges.'
# 使用 re.search 查找第一个匹配
match = re.search(pattern, string)
if match:
print(match.group()) # 输出 '123'
print(match.groups()) # 输出 ('123',)
# 使用 re.findall 查找所有匹配
matches = re.findall(pattern, string)
print(matches) # 输出 ['123', '456']
4. 编译正则表达式
re.compile(pattern):
功能:将正则表达式编译成一个正则表达式对象,可以多次使用。
示例:
import re
pattern = re.compile(r'\d+')
result = pattern.findall('The numbers are 123 and 456.')
print(result) # 输出 ['123', '456']
模拟github登录(异地登录需要邮件验证码未解决)
GitHub网站:https://github.com/login
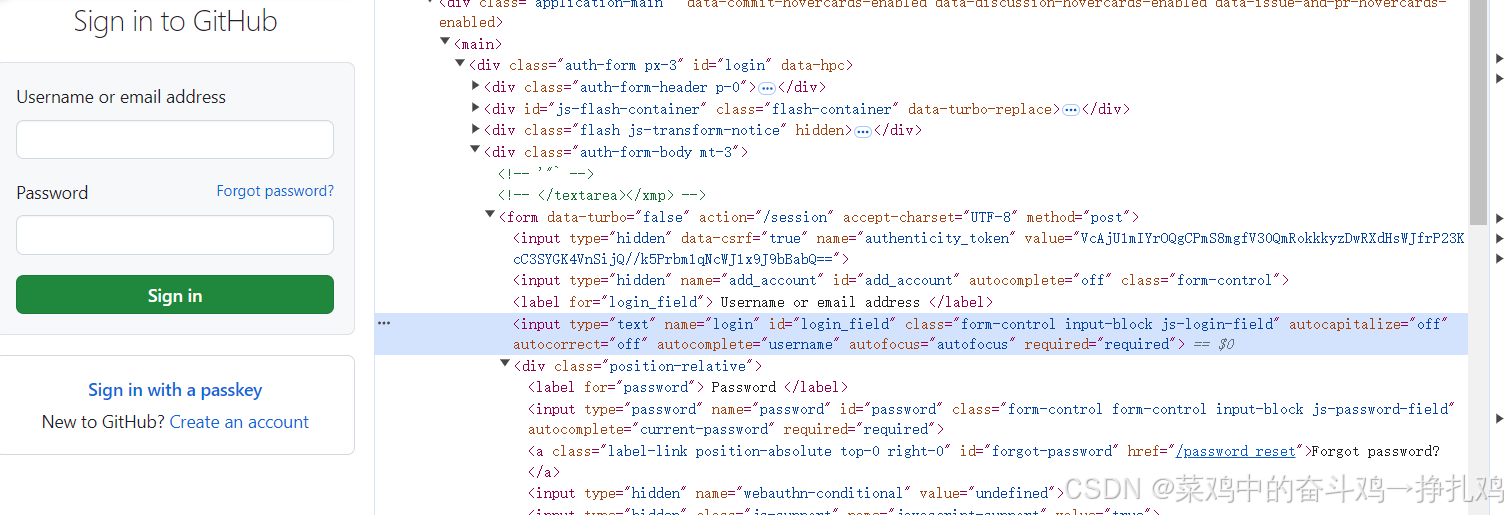
勾选Preserve log,记录每次响应:
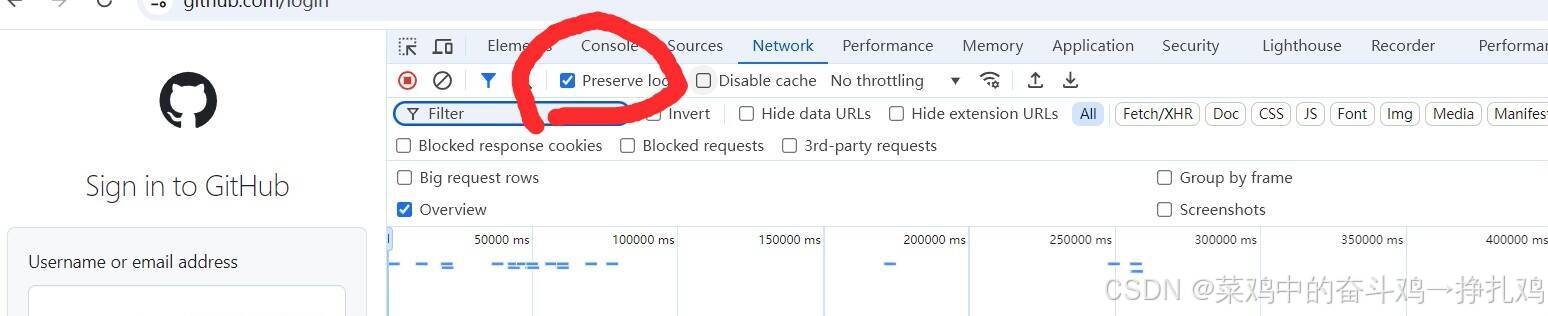
登录后查看post请求产生的Payload,此处信息可以两次登录对比看,以此得到想要模拟的登录信息:

完整实现github登录代码:
# -*- coding: utf-8 -*-
import re
# 1.获取并模拟登录操作 2.保存登录会话信息 3.验证是否登录成功
import requests
from requests import Session
def do_auth_token(session: Session):
global response
response = session.get('https://github.com/login')
if response.status_code != 200:
print("请求失败,请稍后再试!")
exit(0)
login_html = response.content.decode()
auth_token = re.findall(r'name="authenticity_token" value="(.*?)"', login_html)[0]
return auth_token
def do_auth_login(session: Session):
post_data = {
"commit": "Sign in",
"authenticity_token": auth_token,
"login": "123456",
"password": "123456", # 登录密码,为了个人账号安全我这里不是真实密码
"webauthn-conditional": "undefined",
"javascript-support": "true",
"webauthn-support": "supported",
"webauthn-iuvpaa-support": "unsupported",
"return_to": "https://github.com/login"
}
response = session.post(url='https://github.com/session', data=post_data)
if response.status_code != 200:
print("请求失败,请检查参数!")
else:
print("请求session 成功!")
def do_login_status(session: Session):
response = session.get('https://github.com/csqting')
html_content = response.content
response1 = re.findall(r'<title>(.+?)(GitHub)?</title>', html_content.decode('utf-8'))
try:
end_str = response1[0][1]
except IndexError:
end_str = ""
if end_str == "":
# 个人主页的title内容如果结尾没有GitHub,说明登录成功
print("登录成功!")
else:
print("登录失败!")
with open("github_profile.html", "wb") as f:
f.write(html_content)
if __name__ == '__main__':
# 使用session进行状态保持
session = requests.session()
session.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'
}
# 1. 获取并模拟登录操作
auth_token = do_auth_token(session)
# 2. 保存登录会话信息
do_auth_login(session)
# 3. 验证是否登录成功
do_login_status(session)

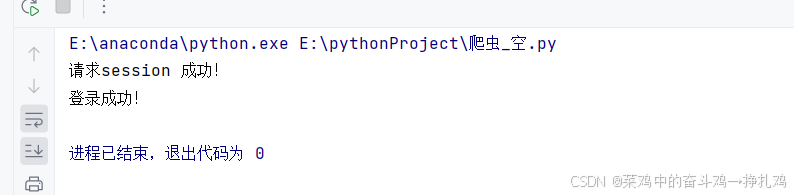
到此requests模块基本结束,下面就是数据提取的学习。