【RAG】RAG再进化?基于长期记忆的检索增强生成新范式-MemoRAG
前言
RAG现在工作很多,进化的也很快,再来看看一个新的RAG工作-MemoRAG。
文章提出,RAG在减少大模型对于垂类知识的问答幻觉上取得了不错的效果,也成为私域知识问答的一种范式。然而,传统RAG系统主要适用于明确信息需求的问答任务,但在处理涉及模糊信息需求或非结构化知识的复杂任务时表现不佳。因为,现实世界中的许多问题信息需求是模糊的,外部知识是非结构化的,例如理解书籍中主要角色之间的相互关系。
因此,研究难点在于:
- 如何有效处理模糊的信息需求
- 如何从非结构化知识中提取有用信息
- 如何在长文本上下文中进行有效的信息检索和生成
本文介绍的MemoRAG,一种基于长期记忆的检索增强生成新范式。
方法
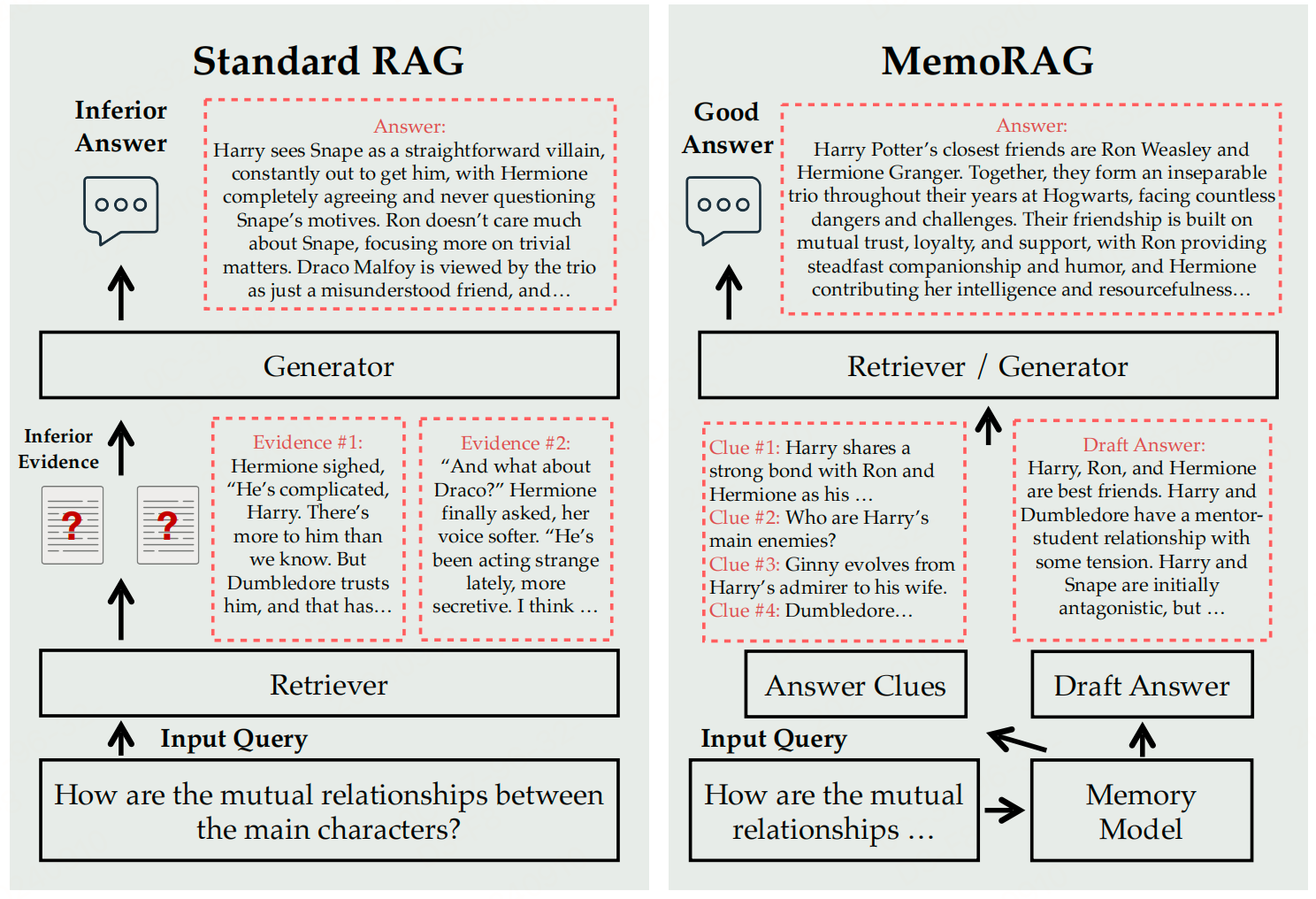
-
传统RAG
Y = Θ ( q , C ∣ θ ) , C = Γ ( q , D ∣ γ ) Y = \Theta(q, C | \theta), \quad C = \Gamma(q, D | \gamma) Y=Θ(q,C∣θ),C=Γ(q,D∣γ)
这里, Y Y Y 表示最终答案, q q q 表示输入查询, C C C表示从相关数据库 D D D 中检索到的上下文, Θ ( ⋅ ) \Theta(·) Θ(⋅) 和 Γ ( ⋅ ) \Gamma(·) Γ(⋅) 分别表示生成模型和检索模型, θ \theta θ 和 $\gamma $ 表示模型参数。
-
MemoRAG:
MemoRAG提出了一个双系统架构,采用了一个轻量级但长上下文的LLM来形成数据库的全局记忆,并在任务呈现时生成草稿答案,提示检索工具在数据库中定位有用信息。另一方面,它利用一个能力较强的LLM,根据检索到的信息生成最终答案。MemoRAG的核心是引入了一个记忆模块:

- y y y 表示由记忆模型 Θ mem ( ⋅ ) \Theta_{\text{mem}}(·) Θmem(⋅) 生成的中间答案,用作检索线索。
- 这个中间答案 y y y 帮助检索模型 Γ ( ⋅ ) \Gamma(·) Γ(⋅) 从数据库 D D D 中检索最相关的上下文 C C C。
记忆模型的作用:记忆模型 Θ mem ( ⋅ ) \Theta_{\text{mem}}(·) Θmem(⋅) 的设计目的是建立数据库 D D D 的全局记忆,并生成有助于检索的线索 y y y。
记忆模型选型:任何能够有效处理超长上下文的语言模型都可以作为记忆模型。文章也实现了两个记忆模型(memorag-qwen2-7b-inst和memoragmistral-7b-inst)。
记忆模块设计
-
输入
输入序列 X 包含 n 个标记,表示为 $ X = {x_1, \ldots, x_n} $
-
标注注意力机制
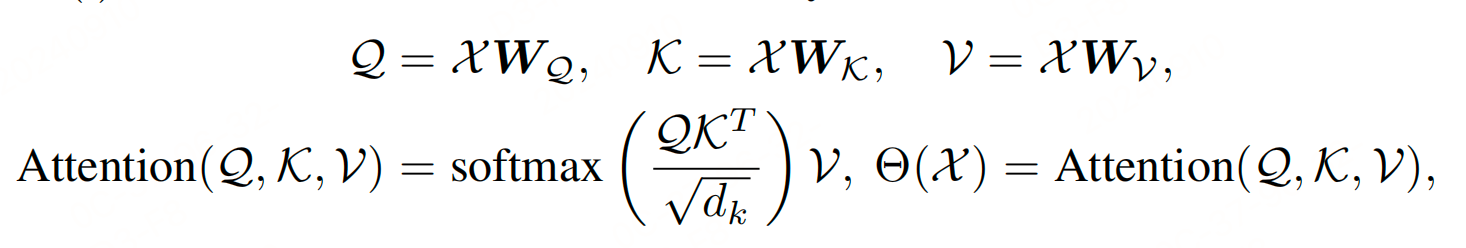
-
短期记忆到长期记忆的转换
为了将短期记忆转换为长期记忆,引入了记忆标记 $ x_m $ 作为LLMs中长期记忆的信息载体。假设底层LLM $\Theta(\cdot) $ 的工作上下文窗口长度为 $ l $,在每个上下文窗口后,附加 $ k $ 个记忆标记: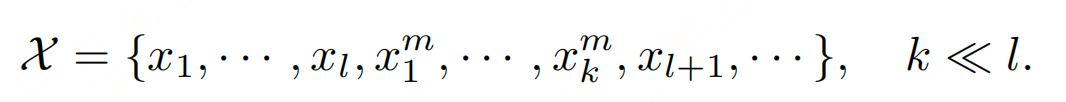
新的注意力变成:
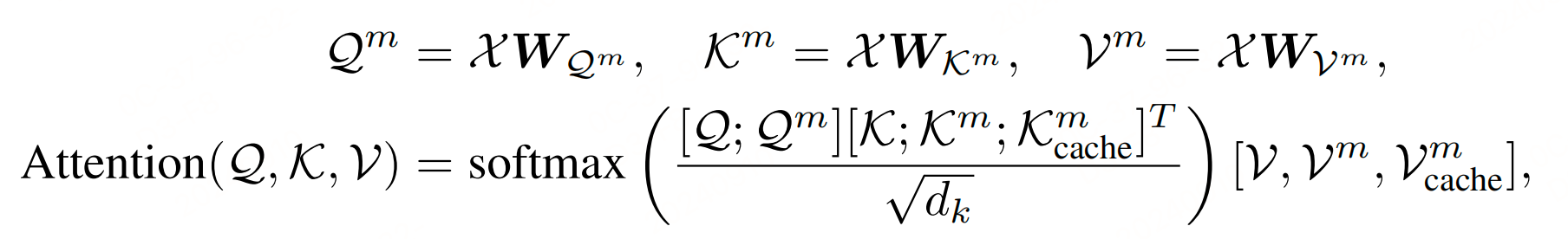
通过多个注意力过程,原始标记被编码成隐藏状态 $ X[0:l] = {x_1, \ldots, x_l, x_1^{m}, \ldots, x_k^{m}} $,其中 $ {x_1, \ldots, x_l} $ 表示原始标记的隐藏状态,$ {x_1^{m}, \ldots, x_k^{m}} $ 表示记忆标记的隐藏状态。
-
记忆模块训练:
-
训练过程
记忆模块的训练分为两个阶段:
- 预训练:使用来自RedPajama数据集的随机抽样长上下文对模型进行预训练,使记忆模块能够从原始上下文中学习如何形成记忆。
- 指令微调(SFT):使用特定任务的SFT数据,使MemoRAG能够基于形成的记忆生成特定任务的线索。
-
训练目标
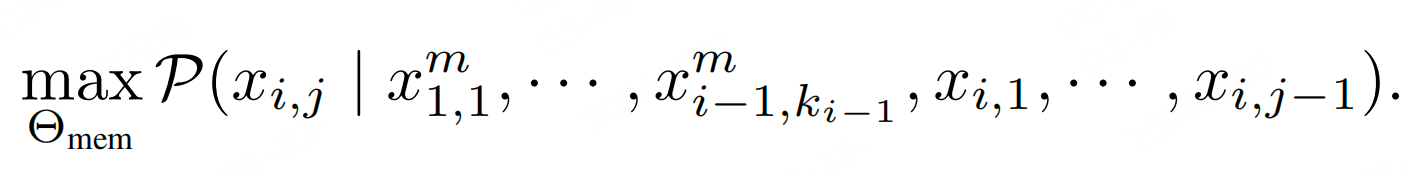
这个公式表示训练过程中的目标是最大化给定先前记忆标记 x m 1 , 1 , … , x m i − 1 , k i − 1 x_{m_1,1}, \ldots, x_{m_{i-1},k_{i-1}} xm1,1,…,xmi−1,ki−1 和最近原始标记 x i , 1 , … , x i , j − 1 x_{i,1}, \ldots, x_{i,j-1} xi,1,…,xi,j−1 的情况下,下一个标记 x i , j x_{i,j} xi,j的生成概率。
通过这种设计,记忆模块能够有效地将大量原始上下文压缩成少量的记忆标记,同时保留关键的语义信息,从而在处理长上下文和高层次查询时提供显著的优势。
基本使用
from memorag import MemoRAG
# Initialize MemoRAG pipeline
pipe = MemoRAG(
mem_model_name_or_path="TommyChien/memorag-mistral-7b-inst",
ret_model_name_or_path="BAAI/bge-m3",
gen_model_name_or_path="mistralai/Mistral-7B-Instruct-v0.2", # Optional: if not specify, use memery model as the generator
cache_dir="path_to_model_cache", # Optional: specify local model cache directory
access_token="hugging_face_access_token", # Optional: Hugging Face access token
beacon_ratio=4
)
context = open("examples/harry_potter.txt").read()
query = "How many times is the Chamber of Secrets opened in the book?"
# Memorize the context and save to cache
pipe.memorize(context, save_dir="cache/harry_potter/", print_stats=True)
# Generate response using the memorized context
res = pipe(context=context, query=query, task_type="memorag", max_new_tokens=256)
print(f"MemoRAG generated answer: \n{res}")
运行上述代码时,编码后的键值 (KV) 缓存、Faiss 索引和分块段落都存储在指定的 中save_dir。之后,如果再次使用相同的上下文,则可以快速从磁盘加载数据:
pipe.load("cache/harry_potter/", print_stats=True)
摘要任务
res = pipe(context=context, task_type="summarize", max_new_tokens=512)
print(f"MemoRAG summary of the full book:\n {res}")
实验

参考文献
- paper:MEMORAG: MOVING TOWARDS NEXT-GEN RAG VIA MEMORY-INSPIRED KNOWLEDGE DISCOVERY,https://arxiv.org/pdf/2409.05591v2
- code:https://github.com/qhjqhj00/MemoRAG