基于Kubernetes部署Spark:spark on kubernetes
什么是spark?
spark是一种基于内存的快速、通用、可扩展的的数据分析计算引擎。
Hadoop、Hive、Spark是什么关系?
大数据技术生态中,Hadoop、Hive、Spark是什么关系?| 通俗易懂科普向_哔哩哔哩_bilibili
Hadoop 与 HDFS (Hadoop Distributed File System):
-
- Hadoop 是一个用于处理大数据的开源框架,而HDFS是Hadoop的一个重要组成部分,它是一个分布式文件系统,用于存储大量的数据。
- HDFS 负责将数据分布在集群中的多个节点上,并提供一个统一的接口,使得这些数据看起来像是存储在一个地方。
MapReduce 与 Hadoop:
-
- MapReduce 是Hadoop的一个核心组件,它提供了一个编写并行处理应用的框架。
- 开发者可以使用MapReduce API将任务分解成Map(映射)和Reduce(归约)两个阶段,从而实现并行处理。
Hive 与 SQL:
-
- Hive 是一个构建在Hadoop之上的数据仓库工具,它允许用户使用SQL-like语言(HiveQL)来处理存储在Hadoop中的大规模数据集。
- Hive 提供了更高的抽象层次,简化了数据分析工作,降低了编写复杂MapReduce程序的难度。
Spark 与 Hadoop:
-
- Spark 是另一个用于大数据处理的框架,它可以独立运行或运行在Hadoop之上。
- Spark 与 MapReduce 不同之处在于它提供了内存计算能力,这意味着Spark可以在内存中缓存数据,从而加快数据处理速度。
- Spark 还提供了多种高级库,如Spark SQL、Spark Streaming、MLlib 和 GraphX,分别用于SQL查询、流式数据处理、机器学习和图计算。
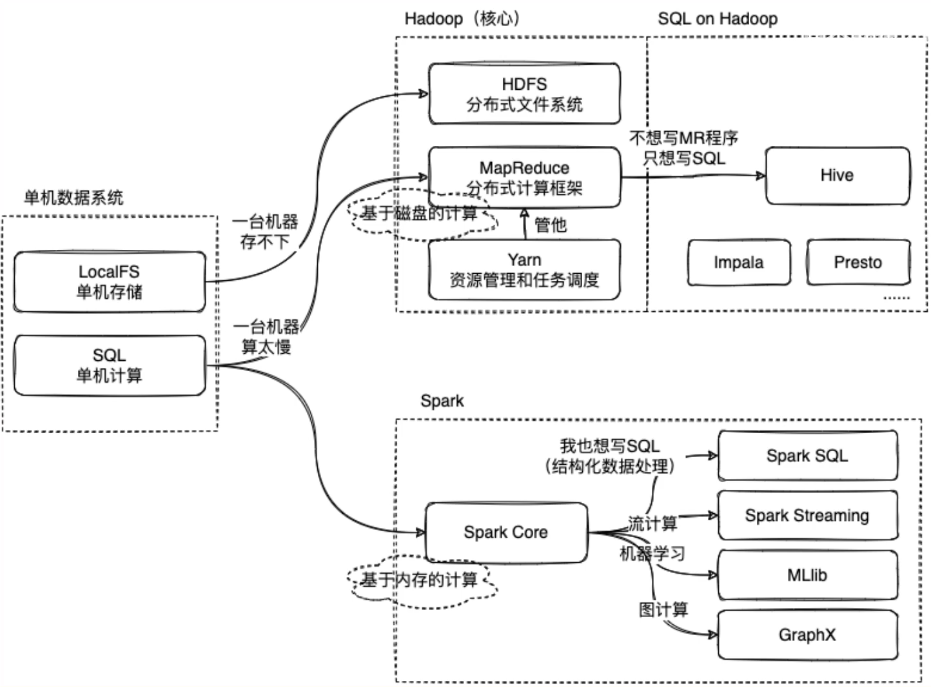
Hadoop 主要用于分布式存储和计算,而Hive和Spark则是建立在其上的更高层次的工具,旨在提高开发者的生产力并优化数据处理性能。这些技术共同构成了大数据生态系统的重要部分,帮助管理和分析海量数据。选择哪种技术取决于具体的应用需求、数据规模以及对处理速度的要求。
Spark基于Kubernetes部署优势
Spark是新一代分布式内存计算框架,Apache开源的顶级项目。相比于Hadoop Map-Reduce计算框架,Spark将中间计算结果保留在内存中,速度提升10~100倍;同时它还提供更丰富的算子,采用弹性分布式数据集(RDD)实现迭代计算,更好地适用于数据挖掘、机器学习算法,极大提升开发效率。
相比于在物理机上部署,在Kubernetes集群上部署Spark集群,具有以下优势:
快速部署:安装1000台级别的Spark集群,在Kubernetes集群上只需设定worker副本数目replicas=1000,即可一键部署。
快速升级:升级Spark版本,只需替换Spark镜像,一键升级。
弹性伸缩:需要扩容、缩容时,自动修改worker副本数目replicas即可。
高一致性:各个Kubernetes节点上运行的Spark环境一致、版本一致。
高可用性:如果Spark所在的某些node或pod死掉,Kubernetes会自动将计算任务,转移到其他nod或创建新pod。
强隔离性:通过设定资源配额等方式,可与Web、大数据应用部署在同一集群,提升机器资源使用效率,从而降低服务器成本。
spark-standalone框架
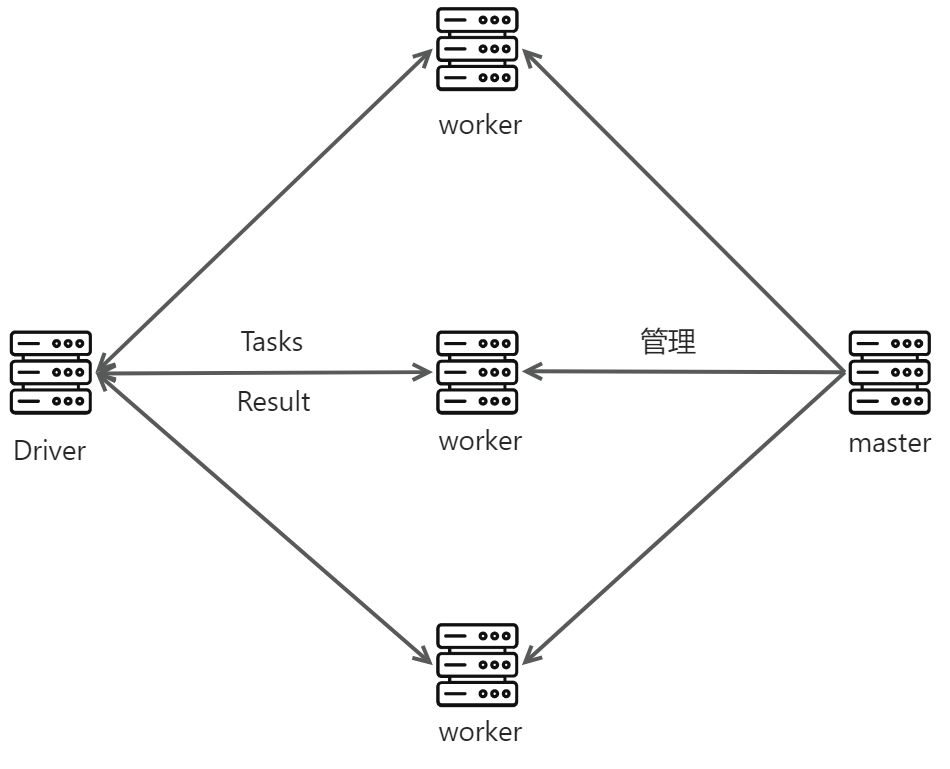
Client:客户端进程,负责提交作业到Master。
Master:Standalone模式中主节点,负责接收Cient提交的作业管理Worker,并命令Worker启动Driver和Executor。
Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver:一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上,包括DAGScheduler,TaskScheduler。
Spark提交任务的两种模式
- 客户端模式 (Client Mode):
- 在客户端模式下,提交 Spark 应用程序时,驱动程序会在提交任务的客户端机器上运行。
- 驱动程序不会作为集群的一部分运行,而是从客户端接收指令,并且客户端需要保持活动状态直到整个 Spark 应用程序执行完毕。
- 集群模式 (Cluster Mode):
- 在集群模式下,驱动程序将被部署到集群中的一个工作节点上运行。
- 驱动程序成为集群的一部分,并且不再依赖于提交任务的客户端机器。集群模式下,客户端提交完任务后就可以退出,而无需保持连接。
当使用 spark-submit 命令提交 Spark 应用程序时,可以通过添加 --deploy-mode 参数来指定提交模式。例如:
- 使用客户端模式:
spark-submit --deploy-mode client - 使用集群模式:
spark-submit --deploy-mode cluster
spark on k8s 的两种方式
1.Standalone on Kubernetes部署
spark以pod的形式运行在k8s里。
2.Spark 的原生 Kubernetes 调度
k8s只作为调度器和容器运行时,spark-submit命令执行后k8s调度pod执行计算,执行完pod自动释放
在 Kubernetes 上运行 Spark - Spark 3.5.1 文档 - Spark 中文 (apache.ac.cn)
Standalone on Kubernetes部署
Spark Standalone 集群中有Master和Worker两种角色,基于Kubernetes进行部署,即将两种对象以pod的方式部署到Kubernetes集群中,Master和Worker所需要的资源由Kubernetes集群提供。
构建镜像
Spark官方没有提供Spark的容器镜像,需要自己构建,构建Spark镜像的步骤如下:
1.下载Spark安装包
mkdir -p /root/spark && cd spark
wget https://mirrors.huaweicloud.com/apache/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
wget https://mirrors.huaweicloud.com/apache/hadoop/core/hadoop-3.1.4/hadoop-3.1.4.tar.gz
[root@master spark]# ls
hadoop-3.1.4.tar.gz spark-3.3.1-bin-hadoop3.tgz2.编写DockerFile
vim Dockerfile
FROM openjdk:8u151
ENV hadoop_version 3.1.4
ENV spark_version 3.3.1
ADD hadoop-3.1.4.tar.gz /opt
ADD spark-3.3.1-bin-hadoop3.tgz /opt
RUN mv /opt/hadoop-3.1.4 /opt/hadoop && mv /opt/spark-3.3.1-bin-hadoop3 /opt/spark && \
echo HADOOP ${hadoop_version} installed in /opt/hadoop && \
echo Spark ${spark_version} installed in /opt/spark
ENV SPARK_HOME=/opt/spark
ENV PATH=$PATH:$SPARK_HOME/bin
ENV HADOOP_HOME=/opt/hadoop
ENV PATH=$PATH:$HADOOP_HOME/bin
ENV LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
ADD start-common.sh start-worker start-master /
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ENV PATH $PATH:/opt/spark/bin
ENV SPARK_WORKER_MEMORY=1024m
ENV SPARK_WORKER_CORES=23.上传Dockerfile构建需要的文件
vim start-common.sh
#!/bin/sh
unset SPARK_MASTER_PORT
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/opt/hadoop/lib/nativevim start-master
#!/bin/sh
. /start-common.sh
echo "$(hostname -i) spark-master" >> /etc/hosts
/opt/spark/bin/spark-class org.apache.spark.deploy.master.Master --ip spark-master --port 7077 --webui-port 8080vim start-worker
#!/bin/sh
. /start-common.sh
if ! getent hosts spark-master; then
echo "=== Cannot resolve the DNS entry for spark-master. Has the service been created yet, and is SkyDNS functional?"
echo "=== See http://kubernetes.io/v1.1/docs/admin/dns.html for more details on DNS integration."
echo "=== Sleeping 10s before pod exit."
sleep 10
exit 0
fi
/opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077 --webui-port 8081vim spark-defaults.conf
spark.master spark://spark-master:7077
spark.driver.extraLibraryPath /opt/hadoop/lib/native
#spark.driver.extraClassPath /opt/spark/jars/hadoop-aws-2.8.2.jar:/opt/spark/jars/aws-java-sdk-1.11.712.jar
#spark.hadoop.fs.s3a.impl org.apache.hadoop.fs.s3a.S3AFileSystem
#spark.fs.s3a.connection.ssl.enabled false
#spark.executor.extraJavaOptions -Dcom.amazonaws.sdk.disableCertChecking=1
spark.app.id KubernetesSpark
spark.executor.memory 512m
spark.executor.cores 1添加权限
chmod +x ./start-common.sh ./start-master ./start-worker4.构建Spark容器镜像
执行如下命令,构建Spark容器镜像:
#构建spark 容器镜像
[root@master spark]# docker build -t myspark:v1 .
#查看spark 容器镜像
[root@master spark]# docker images
[root@master spark-standalone-deployment]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
myspark v1 fabd9ffaef9f 3 hours ago 3.12GB5.将镜像上传到 harbor
后续基于Kubernetes部署Spark standalone集群时需要使用该spark容器镜像,需要从harbor私有镜像仓库进行拉取,这里我们将myspark:v1镜像上传至Harbor私有镜像仓库,步骤如下:
#给当前镜像打标签
[root@master spark]# docker tag myspark:v1 192.168.86.218:8080/library/spark:v1
#上传到harbor
[root@master spark]# docker push 192.168.86.218:8080/library/spark:v1登录harbor观察对应的镜像是否上传成功,通过webui观察,上传已经成功。
配置containerd源(每个节点都要):
vim /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".registry.configs."192.168.86.218:8080".tls]
insecure_skip_verify = true
[plugins."io.containerd.grpc.v1.cri".registry.configs."192.168.86.218:8080".auth]
username = "admin"
password = "xxxxxxx"
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."192.168.86.218:8080"]
endpoint = ["http://192.168.86.218:8080"]yaml资源清单文件
创建/root/spark-standalone-deployment目录:
[root@master ~]# mkdir -p /root/spark-standalone-deployment
[root@master ~]# cd /root/spark-standalone-deployment/在该目录中创建如下yaml资源清单文件:
spark-master-controller.yaml:
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-master-controller
spec:
replicas: 1
selector:
component: spark-master
template:
metadata:
labels:
component: spark-master
spec:
hostname: spark-master-hostname
subdomain: spark-master-nodeport
containers:
- name: spark-master
image: 192.168.86.218:8080/library/spark:v1
imagePullPolicy: Always
command: ["/start-master"]
ports:
- containerPort: 7077
- containerPort: 8080
resources:
requests:
cpu: 100mspark-master-service.yaml:
kind: Service
apiVersion: v1
metadata:
name: spark-master-nodeport
spec:
ports:
- name: rest
port: 8080
targetPort: 8080
nodePort: 30080
- name: submit
port: 7077
targetPort: 7077
nodePort: 30077
type: NodePort
selector:
component: spark-master
---
kind: Service
apiVersion: v1
metadata:
name: spark-master
spec:
ports:
- port: 7077
name: spark
- port: 8080
name: http
selector:
component: spark-masterspark-worker-controller.yaml:
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-worker-controller
spec:
replicas: 2
selector:
component: spark-worker
template:
metadata:
labels:
component: spark-worker
spec:
containers:
- name: spark-worker
image: 192.168.86.218:8080/library/spark:v1
imagePullPolicy: Always
command: ["/start-worker"]
ports:
- containerPort: 8081
resources:
requests:
cpu: 100m部署yaml资源清单文件
通过以下命令进行部署以上yaml资源清单文件:
#部署yaml资源清单文件
[root@master spark-standalone-deployment]# kubectl create -f .
[root@master spark-standalone-deployment]# kubectl get pod
NAME READY STATUS RESTARTS AGE
spark-master-controller-rv4bw 1/1 Running 0 23m
spark-worker-controller-n82r8 1/1 Running 0 12m
spark-worker-controller-wmlxw 1/1 Running 0 23m
[root@master spark-standalone-deployment]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 28h
spark-master ClusterIP 10.68.33.230 <none> 7077/TCP,8080/TCP 24m
spark-master-nodeport NodePort 10.68.84.103 <none> 8080:30080/TCP,7077:30077/TCP 24m访问spark:IP:30080
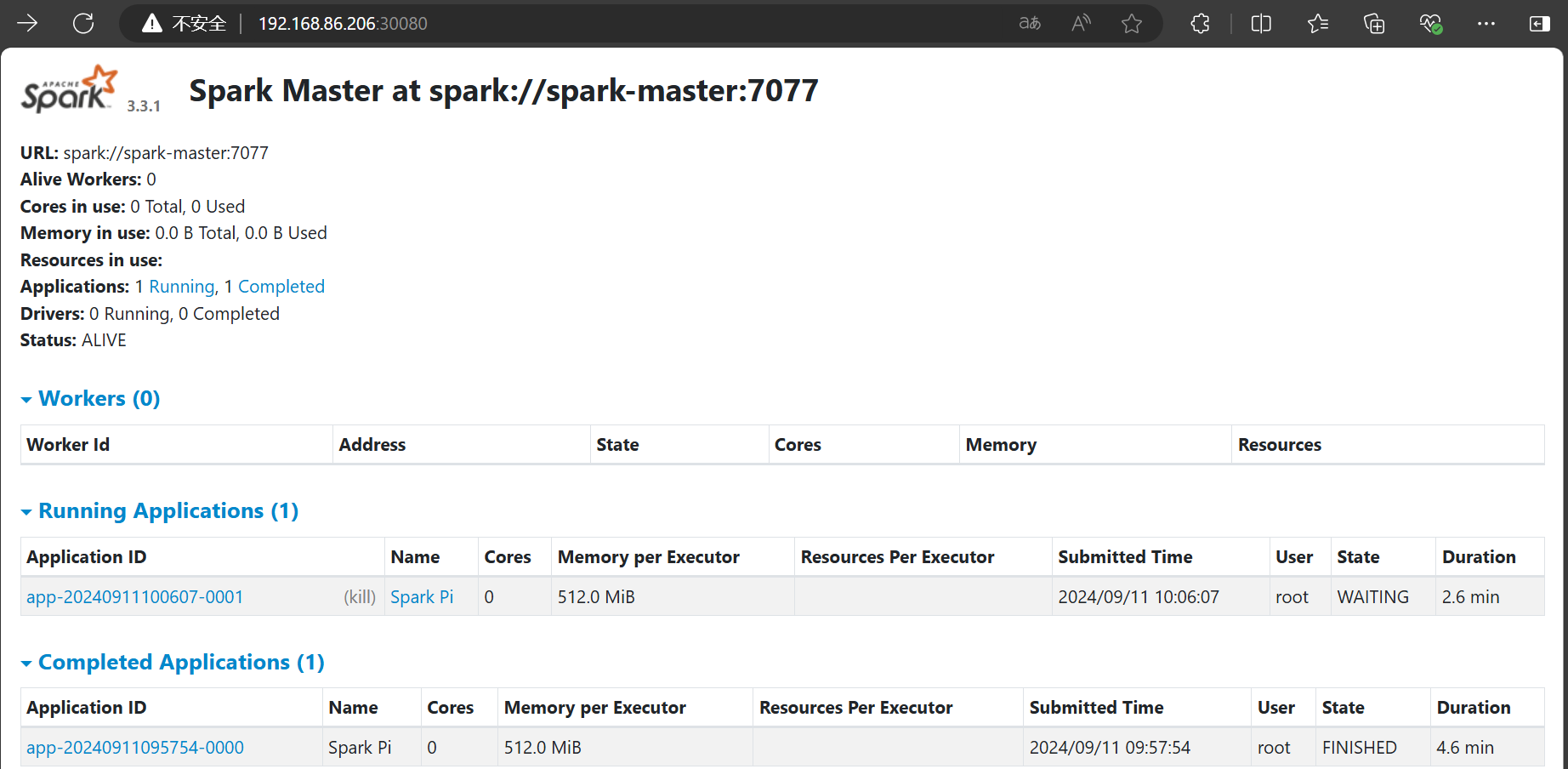
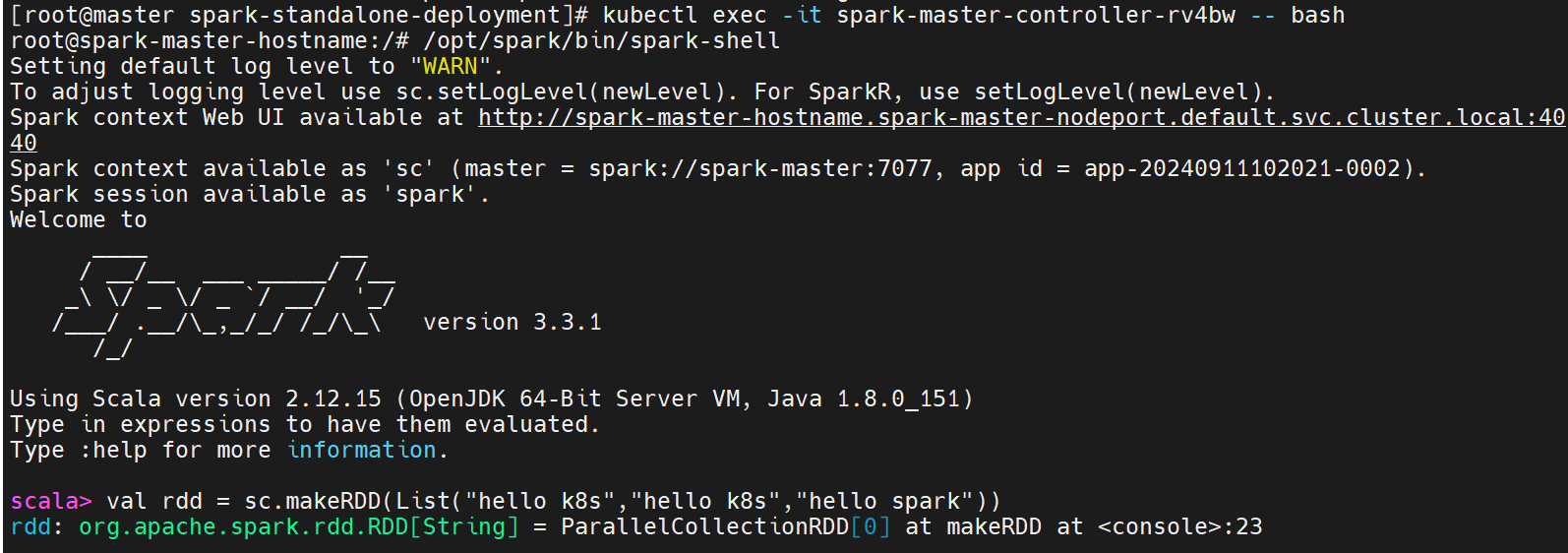
验证spark是否正常运行:
#进入容器,执行spark shell
[root@master ~]# kubectl exec -it spark-master-controller-rv4bw -- bash
root@spark-master-hostname:/# /opt/spark/bin/spark-shell
...
#编程scala代码进行测试
scala> val rdd = sc.makeRDD(List("hello k8s","hello k8s","hello spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at makeRDD at <console>:23
scala> rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
res0: Array[(String, Int)] = Array((spark,1), (k8s,2), (hello,3))
...
Spark 的原生 Kubernetes 调度部署
参考文档:在 Kubernetes 上运行 Spark - Spark 3.5.1 文档 - Spark 中文 (apache.ac.cn)
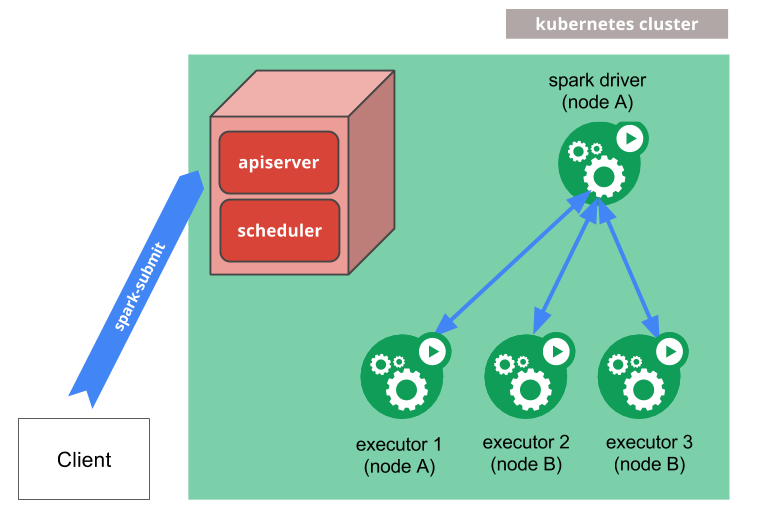
spark-submit 可以直接用于将 Spark 应用程序提交到 Kubernetes 集群。提交机制的工作原理如下
- Spark 创建一个在 Kubernetes Pod 中运行的 Spark 驱动程序。
- 驱动程序创建执行器,它们也运行在 Kubernetes Pod 中,并连接到它们,并执行应用程序代码。
- 当应用程序完成时,执行器 Pod 会终止并被清理,但驱动程序 Pod 会保留日志并保持在 Kubernetes API 中的“已完成”状态,直到它最终被垃圾回收或手动清理。
使用spark官方的脚本构建镜像并上传镜像到harbor
mkdir -p /opt/software
tar -xzvf spark-3.3.1-bin-hadoop3.tgz -C /opt/software
cd /opt/software/spark-3.3.1-bin-hadoop3/bin/
./docker-image-tool.sh -r 192.168.86.218:8080/library -t v2 build
docker login 192.168.86.218:8080 -uadmin -pAbc@1234
docker push 192.168.86.218:8080/library/spark:v2后续基于Kubernetes提交Spark任务时需要指定用户,Kubernetes是基于角色进行授权,所以这里创建对应的serviceaccount,然后给serviceaccount进行角色赋权。
#创建命名空间
[root@master ~]# kubectl create ns spark
namespace/spark created
#创建serviceaccount
[root@master ~]# kubectl create serviceaccount spark -n spark
serviceaccount/spark created
#给serviceaccount进行角色赋权
[root@master ~]# kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark
clusterrolebinding.rbac.authorization.k8s.io/spark-role created提交任务需要在节点上有Spark安装包,使用spark-submit命令进行任务提交。
cd /opt/software/spark-3.3.1-bin-hadoop3/bin/
[root@master ~]# cd /software/spark-3.3.1-bin-hadoop3/bin/
./spark-submit \
--master k8s://https://192.168.86.206:6443 \
--deploy-mode client \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.kubernetes.namespace=spark \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image=192.168.86.218:8080/library/spark:v2 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.driver.host=192.168.86.206 \
/opt/software/spark-3.3.1-bin-hadoop3/examples/jars/spark-examples_2.12-3.3.1.jar开启另外一个终端,可以查看到启动了两个pod,任务执行完后pod自动消失。
kubectl get all -n spark
spark spark-pi-cf4e8c91e429aa9a-exec-1 1/1 Running 0 30s
spark spark-pi-cf4e8c91e429aa9a-exec-2 1/1 Running 0 29s