Python数据分析 Pandas库-初步认识
Python数据分析 Pandas库-初步认识
认识Pandas
pandas是一个非常实用的Python工具,我们可以把它想象成一个超级强大的表格处理工具,它比Excel更智能,操作更为简单。pands可以从各种文件格式(CSV、JSON、SQL、Excel)中导入数据,可以对各类数据进行运算操作,还能对数据进行清洗和数据加工等特性。
pandas的用途
-
数据清洗:可以快速处理缺失值、重复数据和数据类型转换等问题。
-
数据操作:提供了灵活的数据操作功能,如数据筛选、排序、分组、汇总和合并等。
-
数据处理:支持对数据进行高效的行列操作,例如数据透视表、交叉表等。
-
数据分析:能够进行基本的统计分析和计算,如均值、中位数、标准差等,以及更复杂的数据分析任务。
-
数据导入导出:可以方便地从各种数据源(如CSV、Excel、SQL数据库等)导入数据,也能将数据导出到不同格式的文件中。
-
时间序列分析:提供强大的时间序列数据处理和分析功能,包括日期范围生成、时间偏移、频率转换等。
-
数据可视化:虽然
pandas本身不专注于可视化,但它可以与matplotlib或seaborn等库配合使用,进行数据可视化。
Pandas的数据结构:
series列的主要组成:
series:它是一种了类似一维数组或python中列表的一个对象,它具有一个索引标签,我们可以把它想象成一个带有标签的数组。

索引标签(Index):
- 作用:为每个数据元素提供一个标签,使得数据的访问和操作更加方便。
- 特性:索引标签可以是任何可哈希类型的数据,如整数、字符串等。索引可以是自定义的,也可以是默认的整数索引。
数据元素(Data):
- 作用:存储实际的数据值,可以是任何数据类型(整数、浮点数、字符串等)。
- 特性:数据元素可以通过索引标签进行访问、修改和操作。
主要功能
- 访问数据:通过标签或位置索引访问数据。
- 数据操作:支持各种操作,如算术运算、统计计算等。
- 数据清洗:可以处理缺失数据、重复数据等。
Series 是处理一维数据非常便利的工具,特别适合进行快速的数据操作和分析。
DataFrame
DataFrame : 它是一种表格类型的数据结构,组成它的对象是由多个series列组成一个二维的表。
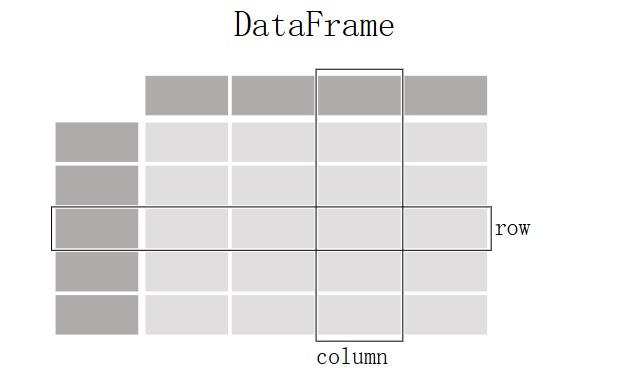
DataFrame的表结构
-
行和列:
DataFrame具有行和列,可以看作是一个二维的表格。每一列是一个Series对象。 -
标签:行和列都可以有标签。行标签是索引,列标签是列名。
DataFrame的列结构:
-
列数据:
DataFrame的每一列实际上是一个Series对象。每个Series对象有相同的行索引,但列标签不同。 -
类型一致性:虽然每列的
Series可以包含不同的数据类型,但每列内部的数据类型应该一致。
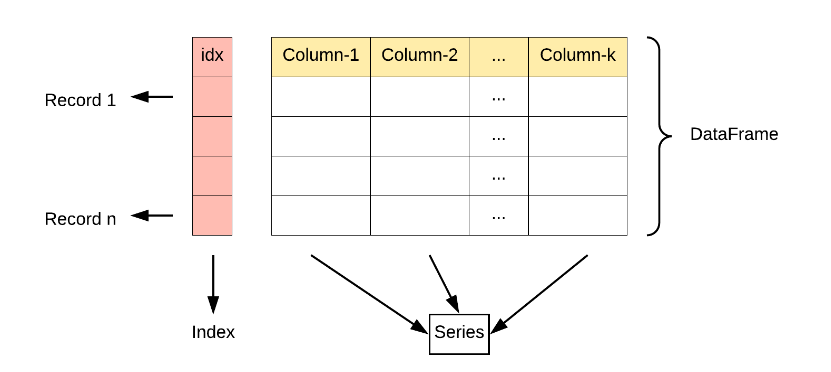
主要功能
- 数据选择:可以通过标签或位置索引选择特定的行和列。
- 数据处理:支持多种数据处理和转换操作,如添加/删除列、合并数据等。
- 数据分析:提供各种统计函数和数据聚合功能,便于数据分析。
- 数据导入/导出:可以轻松地从 CSV、Excel 等文件格式中读取数据,也可以将数据保存到这些格式中。