二叉树算法
1. 几种二叉树的概念
1.1. 满二叉树
所有节点都长满了叶子。
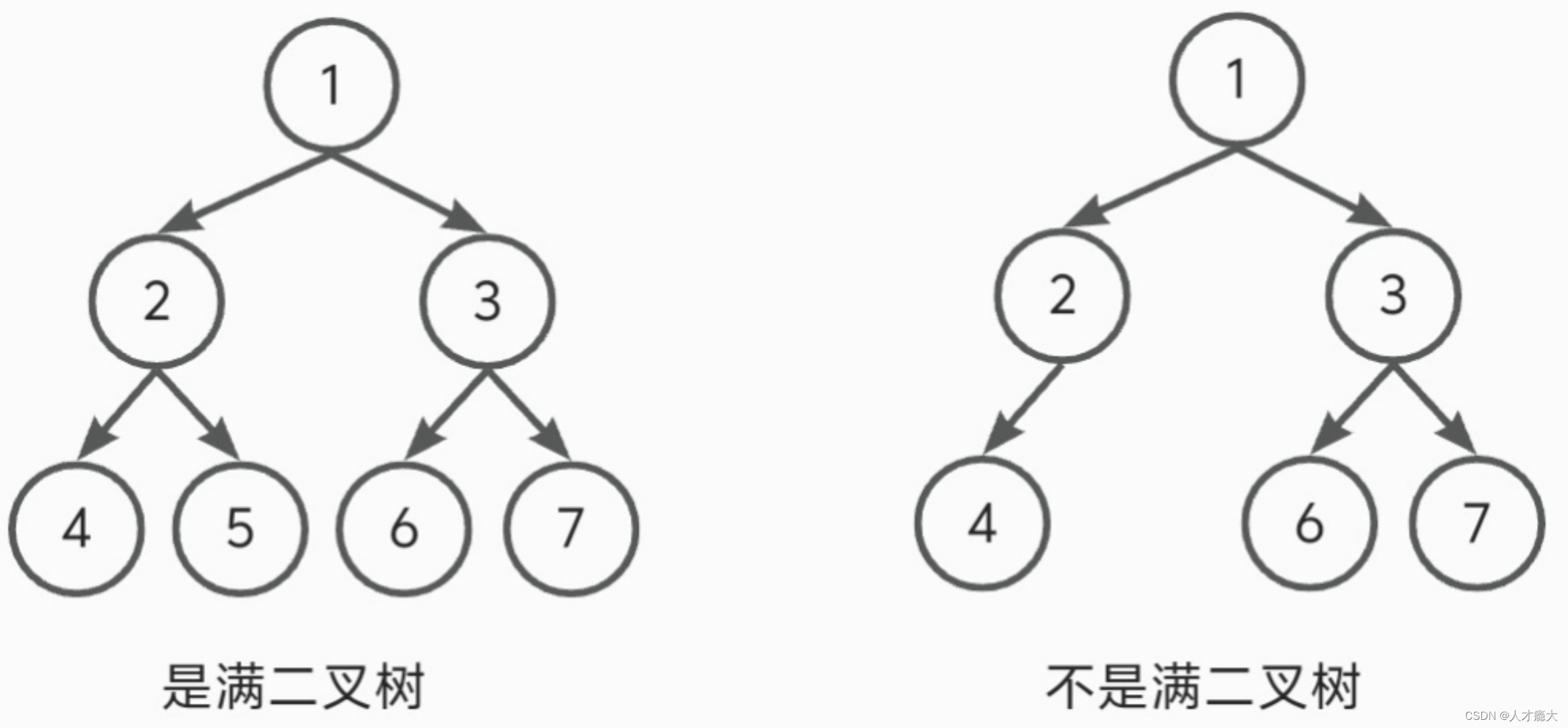
1.2. 完全二叉树
倒数第二层是满的,最后一层完全堆在左边。

1.3. 平衡二叉树(AVL树)
任意两个子树高度差不超过1的二叉树。

2. 表示树的底层结构
可以用数组或链表(有多个指针的链表)来表示树形结构。
2.1. 数组
使用数组的下标计算来确定某个节点的左右孩子和父。
- 如果数组用下标0来存根节点,则数组下标是i的节点,它的左孩子下标是i*2+1,右孩子下标是i*2+2,父节点下标是(i-1)/2,当然根节点的父节点要除外,因为这样算下来它的父节点下标是负数了。
- 如果数组用下标1来存根节点(下标0不用),则数组下标是i的节点,它的左孩子下标是i*2,右孩子下标是i*2+1,父节点下标是i/2,当然根节点的父节点要除外,因为这样算下来它的父节点下标是0了。
本文统一用数组下标1来存根节点的方式讨论。

因为要用null占位,表示树的结构,所以数组来存储树形结构比较浪费空间。如果是完全二叉树,它是靠左紧凑的,我们可以不用null来占位,如下图所示。

2.2. 链表
用一个节点对象表示树形结构上的一个节点,该节点中包含3个指针来存储一个其与父、左右孩子的关系。
用链表来存储树形结构,就不需要通过下标计算父、左右孩子的位置了,直接取指针就可以了。
3. 树的遍历
先总结一下,详细解释见下文:非递归的方式遍历,深度用栈、广度用队列。
3.1. 深度优先遍历(DFS)
整个遍历过程是从根节点开始,先打到左边底,再慢慢回到根部,再打到右边底。
根据遍历任何一个子树的时候,先遍历当前节点还是后遍历当前节点,可以分为先序、中序、后序3种遍历方式。

可以看到,不管哪种方式,右孩子都在左孩子之后遍历。
一般来说,这3种遍历方式都有递归和非递归两种方式来实现。
3.1.1. 递归实现3种深度优先遍历
递归实现树的深度优先遍历,是很直观的。
// 先序遍历
dfsPre(Node node){
visit(node);//先访问当前节点,再访问其左右子树
dfsPre(node.left);
dfsPre(node.right);
}// 中序遍历
dfsMid(Node node){
dfsMid(node.left);
visit(node);//先访问其左子树,再访问当前节点,再访问其右子树
dfsMid(node.right);
}// 后序遍历
dfsPost(Node node){
dfsPost(node.left);
dfsPost(node.right);
visit(node);//先访问其左右子树,再访问当前节点
}3.1.2. 非递归实现3种深度优先遍历
非递归方式需要使用栈结构来实现(递归方式本质是用了计算机程序自己的调用栈)。
非递归方式没有递归方式那么直观,可以说是用了3种思路分别实现的。它们3者的共同点有:
- 都要用栈
- 节点出栈时打印,出栈顺序代表打印顺序
- 先序和后序就是颠倒一下(用栈来颠倒,详见下文),代码大部分一样
3.1.2.1. 非递归的先序遍历
每次循环出栈一个节点。
上来先把头结点丢到栈里,然后开始循环出栈。
一次循环里面先放右节点再放左节点。
void pollVisitPre(Node node) {
if (node == null) return;
Stack<Node> stack = new Stack<>();
stack.push(node);
while (!stack.isEmpty()) {
Node c = stack.pop();
System.out.print(c.val + ",");
if (c.right != null) stack.push(c.right);//因为后打印right,所以先放right
if (c.left != null) stack.push(c.left);
}
}3.1.2.2. 非递归的中序遍历
先把左树全部入栈,然后一个个地弹出来打印,然后入栈右树。
可以把一棵二叉树想象成一个个的左子树的形式:

代码如下
void pollVisitMid(Node node) {
if (node == null) return;
Stack<Node> stack = new Stack<>();
while (node != null || !stack.isEmpty()) {
while (node != null) { // 这个while可以看做上图中的斜着的一列左子树
stack.push(node);
node = node.left;
}
node = stack.pop();
System.out.print(node.val + ",");
node = node.right;
}
}其中比较难以理解的是两个while的判断条件里都有 node != null 的条件。
3.1.2.3. 非递归的后序遍历
上面非递归的先序遍历中,左右孩子是右先进,所以左先打。如果改成左先进,就是右先打,然后在用一个栈把它的结果倒来打印,就是后续遍历了,思路如下图所示:

代码如下:
void pollVisitPost(Node node){
if(node == null) return;
Stack<Integer> savePrintResult = new Stack<>();//存储先序遍历时的出栈结果
Stack<Node> stack = new Stack<>();
stack.push(node);
while(!stack.isEmpty()){
node = stack.pop();
savePrintResult.push(node.val);//存储先序遍历时的出栈结果,待会儿打印
if(node.left!=null) stack.push(node.left);//先左进,所以会先打印右
if(node.right!=null) stack.push(node.right);
}
while(!savePrintResult.isEmpty()){//反向打印出来
System.out.print(savePrintResult.pop()+",");
}
}3.2. 广度优先遍历(BFS)
整个遍历过程是从根节点开始,一层一层地遍历。
3.2.1. 非递归的广度优先遍历
非递归的广度优先遍历比较简单明了,所以先介绍。
这种方式使用了队列,也是节点出来的时候打印,同时把它的左右孩子放到队列里,出来一个打印一个、放一对(左右孩子),直到队列为空。
void bfs(Node node) {
Queue<Node> queue = new LinkedList<>();
queue.add(node);
while (!queue.isEmpty()) {
Node n = queue.poll();
System.out.print(n.val + ",");
if (n.left != null) queue.add(n.left);
if (n.right != null) queue.add(n.right);
}
}3.2.2. 递归的广度优先遍历
思路是用一个List<List<>>的容器存储每一层的遍历结果,然后最后再打印出来。代码如下:
void recurseBfs(Node node){
List<List<Integer>> lists = new ArrayList<>();
doRecurseBfs(lists, 0, node);
for(List<Integer> list:lists){
for(Integer i:list){
System.out.print(i+",");
}
}
}
void doRecurseBfs(List<List<Integer>> lists, int i, Node node) {
if(node==null) return;
if(lists.size()==i){
lists.add(new ArrayList<>());
}
List<Integer> list = lists.get(i);
list.add(node.val);
doRecurseBfs(lists, i+1, node.left);
doRecurseBfs(lists, i+1, node.right);
}本文前面介绍的用数组存储的方式,其实是一种“广度优先”遍历后存下来的节点。如果不用广度优先,则位置i的左右孩子和父就不一定是2*i、2*i+1、i/2的关系了。
4. 树的序列化和反序列化
序列化就是把对象保存成字符串或二进制,反序列化就是把保存的字符串或二进制再转成内存里的对象。
4.1. 树的序列化
树的序列化需要记录下所有null节点(不然树的造型可能会变)如下图所示

如果是完全二叉树,可以不记录null节点。
序列化的过程跟前面遍历过程一致,只是把前面打印和返回空节点的地方,改成用字符串存起来(返回的空节点用"null"存储)。
StringBuilder serializeNode(Node node) {
if (node == null) {
return new StringBuilder("null");
} else {
return new StringBuilder(node.val + "");
}
}下面给一个先序遍历方式序列化的示例代码(递归、非递归,先/中/后序都有对应的序列化代码):
StringBuilder serializeTreePre(Node node) {
if (node == null) {
return serializeNode(null);
}
return serializeNode(node).append(",")
.append(serializeTreePre(node.left)).append(",")
.append(serializeTreePre(node.right));
}再给一个广度优先的序列化的示例代码(这里用非递归方式,递归方式也可以实现):
StringBuilder serializeTreeBfs(Node node) {
if (node == null) {
return serializeNode(null);
}
StringBuilder sb = new StringBuilder();
Queue<Node> queue = new LinkedList<>();
queue.add(node);//广度优先的架子
while (!queue.isEmpty()) {//广度优先的架子
node = queue.poll();//广度优先的架子
sb.append(serializeNode(node)).append(",");
if (node != null) queue.add(node.left);//这里注意,空孩子也要丢到队列里输出
if (node != null) queue.add(node.right);
}
return sb;
}4.2. 树的反序列化
树的反序列化要与序列化方式对应起来用,比如用先序遍历序列化的,就要用先序遍历反序列化、用广度优先序列化的,就要用广度优先反序列化来还原。
树的反序列化都要用到队列,从队列里一个个地poll出来,构造树的节点。
4.2.1. 深度优先反序列化
直接上代码,先序遍历的反序列化(中序、后序类似)
Node deserializeTreePre(String txt) {
return doDeserializeTreePre(new LinkedList<>(Arrays.asList(txt.split(","))));
}
Node doDeserializeTreePre(Queue<String> queue) {
if (queue.isEmpty()) return null;
String val = queue.poll();
if (val.equals("null")) {
return null;
}
Node n = new Node(Integer.parseInt(val));//先序,先处理当前节点
Node left = doDeserializeTreePre(queue);//再处理左、右孩子
Node right = doDeserializeTreePre(queue);
// 把3个节点连起来
n.left = left;
n.right = right;
if (left != null) left.parent = n;
if (right != null) right.parent = n;
return n;
}4.2.2. 广度优先反序列化
广度优先反序列化,也是广度优先遍历的过程,所以需要一个广度优先遍历的队列,加上反序列化用于存储字符串的那个队列,就有两个队列了。
代码如下,跟广度优先遍历过程的架子是一样的:
Node deserializeTreeBfs(String txt) {
Queue<String> strQueue = new LinkedList<>(Arrays.asList(txt.split(",")));
if(strQueue.isEmpty()||strQueue.peek().equals("null")) return null;
Queue<Node> resultQueue = new LinkedList<>(); //广度优先遍历的队列
Node head = new Node(Integer.parseInt(strQueue.poll()));
resultQueue.add(head); //与广度优先遍历架子一样
while(!resultQueue.isEmpty()){//广度优先的架子
Node n = resultQueue.poll();//广度优先的架子
String leftStr = strQueue.poll();
String rightStr = strQueue.poll();
if(!"null".equals(leftStr)){
Node left = new Node(Integer.parseInt(leftStr));
n.left = left;
left.parent = n;
resultQueue.add(left);
}
if(!"null".equals(rightStr)){
Node right = new Node(Integer.parseInt(rightStr));
n.right = right;
right.parent = n;
resultQueue.add(right);
}
}
return head;
}