【机器学习】分类与回归——掌握两大核心算法的区别与应用
【机器学习】分类与回归——掌握两大核心算法的区别与应用
1. 引言
在机器学习中,分类和回归是两大核心算法。它们广泛应用于不同类型的预测问题。分类用于离散的输出,如预测图像中的对象类型,而回归则用于连续输出,如预测房价。本文将深入探讨分类与回归的区别,并通过代码示例展示它们在实际问题中的应用。

2. 什么是分类?
分类问题指的是将输入数据分配到预定义的离散类别中。常见的分类任务包括垃圾邮件检测、手写数字识别等。
分类的特征:
- 输出为离散值:即数据属于某个特定类别。
- 常用算法:如逻辑回归、支持向量机、决策树、随机森林、KNN等。
示例:逻辑回归(Logistic Regression)用于分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练逻辑回归模型
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
print(f"分类准确率: {accuracy_score(y_test, y_pred)}")

3. 什么是回归?
回归问题指的是预测一个连续的数值输出。常见的回归任务包括房价预测、股票价格预测等。
回归的特征:
- 输出为连续值:即预测结果是一个具体数值。
- 常用算法:如线性回归、决策树回归、支持向量回归(SVR)、Lasso回归等。
示例:线性回归(Linear Regression)用于回归
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse}")
4. 分类与回归的区别
1. 输出类型不同:
- 分类:输出为离散类别,例如[0, 1],或者多类别如[猫, 狗, 鸟]。
- 回归:输出为连续的数值,例如预测房价为250,000元。
2. 评估指标不同:
- 分类常用指标:准确率(Accuracy)、混淆矩阵、ROC曲线、F1分数等。
- 回归常用指标:均方误差(MSE)、均方根误差(RMSE)、R²等。
3. 模型不同:
- 分类:常用的模型如逻辑回归、KNN、支持向量机等。
- 回归:常用的模型如线性回归、岭回归、支持向量回归等。

5. 常见的分类算法
1. K 近邻算法(K-Nearest Neighbors, KNN)
KNN 是一种基于距离的分类算法,通过找到与输入数据最近的K个样本来进行分类。
KNN 示例代码:
from sklearn.neighbors import KNeighborsClassifier
# 训练 KNN 模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# 预测与评估
y_pred_knn = knn.predict(X_test)
print(f"KNN 分类准确率: {accuracy_score(y_test, y_pred_knn)}")
2. 支持向量机(SVM)
SVM 是一种分类算法,它通过找到一个超平面,将数据点划分到不同的类别中。
SVM 示例代码:
from sklearn.svm import SVC
# 训练 SVM 模型
svm = SVC(kernel='linear')
svm.fit(X_train, y_train)
# 预测与评估
y_pred_svm = svm.predict(X_test)
print(f"SVM 分类准确率: {accuracy_score(y_test, y_pred_svm)}")
6. 常见的回归算法
1. 决策树回归(Decision Tree Regressor)
决策树是一种基于树形结构的回归算法,通过递归划分特征空间来预测目标值。
决策树回归示例代码:
from sklearn.tree import DecisionTreeRegressor
# 训练决策树回归模型
tree = DecisionTreeRegressor()
tree.fit(X_train, y_train)
# 预测与评估
y_pred_tree = tree.predict(X_test)
print(f"决策树均方误差: {mean_squared_error(y_test, y_pred_tree)}")
2. 支持向量回归(SVR)
SVR 是支持向量机的回归版本,通过找到一个使得预测误差最小的超平面来进行回归预测。
SVR 示例代码:
from sklearn.svm import SVR
# 训练支持向量回归模型
svr = SVR(kernel='linear')
svr.fit(X_train, y_train)
# 预测与评估
y_pred_svr = svr.predict(X_test)
print(f"SVR 均方误差: {mean_squared_error(y_test, y_pred_svr)}")
7. 如何选择分类或回归算法?
- 数据的输出类型:首先根据输出是离散值还是连续值选择分类或回归算法。
- 数据的规模与维度:不同的算法对数据规模和维度有不同的处理效果,如 SVM 适用于高维数据,而线性回归适用于低维数据。
- 计算资源:一些复杂的算法如支持向量机和神经网络需要大量计算资源,而简单的模型如线性回归和 KNN 相对较快。

8. 应用案例
案例1:使用逻辑回归预测是否为高收入人群
from sklearn.datasets import fetch_openml
# 加载收入数据集
income_data = fetch_openml('adult', version=1)
X = income_data.data
y = income_data.target
# 预处理数据并进行训练和预测
# 省略具体代码,类似于上面的逻辑回归步骤
案例2:使用线性回归预测房价
# 加载房价数据并应用线性回归模型预测
# 类似上面展示的线性回归示例
9. 总结与未来展望
分类和回归是机器学习中两类基本问题,它们分别解决了离散输出和连续输出的预测需求。通过理解二者的区别和实际应用,你可以更好地解决不同类型的预测问题。未来,随着数据集的增长和算法的优化,分类与回归算法将继续在各个领域中发挥重要作用。
10. 参考资料
- 《机器学习实战》 by Peter Harrington
- Scikit-learn 官方文档
使用机器学习分析CSDN热榜
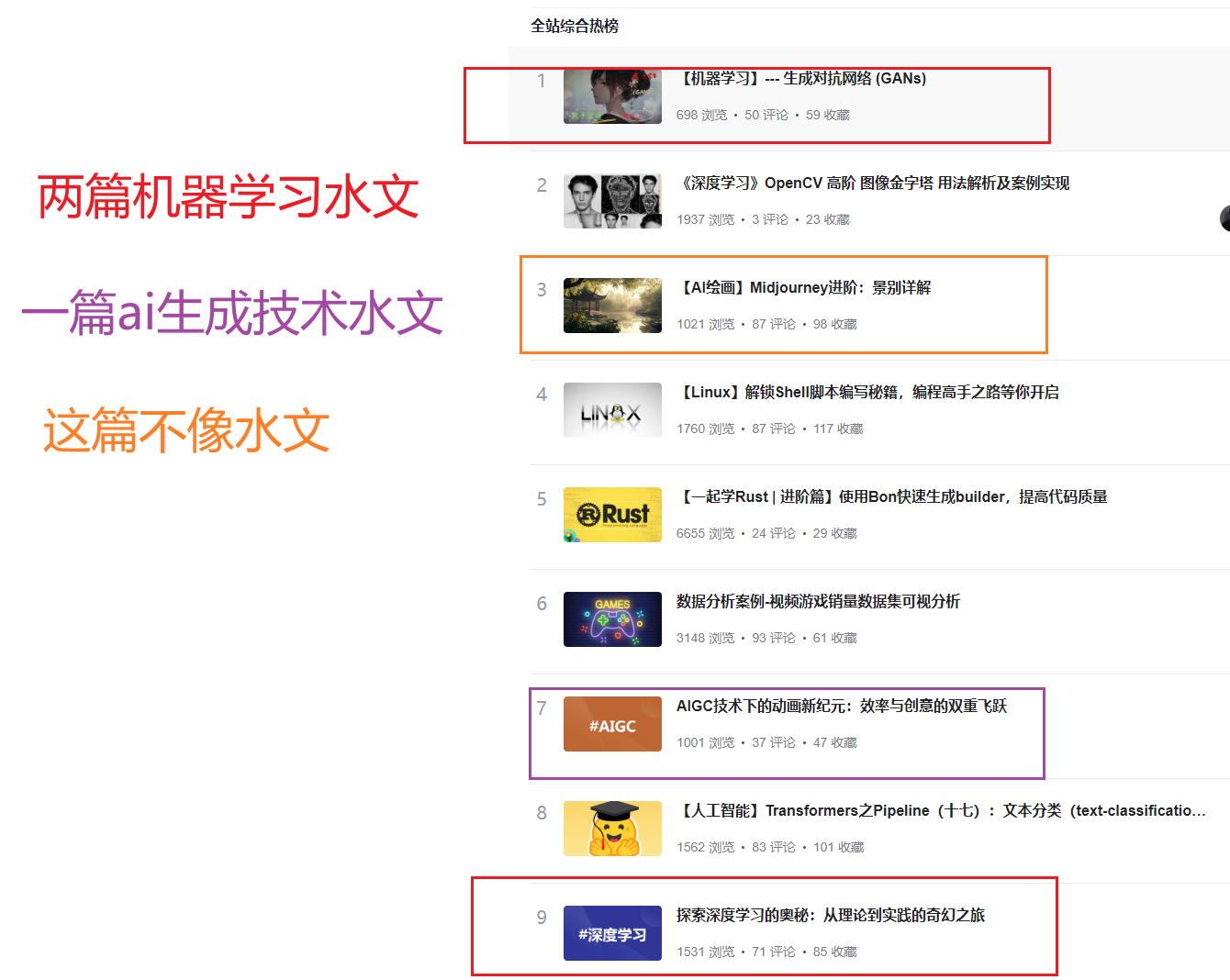
- 也不知道是不是错觉,感觉机器学习水文好像在逐渐变少。那种没有代码,只介绍几个百度就能搜到概念的机器学习水文正在逐渐变少。
- 博主目前见到机器学习最猖狂的时候,是热榜前十中六篇都是机器学习水文,而且都是一点进去就知道不是人写得那种机生文 。让人感觉CSDN药丸

你好,我是Qiuner. 为帮助别人少走弯路而写博客 这是我的 github https://github.com/Qiuner⭐ gitee https://gitee.com/Qiuner 🌹
如果本篇文章帮到了你 不妨点个赞吧~ 我会很高兴的 😄 (^ ~ ^) 。想看更多 那就点个关注吧 我会尽力带来有趣的内容 😎。
代码都在github或gitee上,如有需要可以去上面自行下载。记得给我点星星哦😍
如果你遇到了问题,自己没法解决,可以去我掘金评论区问。私信看不完,CSDN评论区可能会漏看 掘金账号 https://juejin.cn/user/1942157160101860 掘金账号
更多专栏:
📊 一图读懂系列
📝 一文读懂系列
⚽ Uniapp
🌟 持续更新
🤩 Vue项目实战
🚀 JavaWeb
🎨 设计模式
📡 计算机网络
🎯 人生经验
🔍 软件测试
掘金账号 CSDN账号
感谢订阅专栏 三连文章