xml重点笔记(尚学堂 3h)
XML:可扩展标记语言
主要内容(了解即可)
1.XML介绍
2.DTD
3.XSD
4.DOM解析
6.SAX解析
学习目标
一. XML介绍
1.简介
XML(Extensible Markup Language) 可扩展标记语言,严格区分大小写
2.XML和HTML
XML是用来传输和存储数据的。
XML多用在框架的配置文件中
XML大多平台都支持,所以可以实现跨平台数据传输
HTML是用来显示数据的
3.XML的引入
XML的引入:
保存5个学生对象的信息(持久化保存)
A、保存数组/集合====>内存中当项目重启后我们保存到内存中数据就会丢失
B、使用IO流保存到文件中优点:实现数据的持久化保存缺点:保存数据比较麻烦,并且保存的对象值我们看不懂
C、使用XML进行数据的保存
[1]进行数据的存储(数据存储的功能就在这个阶段使用,以后不用xmL进行数据存储)
[2]在我们后期学习(javaEE/框架)中充当配置文件
D、数据库(最终数据存储位置)
4.语法
<元素名 属性名=“属性值”>文本内容</元素名>。
前后元素名相同,元素名自定义。
每个元素可以有0到多个属性,属性名自定义。
文本内容表示文字。
支持嵌套结构。
结束时元素名前有/。
5.语法要求
XML的语法和HTML语法是差不多的,但是比HTML要求更加严格。
1.元素正确嵌套
2.XML文件的第一行必须是xml声明
3.只能有一个根节点
4.严格区分大小写
5.结束标签必须包含/
6.属性值的设置必须被包围起来
7.XML认为换行标记也属于文本节点
8.<!---->注释。有的非官方资料认为这是注释节点。
<?xml version="1.0" encoding="utf-8"?> <!--文档头,声明版本和编码 -->
<students> <!--在xml中只可以定义一个根节点,并且是一个双标签-->
<student id="1"> <!--属性节点-->
<name>张三</name>
<age>12</age> <!--元素节点-->
<score>88</score><!-- 文本内容/文本值节点-->
</student>
<student id="2">
<name>李四</name>
<age>13</age>
<score>99</score>
</student>
</students>
6.特殊符号
6.1 实体符号
| 字符实体 | 特殊字符 | 含义 |
|---|---|---|
| &It | < | 小于 |
| > | > | 大于 |
| & | & | 和号 |
| &apos | ’ | 单引号 |
| " | " | 双引号 |
6.2 转义标签
<font style='color:blue'> <![CDATA[要打印内容]] </font>
二,小节实现案例-编写XML文件
1.需求
项目根路径下创建product.xml并存储下面信息。
根节点叫做products,里面包含3个product元素。每个元素里面又包含下面的元素及文本内容

2.实现
<?xml version="1.0" encoding="utf-8" ?> <!--xml的文档声明-->
<products>
<product>
<id>P001</id>
<name>蜘蛛王皮鞋</name>
<price>268</price>
<color>黑色</color>
<size>42</size>
<num>500</num>
</product>
<!-- ... -->
</products>
三.DTD(约束)
1.简介
DTD(Document Type Definition) 文档类型定义。
即约束XML文件中可以包含哪些元素、哪些属性、及元素个数和元素之间的关系和元素的顺序。
在包含DTD的XML文件中,如果XML内容不满足DTD要求,会提示错误。
2.分类
DTD的三种分类:
1.内部DTD
2.外部DTD
3.公共DTD
2.1内部DTD
直接在XML中编写DTD内容。不推荐。
- <!ELEMENT元素名(包含内容)>内容可以是其他标签,也可以是#PCDATA文本内容。
- <!ATTLIST元素名属性名CDATA内容控制>定义属性
- 内容控制可取值:
- #REQUIRED必须有这个属性
- #IMPLIED可以有也可以没有
3. #FIXED“内容”必须取固定值
-
(name,age,score)表示顺序必须是先name,后age,然后score
-
student+表示student至少出现一次。括号内容的元素名都可以跟下面符号
1.?表示子元素出现0次到1次(最多出现一次)2.+表示子元素至少出现一次(至少出现一次)
3.*表示子元素可以出现0到多次(任意)
<?xml version="1.0" encoding="UTF-8"> <!--声明xm1文档头
<!-- 内部DTD约束 -->
<!--
!DOCTYPE: 固定语法文档类型
students: 自定义根标签名字
[]: 存放子标签
ELEMENT: 元素(标签)
#PCDATA:元素是字符串类型#PCDATA(不能再有子元素,也不能为空)
DTD中标签的顺序就是日后使用的顺序,不允许改变
-->
<!DOCTYPE students [
<!-- 标签 -->
<!--
(student): 只能有一对student标签
(student?): 0~1次
(student+): 至少1次
(student*): 0~多次
-->
<!ELEMENT students (student*)>
<!ELEMENT student (name, age, sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT SeX (#PCDATA)>
<!--属性-->
<!--
ATTLIST: 属性
student: 哪个标签指定属性
id: 指定的属性名
CDATA: 属性控制
#REQUIRED: 必须有
#FIXED“值": 固定值
#IMPLIED: 可有可无
-->
<!ATTLIST student id CDATA #REQUIRED>
<!ATTLIST name class CDATA #FIXED"qwe">
<!ATTLIST age test CDATA #IMPLIED>
]>
<students>
<student id="aa">
<name class="qwe">张三</name>
<age test="aaa">18</age>
<sex>男</sex>
</student>
</students>
2.2外部DTD(项目配置文件来源于此!!!)
外部DTD是我们自己编写的DTD文件。通过引I入方式引I入DTD。
在外部创建一个xxx.dtd文件,文件内容和内部dtd[]中的内容相同。
1.新建dtd文件
<!ELEMENT students (student*)>
<!ELEMENT student (name,age,sex)>
<!ELEMENT name(#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT SeX(#PCDATA)>
<!ATTLIST student id CDATA #REQUIRED>
<!ATTLIST name class CDATA #FIXED "qwe">
<!ATTLIST age test CDATA #IMPLIED>
2.xml引入外部dtd文件
<?xml version="1.0" encoding="uTF-8" ?>
<!DOCTYPE students SYSTEM "aa.dtd">
<students>
<student id="aa"
<name class="qwe">张三</name>
<age test="aaa">18</age>
<sex>男</sex>
</student>
</students>
2.3公共DTD
公共DTD是一些开源组织编写的DTD,并且已经发布到互联网中。
公共DTD语法:
< !DOCTYPE 根元素 PUBLIC “DTD标识名” “公用DTD的URI”>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
3, 总结
DTD是较简单的语法检查机制。整体语法较简单,功能较单一。
当需要对XML文件结构更新时,需要修改整个DTD文件,不够灵活。
四, XSD
1.简介
XSD(XML Schema Definition)XML模式定义。
属于DTD的升级版。完美的解决了DTD使用时不易扩展问题,并且提供了更强大功能。
2.定义XSD
新建xxx.xsd。
所有需要的元素,属性都需要被定义。
<!--
声明xsd约束
aa: 自定义名称(随意)
schema: 约束(固定)
-->
<aa:schema xmlns:aa="http://www.w3.org/2001/XMLSchema">
<!--
aa:element: 标签
name: 标签名
-->
<aa:element name="students">
<!--必须设置为复杂类型-->
<aa:complexType>
<!--在此标签中规范了标签的顺序
<aa:sequence>
<!--引用其他标签 -->
<!--maxoccurs: 指定可以有多少个标签-->
<aa:element ref="student"maxoccurs="2"/>
</aa:sequence>
</aa:complexType>
</aa:element>
<aa:element name="student">
<!--复杂类型可以指定 包含的标签 属性-->
<aa:complexType>
<aa:sequence>
<!--type: 值的类型-->
<aa:element name="name" type="aa:string"/>
<aa:element name="age" type="aa:int"/>
<aa:element name="sex" type="aa:boolean"/>
</aa:sequence>
<!--
use:属性的设置
required: 必须存在
prohibited: 禁用
optional: 可选的
fixed="值": 固定值
-->
<aa:attribute name="id" use="optional" fixed="aa"/>
</aa:complexType>
</aa:element>
3.引用xsd
<?xml version="1.0" encoding="uTF-8" ?>
<students xm1ns:xsi="http://www.w3.org/2001/xMLSchema-instance"
xsi:noNamespaceSchemaLocation="s.xsd">
<student id="aa">
<name></name>
<age>11</age>
<sex>false</sex>
</student>
</students>
五.XML 解析
1.简介
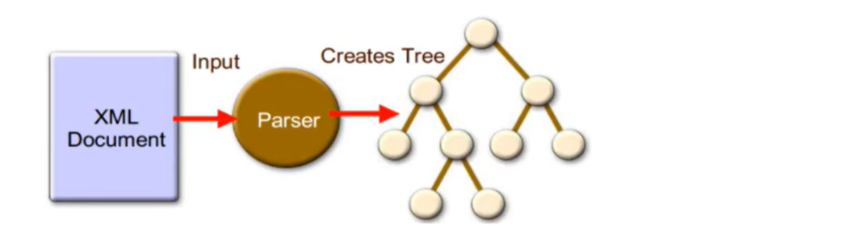
在Java中提供了两种XML解析方式: DOM、SAX。
2.DOM解析
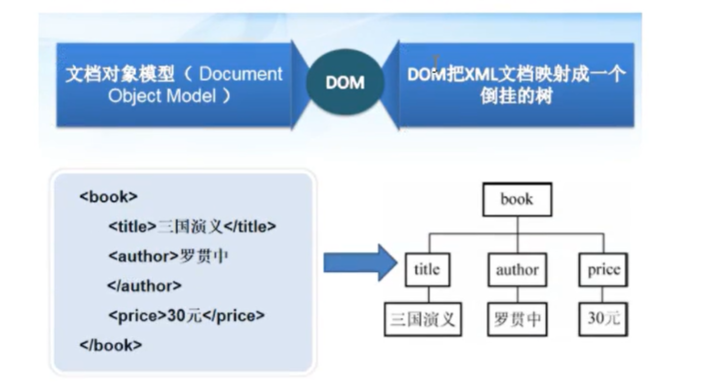
Document Object Model文档对象模型。把XML文件一次性加载到内存中,并转换为树状模型。然后一个节点一个节点的解析,这种解析方式效率较高,但是比较消耗内存,适用于小型XML文档。
3.SAX(Spring)
SAX(SimpleAPIforXML)解析:是基于事件的解析,它是为了解决DOM解析的资源耗费而出现的。SAX在解析一份XML文档时,会依次出发文档开始、元素开始、元素结束、文档结束等事件,应用程序通过监听解析过程中所触发的事件即可获取XML文档的内容。该方式不需要事先调入整个文档,优势是占用资源少,内存消耗小,一般在解析数据量较大的文档是采用该方式。
六.DOM解析
1.简介
DOM解析所有API都是org.w3c包中。
使用DOM操作XML按照标准树状结构一层一层解析。
解析器是基于工厂设计模式的。当获取到文档对象后每个元素都是一个节点,然后操作节点对象。
在DOM解析时,每个换行符都是一个文本节点,所以一定要过滤掉换行。
2.代码示例
以上面的students作为xml进行解析。
已知XML文件就三层结构,所以直接使用循环进行解析。如果XML文档结构比较深,此处需要使用递归。
public class TestDoM {
public static void main(String[] args) throws Exception {
parse();
}
//使用DoM解析XML
public static void parse() throws ParserConfigurationException, IoException, SAXException {
//1.获取document构建 工厂对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//2.根据文档构建工厂获取文档构建对象
/* 将xm1变为document
* 手动的创建document
**/
DocumentBuilder db = dbf.newDocumentBuilder();
//3.使用文档构建对象,将xm1解析为document对象
Document document = db.parse(new File("stu.xm1"));
//4.根据标签名获取跟标签
NodeList rootList = document.getElementsByTagName("students");
//5.xm1中仅会存在一个跟标签,获取这个根标签
Node root = rootList.item(0);
System.out.print1n ("根节点名称: " + root.getNodeName();
//6.获取标签所有的直接子节点
NodeList chi1dNodes = root.getChi1dNodes();
for (int i = 0; i < childNodes.getLength(); i++){
//7.获取每一个子节点
/*
* getNodeType(): 结点类型,常量
* 1: 标签结点
* 2: 属性结点
* 3: 文本结点
**/
Node item = childNodes.item(i);
if (item.getNodeType() == Node.ELEMENT_NODE) {
System.out.println("子节点名称: " + item.getNodeName());
//8.获取该结点的所有子节点
NodeList childNodes1 = item.getChildNodes();发送
for(int j = 0; j < childNodes1.getLength(); j++) {
Node item1 = childNodes1.item(j);
if (item1.getNodeType() == Node.ELEMENT_NODE) {
System.out.println("子节点名称: " + item1.getNodeName() + ":" + item1.getTextContent()));
}
}
}
}
}
}
七.使用DOM生成XML
1.简介
DOM生成XML时主要是创建节点。然后把节点添加到上层节点。
2.代码示例
public class TestDoM {
public static void main(String[] args)throws Exception {
transform();
}
//先构建文档,再将文档变为xml
public static void transform throws ParserConfigurationException, TransformerException, FileNotFoundException{
//1.获取文档构建器工厂对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//2.构建器工厂对象 获取 构建器对象
DocumentBuilder db=dbf.newDocumentBuilder();
//3.创建文档对象
Document document=db.newDocument();
//4.创建teachers标签
Element teachers=document.createElement("teachers");
//5.创建teacher标签
Element teacher =document.createElement("teacher");
teacher.setAttribute("id","tea");//设置属性
//6.创建name标签
Element name =document.createElement("name");
name.setAttribute("class", "na"); // 设置属性
name.setTextContent("zs");
//7.创建age标签
Element age = document.createElement("age");
age.setTextContent("18");
//8.创建sex标签
Element sex = document.createElement("sex");
sex.setTextContent("男");
//9.设置标签之间的关系
//添加teacher的子标签*
teacher.appendchild(name);
teacher.appendchild(age);
teacher.appendchild(sex);
}
}
八.SAX解析
1.简介
SAX解析是基于事件模型完成的。所有的API都在org.Xml中。
SAX解析时也会识别换行为文本节点,这个坑一定躲避。
2.代码示例
public class TestSAX {
public static void main(String[] args) throws Exception {
parse();
}
public static void parse() throws Exception {
//1.SAX解析器工厂对象
SAXParserFactory spf = SAXParserFactory.newInstance();
//2.基于工厂对象获取解析器对象
SAXParser sp = spf.newSAxParser();
//3.使用解析器解析xml
sp.parse(new File("java_day13/teacher.xm1"),new MyHandler());
}
public class MyHandler extends DefaultHandler {
String name = null;
@override
public void startDocument() throws SAXException {
System.out.print1n("文档开始解析");
}
@override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("开始解析,标签名: " + qName);
name = qName;
}
@Override
}
}
九, SAX生成
1.简介
SAX生成XML和手写XML比较相似。
也是在调用5个操作方法。
2.代码生成
public class TestSAX {
public static void main(String[] args) throws Exception {
parse();
}
public void transfom() throws TransformerConfigurationException, FileNotFoundException,SAxException {
//1.创建转换器工厂
SAXTransformerFactory stff =(SAXTransformerFactory) SAXTransformerFactory.newInstance();
//2.根据工厂获取转换器
/*
*传输
*创建xml
**/
TransformerHandler th = stff.newTransformerHandler();
Transformer transformer = th.getTransformer();
transformer.setOutputProperty(OutputKeys.INDENT,"yes");
transformer.setOutputProperty(OutputKeys.ENcoDING,"utf-8");
transformer.setoutputProperty("{http://xml.apache.org/xslt}indent-amount","2");
th.setResult(new StreamResult(new FileoutputStream("stu.xml")));
th.startElement(null,null,“students",null);
AttributesImpl attributes = new AttributesImpl();
attributes.addAttribute(null,null,“id",null,“aa");
th.startElement(null,null,"student",attributes);
th.startElement(null, null, "name", null);
char[] chars = "zs".tocharArray();
th.characters(chars,0,chars.length);
th.endElement(null, null, "name");
th.startElement(null, null, “"age", null1);
char[] chars1 = "19".toCharArray();
th.characters(chars1,0,chars1.1ength);
th.endElement(null, null, "age");
th.startElement(null, null, “sex", null);
char[] chars2 ="男".tocharArray();
th.characters(chars2,0,chars2.length);
th.endelement(null, null,"sex");
th.endElement(null,null,“student");
th.endelement(null,null,“students");
th.endDocument();
}
}