第14章 存储器的保护
第14章 存储器的保护
该章主要介绍了GDT、代码段、数据段、栈段等的访问保护机制。
存储器的保护功能可以禁止程序的非法内存访问。利用存储器的保护功能,也可以实现一些有价值的功能,比如虚拟内存管理。
代码清单14-1
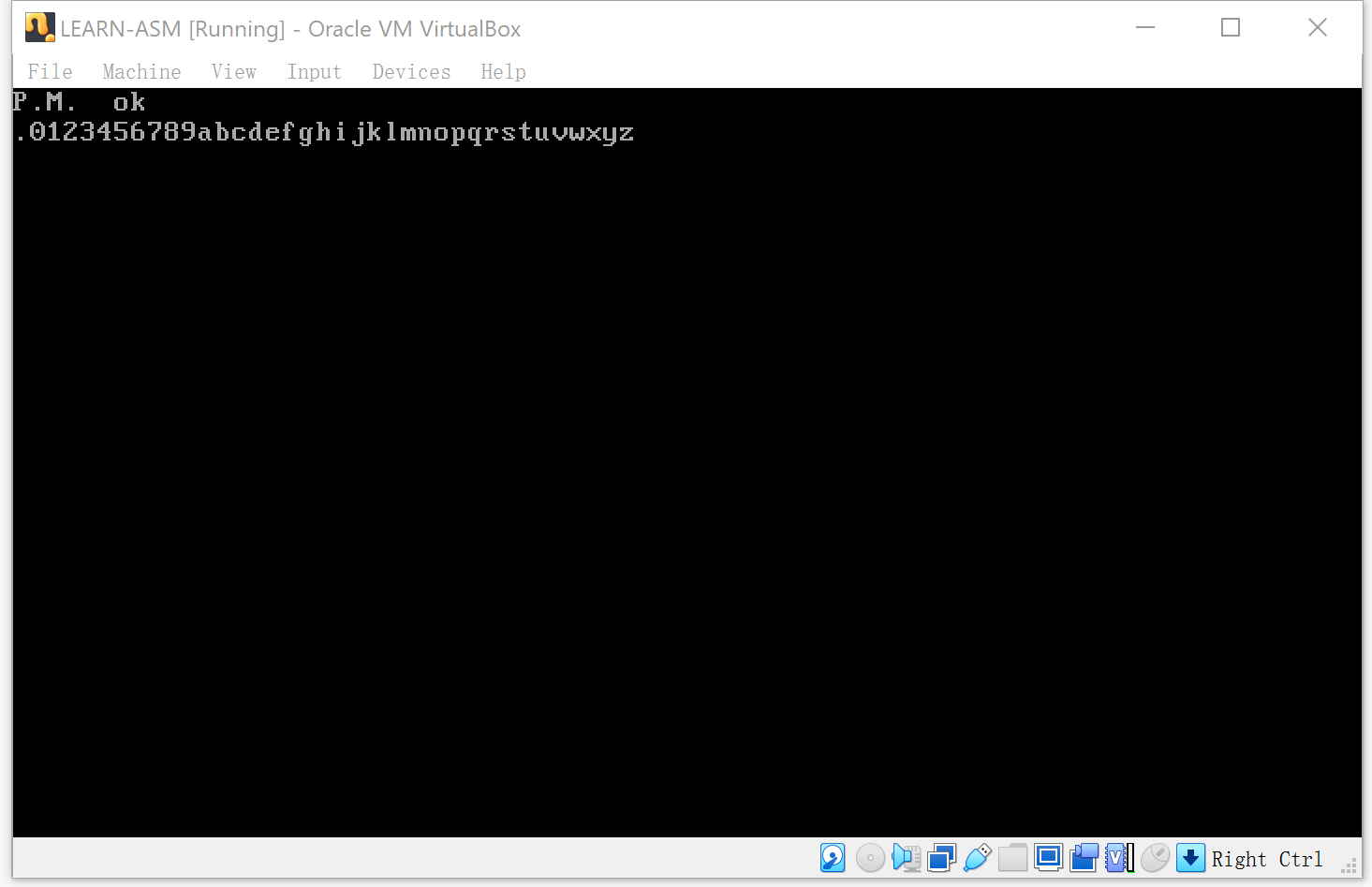
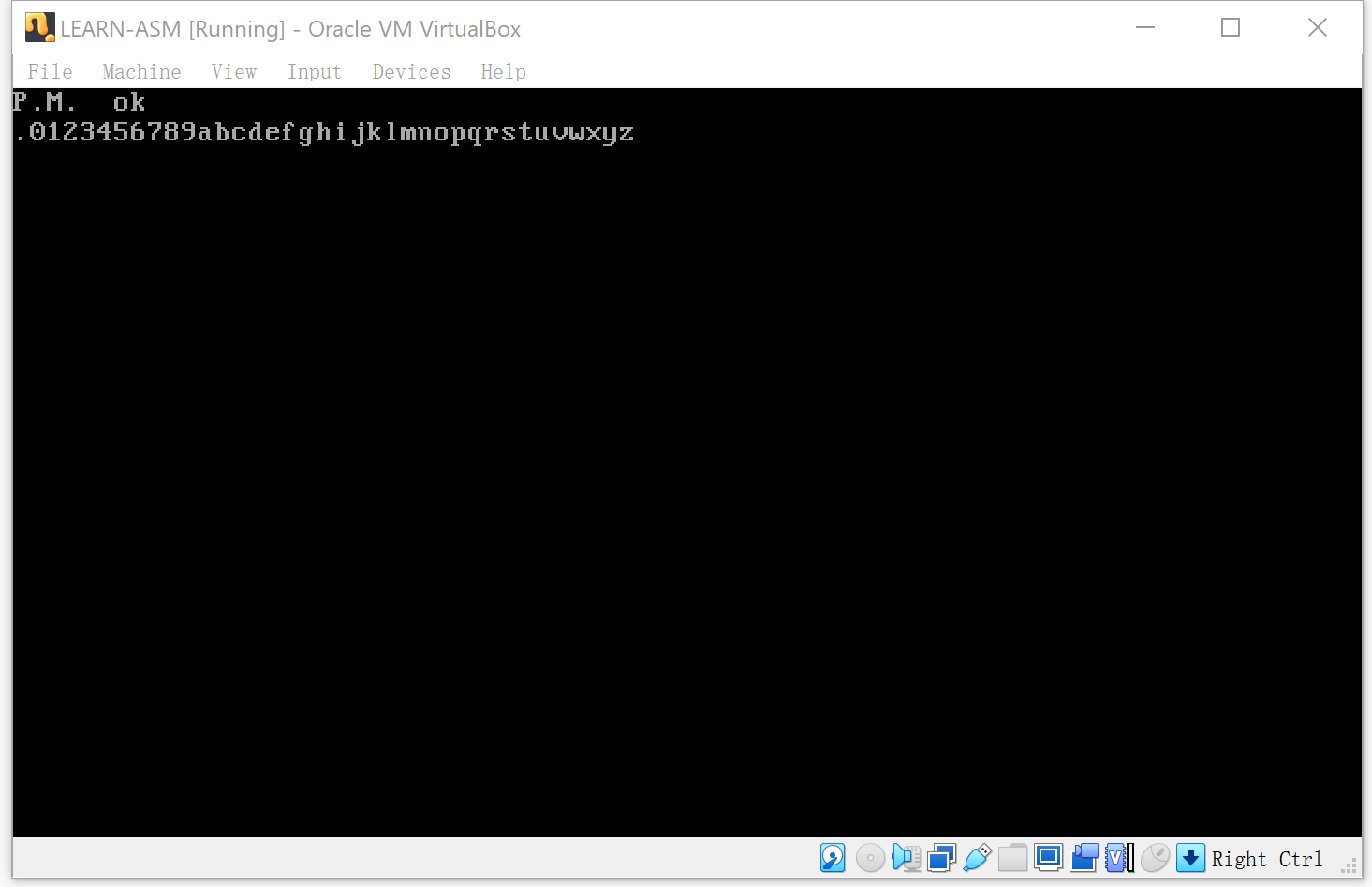
该章节的代码主要实现的功能就是对字符串 ‘s0ke4or92xap3fv8giuzjcy5l1m7hd6bnqtw.’ 进行排序,然后显示在页面上。
进入32位保护模式
话说mov ds,ax和mov ds,eax
该章节主要介绍了为什么要用 mov ds,eax 的写法。总结来看:就是可以不用生成操作尺寸反转前缀0x66,可以加快运行效率。
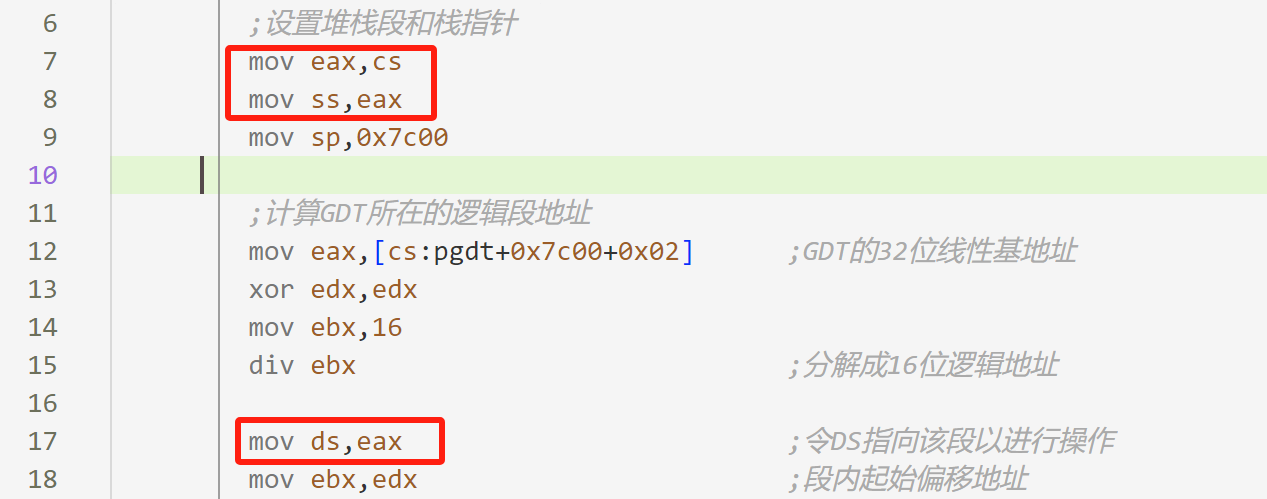
段寄存器的值传送:段寄存器(选择器)的值只能用内存单元或者通用寄存器来传送,一般的指令格式为:
mov sreg, r/m16
例如:
mov ds,ax ;寄存器ax的值传送到ds里。
- 在实模式下,传送到DS中的值是逻辑段地址;
- 在保护模式下,传送的是段选择子。
段寄存器的值传送机器码:在不同的操作尺寸下,老式的编译器会产生不同的机器代码。
[bits 16]
mov ds,ax ;8E D8
[bits 32]
mov ds,ax ;66 8E D8
有前缀的和没有前缀的相比,处理器在执行时会多花一个额外的时钟周期。
但是如果写成如下形式,那么生成的就是不加前缀的8E D8,执行上就可以少花一个额外的时钟周期了。
mov ds,eax ;8E D8
NASM编译器:NASM编译器不管指令形式如何变化,以下代码编译后的结果都一样:
[bits 16]
mov ds,ax ;8E D8
mov ds,eax ;8E D8
[bits 32]
mov ds,ax ;8E D8
mov ds,eax ;8E D8
总结:虽然书中说明了理由,但是我没太明白为什么要这么写?
因为前面默认操作尺寸都是16位的,直接用16位的写法不就好了。带着这个疑问,我修改了书中的例子,将eax换成了ax,编译后发现确实没有啥差别,而且用ax的还少了一个反转前缀0x66。
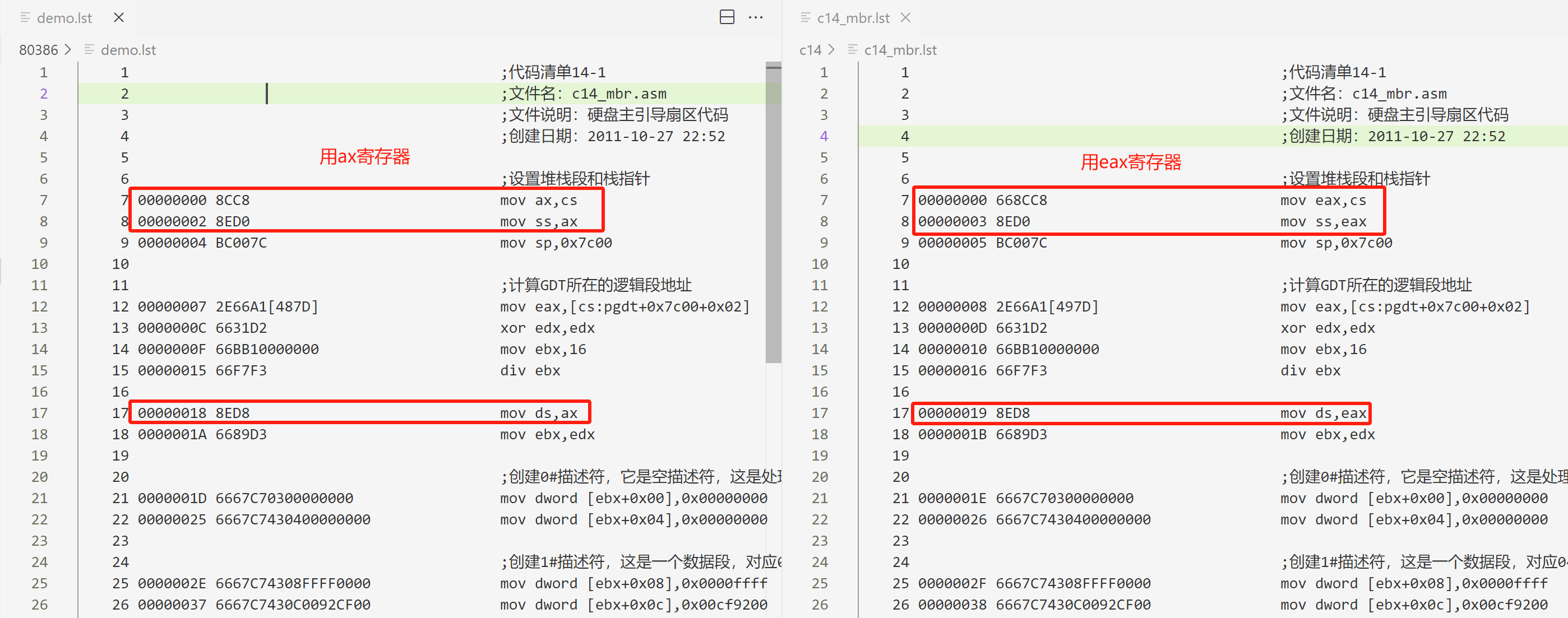
难道是nasm编译器优化过了?
创建GDT并安装段描述符
创建GDT:基本和前面类似,就是把16位寄存器换成了32位寄存器。
;计算GDT所在的逻辑段地址
mov eax,[cs:pgdt+0x7c00+0x02] ;GDT的32位线性基地址
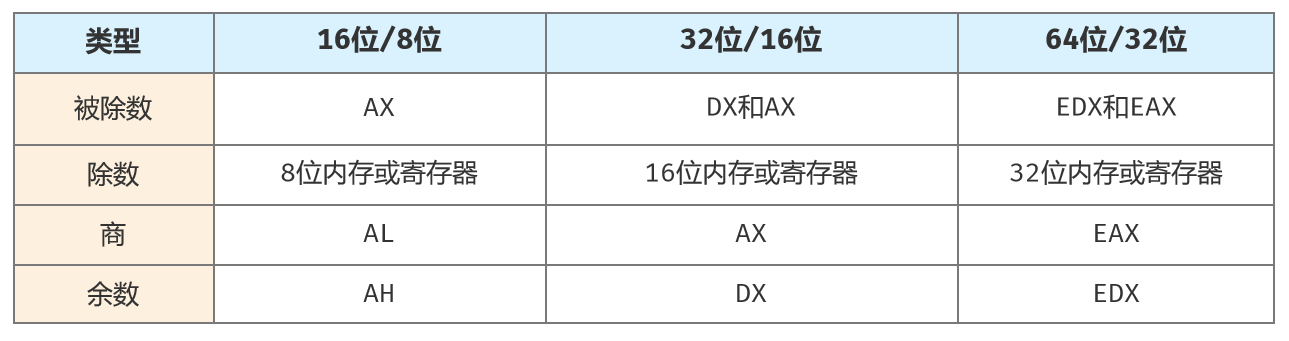
xor edx,edx ;清0,被除数高位为0
mov ebx,16 ;段地址是16位对齐
div ebx ;分解成16位逻辑地址商存储在eax,余数存储在edx。
mov ds,eax ;令DS指向该段以进行操作
mov ebx,edx ;段内起始偏移地址
......
pgdt dw 0 ;汇编地址:pgdt+0x00
dd 0x00007e00 ;GDT的物理地址,汇编地址:pgdt+0x02
除法的规则:
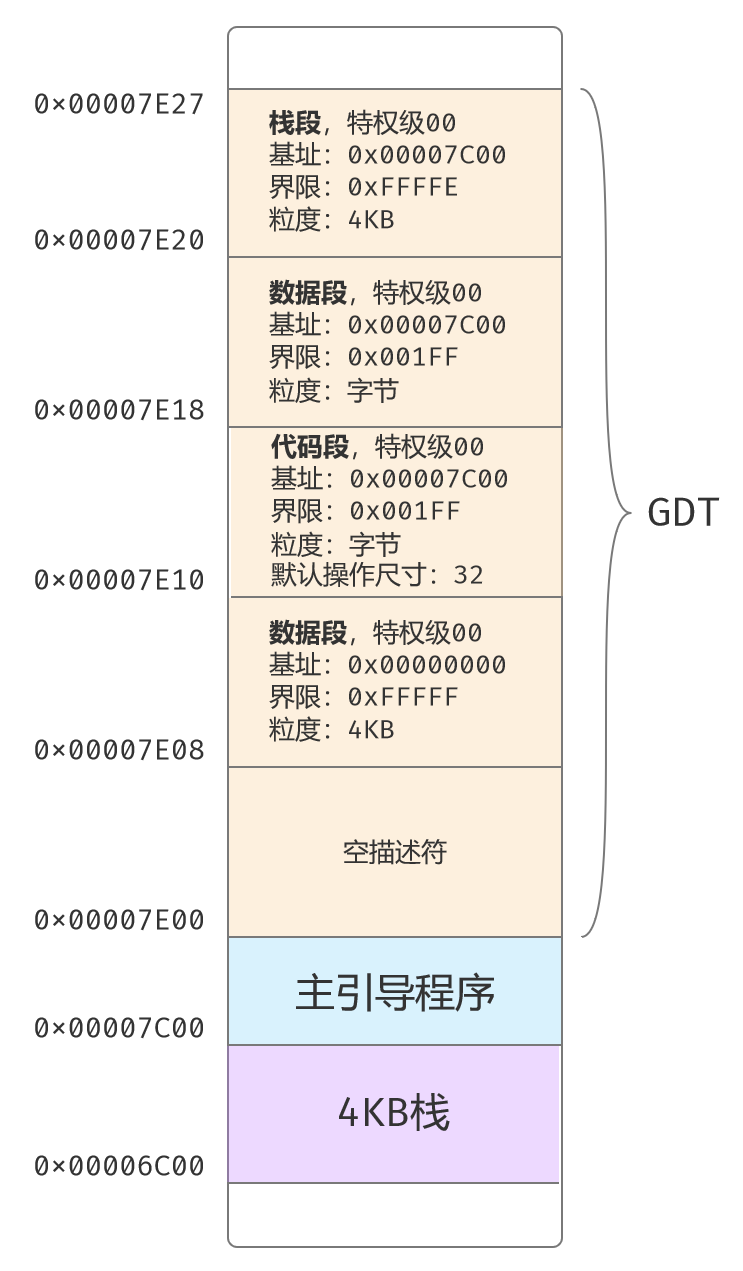
安装空描述符:0#描述符是空描述符,这是处理器的要求。
;创建0#描述符,它是空描述符,这是处理器的要求
mov dword [ebx+0x00],0x00000000
mov dword [ebx+0x04],0x00000000
创建保护模式下的数据段描述符:数据段,对应0~4GB的线性地址空间。
;创建1#描述符,这是一个数据段,对应0~4GB的线性地址空间
mov dword [ebx+0x08],0x0000ffff ;基地址为0,段界限为0xfffff
mov dword [ebx+0x0c],0x00cf9200 ;粒度为4KB,存储器段描述符
- 线性基地址:0x00000000;
- 段界限:0xFFFFF;
- 段粒度:G=1,表示4KB。
段的粒度是以4KB(十进制数4096或十六进制0x1000)为单位,其实际使用的段界限用字节表示为:
(描述符中的段界限值+1)*0x1000-1
= 描述符中的段界限值*0x1000 + 0x1000 -1
= 描述符中的段界限值*0x1000 + 0xFFF
= 0xFFFFF * 0x1000 + 0xFFF = 0xFFFFFFFF
也就是4GB。
创建保护模式下的代码段描述符:
;创建保护模式下初始代码段描述符
mov dword [ebx+0x10],0x7c0001ff ;基地址为0x00007c00,512字节
mov dword [ebx+0x14],0x00409800 ;粒度为1个字节,代码段描述符
- 线性基地址:0x00007c00;
- 段界限:0x001FF;
- 粒度为:G=0,表示字节。
就是当前执行代码的这个段,总共0x200字节,十进制即512个字节。
创建以上代码段的别名描述符:
;创建以上代码段的别名描述符
mov dword [ebx+0x18],0x7c0001ff ;基地址为0x00007c00,512字节
mov dword [ebx+0x1c],0x00409200 ;粒度为1个字节,数据段描述符
- 线性基地址:0x00007c00;
- 段界限:0x001FF;
- 粒度为:G=0,字节;
- TYPE位:0010,可读可写。
因为代码段描述符的TYPE位并没有可写标志,所以需要另外定义一个数据段段支持写入。
安装保护模式下的栈段描述符:
mov dword [ebx+0x20],0x7c00fffe ;基地址为0x00007c00,界限为0xffffe
mov dword [ebx+0x24],0x00cf9600 ;粒度为4KB,向下扩展
- 线性基地址:0x00007C00;
- 段界限:0xFFFFE;
- 粒度为:4KB。
书中提到栈段的大小是4KB,为什么是4KB,后续 栈操作时的保护 章节有详细解释了这个问题。
设置GDT的界限:设置GDT的界限为39。因为总共5个描述符,每个描述符占用8字节,总大小40字节,界限值总大小减1为39。
;初始化描述符表寄存器GDTR
mov word [cs:pgdt+0x7c00],39 ;描述符表的界限
安装GDT表后,内存映像如下。
初始化描述符表寄存器GDTR:
lgdt [cs: pgdt+0x7c00]
修改段寄存器时的保护
修改CS段寄存器:这里也是通过jmp指令进行隐式修改,和上一章不同这里增加了一个dword修饰flush标号。
;以下进入保护模式... ...
jmp 0x0010:dword flush ;16位的描述符选择子:32位偏移
作者在书中解释了加这个 dword 的原因,总结来看就是flush标号变成了32位的,但是在这里完全没有意义。
我尝试对比两种不同的写法编译后的文件,看得就更加清晰了。

最后得出结论完全没有必要。
修改其他段寄存器:代码我加了一些注释
mov eax,0x0018 ;00000000_0001_1000 3号数据段选择子,指向代码段空间
mov ds,eax
mov eax,0x0008 ;00000000_0000_1000 1号数据段选择子,0~4GB的选择子
mov es,eax
mov fs,eax
mov gs,eax
mov eax,0x0020 ;00000000_0010_0000 4号栈段选择子
mov ss,eax
xor esp,esp ;ESP <- 0
因为选择子的索引号是从第4位(位3)开始的,一开始不容易看出选择子的编号,多看几次就熟悉了。
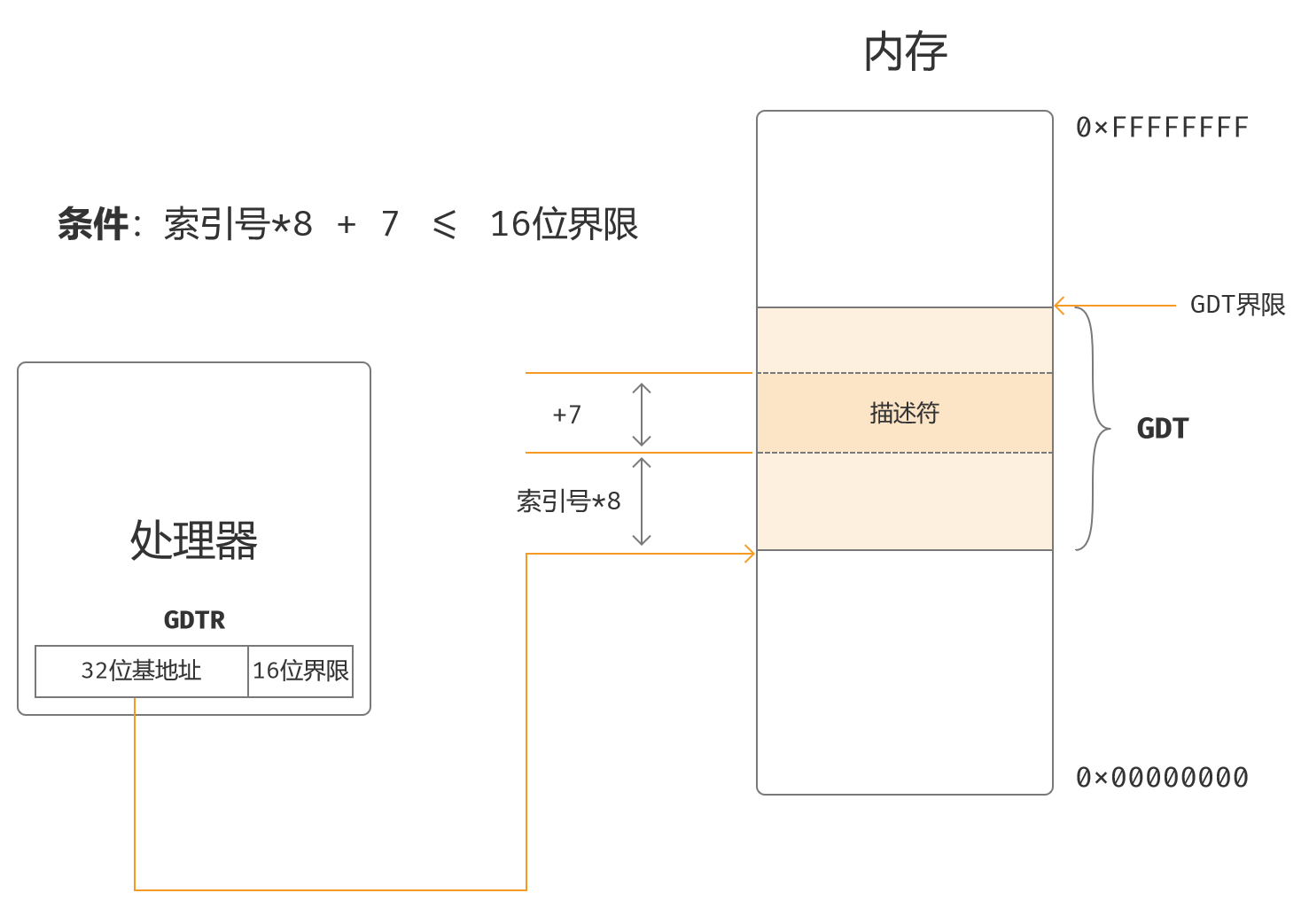
段描述符边界检查:处理器从GDT中取某个描述符时,就要求描述符的8字节都在GDT边界之内,也就是索引号×8+7小于或等于边界。如果检测到段描述符其位置超过表的边界时,处理器中止处理,产生异常中断13。
判断条件:
索引号*8 + 7 <= 16位界限
参考下图:
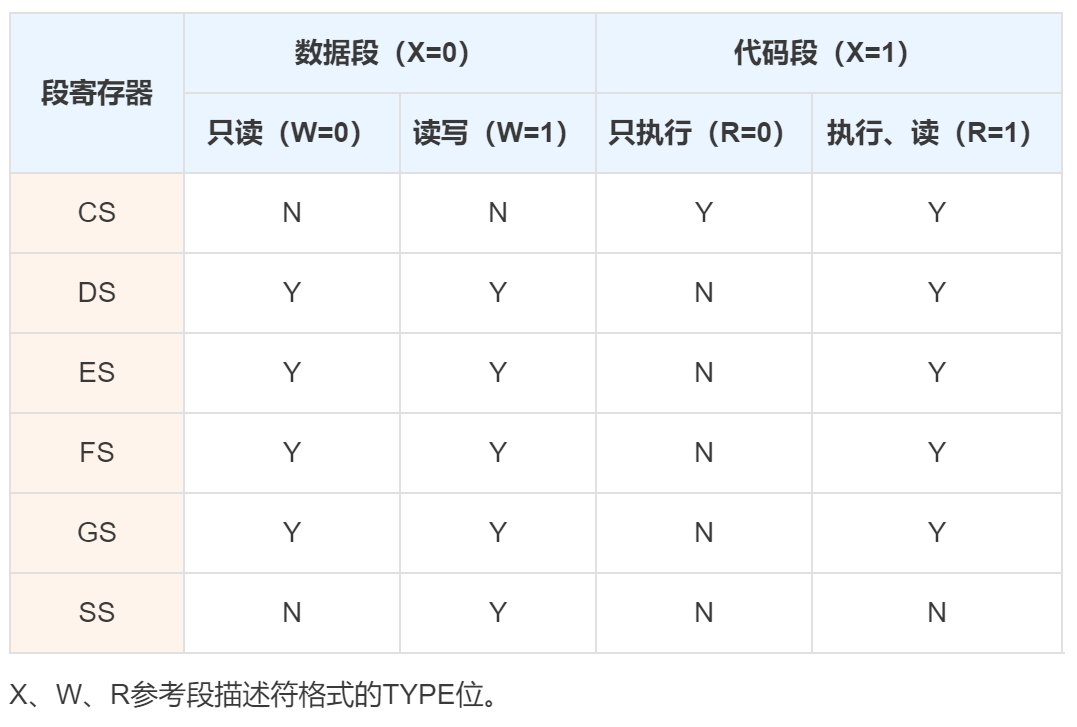
段描述符的类别检查:载入段寄存器时,还要检查描述符的类别,比如数据段类型就不能载入CS段寄存器。
段描述符中的P位检查:P位表示段存在位(Segment Present),用于指示描述符所对应的段是否存在。
- P=0:表明虽然描述符已被定义,但该段实际上并不存在于物理内存中。此时,处理器中止处理,引发异常中断11。一般来说,应当定义一个中断处理程序,把该描述符所对应的段从硬盘等外部存储器调入内存,然后置P位。中断返回时,处理器将再次尝试刚才的操作。
- P=1:则处理器将描述符加载到段寄存器的描述符高速缓存器,同时置A位(仅限于当前讨论的存储器的段描述符)。
地址变换时的保护
代码段执行时的保护
段界限容量计算:每个代码段都有自己的段界限,位于其描述符中。实际使用的段界限,其数值和粒度(G)位有关。
- G=0,表示字节,则实际使用的段界限为:描述符中的段界限值 字节;
- G=1,表示4KB,则实际使用的段界限为:描述符中的段界限值*0x1000+0xFFF 字节。
假设当前代码段的粒度是4KB,那么,因为描述符中的段界限值是0x001FF,故实际使用的段界限是:
0x1FF * 0x1000 + 0xFFF = 0x001FFFFF
代码段越界检查:代码段是向上(高地址方向)扩展的,要执行的那条指令,其长度减1后,与EIP寄存器的值相加,结果必须小于或等于实际使用的段界限,否则引发处理器异常。即:
0 <= (EIP+指令长度-1) <= 实际使用的段界限
数据访问时的保护
数据段分类:数据段分为向上扩展的数据段和向下扩展的数据段。
- 向上扩展的数据段可以是一般的数据段,也可用做栈段;
- 向下扩展的数据段总是用作栈段。
向上扩展的数据段,代码段的检查规则同样适用于数据段,只是将代码段的指令长度换成操作数长度。
例如:
mov [0x2000],edx ;将寄存器edx的值写入内存0x2000处。
检查规则:
0 <= (EA + 操作数大小 -1) <= 实际使用的段界限
- EA表示:Effective Address 有效地址。
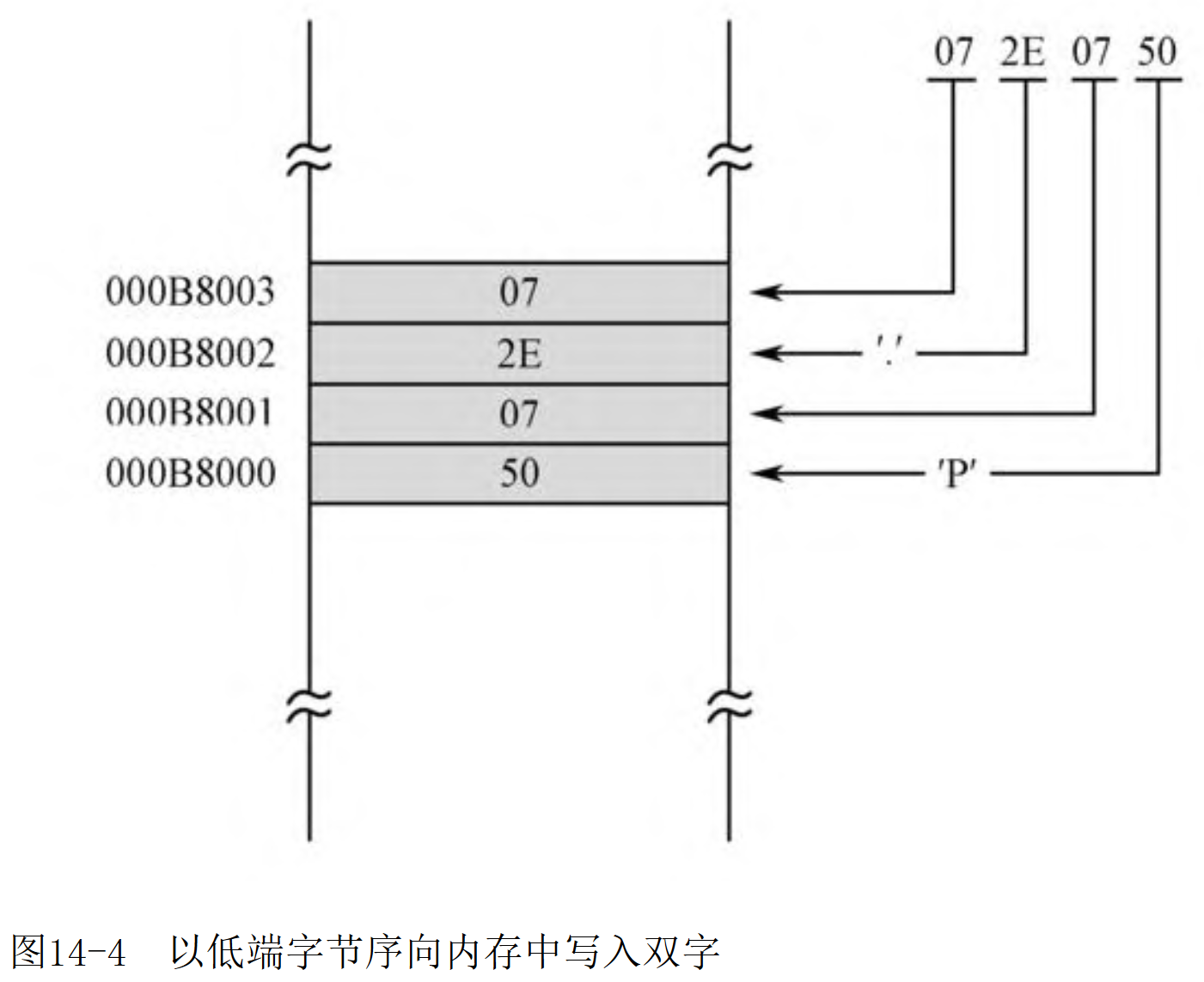
屏幕显示字符:es指向0~4GB内存空间,加上0xb8000,正好是屏幕显示缓冲区所在的区域。另外这次显示字符是一行代码显示两个字符,原理都是类似的。
mov dword [es:0x0b8000],0x072e0750 ;字符'P'、'.'及其显示属性
mov dword [es:0x0b8004],0x072e074d ;字符'M'、'.'及其显示属性
mov dword [es:0x0b8008],0x07200720 ;两个空白字符及其显示属性
mov dword [es:0x0b800c],0x076b076f ;字符'o'、'k'及其显示属性
一次写入两个字符:
栈操作时的保护
栈段段界限:栈段也是数据段,可以向上扩展,也可以向下扩展。
- 向上扩展:段界限的最小值等于0;最大值在段描述符中指定。
- 向下扩展:段界限的最大值是固定的,最小值需要在段描述符中指定。
向下扩展的栈段段界限最大值:取决于D/B位,对于代码段来说是D位,对于向下扩展的栈段来说是B位。
- B=0:表示段界限的最大值是0xFFFF;
- B=1:表示段界限的最大值是0xFFFFFFFF。
栈段栈指针:不管是向下扩展,还是向上扩展的段都符合如下规则。
- B=0:表示栈操作时使用栈指针寄存器SP;
- B=1:表示栈操作时使用栈指针寄存器ESP。
实际使用的段界限:在栈段中,实际使用的段界限也和粒度(G)位相关,
- G=0:实际使用的段界限就是描述符中记载的段界限;
- G=1:则实际使用的段界限:描述符中的段界限值*0x1000+0xFFF。
检测规则:
- B=0:实际使用的段界限+1 <= (SP的内容-操作数的长度) <= 0xFFFF;
- B=1:实际使用的段界限+1 <= (ESP的内容-操作数的长度) <= 0xFFFFFFFF。
安装栈段描述符:
mov dword [ebx+0x20],0x7c00fffe ;基地址为0x00007c00,界限为0xffffe
mov dword [ebx+0x24],0x00cf9600 ;粒度为4KB,向下扩展
- 线性基地址:0x00007C00;
- 段界限:0xFFFFE;
- 上下:向下扩展的段(TYPE中E=1);
- 粒度:4KB(G=1);
- 栈指针:ESP(B=1)
- 段界限的最大值:0xFFFFFFFF(B=1)
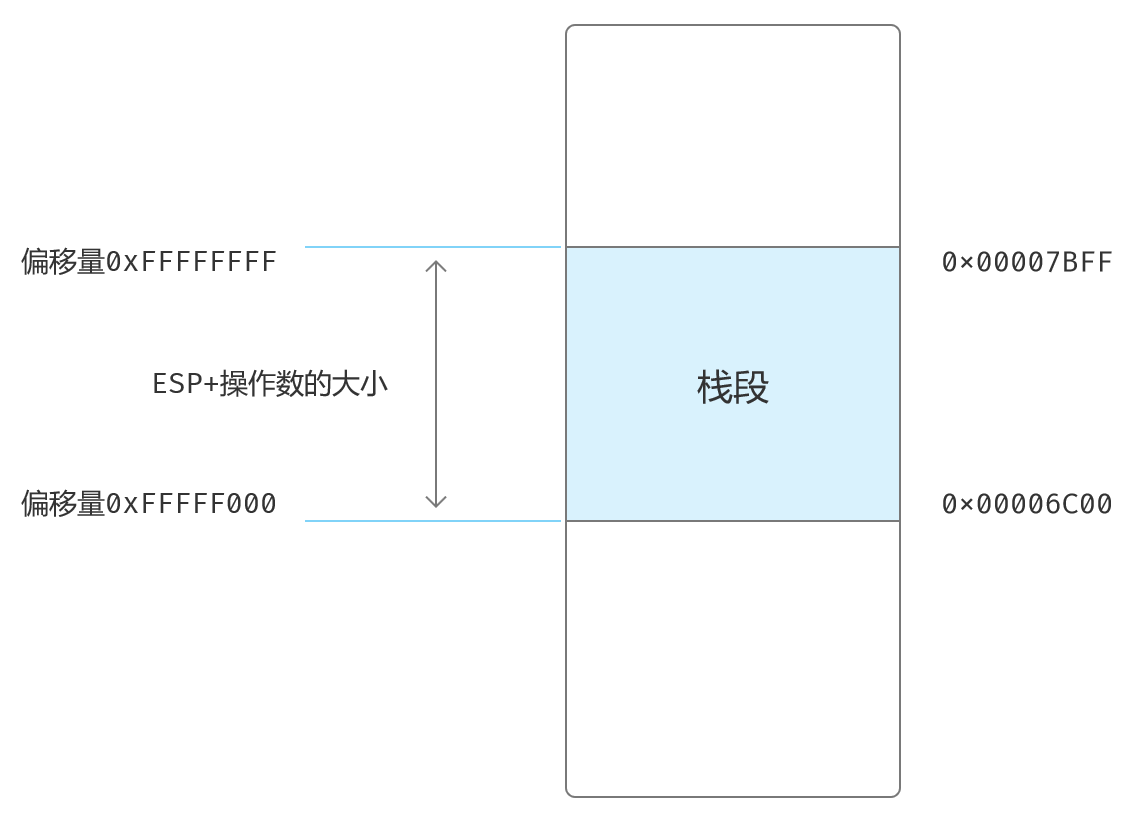
计算实际使用的段界限:
0xFFFFE*0x1000 + 0xFFF = 0xFFFFEFFF
因为ESP的最大值是0xFFFFFFFF,处理器的检查规则:
0xFFFFEFFF+1 <= (ESP的内容-操作数的长度) <= 0xFFFFFFFF
= 0xFFFFF000 <= (ESP的内容-操作数的长度) <= 0xFFFFFFFF
栈指针寄存器ESP的内容仅仅是在压栈和出栈时提供有效地址,操作数的物理地址要用段寄存器的描述符高速缓存器中的段基址和ESP的内容相加得到。
该栈最低端的有效物理地址是:
0x00007C00 + 0xFFFFF000 = 0x00006C00
最高端的有效地址:
0x00007C00 + 0xFFFFFFFF = 0x00007BFF
也就是说,当前程序所定义的栈空间介于地址为0x00006C00~0x00007BFF之间,大小是4KB。
如果单纯算栈段空间大小,用偏移量的最大值和最小值相减即可:
0xFFFFFFFF - 0xFFFFF000 = 0xFFF
设置栈段寄存器和栈指针:
mov eax,0x0020 ;0000 0000 0010 0000, 索引号是4
mov ss,eax
xor esp,esp ;ESP <- 0,最大值 0xFFFFFFFF + 1
处理器检查过程实例:一开始压入一个双字。
push ecx ; 压入一个双字,4字节
因为压栈操作是先减ESP,然后再访问栈,故ESP的新值:
0-4 = 0xFFFFFFFC (-1:F -2:E -3:D -4:C)
符合段界限的范围:0xFFFFF000 ~ 0xFFFFFFFF,压入的双字,其线性地址:
0x00007c00 + 0xFFFFFFFC = 0x00007BFC
该双字的4个字节分别占据以下线性地址:0x00007BFC、0x00007BFD、0x00007BFE和0x00007BFF。
使用别名访问代码段对字符排序
该章节就是对字符串进行排序。
字符串定义:通过string别名可以访问到字符串。
string db 's0ke4or92xap3fv8giuzjcy5l1m7hd6bnqtw.'
使用代码段别名描述符:代码段是不可以更改内容,所以用代码段的别名描述符,就是如下这个。
mov eax,0x0018 ;00000000_0001_1000 3号数据段选择子,指向代码段空间
mov ds,eax
排序逻辑:思路如下。
- 使用冒泡排序;
- 冒泡排序需要两个循环,都需要ECX,可以利用栈进行保存;
- 一次读入相邻的两个字符到ax,比较ah和al,看是否交换ah和al。
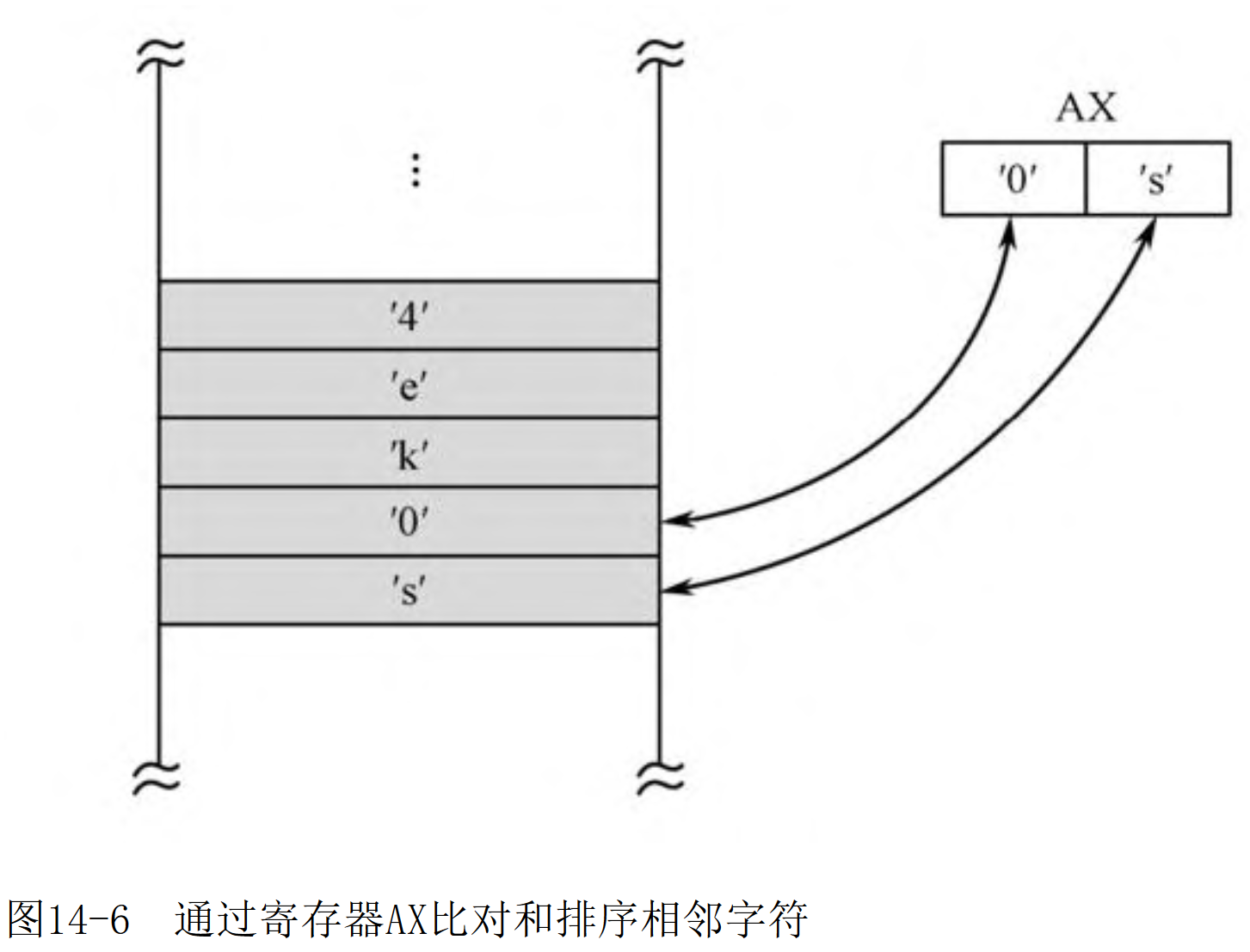
代码我做了一些注释和说明,更加清晰。

其中xchg是交换指令,用于交换两个操作数的内容。
xchg r/m8, r8
xchg r/m16, r16
xchg r/m32, r32
xchg r8,m8
xchg r16,m16
xchg r32,m32
我用JavaScript编写冒泡排序,汇编的排序逻辑类似。
// JavaScript编写的冒泡排序
let arr = [11, 8, 5, 3, 5, 2, 9, 20, 1];
for (let i = arr.length - 1; i >= 0; i--) { // 外层循环 length-1 ~ 0
for (let j = 0; j <= i; j++) { // 内层循环 0 ~ i
if (arr[j] > arr[i]) {
let temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
}
}
显示最终的排序结果:
mov ecx,pgdt-string ;循环次数就是字符串的长度
xor ebx,ebx ;偏移地址是32位的情况
@@4: ;32位的偏移具有更大的灵活性
mov ah,0x07 ;字符显示属性
mov al,[string+ebx] ;字符
mov [es:0xb80a0+ebx*2],ax ;es是0~4GB寻址,从第2行第1列开始写入
inc ebx ;增加ebx,显示下一个字符
loop @@4
为什么是从第2行第1列?
因为每行可以已显示80个字符,每个字符都有一个属性字节,所以每行总共160个字节。
所以显示第一行就是:0xb80000, 0xb8001, …, 0xb809F
第二行就是:0xb80a0, 0xb80a1, …, 0xb813F
偏移量:0xa0=160,所以就是第2行第1列了。
程序的编译和运行
完。