「数据科学」转换数据,数据存储空间和类型转换
在数据科学过程中,我们在分析和处理数据的时候,经常会遇到各式各样,大大小小的数据集。在国家数字中国,数字建设大的战略背景下,我们的数据量越来越大,数据集,也从以前的小数据集,摇身一变,成为目前主流的大数据集。
对于小数据集来说,在处理和分析数据的时候,我们并不需要考虑数据集占用的内存空间。但是对于大数据集来说,我们要想让数据的时效性更高一些的话,就需要考虑数据集中,每个列代表的变量的数据类型。
合适的数据类型,可以节省我们的数据在内存和硬盘中,持久化的存储空间,减少我们的硬件投入成本。也可以加快我们的处理和分析的进程,特别是在设计算法、数据分组和聚合,这样大规模数据操作的时候,数据类型往往对处理的时间,影响很大。
查看数据类型和占用空间情况
在Python编程语言中,Pandas库有着很强大的数据处理和分析能力,包括数据类型和占用内存的属性、方法和函数。
我们先导入Pandas库,设置显示的行和列的数目,然后导入所需数据集。
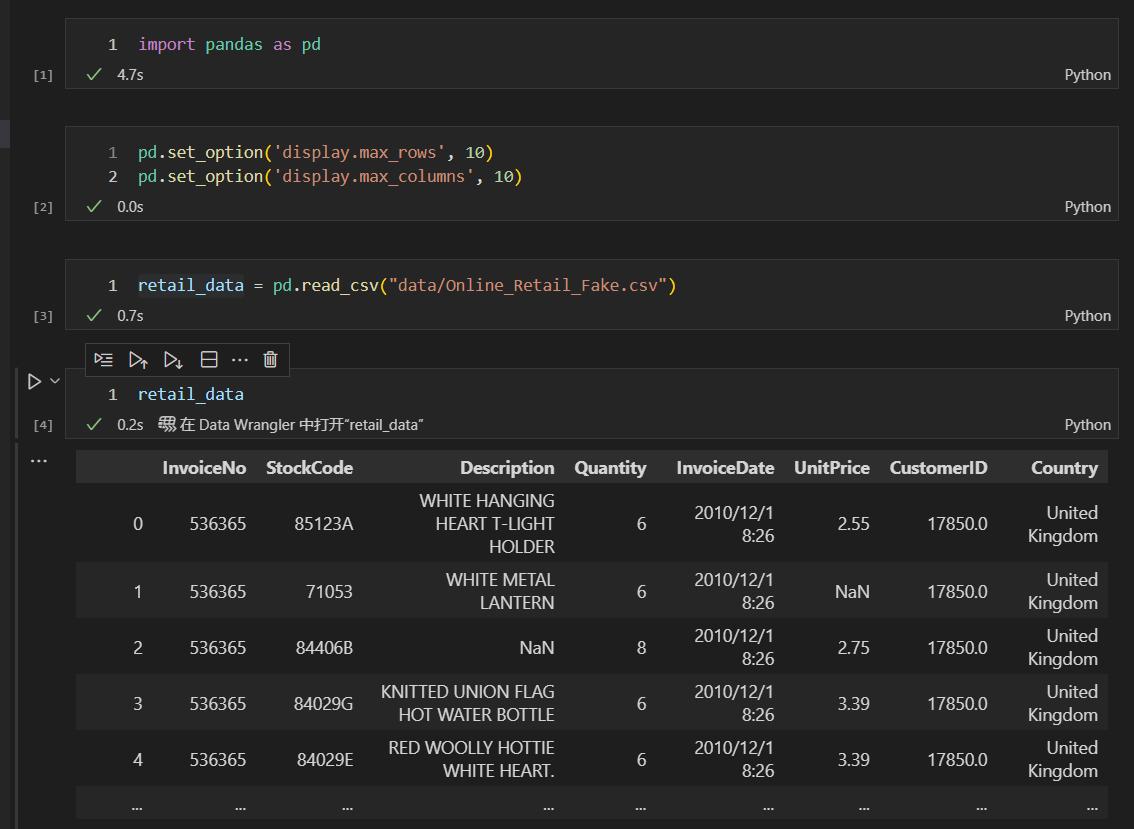
然后,通过dtypes属性,查看数据集中,每一列的数据类型。
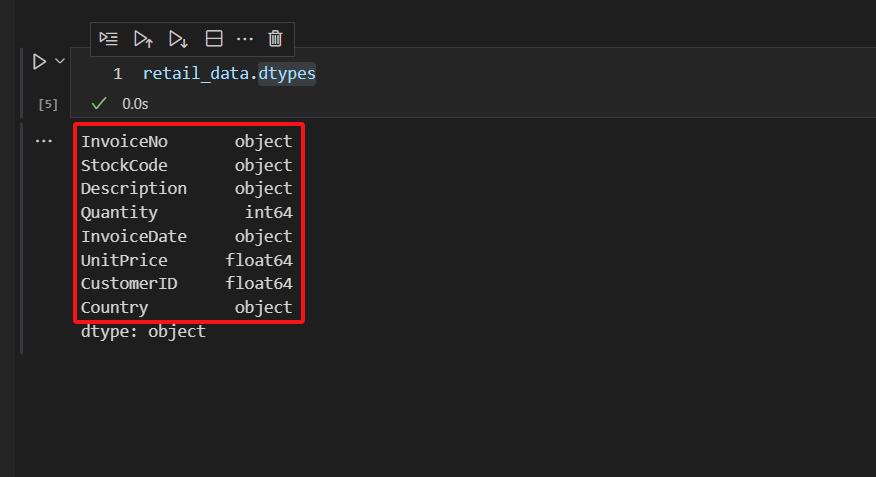
可以看到,retail_data数据集的每一列的数据类型情况,如上图所示。
我们再来查看,每一列的数据类型,占用内存的精确统计信息。
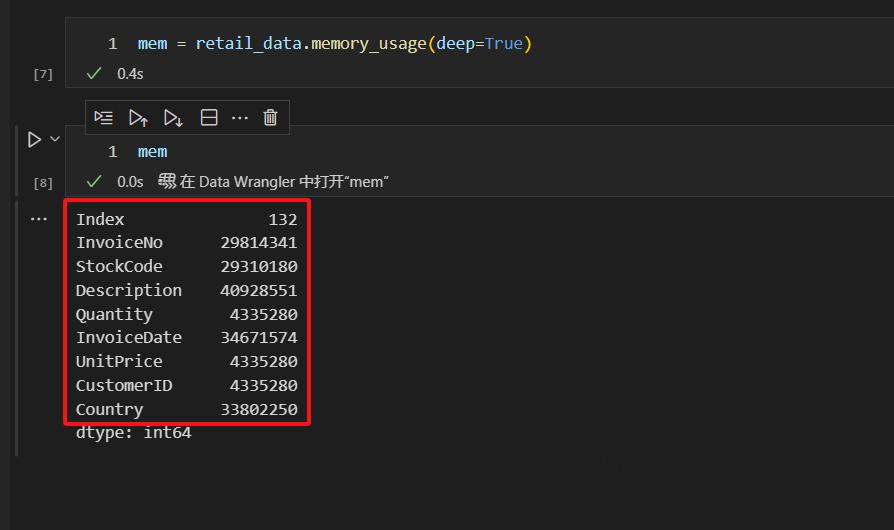
我们通过memory_usage方法,获得包括索引列在内的,所有列的精确占用内存数据。
这里我们统计了retail_data中,每一列数据所占的存储空间(字节数),其中的deep=True参数代表是否计算引用的对象的内存使用情况。
此外,也可以将其转换为以兆字节方式显示,如下图所示。

这里,显示的结果是以MB为单位,表示173MB。也就是说,retail_data数据集,导入到我们的Python语言环境中,存储在我们的内存上,占用的内存空间是173MB。
数据转换(调整数据类型)
在完成对数据集的数据类型查看,以及数据集和数据列在内存中占用空间的信息统计数据之后。我们就可以调整数据集中,各个列的数据类型了。
我们来看国家列(Country)的数据类型情况。
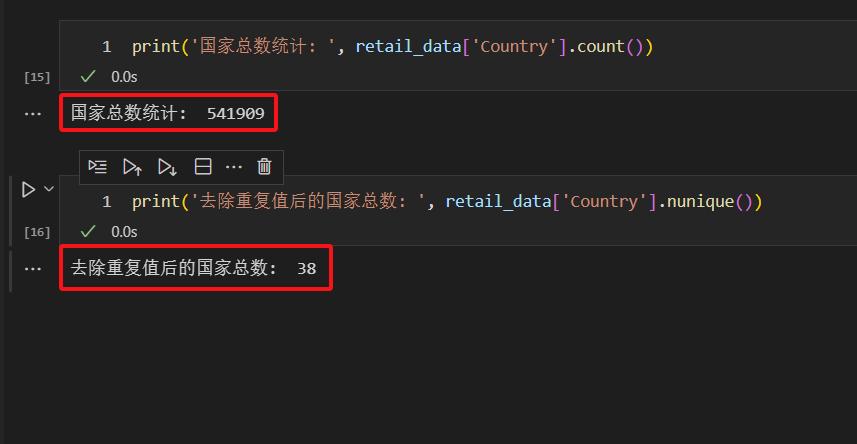
使用以上代码,可以统计出,数据集中,Country列,总共有541909行国家数据。去除重复值后,总共有38个国家数据。也就是说,这541909行国家数据中,分别只有38个国家。
我们的Country列,数据类型为object。像这样国家的数据类型,我们可以设置为category类型。
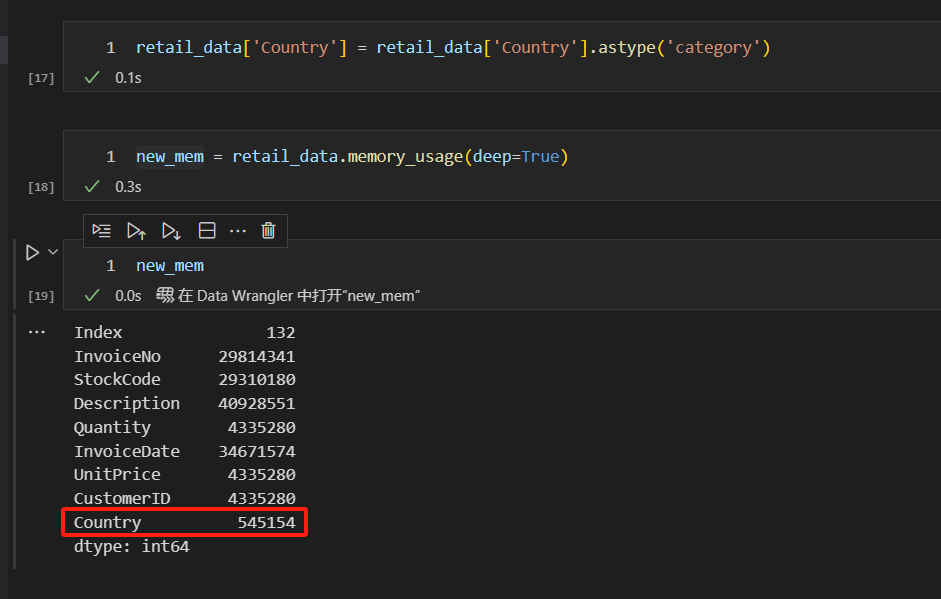
可以看出,我们把Country列,从object类型,设置为category类型之后,内存占用空间,从之前的33802250字节,减少到545154字节。
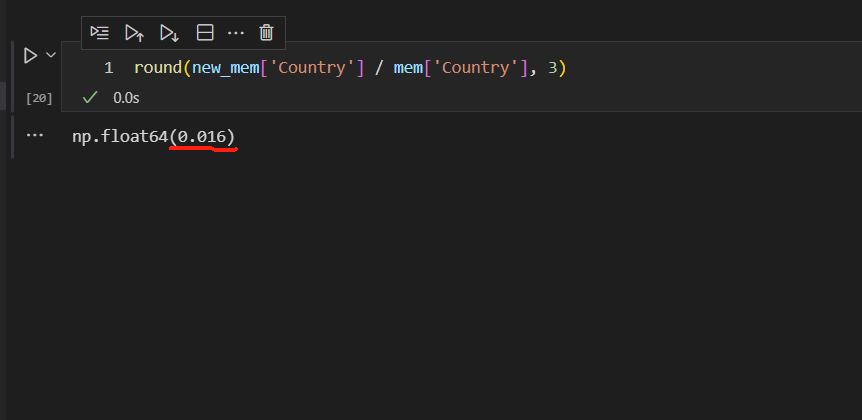
Country的取值一共只有38个国家,经过转换后存储空间明显减少,只有原来存储空间的1.6%。
类似地,还可以对CustomerID列进行数据类型转换,目前CustomerID是浮点数类型,而实际上该数据应该是整数。
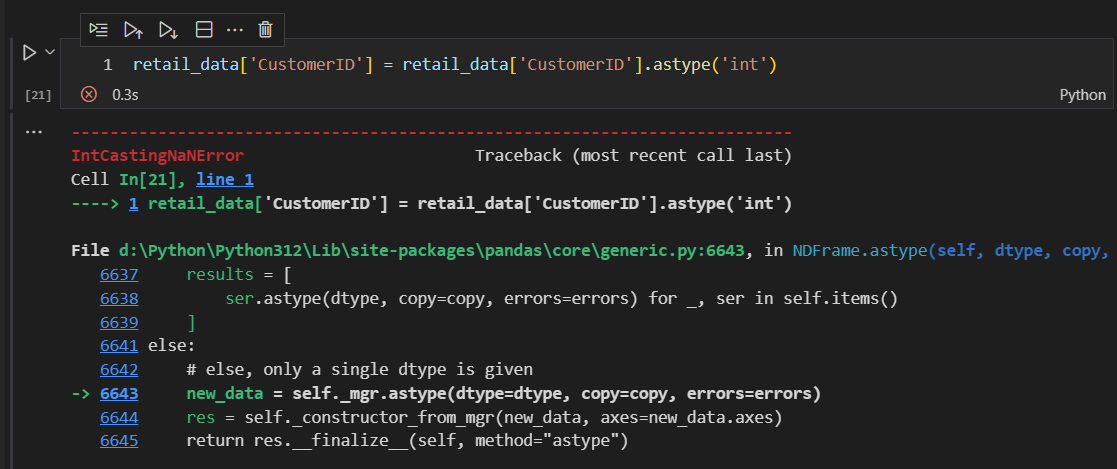
这里,我们直接进行转换的话,会报错。这是因为,在CustomerID列,有缺失值的存在。我们需要先填补缺失值。
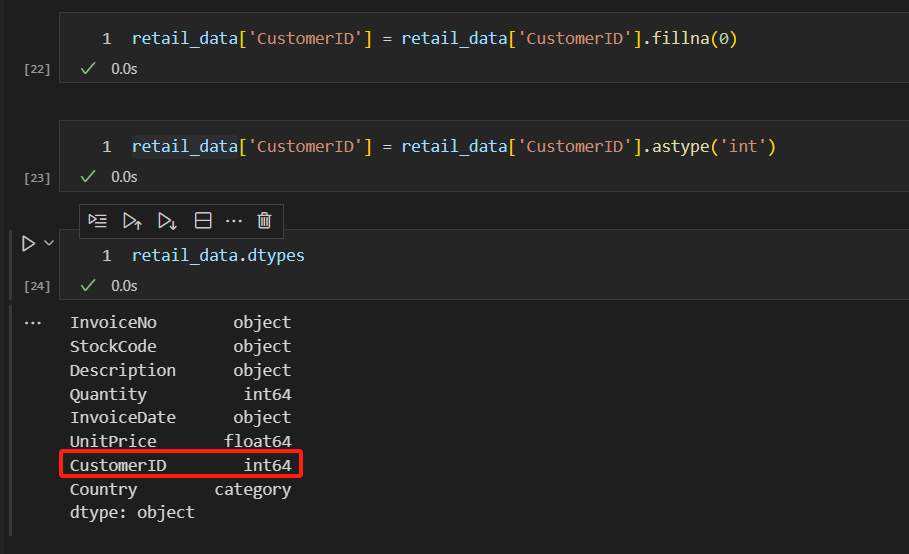
我们先用0填补缺失值,在进行数据类型转换,就正常了。缺失值的处理,我们会在会面的文章中,详细进行讲解。
我们再来看看,时间类型的列,该如何转换。这里是InvoiceDate列。
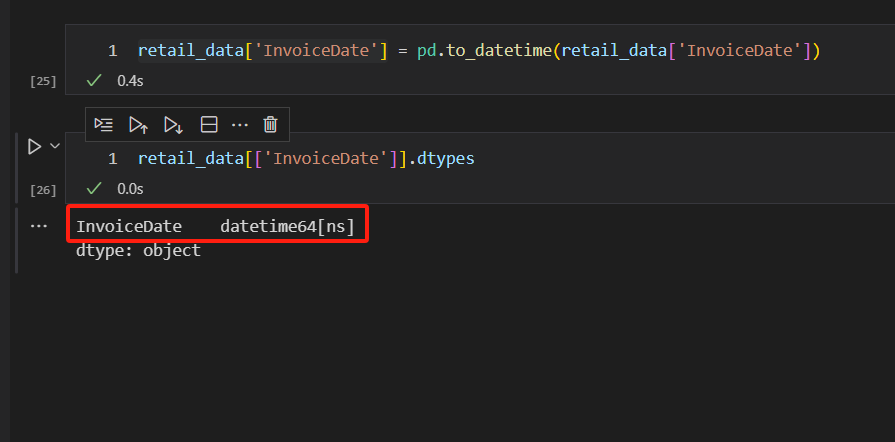
时间数据类型的转换,需要借助to_datetime函数来实现。注意上面代码中,单个列,或者是单个变量的数据类型查看方式。
以上就是本篇文章的全部内容。