【HTTP】HTTP报文格式和抓包
文章目录
- HTTP 是什么
- HTTP 报文格式
- 抓包工具
- 抓包工具的原理
- 抓包结果
- 请求
- 响应
IP,数据链路层,DNS… 都是理论为主,TCP/UDP 虽然有一些时间,但课堂内容不多
HTTP 理论和实践同样重要,未来作为 web 开发程序猿(写网站),HTTP 就是咱们工作中最常用到的东西,吃饭的饭碗
HTTP 是什么
HTTP 全称为“超文本传输协议”,是一种应用非常广泛的应用层协议
- 文本就是字符串,能在 UTF8/GBK 码表上找到合法字符的
- 超文本不仅仅是字符串,还可以携带一些图片,特殊的格式(标题,链接,表格…)
- 富文本还可以设置行高,行间距等等更多
HTTP 最新的版本是 HTTP/3.0,但目前大规模使用的版本是 HTTP/1.1。2.0 和 3.0 引入了很多新的特性:
- 提高传输效率
- 提高传输的安全性
HTTP3.0 之前,在传输层是基于 TCP;3.0 之后,传输层是基于 UDP。HTTP 3.0 基于 UDP 实现了一系列的更复杂的机制,可以确保可靠性,也不怕大数据包
使用 HTTP 的场景:
- 浏览器打开网站(基本上)
- 手机 APP 访问对应的服务器(大概率)
HTTP 协议最主要的应用场景就是网站、浏览器和服务器之间传输数据。客户端(手机,pc)和服务器之间的数据传输,也很可能是 HTTP
所谓网页,是通过 HTML 来构建的,HTML 也是一个“编程语言”,和 Java,C++画风差异很大。
C++,Java表达的是“逻辑”,你要做什么HTML则是描述的“内容”,你这里有什么
一个成熟的网页,光有 HTML 是不够的,还需要 CSS 和 JavaScript 配合。(前端开发三剑客)
HTTP 协议的交互过程,是非常典型的“一问一答”。对于网站来说,基本够用了
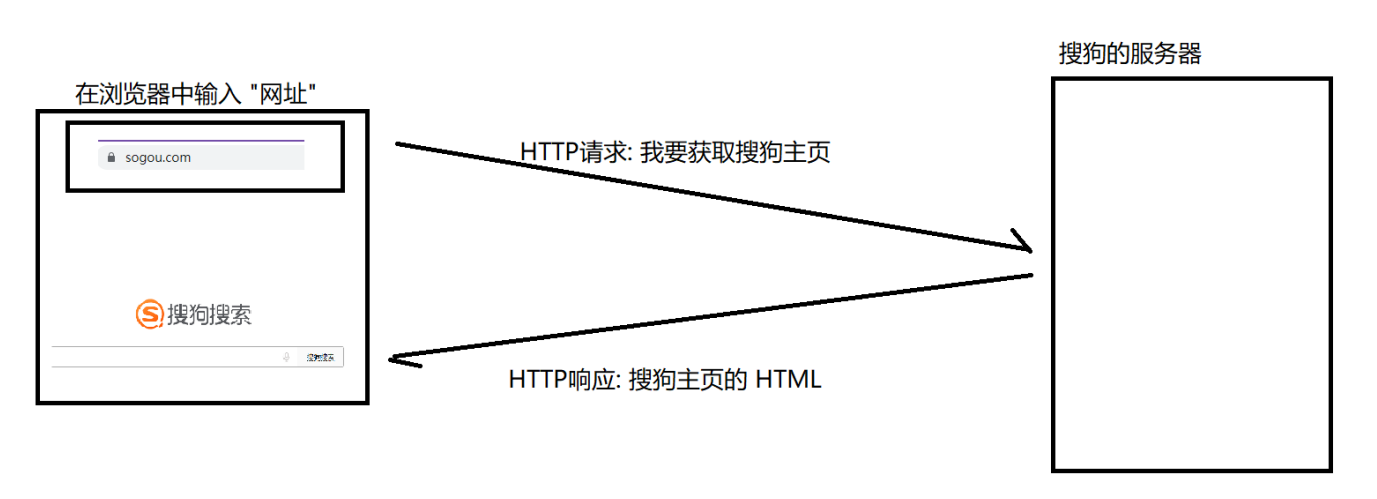
TCP/UDP这样的协议,具体是怎么样的模式,取决于你的代码实现,完全可以实现各种效果。但 HTTP 只能是“一问一答”的形式
HTTP 报文格式
抓包工具
抓包工具,本质上是一个“代理程序”,能够获取到网络上传输的数据,并显示出来,从而给程序猿提供一些参考。
wireshark,高大全,可以抓各种协议数据包,TCP、IP、UDP、以太网等等都可以抓,但是用起来比较复杂
fiddler,专注于 HTTP 的抓包,虽然功能没有 wireshark 丰富,但在抓 HTTP 上面的体验比 wireshark 更好
当前网络上的大部分请求都是基于 HTTPS 的(在 HTTP 的基础上进行了加密)
抓包工具的原理
需要关闭电脑上本身的代理程序,有的为了 fq,电脑上本身就有代理(单独的程序/浏览器插件)。要确保你其他的代理都是关闭状态,因为 fiddler 也是一个代理程序,代理之间会产生冲突
代理就是进行了一个请求转发的工作
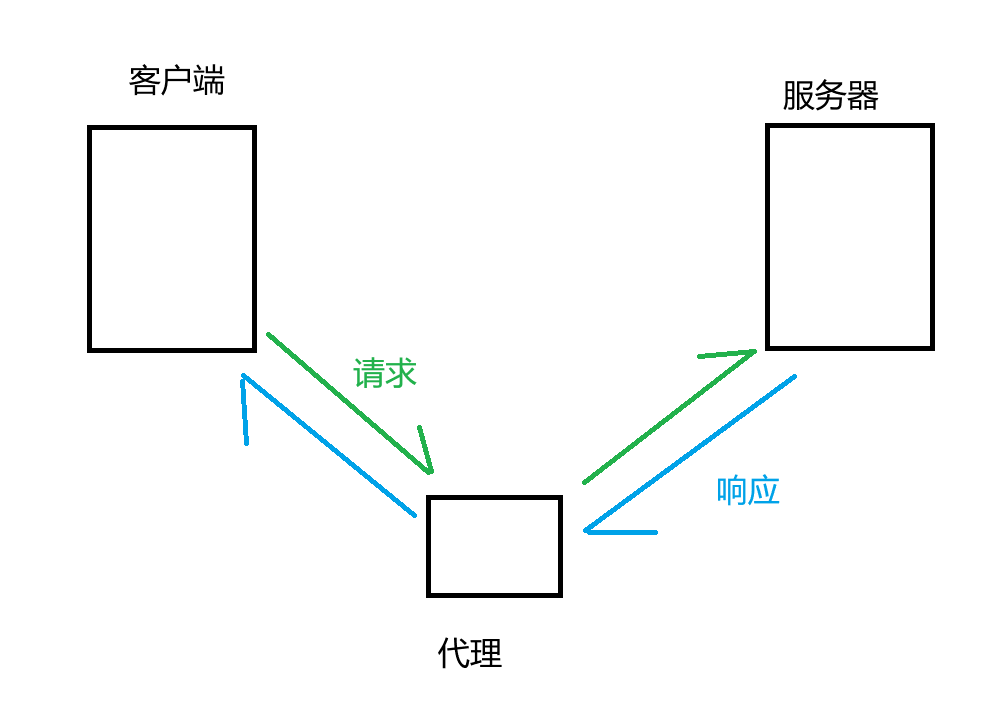
- 正常来说,客户端(你)和服务器之间是直接通信的,你给服务器发请求,服务器给你返回请求
- 引入代理之后,客户端要先把请求发给代理,代理再把请求转发给服务器;服务器把响应发给代理,代理再把响应转发给客户端
- 代理是一个程序,而不是一个设备,工作在应用层。上述的转发都是站在应用层的角度
代理分为两种:
- 正向代理:客户端的代言人
- 反向代理:服务器的代言人
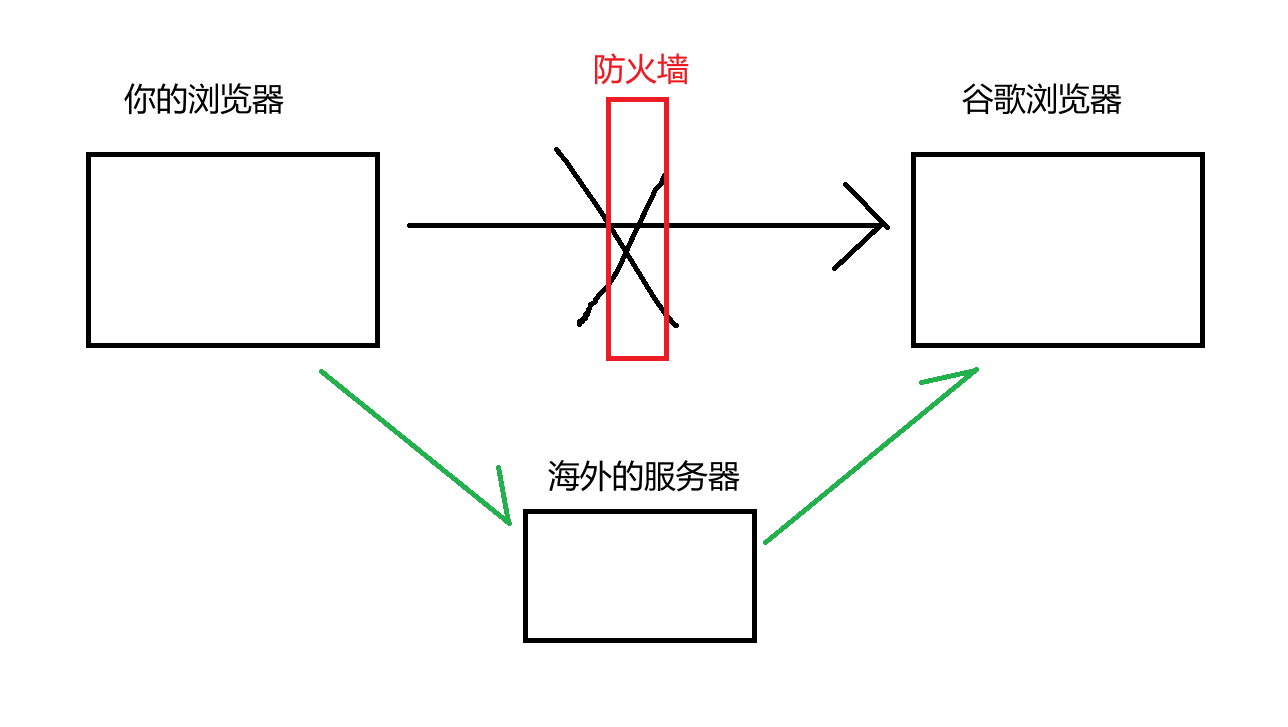
用来 fq 的代理,本质上是通过一个可以被访问到的境外服务器,部署代理服务器,这样就可以绕过防火墙
抓包结果
你的系统上有任何一个程序(不一定是浏览器)使用了 HTTP/HTTPS,此时就都能被 fiddler 给获取到
你电脑上的很多程序,会在你感知不到的情况下,在后台偷偷的做很多事情,和人家的服务器进行交互
- 电脑上装了各种乱七八糟的程序,会在后台做很多事情,所以会越用越卡
打开一个网站,其实浏览器和服务器之间进行的 HTTP 交互不是只有一次,而是通常有很多次。
- 第一次交互是拿到这个页面的
HTML,HTML还会依赖其他的CSS、JS和图片等。HTML被浏览器加载之后,又会触发一些其他的HTTP请求,获取到CSS和JS等。 - 当执行
JS的时候,JS代码里可能又要触发很多的HTTP请求,获取到一些数据

- 蓝色的表示返回的是一个
HTML - 往往是访问一个网站的入口请求
选中这个请求并双击,此时就能看到明细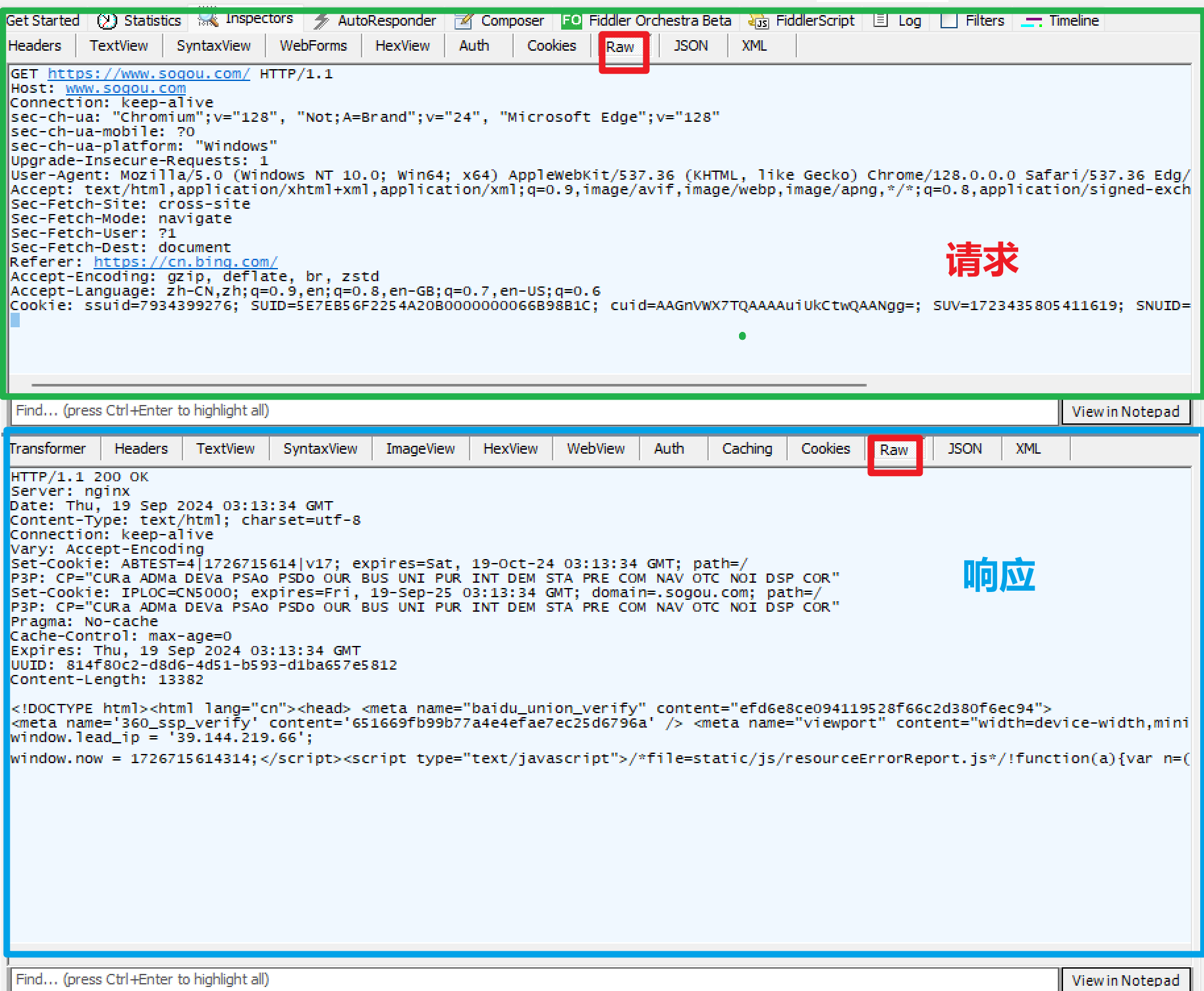
-
上面是请求的明细
在两行标签页中,Raw是HTTP请求的原始数据,一般就看这个 -
下面是响应的明细
在标签页中,也是选择Raw。
当你在记事本中打开响应的时候,会发现是乱码。因为当前响应数据是被压缩了的。网络传输中,带宽是一个比较贵的硬件资源(比CPU还贵),为了节省带宽,我们就可以把响应数据进行压缩(一般都是压缩响应,请求不太需要。请求比较小,响应比较大)
压缩和解压缩的过程,是需要消耗时间和 CPU 的
请求
HTTP 请求,包含四个部分
- 首行
三个部分使用空格来分割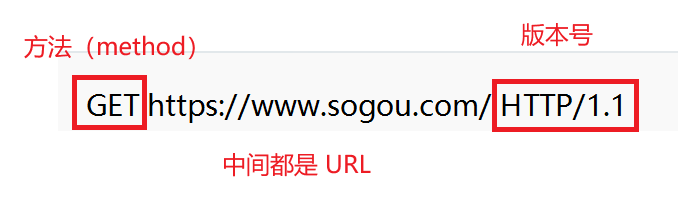
- 请求头(
header)
从第二行,一直到后面都是请求头。类似于 TCP 报头/IP 报头一样,携带了一些重要的属性信息。
TCP/IP报头是以二进制方式组织的,而HTTP的是以文本的方式组织的
报头中包含了很多的键值对,每个键值对占一行,键和值之间用 : 空格来分割。此处的键值对都有哪些,都是什么含义,都是 HTTP 协议规定好的
- 空行
请求头最下面,会有一个空行,这个空行就可以表示结束标记
- 正文(
body)
HTTP 的载荷部分,有的 HTTP 请求有 body,但有的没有
响应
HTTP 响应,也包含四个部分
- 首行
三个部分之间用空格来分割 
- 状态码就描述了这次请求是成功还是失败。失败的原因
- 响应头
响应头中包含了很多的键值对,每个键值对占一行,键和值之间用 : 空格来分割。此处的键值对都有哪些,都是什么含义,都是 HTTP 协议规定好的
- 空行
响应的结束标记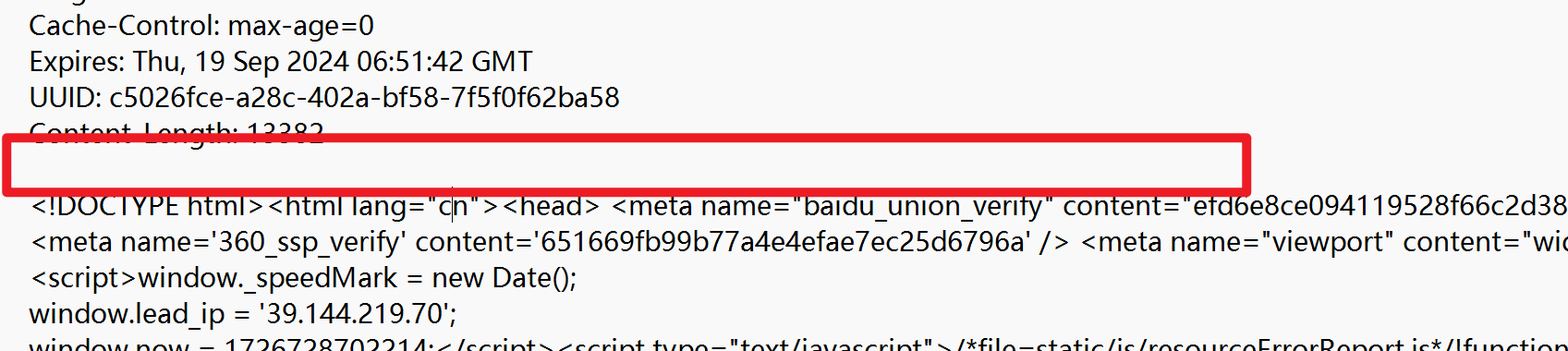
- 响应正文(
body)
HTTP 的载荷,是 HTML。