YOLOv5模型部署教程
一、介绍
YOLOv5模型是一种以实时物体检测闻名的计算机视觉模型,由Ultralytics开发,并于2020年年中发布。它是YOLO系列的升级版,继承了YOLO系列以实时物体检测能力而著称的特点。
二、基础环境
系统:Ubuntu系统,显卡:3090,显存:24G,cuda12.1
特别提醒:本人使用cuda12.1,在下载依赖包时已将pytorch注释掉,最好使用cuda11.8
1.查看系统是否有Miniconda3的虚拟环境
如果输入命令没有显示Conda版本号,则需要安装。
conda -V
2.更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y

3.下载模型
输入下列命令对Cinemo模型进行下载同时进入项目中
git clone https://gitclone.com/github.com/ultralytics/yolov5.git
cd yolov5

4.创建虚拟环境
- 创建名称为“yolov5”,python版本为3.8的虚拟环境
conda create -n yolov5 python=3.8
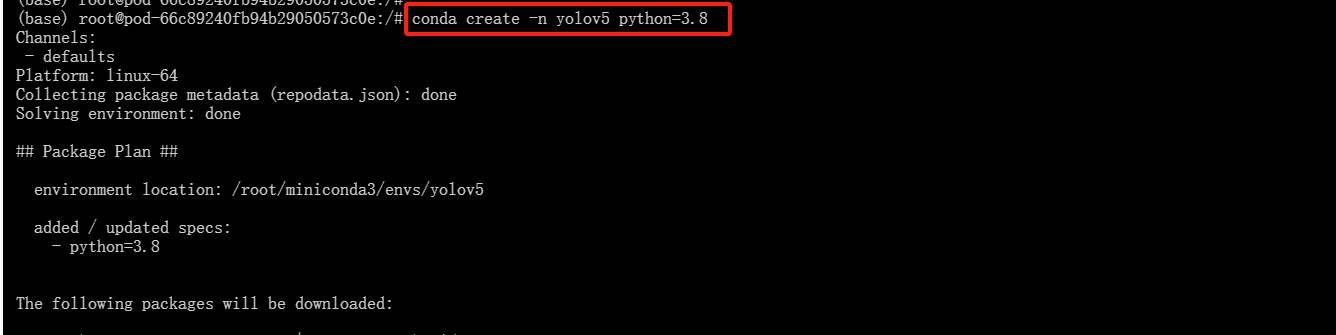
- 激活“cinemo"虚拟环境
conda activate yolov5
5.换源
输入下列命令换成国内源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.douban.com
n/simple --trusted-host pypi.douban.com

6.下载pytorch
输入下列命令:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1

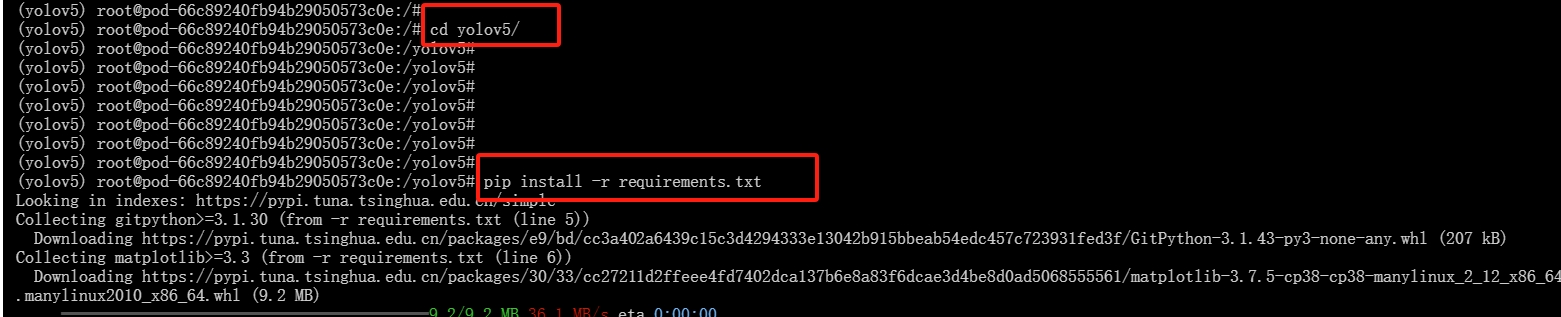
7.下载依赖包
输入下列命令
pip install -r requirements.txt
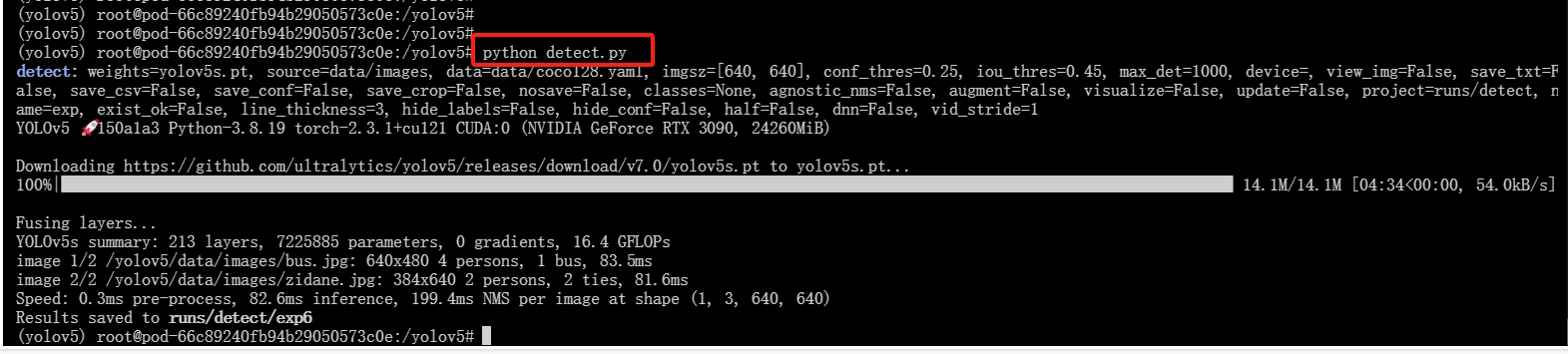
8.使用 detect.py 进行推理
输入下列命令:
python detect.py
系统会自动下载推理所用的图片及权重文件
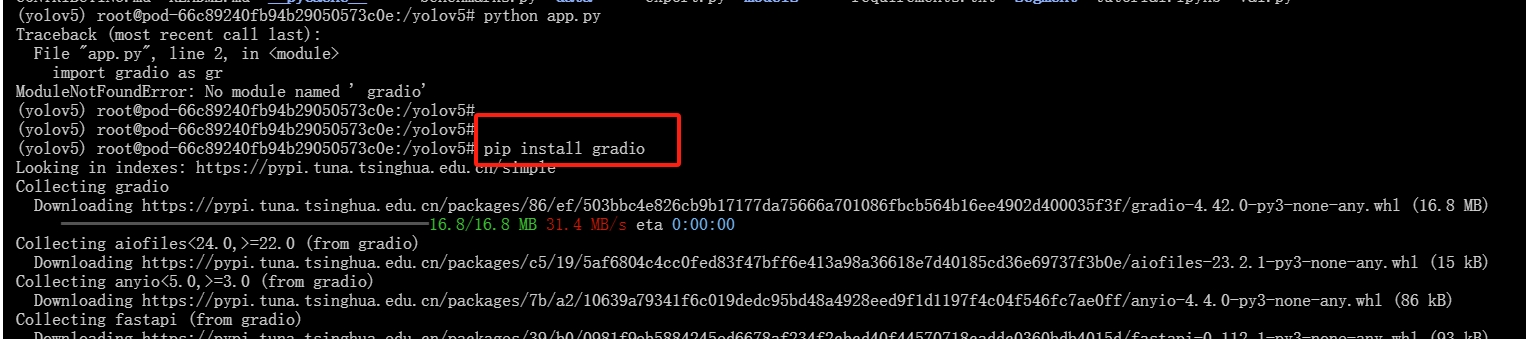
9.下载gradio
输入下列命令:
pip install gradio
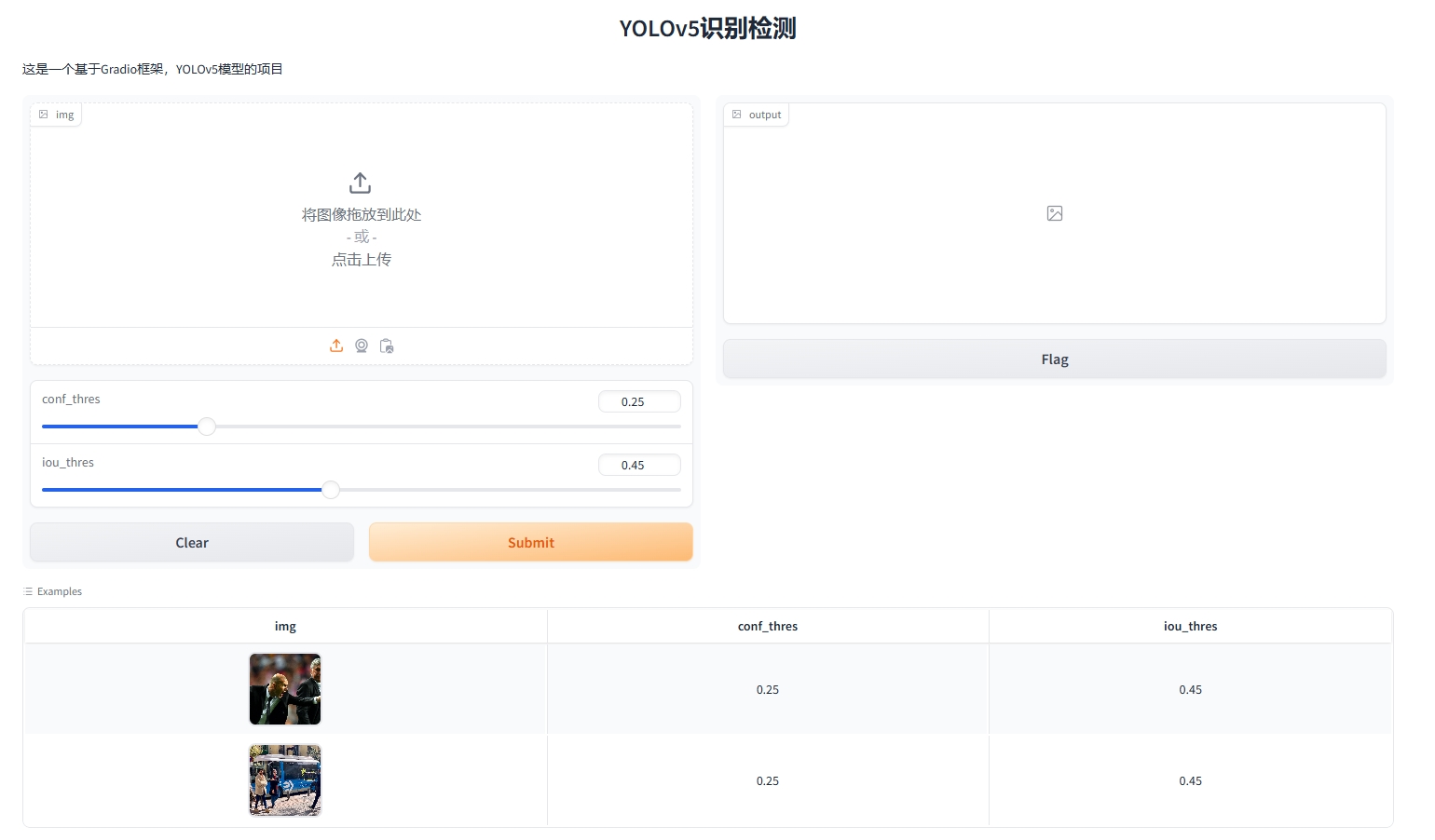
三、界面演示
对于web界面本人使用Gradio编写的,比较简洁
python gradio_app.py