2024/9/21黑马头条跟学笔记(十)
1)今日内容
1.1)定时计算流程

1.不想用户看到的全是最新的,实时计算最火的推送
2.定时计算热度最高,存redis,推送到推荐页面
1.2)使用schedule

多个服务部署,多次执行
硬编码定时时间在cron
任务失败无统计
任务量过大不能分片执行
1.3)xxljob

1.4)目录

- 概述
- 案例,linux部署环境
- 参数修改
- 定时计算,根据三连+关注计算
- 接口改,先redis热点,上下拉分页后再数据库查数据
2)xxljob概述
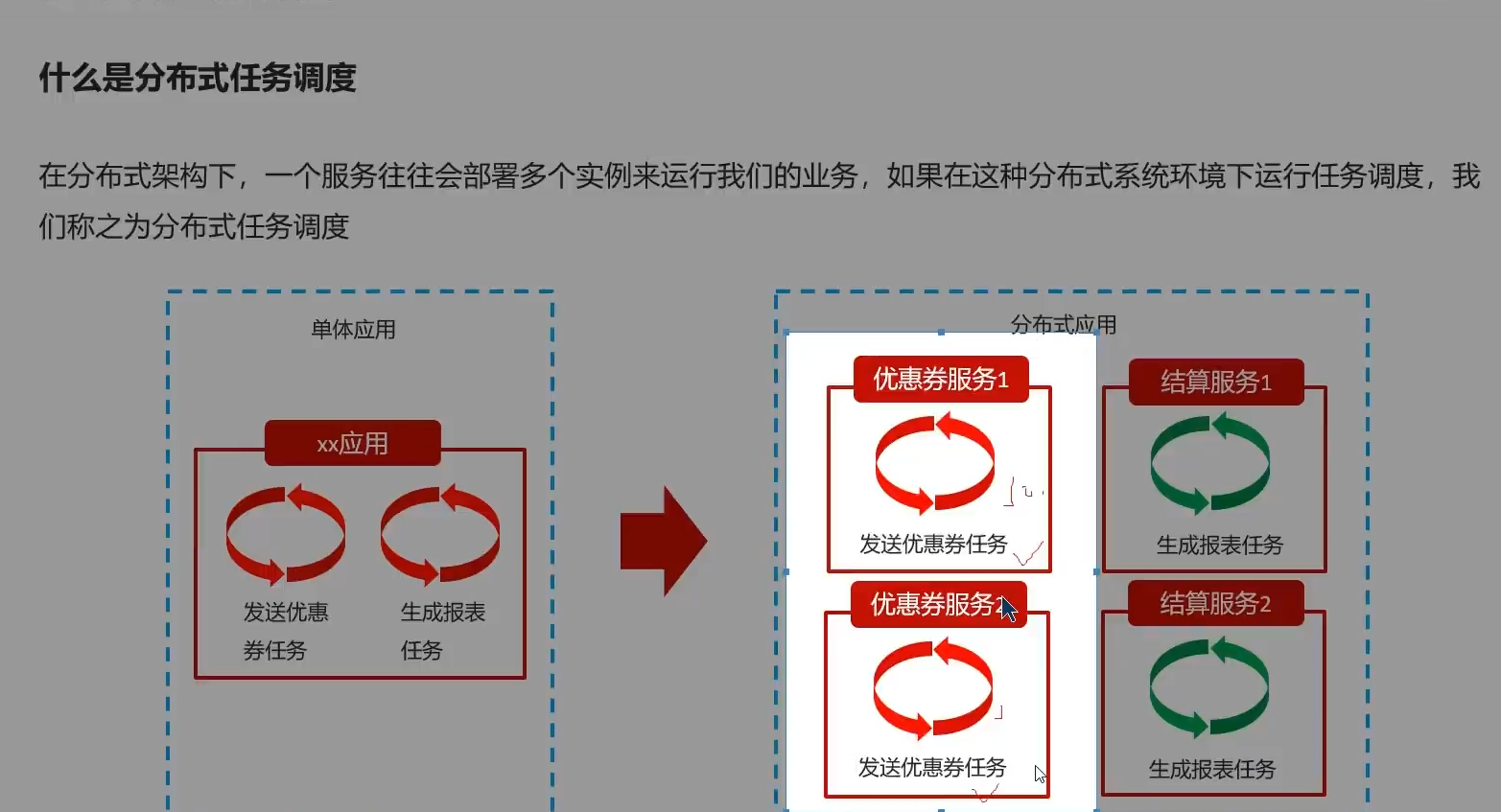
同个项目同个代码,部署多个实例,运行,定时发放优惠券任务重复

美团员工开发
开箱即用
3)环境搭建
3.1)版本

版本调一致
3.2)源码注释

3.3)搭建调度中心步骤
web后台部署本地springboot
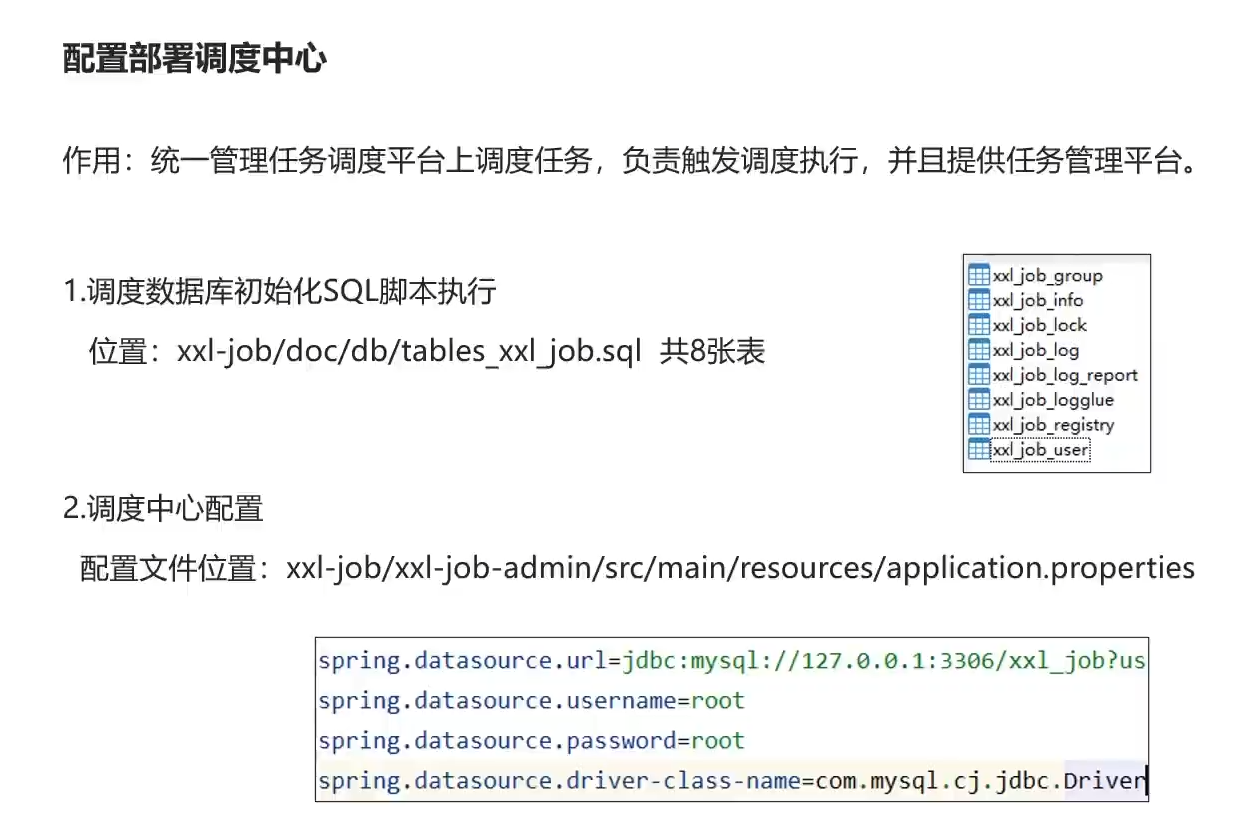
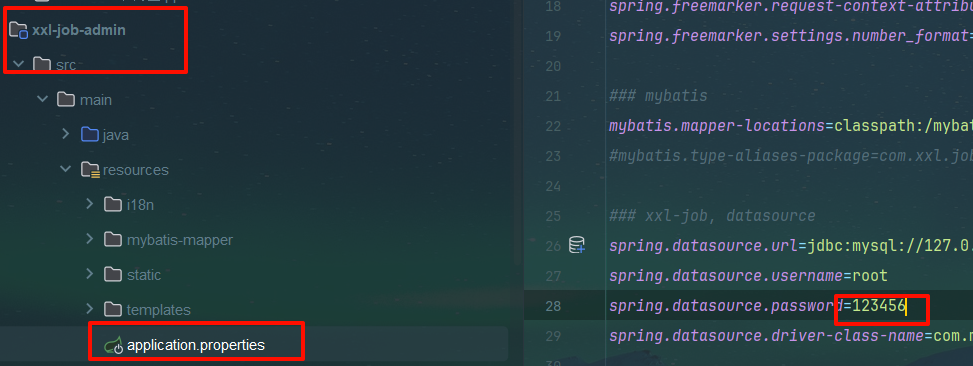
启动!
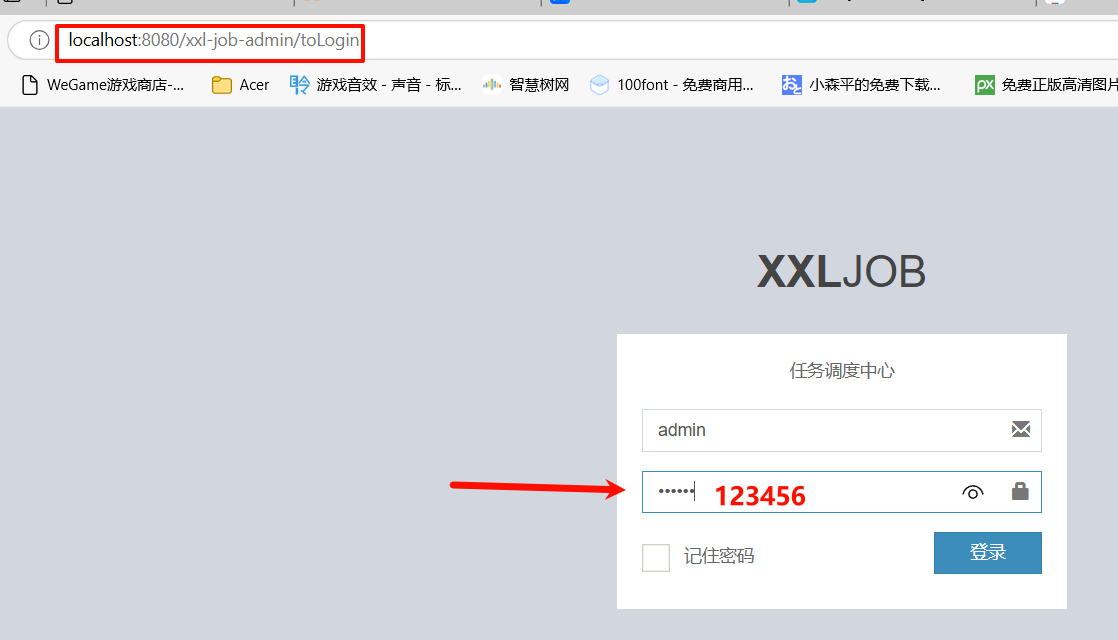
任务调度中心
用户名admin
密码123456
docker部署
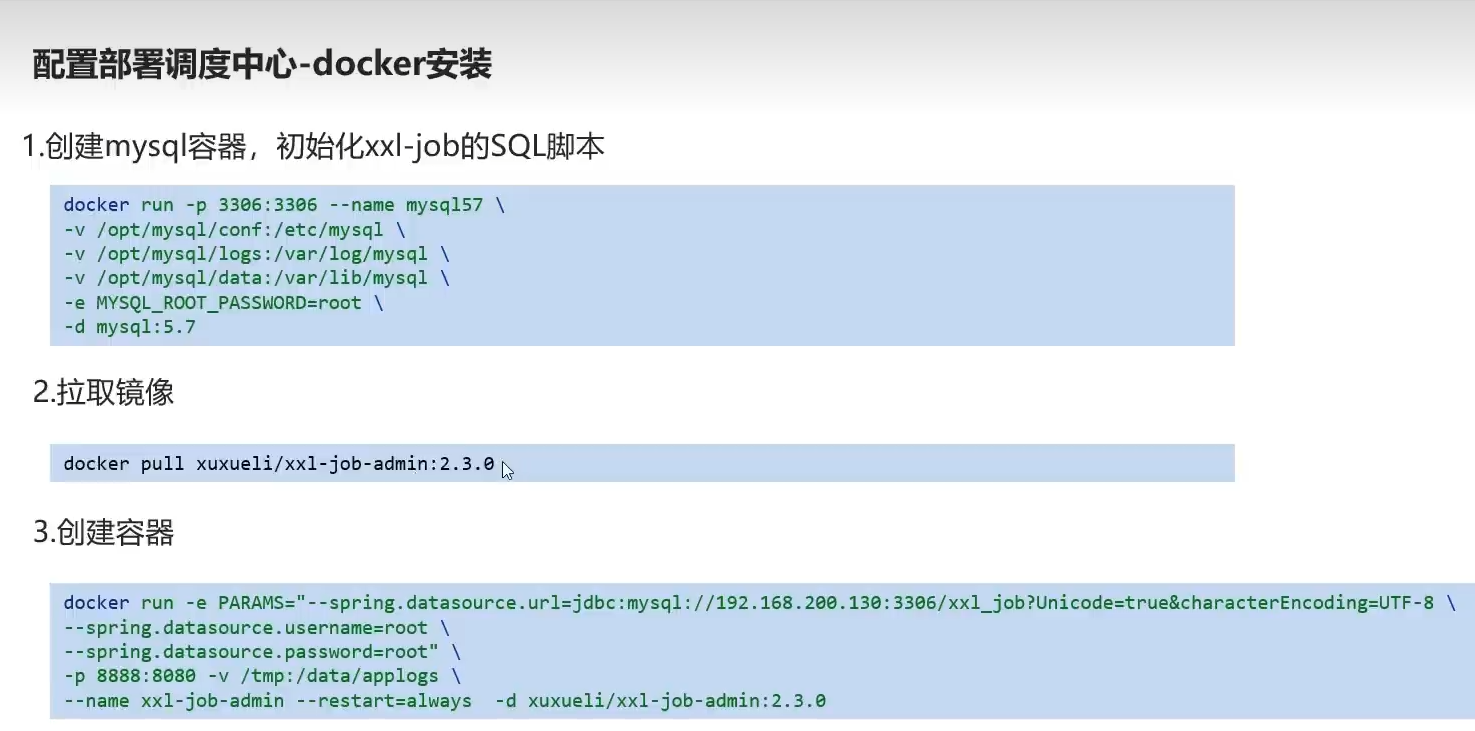
1.mysql镜像拉取
docker pull mysql:5.7
2.运行sql容器 密码我习惯123456了,手改一下
docker run -p 3306:3306 --name mysql57 \
-v /opt/mysql/conf:/etc/mysql \
-v /opt/mysql/logs:/var/log/mysql \
-v /opt/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:5.7
3.xxl-job拉取镜像
docker pull xuxueli/xxl-job-admin:2.3.0
4.创建容器
自己改mysql地址,username 和pwd
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://192.168.233.136:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 \
--spring.datasource.username=root \
--spring.datasource.password=123456" \
-p 8888:8080 -v /tmp:/data/applogs \
--name xxl-job-admin --restart=always -d xuxueli/xxl-job-admin:2.3.0
5.访问
任务调度中心
4)入门案例
4.1)概述
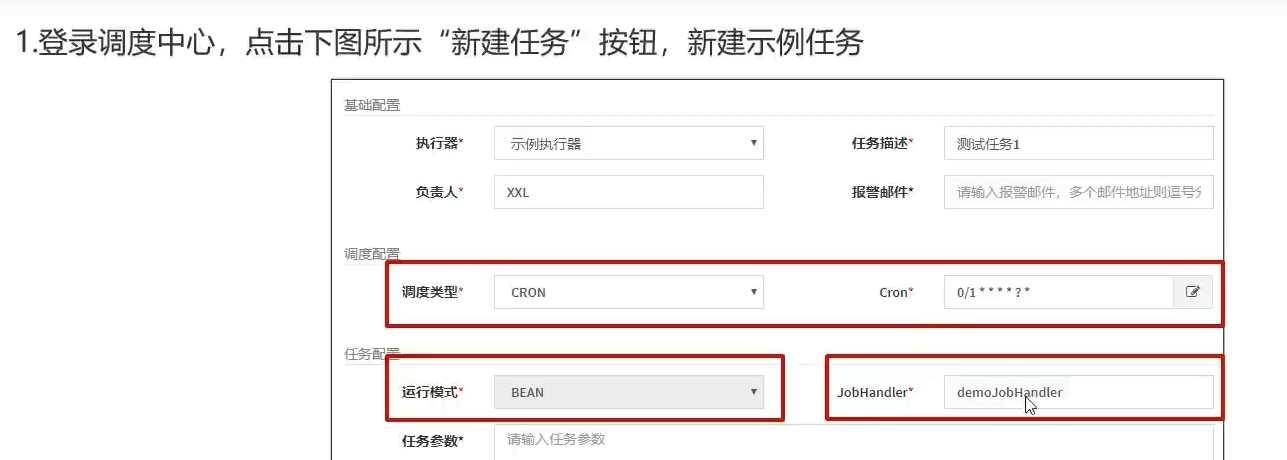
- 类型
- 时间
- 调度类为bean类型
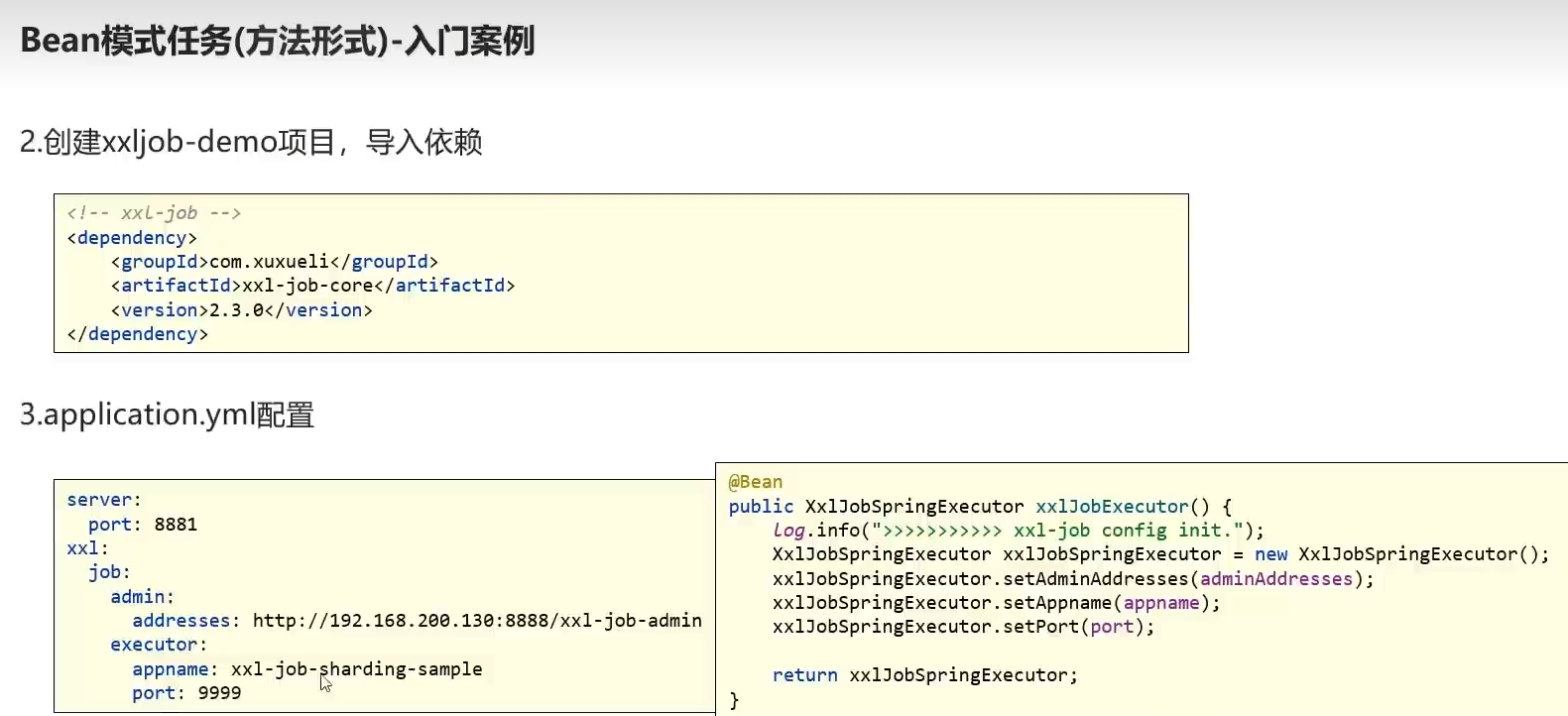

4.2)步骤
①)创建模块,导入依赖
每逢新技术,必在test搞一个新的入门案例一下
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--xxl-job-->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
②)配置文件yml
server:
port: 8881
xxl:
job:
admin:
addresses: http://192.168.233.136:8888/xxl-job-admin
executor:
appname: xxl-job-executor-sample
port: 9999
③)配置类
package com.heima.xxljob.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.port}")
private int port;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setPort(port);
return xxlJobSpringExecutor;
}
}
addresses 地址, appname 执行器名字, 执行器监听端口后,用来与xxl-admin通信且访问执行其相关接口
④)hello job
package com.heima.xxljob.job;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
@Component
public class HelloJob {
@XxlJob("demoJobHandler")
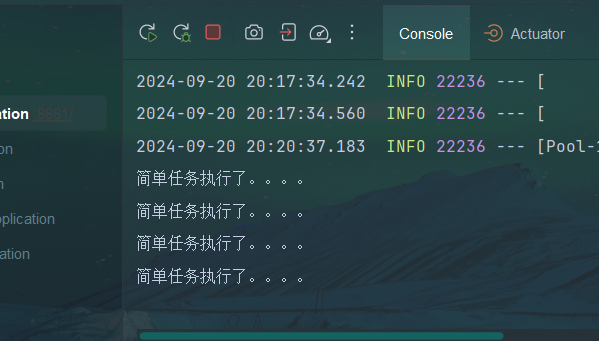
public void helloJob(){
System.out.println("简单任务执行了。。。。");
}
}
@xxljob注解后面跟着执行器的名字
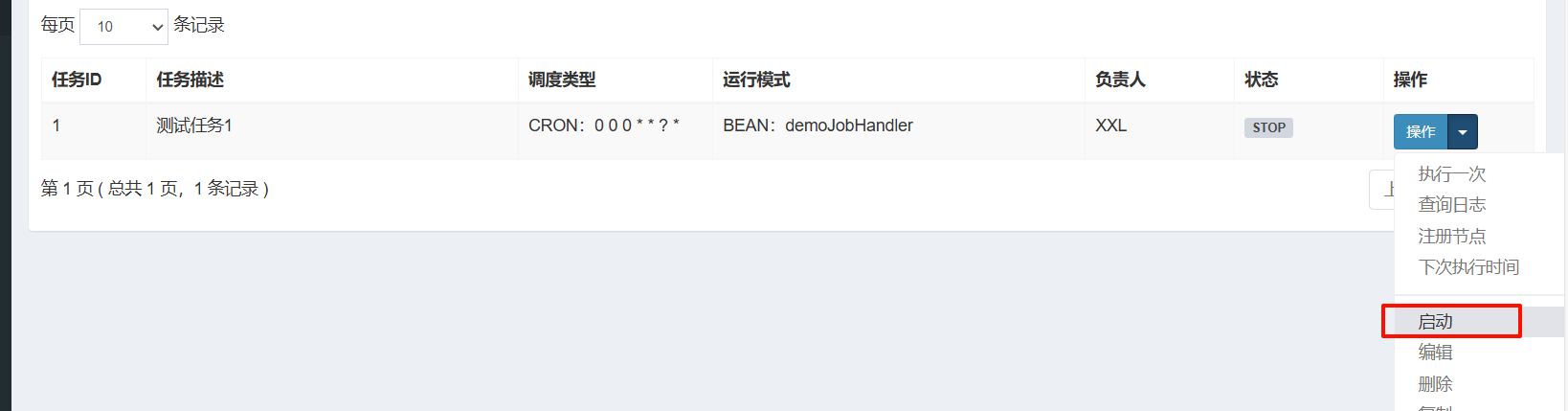
⑤)启动引导类,启动任务
4.3)执行器详解
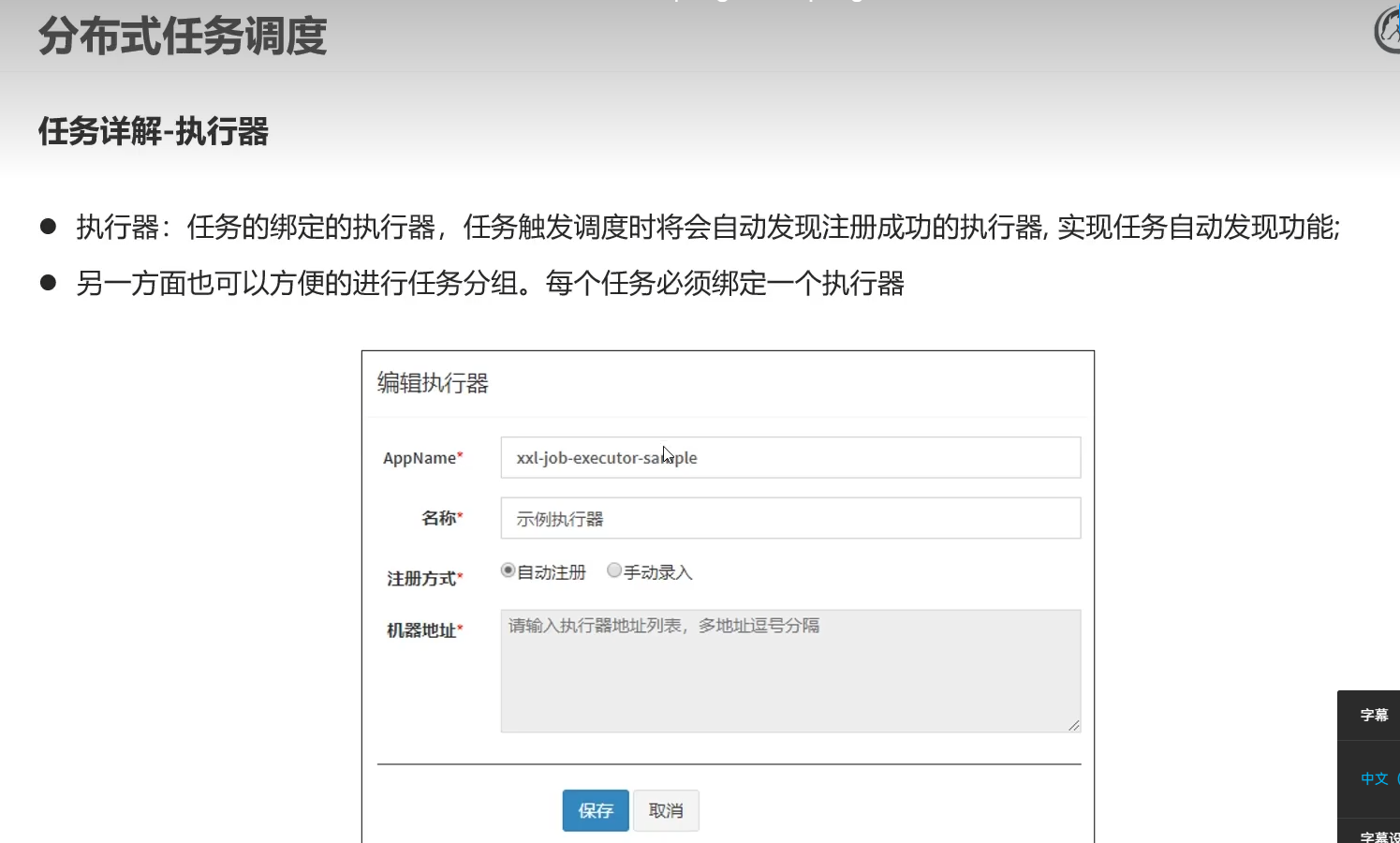
执行器,针对不同任务进行了一个分组
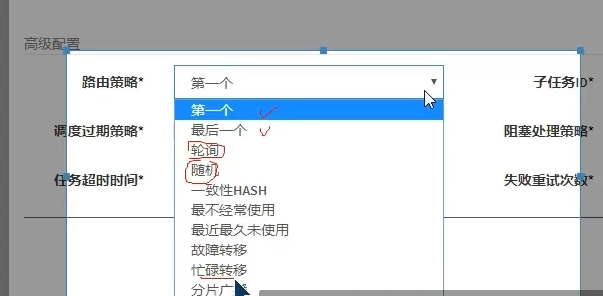
路由策略,感觉和负载均衡差不多
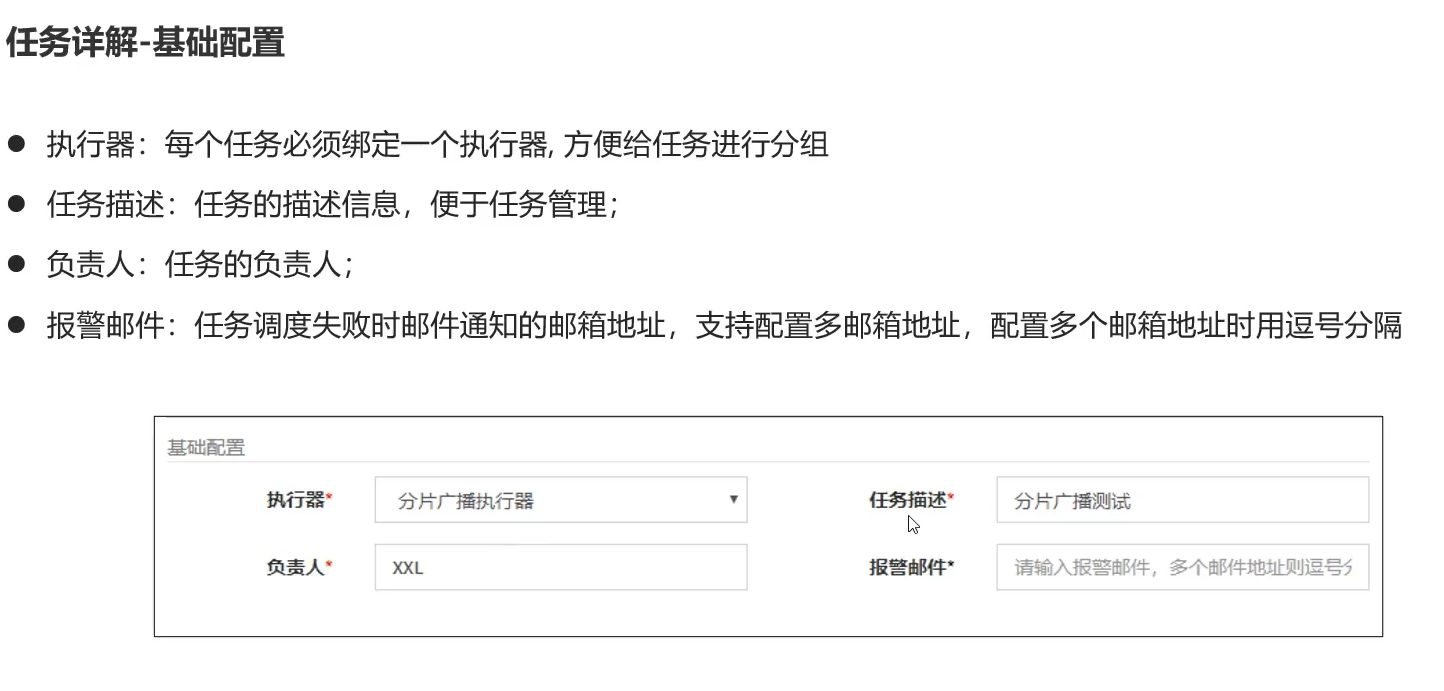
配置
- 负责人
- 邮件
4.4)任务详解
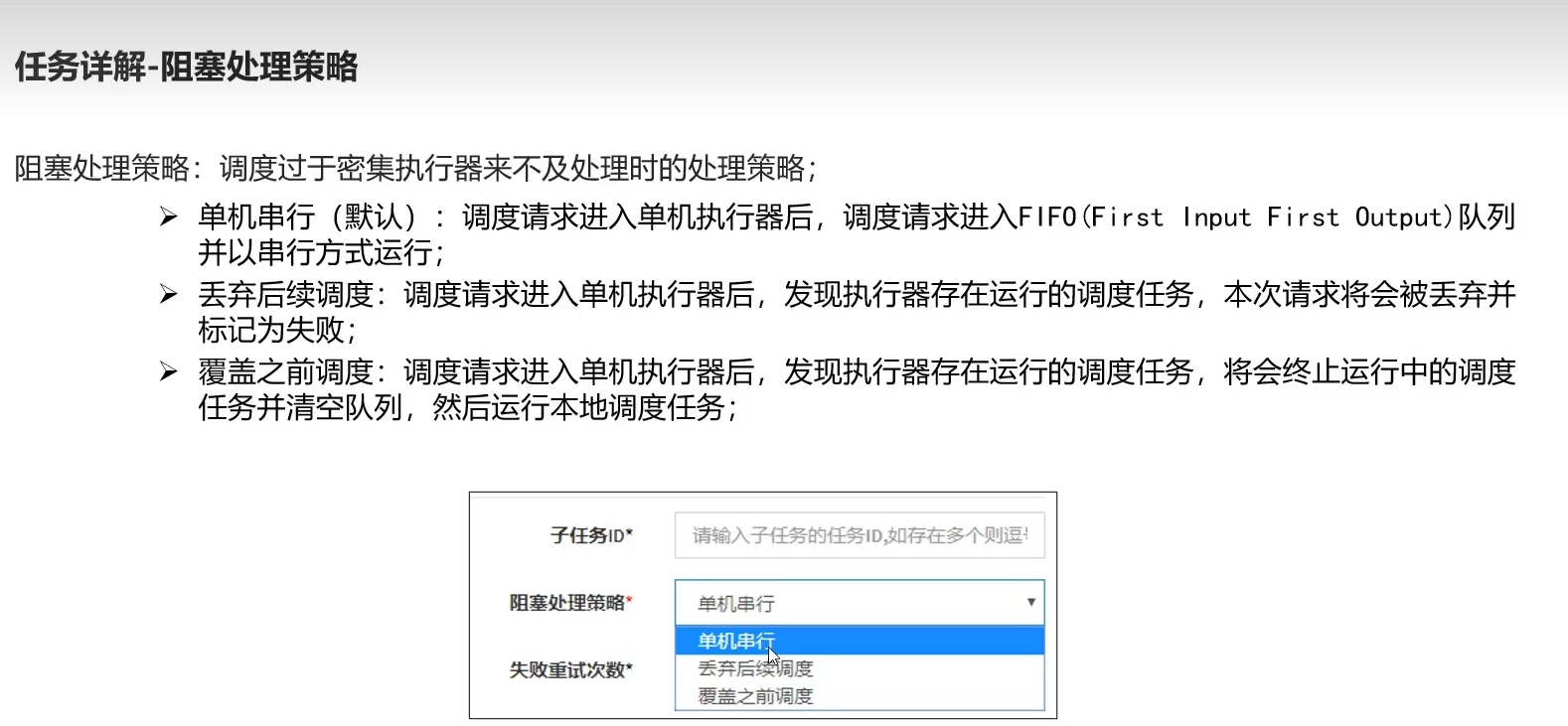
4.5)路由策略

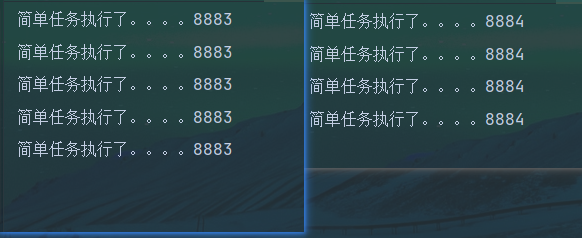
5)路由策略(轮询案例)
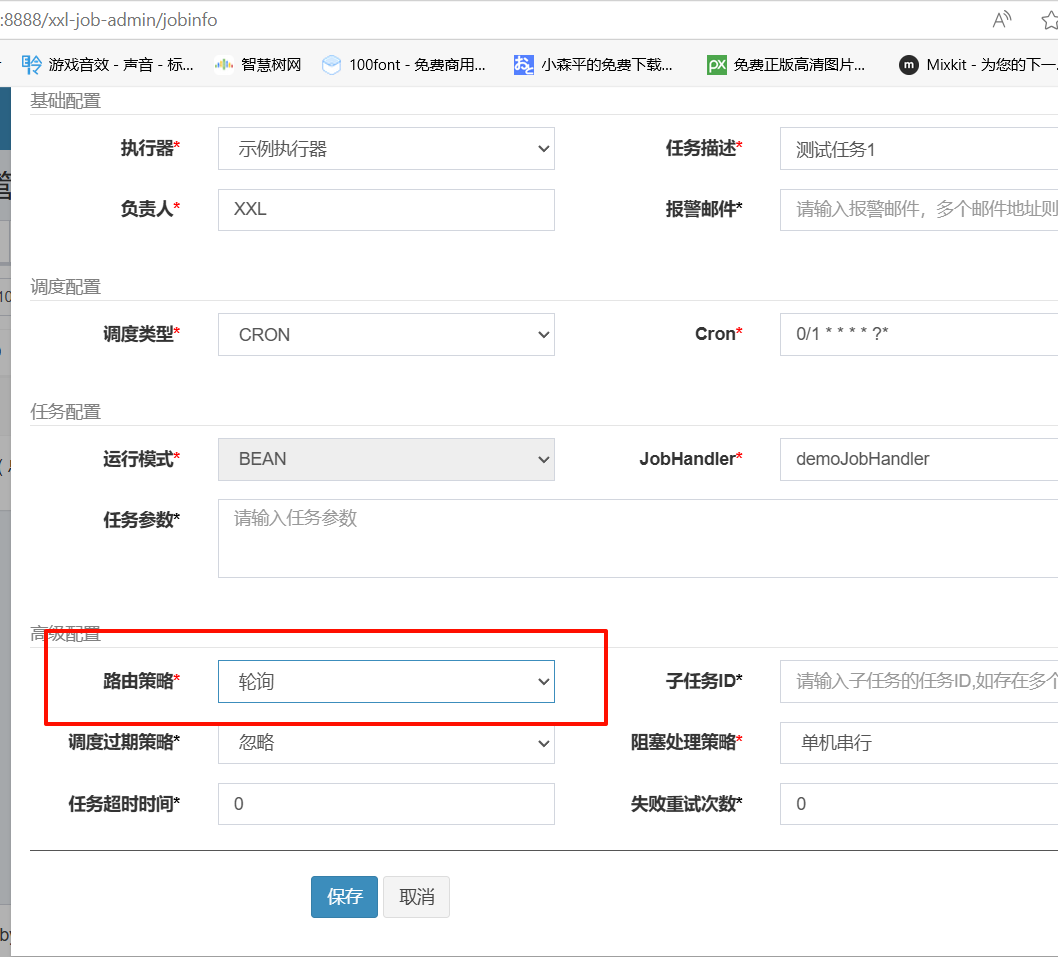
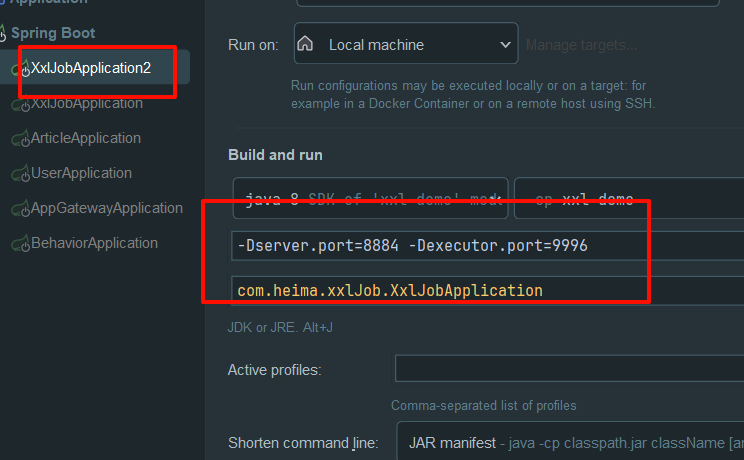
复制修改端口后启动
6)路由策略(分片广播)
6.1)概述
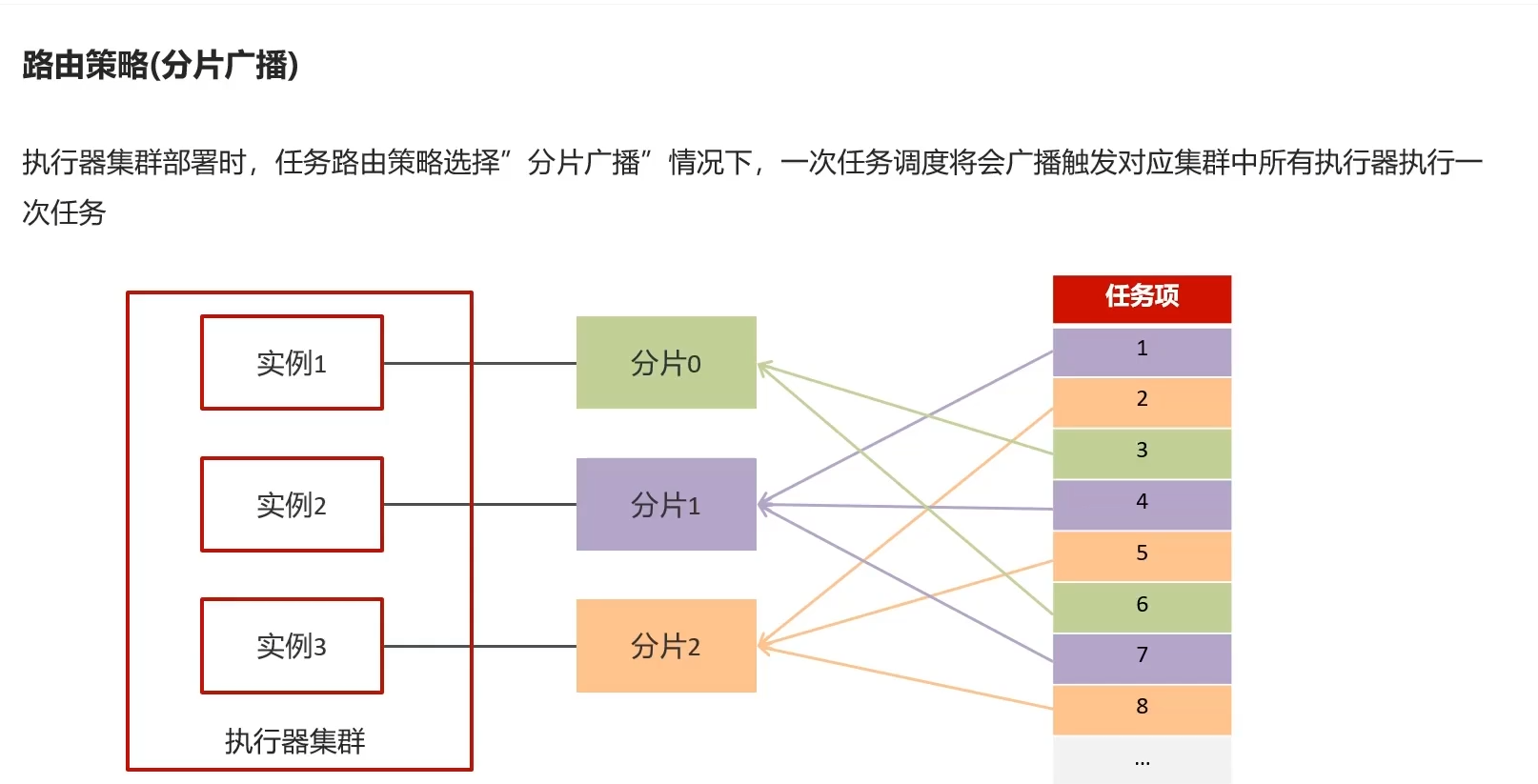
场景:支付宝,还款提醒
方法,任务项id取模 派发到哪个分片对应的实例上
6.2)新建执行器
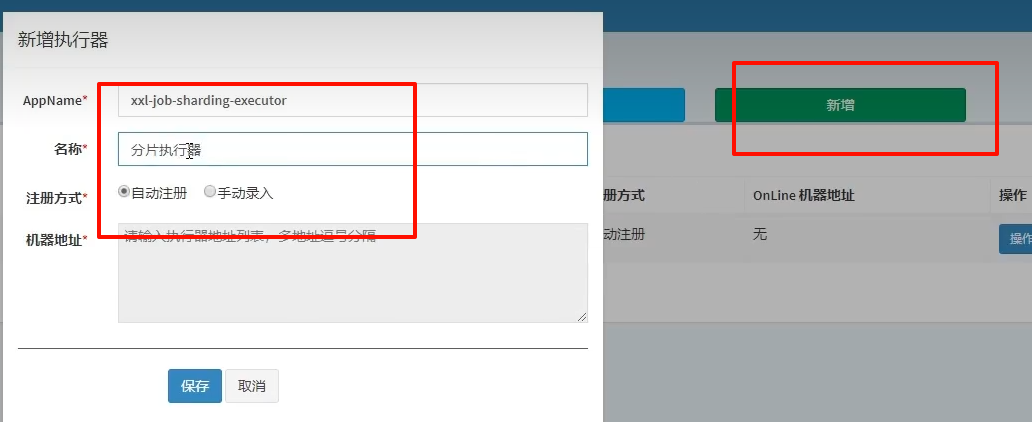
6.3)新建任务
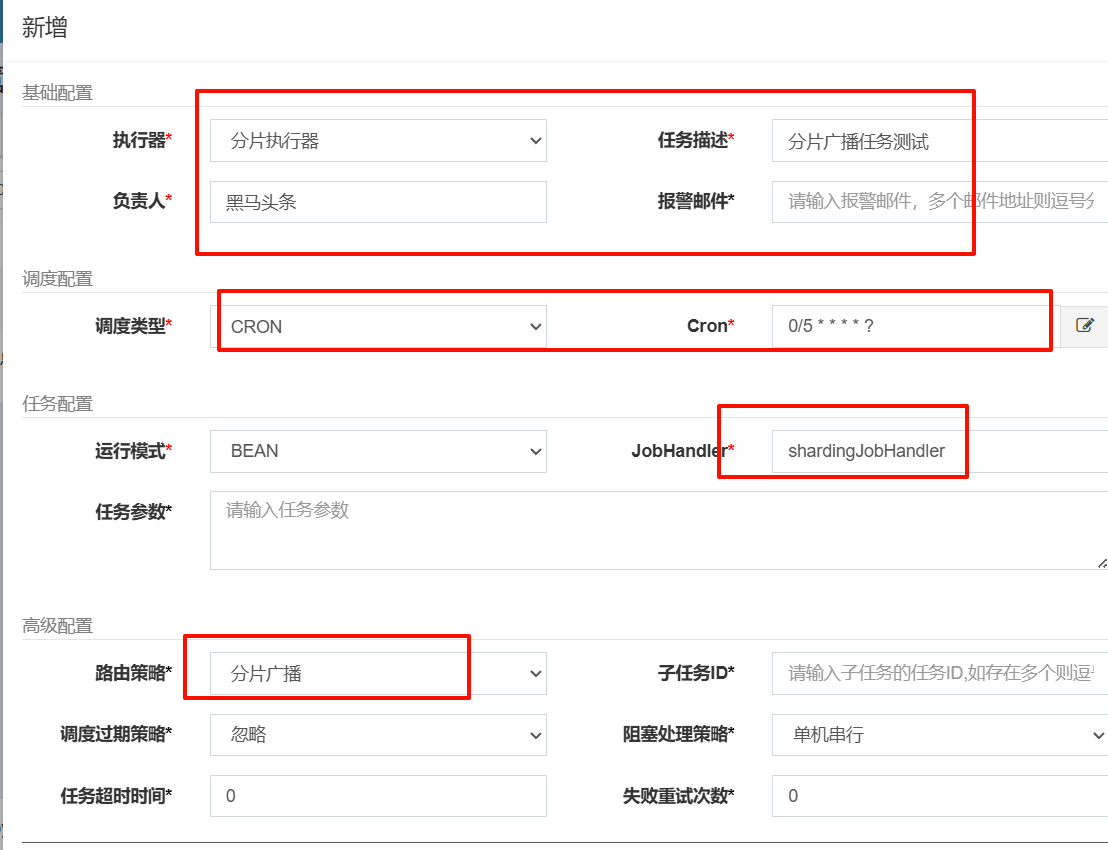

6.4)修改配置文件
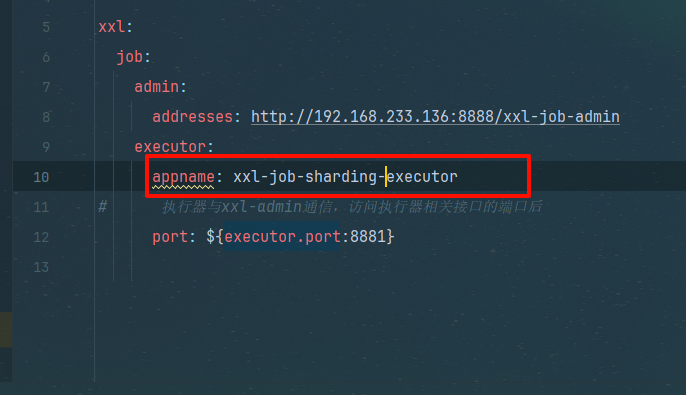
xxl-job-sharding-executor
6.5)新增方法
@XxlJob("shardingJobHandler")
public void shardingJob() {
//分片的参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
List<Integer> integers = genList();
for (int i = 0; i < 1000; i++) {
if (i%shardTotal==shardIndex){
System.out.println("分片"+shardIndex+"执行了"+i);
}
}
}
List<Integer> genList() {
List<Integer> integers = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
integers.add(i);
}
return integers;
}
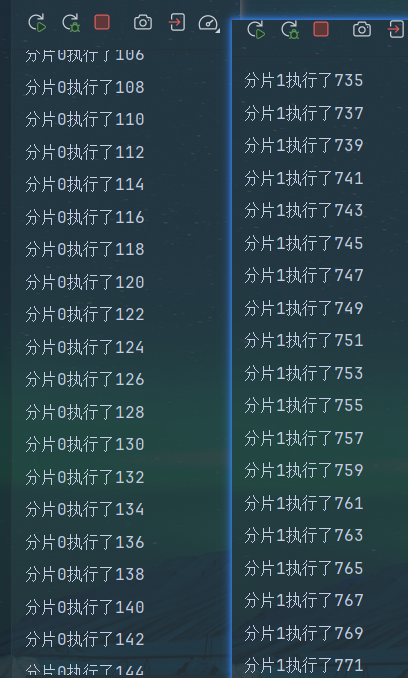
对某个值 取模运算,可以得到 小于某个值的所有数,(类似求0~X的随机值)
因此我们可以确定好每一轮应该分配给哪几个分片
假设现在有两个分片 总数为2
任务0%2==0 那就让分片0去执行
任务1%2==1 那就让分片1去执行
任务2%2==0 那就让分片0去执行(新的一轮)
对这个方法起个名字好记一点 叫均分法吧,就是能让所有人均匀的分配所有任务
确定任务分给哪个分片公式为 当前任务索引%总数===当前分片
由于当前分片不可能大于总分片数,因此当前分片无论%总数都等于自己,
结论
总任务取模与总人数,能将所有任务均分给每一个人
- (任务索引)对比自己大(总人数)的取模,都为(任务索引)本身
相当于每个任务索引向总人数拿了把铲子给自己挖了个1米的坑,将自己的劳动(分片)埋进去
- 对比自己小的,说明新的一轮了,取模值又重新递增,再往下挖深了1米,直到所有任务结束(坑挖到底了)
取模运算所得值==均匀分配
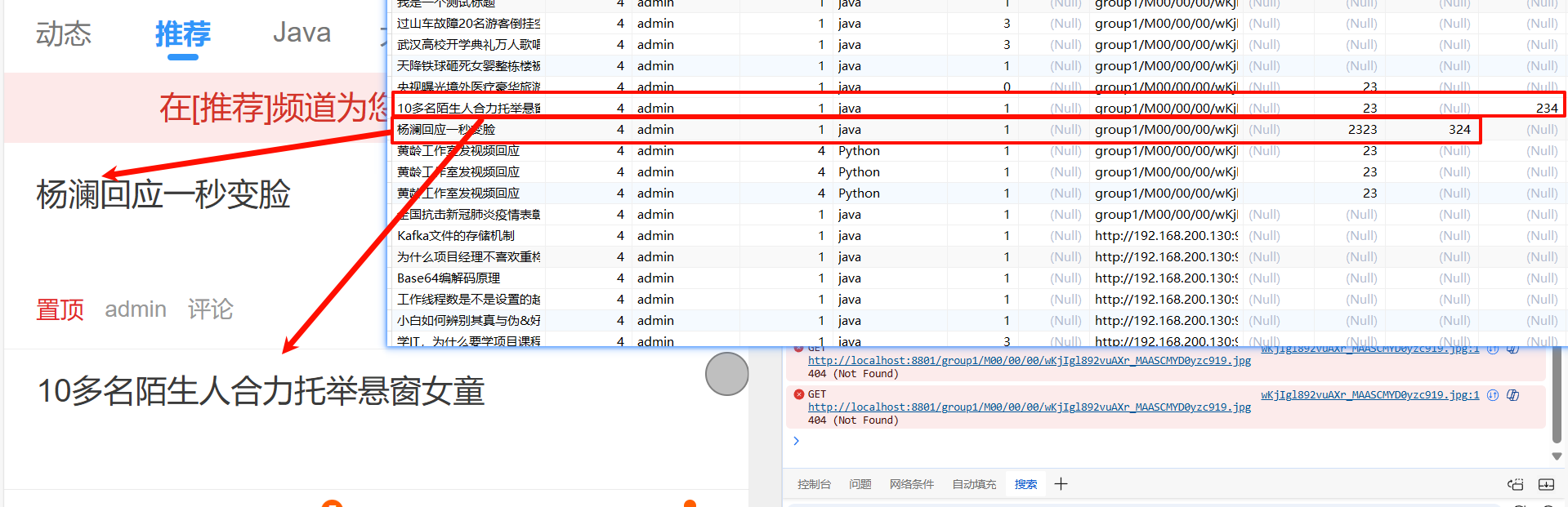
7)热度计算
7.1)概述
点赞收藏评论阅读数量计算
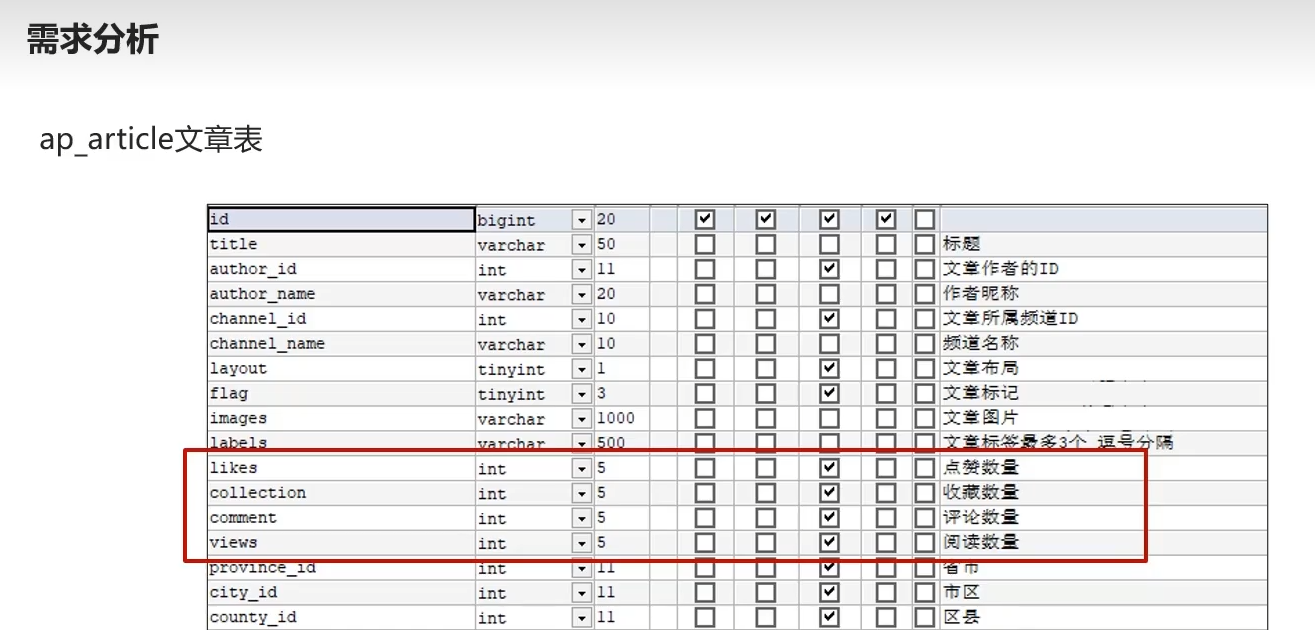
7.2)需求分析
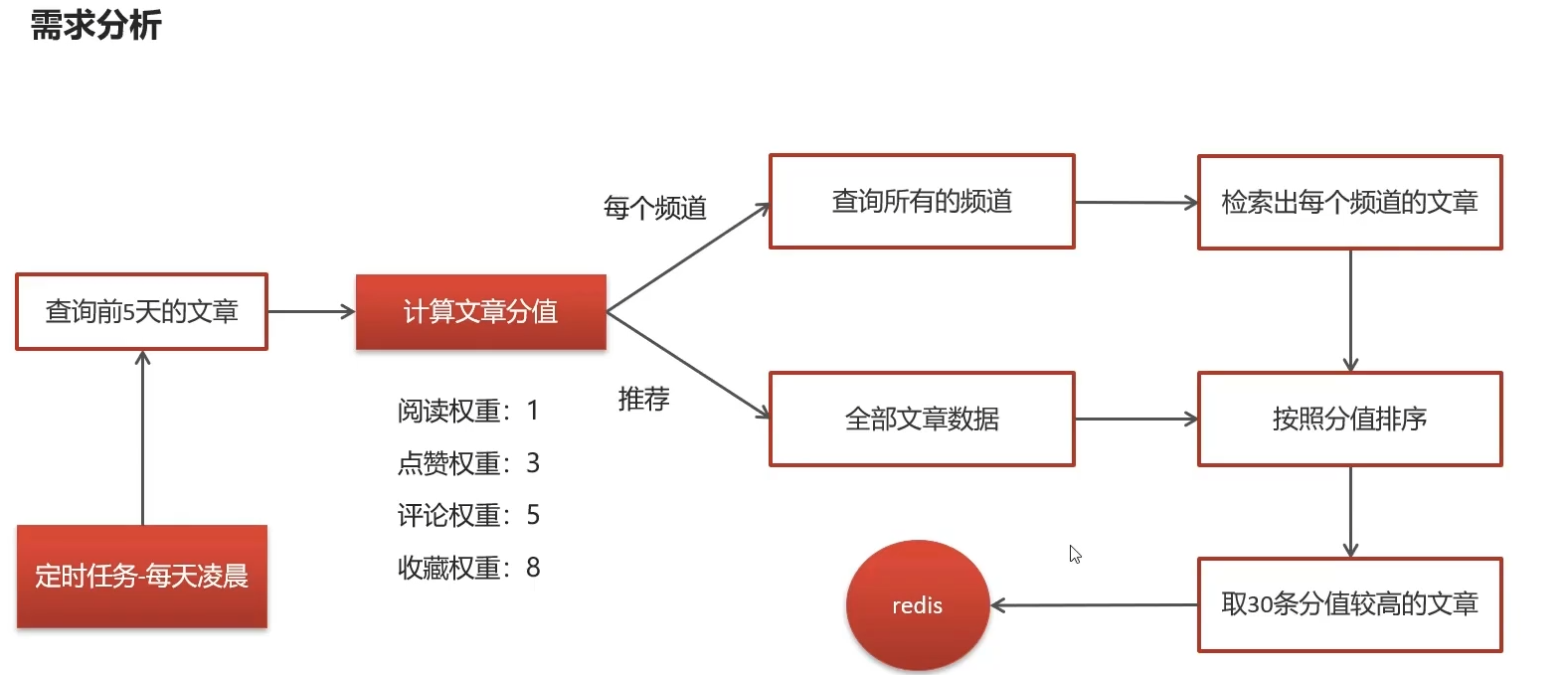
范围,近五天
分值权重分配
每个频道(省赛)选出前三十的高手 放频道redis里
所有频道(国赛)选出前三十的高手 放推荐redis里
凌晨2点定时计算
7.3)代码
思路
1.查所有
2.根据所有计算分值,成新列表
3.远程拿所有频道(接口+Impl),循环频道,article符合频道id则分为一组
4.分组后在从组里挑前30条,存redis
mapper
/**
* 找近5天的文章
*/
List<ApArticle> findArticleListByLast5Days(@Param("dayParam") Date dayParam);
mapperXML
<select id="findArticleListByLast5Days" resultType="com.heima.model.article.pojos.ApArticle">
select * from `ap_article` aa
LEFT JOIN ap_article_config aac ON aa.id=aac.article_id
<where>
and aac.is_delete!=1
and aac.is_down!=1
<if test="dayParam!=null">
and aa.publish_time <![CDATA[>=]]> #{dayParam}
</if>
</where>
</select>
思路
//1.查五天前文章
//2.计算文章的分支
//3.每个频道缓存30条牛逼文章
service
public interface HotArticleService {
/**
* 计算热点文章
*/
void computedHotArticle();
}
impl
@Service
@Slf4j
public class HotArticleServiceImpl implements HotArticleService {
@Autowired
private ApArticleMapper apArticleMapper;
@Autowired
private IWemediaClient wemediaClient;
/**
* 计算热点文章
*/
@Override
public void computedHotArticle() {
// 1.查五天前文章
Date date = DateTime.now().minusDays(1935).toDate();
List<ApArticle> articleListByLast5Days = apArticleMapper.findArticleListByLast5Days(date);
List<HotArticleVo> hotArticleVoList = computeScoredArticle(articleListByLast5Days);
// 3.每个频道缓存30条牛逼文章
cache30Redis(hotArticleVoList);
}
private void cache30Redis(List<HotArticleVo> hotArticleVoList) {
// 3.远程拿所有频道,循环频道,article符合频道id则分为一组
ResponseResult result = wemediaClient.getChannels();
if (result.getCode().equals(200)) {
String jsonString = JSON.toJSONString(result.getData());
List<WmChannel> wmChannels = JSON.parseArray(jsonString, WmChannel.class);
for (WmChannel wmChannel : wmChannels) {
List<HotArticleVo> collectGroupByChannelId = hotArticleVoList.stream().filter(x -> x.getChannelId().equals(wmChannel.getId())).collect(Collectors.toList());
// 4.分组后在从组里挑前30条,存redis
sortAndCache(collectGroupByChannelId, ArticleConstants.HOT_ARTICLE_FIRST_PAGE + wmChannel.getId());
}
}
//6.最后是推荐页面也就是最牛逼的也就是国赛的前30
sortAndCache(hotArticleVoList,ArticleConstants.HOT_ARTICLE_FIRST_PAGE+ArticleConstants.DEFAULT_TAG);
}
@Autowired
private CacheService cacheServicel;
private void sortAndCache(List<HotArticleVo> collectGroupByChannelId, String key) {
collectGroupByChannelId = collectGroupByChannelId.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());
// 5. 如果大于30条,保留前30,设置缓存
if (collectGroupByChannelId.size() > 30) {
collectGroupByChannelId.subList(0, 30);
}
cacheServicel.set(key, JSON.toJSONString(collectGroupByChannelId));
}
private List<HotArticleVo> computeScoredArticle(List<ApArticle> articleListByLast5Days) {
List<HotArticleVo> hotArticleVos = new ArrayList<>();
if (articleListByLast5Days != null) {
for (ApArticle articleListByLast5Day : articleListByLast5Days) {
// 2.计算文章的分值
Integer score = computedGoal(articleListByLast5Day);
HotArticleVo hotArticleVo = new HotArticleVo();
BeanUtils.copyProperties(articleListByLast5Day,hotArticleVo);
hotArticleVo.setScore(score);
hotArticleVos.add(hotArticleVo);
}
}
return hotArticleVos;
}
private Integer computedGoal(ApArticle apArticle) {
Integer score = 0;
if(apArticle.getLikes() != null){
score += apArticle.getLikes() * ArticleConstants.HOT_ARTICLE_LIKE_WEIGHT;
}
if(apArticle.getViews() != null){
score += apArticle.getViews();
}
if(apArticle.getComment() != null){
score += apArticle.getComment() * ArticleConstants.HOT_ARTICLE_COMMENT_WEIGHT;
}
if(apArticle.getCollection() != null){
score += apArticle.getCollection() * ArticleConstants.HOT_ARTICLE_COLLECTION_WEIGHT;
}
return score;
}
}
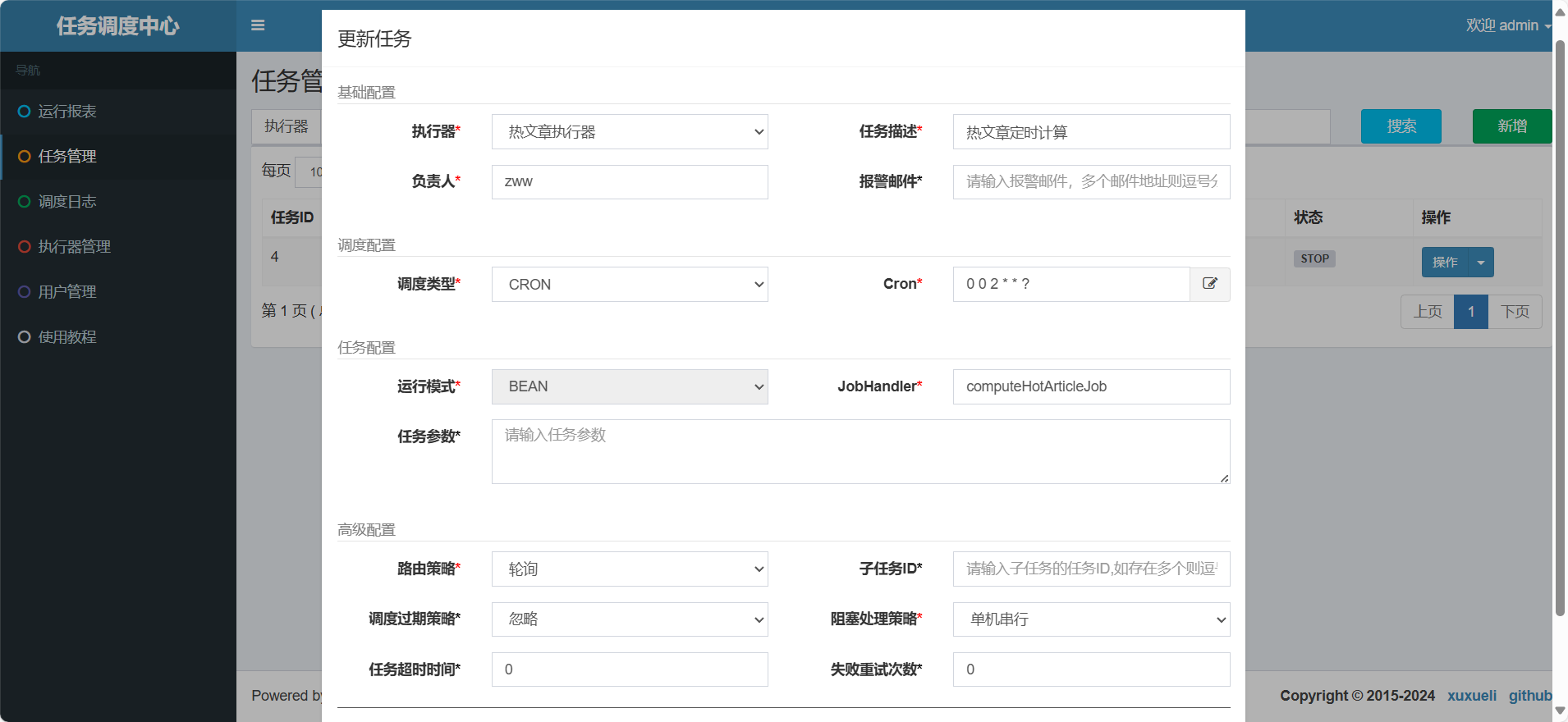
7.4)定时任务
执行器
任务
依赖
article服务新增
<!--xxl-job-->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
配置类
package com.heima.article.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.port}")
private int port;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setPort(port);
return xxlJobSpringExecutor;
}
}
配置文件(nacos)
xxl:
job:
admin:
addresses: http://192.168.233.136:8888/xxl-job-admin
executor:
appname: xxl-job-hotArticle-exectuor
port: 9999
任务类
package com.heima.article.job;
import com.heima.article.service.HotArticleService;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class ComputeHotArticleJob {
@Autowired
private HotArticleService hotArticleService;
@XxlJob("computeHotArticleJob")
public void handle(){
log.info("热文章分值计算调度任务开始执行...");
hotArticleService.computeHotArticle();
log.info("热文章分值计算调度任务结束...");
}
}

8)查询接口改造
8.1)思路
1.每个频道第一次进入,默认redis前30,后续下滑刷新更多,就从数据库里找(好家伙这不会重复吗)
2.写一个loadHotOrMore 根据
8.2)代码
再ApArticleService里
service
/**
* 加载文章列表
* @param dto
* @param type 1 加载更多 2 加载最新
* @return
*/
ResponseResult loadFirstPage(ArticleHomeDto dto, Short type);
impl
/**
* 加载文章列表
*
* @param dto
* @param type 1 加载更多 2 加载最新
* @return
*/
@Override
public ResponseResult loadFirstPage(ArticleHomeDto dto, Short type) {
// 1.从redis里查出来对应频道的首页30条
String jsonString = cacheService.get(ArticleConstants.HOT_ARTICLE_FIRST_PAGE + dto.getTag());
List<HotArticleVo> hotArticleVoList = JSON.parseArray(jsonString, HotArticleVo.class);
return ResponseResult.okResult(hotArticleVoList);
}
controller
/**
* 加载首页
* @param dto
* @return
*/
@PostMapping("/load")
public ResponseResult load(@RequestBody ArticleHomeDto dto) {
// return apArticleService.load(dto, ArticleConstants.LOADTYPE_LOAD_MORE);
return apArticleService.loadFirstPage(dto, ArticleConstants.LOADTYPE_LOAD_MORE);
}