Oracle 启动动态采样 自适应执行计划
为了解决因为统计信息缺失或者统计不够准确而引起的问题,从9iR2的版本开始Oracle推出了动态采样(Dynamic Sampling)功能,使SQL文在硬解析过程中动态地收集统计信息。 该功能在以后的版本上得到更进一步的增强,从11.2.0.4版本改称为动态统计(Dynamic Statistics 以后简称DS )。
1.什么是动态统计(Dynamic Statistics)或者动态采样(Dynamic Sampling)?
2.为什么要使用动态统计?
3.动态统计都有哪些级别,各个级别都有什么区别?
4.如何确认采用了动态统计功能?
5.动态统计在各个版本上有什么区别?
6.如何禁用动态统计和12c的自动动态统计?
7.动态统计的利弊,常见问题?下面章节将针对以上的问题进行解答和说明:
什么是动态统计(Dynamic Statistics)或者动态采样(Dynamic Sampling)?
动态采样是Oracle从9iR2的版本开始推出的一项优化技术,通过执行一些递归SQL(recursive SQL )来随机访问表块,收集一些采样信息,来预估谓词的选择率(selectivities)。
9i以后的版本中不断进行功能加强,在11.2.0.4版本改称为动态统计(Dynamic Statistics)。 在12c版本后进一步推出自动动态统计(Automatic Dynamic Statistics)。
为什么要使用动态统计?
如同前面叙述的,如果由于选择执行计划的Object统计信息缺失、过期或者不足时,CBO优化器选择的执行计划就有可能不是最优的甚至是最差的。 有还不如没有
所以为了保证优化器在SQL硬解析时选择到最优的执行计划,根据数据库动态统计的设置级别,进行动态收集Object的统计信息。
动态统计都有哪些级别,各个级别都有什么区别?
数据库动态统计的级别主要通过参数OPTIMIZERDYNAMICSAMPLING的值(同级别)来决定。
关于OPTIMIZERDYNAMICSAMPLING的值(同级别)和动态统计启用的条件可以参考下表:

※其中样本大小的数据块数可以由隐含参数optimizerdynsmpblks来控制(默认值为32)。
blocks数 ,这个好像有时候不能触发自动采样,如果发现statistics为0 而blocks为XXXX自动采样就好了,但是有个可能就是表被全部delete掉了。
如何确认采用了动态统计功能?
我们可以通过以下的方法来确认一个查询是否使用了动态统计功能:
代码语言:javascript
复制
1.利用DBMS_XPLAN.DISPLAY_CURSOR功能查看是否使用了DS
2.利用Optimizer Trace(10053 Trace)查看是否使用了DS
3.利用SQL Trace(10046 Trace)查看是否使用了DS我们通过以下的例子,来看一下查看某个查询是否使用动态统计。 (在12.1.0.2版本上进行测试)
代码语言:javascript
复制
---首先我们准备查询用的数据
SQL> conn SH/SH
Connected.
---查看optimizer_dynamic_sampling的级别
SQL> SHOW PARAMETERS optimizer_dynamic_sampling
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 2
---使统计信息缺失,以便采用动态统计
SQL> EXEC DBMS_STATS.DELETE_SCHEMA_STATS('sh');
PL/SQL procedure successfully completed.
---设定Optimizer Trace(10053 Trace)和SQL Trace(10046 Trace)
SQL> alter session set tracefile_identifier='sampling_10053_10046';
Session altered.
SQL> alter session set statistics_level=all;
Session altered.
SQL> alter session set max_dump_file_size = unlimited;
Session altered.
SQL> alter session set events '10046 trace name context forever, level 12';
Session altered.
SQL> ALTER SESSION SET EVENTS '10053 trace name context forever, level 1';
Session altered.
---执行SQL文
SQL> SELECT /* statis sampling1 */
2 p.prod_name, COUNT(*)
3 FROM sales s,
4 products p
5 WHERE s.time_id >= TO_DATE(' 1997-07-01 00:00:00',
6 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
7 AND s.time_id < TO_DATE(' 1998-04-01 00:00:00',
8 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
9 AND s.prod_id = p.prod_id
10 GROUP BY
11 p.prod_name;
PROD_NAME COUNT(*)
-------------------------------------------------- ----------
...
60 rows selected.
---通过dbms_xplan.display_cursor查看执行计划。
SQL> SET PAGES 2000 LIN 300
SQL> select * from table(dbms_xplan.display_cursor(null,null,'NOTE ALLSTATS LAST'));
SQL_ID 62054vzrc3rcr, child number 0
-------------------------------------
SELECT /* statis sampling1 */ p.prod_name, COUNT(*) FROM sales
s, products p WHERE s.time_id >= TO_DATE(' 1997-07-01
00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
AND s.time_id < TO_DATE(' 1998-04-01 00:00:00', 'SYYYY-MM-DD
HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN') AND s.prod_id = p.prod_id
GROUP BY p.prod_name
Plan hash value: 1538978877
----------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
----------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 60 |00:00:00.64 | 2339 | | | |
| 1 | HASH GROUP BY | | 1 | 44240 | 60 |00:00:00.64 | 2339 | 974K| 974K| 3016K (0)|
|* 2 | HASH JOIN | | 1 | 44240 | 43687 |00:00:00.57 | 2339 | 1185K| 1185K| 1598K (0)|
| 3 | TABLE ACCESS FULL | PRODUCTS | 1 | 72 | 72 |00:00:00.01 | 4 | | | |
| 4 | PARTITION RANGE ITERATOR | | 1 | 44240 | 43687 |00:00:00.33 | 2335 | | | |
| 5 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| SALES | 2 | 44240 | 43687 |00:00:00.21 | 2335 | | | |
| 6 | BITMAP CONVERSION TO ROWIDS | | 1 | | 43687 |00:00:00.06 | 4 | | | |
|* 7 | BITMAP INDEX RANGE SCAN | SALES_TIME_BIX | 1 | | 90 |00:00:00.01 | 4 | | | |
---------------------------------------------------------------------------------------------------------------------------------------------------
-Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="P"."PROD_ID")
7 - access("S"."TIME_ID">=TO_DATE(' 1997-07-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "S"."TIME_ID"<TO_DATE(' 1998-04-01 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))Note
-----
- dynamic statistics used: dynamic sampling (level=2) ★
- this is an adaptive plandbmsxplan.displaycursor
我们可以看到,通过dbmsxplan.displaycursor输出的执行计划有如下的Note内容: 采用了级别为2的动态统计。
代码语言:javascript
复制
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
10053
然后我们再看一看Optimizer Trace(10053 Trace)中关于动态统计的部分输出,并有包含/* OPTDYNSAMP */ 提示的递归调用SQL文: (详细记录了动态采样的过程)
代码语言:javascript
复制
*** 2016-05-18 20:48:36.534
** Performing dynamic sampling initial checks. **★
Column (#3): TIME_ID(DATE) Part#: 3 NO STATISTICS (using defaults)
AvgLen: 9 NDV: 250 Nulls: 0 Density: 0.003998
Column (#3): TIME_ID(DATE) Part#: 4 NO STATISTICS (using defaults)
AvgLen: 9 NDV: 250 Nulls: 0 Density: 0.003998
Column (#3): TIME_ID(DATE) NO STATISTICS (using defaults)
AvgLen: 9 NDV: 250 Nulls: 0 Density: 0.004000
** Dynamic sampling initial checks returning TRUE (level = 2).★
** Dynamic sampling updated index stats.: SALES_CHANNEL_BIX, blocks=119
** Dynamic sampling updated index stats.: SALES_CUST_BIX, blocks=574
** Dynamic sampling updated index stats.: SALES_PROD_BIX, blocks=105
** Dynamic sampling updated index stats.: SALES_PROMO_BIX, blocks=87
** Dynamic sampling updated index stats.: SALES_TIME_BIX, blocks=127
** Dynamic sampling index access candidate : SALES_TIME_BIX
** Dynamic sampling updated table stats.: blocks=97*** 2016-05-18 20:48:36.534
** Generated dynamic sampling query: ★
query text :
SELECT /* OPT_DYN_SAMP */ /*+ ALL_ROWS IGNORE_WHERE_CLAUSE
...
*** 2016-05-18 20:48:36.695
** Executed dynamic sampling query:★
level : 2
sample pct. : 63.917526
total partitions : 28
partitions for sampling : 2
partitioning pct. : 7.142857
actual sample size : 28277
filtered sample card. : 28277
orig. card. : 8005
block cnt. table stat. : 97
block cnt. for sampling: 97
max. sample block cnt. : 64
sample block cnt. : 62
ndv C3 : 57
scaled : 57.00
nulls C4 : 0
scaled : 0.00
min. sel. est. : 0.00250000
** Dynamic sampling col. stats.:
Column (#1): PROD_ID(NUMBER) Part#: 0
AvgLen: 22 NDV: 57 Nulls: 0 Density: 0.017544
** Using dynamic sampling NULLs estimates.
** Using dynamic sampling NDV estimates.
Scaled NDVs using cardinality = 619358.10046
我们可以通过查看SQL Trace(10046 Trace)中的一些以SELECT /* OPTDYNSAMP */... 开头的动态采样递归SQL来判断是否采用了动态统计功能。
代码语言:javascript
复制
例如:
SELECT /* OPT_DYN_SAMP */ /*+ ALL_ROWS IGNORE_WHERE_CLAUSE
NO_PARALLEL(SAMPLESUB) opt_param('parallel_execution_enabled', 'false')
NO_PARALLEL_INDEX(SAMPLESUB) NO_SQL_TUNE */ NVL(SUM(C1),:"SYS_B_00"),
NVL(SUM(C2),:"SYS_B_01"), COUNT(DISTINCT C3), NVL(SUM(CASE WHEN C3 IS NULL
THEN :"SYS_B_02" ELSE :"SYS_B_03" END),:"SYS_B_04")
FROM
(SELECT /*+ IGNORE_WHERE_CLAUSE NO_PARALLEL("S") FULL("S")
NO_PARALLEL_INDEX("S") */ :"SYS_B_05" AS C1, CASE WHEN "S"."TIME_ID">=
TO_DATE(:"SYS_B_06", :"SYS_B_07") AND "S"."TIME_ID"<TO_DATE(:"SYS_B_08",
:"SYS_B_09") THEN :"SYS_B_10" ELSE :"SYS_B_11" END AS C2, "S"."PROD_ID" AS
C3 FROM "SH"."SALES" SAMPLE BLOCK (:"SYS_B_12" , :"SYS_B_13") SEED
(:"SYS_B_14") "S" WHERE "S"."TIME_ID">=TO_DATE(:"SYS_B_15", :"SYS_B_16")
AND "S"."TIME_ID"<TO_DATE(:"SYS_B_17", :"SYS_B_18")) SAMPLESUB动态统计在各个版本上有什么区别?
下面我们再介绍一下在各个版本上,动态统计有什么特点和那些比较大的演进:
9iR2
在9iR2的版本上推出,称为动态采样(Dynamic Sampling)。
11.2.0.1
在11.2.0.1 的版本上,推出了自动调整(AUTO-ADJUST)功能。 即,11.2.0.1以后的版本,如果动态采样采用的级别是默认级别2,Oracle就有可能根据查询语句的特点自动调整(AUTO-ADJUST)动态采样的级别;调整后的级别范围为4~8. 当然根据需要,你也可以下面的语句关闭这项功能。
代码语言:javascript
复制
SQL> alter session set "_fix_control" = '7452863:off';
11.2.0.4
在11.2.0.4 的版本上,推出了一个新的级别11,并且正式改名为动态统计(Dynamic Statistics) 即,如果把级别设为11,将由Oracle优化器自行决定动态采样范围和采样大小。
12c
在12c的版本上,推出了自动动态统计(Automatic Dynamic Statistics)功能。 即,当满足下面任何的一个条件时,Oracle优化器自行决定动态采样范围和采样大小。
代码语言:javascript
复制
・级别为默认级别2时 或者 级别设为11
・指定SQL HINT(dynamic_sampling)启用动态统计
・并行查询
・执行过的查询语句并且其执行履历还是可用的(如在内存中,AWR中等)。并行并行
当然还有由于如自适应执行计划,统计反馈,SQL计划指令等自适应查询优化(Adaptive Query Optimization)触发的一些情况。
代码语言:javascript
复制
※可以通过以下设定,使并行查询时的12c自动动态统计无效。
SQL> alter system set "_fix_control"= '12914055:off'如何禁用动态统计和12c的自动动态统计?
你可以通过如下几种方法禁用动态统计:
OPTIMIZERDYNAMICSAMPLING
你可以通过设置初始化参数OPTIMIZERDYNAMICSAMPLING为0可以彻底地使动态统计功能无效。
例:
代码语言:javascript
复制
SQL> conn /as sysdba
Connected.
SQL>---系统级别
SQL> show parameter OPTIMIZER_DYNAMIC_SAMPLING
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 2
SQL> alter system set optimizer_dynamic_sampling=0;
System altered.
SQL> show parameter OPTIMIZER_DYNAMIC_SAMPLING
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 0--会话级别
SQL> alter session set optimizer_dynamic_sampling=0;
Session altered.
SQL> show parameter OPTIMIZER_DYNAMIC_SAMPLING
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 0HINT
可以通过dynamic_sampling HINT,针对某些特定SQL使动态统计无效。
代码语言:javascript
复制
select /*+ dynamic_sampling(0) */ ...也可以通过dynamic_sampling HINT,针对某些特定语句中的特定表,使动态统计无效。
代码语言:javascript
复制
SELECT /*+ dynamic_sampling(<tab/alias name> 0) */关于12c版本上的自动动态统计
在12c版本上,自动动态统计(ADS)属于自动查询优化(Adaptive query optimization)的一部分,所以通过参数OPTIMIZERADAPTIVEFEATURES也可以对自动动态统计(ADS)进行控制。 但是需要明确的是,参数OPTIMIZERADAPTIVEFEATURES仅仅能控制12c ADS的使用,并不能控制默认的动态统计功能。即:
代码语言:javascript
复制
当OPTIMIZER_ADAPTIVE_FEATURES = TRUE 并且OPTIMIZER_DYNAMIC_SAMPLING = 2 时,自动动态统计(ADS)有效。
当OPTIMIZER_ADAPTIVE_FEATURES = FALSE 并且OPTIMIZER_DYNAMIC_SAMPLING = 2 时,自动动态统计(ADS)无效,但是默认的动态统计(Level 2)依然会有效。
另外,当OPTIMIZER_DYNAMIC_SAMPLING = 11时,无论OPTIMIZER_ADAPTIVE_FEATURES的值是TRUE 和FALSE ,12c ADS都会有效。在12c版本上的自动动态统计有效的情况下,动态收集的统计信息还会保存在内存的结果缓存(Result Cache)中,以便供其他相关的查询使用。 我们可以通过 参数optimizerads_useresultcache来控制是否保存统计结果到结果缓存(Result Cache)中。
动态统计的利弊?
我们知道任何新功能都是一把双刃剑,有优点也有缺点,对于动态统计也一样。 动态统计最大的优点是,在优化器选择执行计划时,对统计信息缺失或者统计不够准确的对象,能够动态地收集统计信息,从而获得相对好的执行计划。 并且在12c中优化器还能够自行决定统计收集级别和在内存中保存统计结果,供其他操作共享。 而其也有着缺点,就是使硬解析时候的解析时间可能变得更长,而且如果大量的动态收集操作发生时可能影响到数据库全体性能。 针对动态统计的一些常见问题,我们将在以后的案例中进行介绍。
版权声明:本文为订阅号TeacherWhat原创文章,转载必须注明出处,作者保留一切相关权力!
--------------------------
自适应执行计划
对象统计信息并不总是会为查询优化器提供用于找出最优执行计划所需的全部信息。为了改进这种情况,在解析阶段,查询优化器可以利用动态采样对要处理的数据获取额外的洞察力。
此外,自从12.1版本开始,查询优化器能够将某些决定推迟到执行阶段。其思路是,利用在执行计划的执行部分可以收集的信息来决定应该如何执行其他部分。基于这个目的,查询优化器引入了所谓的子计划。同时引入的还有负责决定应该激活哪个子计划的操作。
注意 自适应执行计划只有在企业版中才可用。
从12.1版本开始,查询优化器能在以下状况中使用自适应执行计划。
Ø 从嵌套循环联接切换到散列联接,反之亦然。 NL - HASH
Ø 为并行执行的SQL语句从散列向广播切换分配方法。
-----------------------散列向广播切换,就和分布式DB一样,控制是不是把整个表分发下去参与join 还是每一个并行分派一部分数据做join-----------------------------------
例如,考虑以下替代情况:
- 许多并行服务器进程分配的行很少。
数据库可以选择广播分发方法。在这种情况下,每个并行服务器进程都会接收结果集中的每一行。
- 很少有并行服务器进程分布许多行。
如果在数据重新分发期间遇到数据倾斜,则可能会对语句的性能产生不利影响。数据库更有可能选择散列分布,以确保每个并行服务器进程接收相等数量的行。
所述混合散列分配技术是不决定最终的数据分发方法,直到执行时间的自适应并行数据分配。优化器在操作的生产方将统计收集器插入并行服务器进程的前面。如果行数小于阈值(定义为并行度(DOP)的两倍),则数据分发方法从哈希切换为广播。否则,分发方法是哈希。
------------------------------
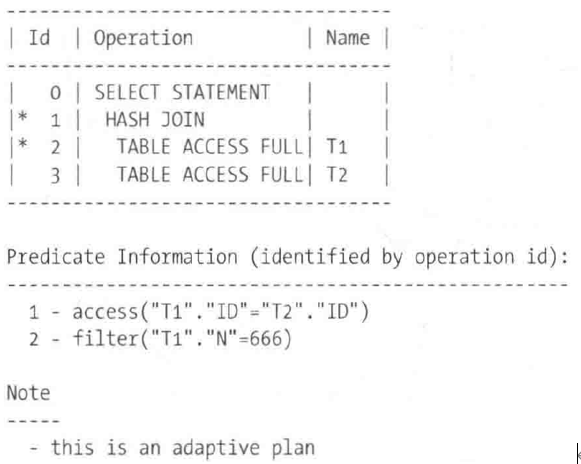
下面的例子演示切换联接方法是如何实现的。这是一段来自adaptive_plan.sql脚本生成输出的摘录。此查询是一个两张表之间的简单联接。它通过普通的嵌套循环联接执行:
EXPLAIN PLAN FOR SELECT * FROM t1, t2 WHERE t1.id = t2.id AND t1.n = 666;
select * from table(dbms_xplan.display(format=>'basic +predicate +note'));

Predicate information(identified by operation id):
-------------------------------------------------------
3- filter("T1"."N"=666)
4- access("T1"."ID"="T2"."ID")
Note
- this is an adaptive plan
注意,上面摘录中末尾的Note部分指出了这个执行计划是自适应的。然而,就执行计划本身而言,却没有任何特别的地方。而事实是,默认情况下,dbms_xplan包的display函数只显示默认的执行计划。
简单来说,这是查询优化器在不考虑自适应执行计划时会选择的执行计划。如果想看见包含子计划的完整执行计划,必须在使用dbms_xplan包时指定adaptive修饰符。在这种情况下,有三个额外的操作会在该执行计划中显示:
select * FROM table(dbms_xplan.display(format=>' basic +predicate +note +adaptive'));

1- access("T1"."ID"="T2"."ID")
5- filter("T1"."N"=666)
6- access("T1"."ID"="T2"."ID")
Note
- this is an adaptive plan(rows marked '-' are inactive)
这样的一个执行计划并不容易读取,因为它其实包含两个不同的执行计划。首先,是基于嵌套循环联接的默认执行计划:

接下来,是基于散列联接的自适应执行计划:

基本上,当t1表的扫描返回少量的数据时,第一个执行计划比第二个好。因此,要决定应该使用哪个执行计划,查询优化器会估算能够被嵌套循环联接有效处理的最大行数(称作转折点)。为了在执行阶段期间决定应该使用哪个执行计划,STATISTICS COLLECTOR操作缓存并记录t1表的扫描返回的记录数。
终于知道STATISTICS COLLECTOR 干什么的了
然后,只有当记录数低于转折点的数值时,嵌套循环联接才会被执行。否则,散列联接会被执行。此时的执行计划通常被称作最终执行计划。一旦最终执行计划确定下来,就会禁用STATISTICS COLLECTOR操作,因此,不会发生进一步的缓存。此外,与转折点方法有关的操作也会禁用。
注意 要知道执行计划切换只会发生在子游标第一次执行时。所有后续执行都使用最终执行计划
v$sq1动态性能视图提供一个新的列帮助你了解,对于一个特定的子游标其最终执行计划是否已经选定。这个列就是is_resolved_adaptive_plan。它会被设置为以下值。
Ø NULL意味着与该游标关联的执行计划不是自适应的。
Ø N意味着最终执行计划还没有被确定下来。这个值只有在最终执行计划被确定下来之前才可以观察到。
Ø Y意味着最终执行计划已经被确定下来。
两个初始化参数控制自适应执行计划。
Ø optimizer_adaptive_features 完全启用或禁用该特性。将这个参数设置为FALSE时,会禁用自适应执行计划。默认值是TRUE。
Ø optimizer_adaptive_reporting_only在报告模式下启用或禁用自适应执行计划。这个模式对于评估执行计划是否会因为自适应执行计划而改变非常有用。当设置为TRUE时,就会生成自适应执行计划,SQL引擎会检查转折点,但是SQL引擎只会使用默认的执行计划。然后,通过下面的例子所示的报告特性,可以检查如果完全启用自适应执行计划,那么会使用哪一个执行计划。默认值是FALSE:
ALTER SESSION SET optimizer_adaptive_reporting_only = TRUE;
select * FROM t1,t2 WHERE ti.id = t2.id AND t1.n=666;
select * FROM table(dbms_xplan.display_cursor(format=>'basic +predicate +note +adaptive +report'));


为了控制在语句级别是否用了自适应计划,自12.1.0.2起可使用hint(no_)adaptive_plan。