MySQL篇(事务 - 基础)
目录
一、简介
二、事务操作
1. 数据准备
2. 未控制事务
2.1. 测试正常情况
2.2. 测试异常情况
3. 控制事务
3.1. 控制事务一
查看/设置事务提交方式
提交事务
回滚事务
3.2. 控制事务二
开启事务
提交事务
回滚事务
3.3. 转账案例
四、事务的好处
五、事务四大特性(ACID)
五、事务能干什么用
六、事务控制
1. 查看事务参数状态
2. 查看事务提交模式
3. 修改事务提交模式:手动提交模式
4. 恢复自动提交模式
5. 开启事务
6. 提交事务
7. 回滚事务
8. 自动提交模式下开启事务
七、并发事务问题
1. 脏读
模板一
模板二
2. 不可重复读
模版一
模板二
3. 虚读/幻读
模板一
模板二
4. 第一类更新
5. 第二类更新
八、事务隔离级别
1. 简介
2. Oracle 支持 2 种事务隔离级别
3. MySQL支持 4 种事务隔离级别
4. 隔离级别操作
查看当前会话隔离级别
查看系统隔离级别
设置当前会话隔离级别
设置系统隔离级别
查看锁资源使用情况
查看锁等待
查看事务
一、简介
事务就是一系列sql语句的组合,是一个整体,在执行的过程中要么都一起成功,要么一起失败
在数据库中,所谓事务是指一组逻辑操作单元,使数据从一种状态变换到另一种状态。
为确保数据库中数据的一致性,数据的操纵应当是离散的成0组的逻辑单元,当它全部完成时,数据的一致性可以保持,
而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
DML 语句需要事务,DDL、DQL 可不需要事务。
简单来说:
事务 是一组操作的集合,它是一个不可分割的工作单位,
事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就比如:
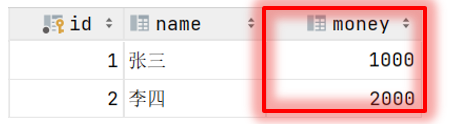
张三给李四转账1000块钱,张三银行账户的钱减少1000,而李四银行账户的钱要增加1000。
这一组操作就必须在一个事务的范围内,要么都成功,要么都失败。

正常情况:
转账这个操作, 需要分为以下这么三步来完成 , 三步完成之后, 张三减少1000, 而李四增加1000, 转账成功 :

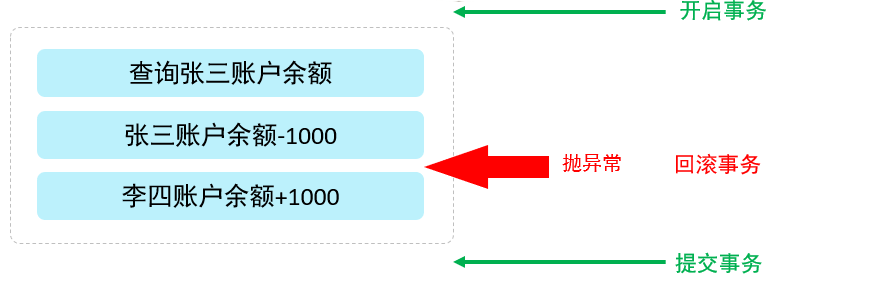
异常情况:
转账这个操作, 也是分为以下这么三步来完成 , 在执行第三步是报错了,
这样就导致张三减少1000块钱, 而李四的金额没变, 这样就造成了数据的不一致, 就出现问题了。

为了解决上述的问题,就需要通过数据的事务来完成,我们只需要在业务逻辑执行之前开启事务,执行完毕后
提交事务。
如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。
注意:
默认MySQL的事务是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式的提交事务。
二、事务操作
1. 数据准备
drop table if exists account;
-- 数据准备
create table account(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
money int comment '余额'
) comment '账户表';
insert into account(id, name, money) VALUES (null,'张三',2000),(null,'李四',2000);2. 未控制事务
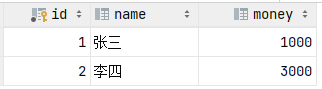
2.1. 测试正常情况
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';测试完毕之后检查数据的状态, 可以看到数据操作前后是一致的。
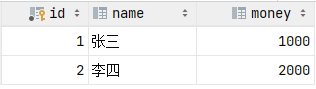
2.2. 测试异常情况
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';出错了....
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';我们把数据都恢复到2000, 然后再次一次性执行上述的SQL语句
(出错了.... 这句话不符合SQL语法,执行就会报错),
检查最终的数据情况, 发现数据在操作前后不一致了。
3. 控制事务
3.1. 控制事务一
查看/设置事务提交方式
SELECT @@autocommit;
SET @@autocommit = 0;提交事务
COMMIT;回滚事务
ROLLBACK;注意:
上述的这种方式,我们是修改了事务的自动提交行为, 把默认的自动提交修改为了手动提交,
此时我们执行的DML语句都不会提交, 需要手动的执行commit进行提交。
3.2. 控制事务二
开启事务
START TRANSACTION 或 BEGIN ;提交事务
COMMIT;回滚事务
ROLLBACK;3.3. 转账案例
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;四、事务的好处
通过以上案例发现事务的好处如下:
① 保证数据一致性,修改过的数据在没有提交之前是不能被其他用户看到的;
② 在数据永久性生效前可以撤回原来的修改操作;
③ 将相关操作组织在一起,一个事务中相关的数据改变或者都成功,或者都失败。
五、事务四大特性(ACID)
- 原子性(atomicity)一个事务必须被视为一个不可分割的工作单元,整个事务中的所有操作要么全部提交
成功,要么全部失败回滚。对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
- 一致性(consistency)数据库总是从一个一致性状态转换到下一个一致性状态。在前面的例子中,一致性
确保了,即使在执行第3、4条语句之间时系统崩溃,支票账户中也不会损失200美元。如果事务最终没有
提交,该事务所做的任何修改都不会被保存到数据库中。
- 隔离性(isolation)通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的,这就是隔
离性带来的结果。在前面的例子中,当执行完第3条语句、第4条语句还未开始时,此时有另外一个账户汇
总程序开始运行,其看到的支票账户的余额并没有被减去200美元。后面我们讨论隔离级别(isolation
level)的时候,会发现为什么我们要说“通常来说”是不可见的。
- 持久性(durability)一旦提交,事务所做的修改就会被永久保存到数据库中。此时即使系统崩溃,数据也
不会丢失。持久性是一个有点模糊的概念,实际上持久性也分很多不同的级别。有些持久性策略能够提供
非常强的安全保障,而有些则未必。而且不可能有100%的持久性保障(如果数据库本身就能做到真正的
持久性,那么备份又怎么能增加持久性呢?)。
五、事务能干什么用
事务是访问和更新数据库的程序执行单元,事务中包含一个或者多个SQL语句,这些语句要么都执行,要么就
都不执行,也就是要么都成功,要么都不成功。
介绍四大特性之前先来说下MySQL的架构:
第一层:客户端层,实现链接处理,身份验证,确保安全性等。
第二层:服务器层,大多数MySQL的核心功能都在这一层,包括查询解析、分析、优化、一级所有的内置
函数(日期,时间、数学、加密函数),以及跨存储引擎的功能(存储过程,触发器,视图等)。
第三层:存储引擎层,负责数据的存储和提取。事务的实现也是在存储引擎中实现的。


MySQL事务的提交与回滚:
- start transaction(开启事务)
- 要执行的SQL语句
- commit/rollback (提交/回滚)
MySQL默认自动提交事务,手动提交事务设置:
set autocommit = 0
上面介绍完相关的理论,记下来我们来详细介绍下到底什么是ACID。
上面介绍完相关的理论,记下来我们来详细介绍下到底什么是ACID。
原子性:
原子性是指一个事务是一个不可分割的单位,是一个最小的操作单元,事务中的操作,要么全成功,要
么全不成功。如果事物中的一个sql语句执行失败了,那么已经执行的SQL语句,要执行回滚动作,回滚到这个
事务执行之前的状态。它的实现原理,主要是通过undo log,它是一个日志,innodb存储引擎提供了两种事
务的日志,一个是redo log,还有一个undo log。原子性的体现,就是在回滚上面,如果SQL报错的话,会
执行回滚,回滚到执行之前的状态。那么怎么回到执行之前的状态呢,这就需要把执行之前的状态记录下
来,一旦这个SQL语句发生错误之后,我们就可以回到我们之前的状态,举个例子:在我们程序上线的过程
中,如果程序上线失败,或者刚上线的时候遇到一些不能及时解决的bug,这个时候我们要把当前的错误版本
回滚到上一个正确的版本,它们之间的原理是相通的,就是我需要要记住上一个正确的版本是什么,当这个事
务对数据库进行修改的时候,innodb就会生成这个对应的undo log,记录这个sql执行的相关信息,如果语句
执行失败,发生回滚,innodb就会根据这个undo log内容去做相反的工作,比如执行了一个insert的操作,
那么回滚的时候,就会执行一个相反的操作,就是delete,我之前执行的是一个delete操作呢,那么回滚的时
候,就会执行一个相反的insert,对于update,回滚的时候会执行一个相反的update,把数据再改回去。
持久性:
持久性的原理,也是通过log,叫redo log,持久性是指这个事物一旦提交,它对数据库的改变,就是永
久性的。首先说下它存在的背景,MySQL的数据,是存在磁盘中的,但是如果每次去读数据都需要经过这个磁
盘IO,那么它的效率就会很低,所以innodb提供了一个缓存buffer,这个buffer中包含了磁盘中的部分数据页
的一个映射,作为访问数据库的一个缓冲,当从数据库读取数据的时候,就会先从这个buffer中取,如果
buffer没有,再去磁盘中读取,读取完之后再放到buffer缓存中。当向数据库写入数据的时候,也会首先向
buffer中写入数据,然后定期将buffer的数据刷新到磁盘上,来完成持久化的操作。这个时候就存在一个问
题,虽然读写效率提升了,但是它也增加了数据丢失的风险,如果buffer中的数据还没有来得及同步到这个磁
盘上,这个时候MySQL宕机了,那么buffer中的数据就会丢失,进而造成数据的丢失。基于这个背景,所以
read log就被引入进来解决这个问题。改进之后的流程是这样的,当数据库的数据要进行新增和修改的时候,
除了修改这个buffer的数据,还要把这次的操作记录到read log日志里面,那么大家可以想一下,如果这个
MySQL宕机了,那么还有这个read log可以去恢复数据,read log是这个预写式日志,也就是说它会将所有
的修改先写入到日志里面,然后再更新到buffer里面,保证了数据不会丢失。既然read log也需要把事务提交
的日志写入到磁盘,那它为什么比直接将buffer中的数据写入到磁盘中要快呢?主要有两个原因,一个是
buffer中的数据持久化是随机写的,IO每次修改的数据位置,都是随机的,但是read log是追加模式的,它是
在文件的尾部去追加,属于一种顺序IO的操作,这种方式就很快,第二个就是buffer持久化数据是以数据页配
置为单位的,MySQL默认的配置页大小是16k,一个数据页上一个小小的修改都要把整个页的数据写入。而
read log只需要写入真正需要的部分就可以了,这样无效的IO就大大的减少了。所以read log要比buffer同步
数据要快的很多很多,那么read log是什么时候会同步到磁盘里去呢?read log在没有同步到磁盘之前,是在
缓冲区中的,叫做read log缓冲区,这个时候就算这个宕机了,也没有关系,因为事务没有执行完,没有去提
交,这样在恢复好数据库之后,还可以走回滚的操作,可以通过这个undo log日志去做回滚。read log的三种
持久化的机制(innodb_flush_log_at_trx_commit ):
0:表示当提交事务时,并不将缓冲区的redo日志写入磁盘的日志文件,而是等待主线程每秒刷新;
1:在事务提交时将redo日志同步写入磁盘,保证一定会写入成功(推荐的方式);
2:在事务提交时缓冲区的redo日志异步写入到磁盘,不能保证在commit时肯定会写入redo日志,只是
会有这个动作。
隔离性:
隔离性呢,又分为两种情况,一个是写写操作,还有一个是写读操作。写写操作,是通过锁去实现隔离
性,写读操作,是通过mvcc来实现。关于读的话大家应该知道,它会存在脏读,不可重复读,以及幻读的情
况,这三种情况是基于mvcc去解决的。隔离性的含义,是指不同的事物之间,它要相互不能影响,就像线程一
样,线程与线程之间是不能互相影响对方的。如果有两个事物,同时要对一行数据进行写操作,那么这时候只
有一个事务能对这个数据进行操作,这就需要锁来保证同一时刻只有一个人在操作这个数据,在这个事务修改
数据之前,要获取相应的锁,获取到锁之后,然后才可以修改这个数据,如果其他事务想操作这个数据,必须
等待当前的事务提交或者回滚之后,释放了这个锁,下一个事务才能继续来抢这个锁,去执行它的事务。关于
锁和mvcc的知识,内容比较多,后面单独一篇文章来讲。
一致性:
一致性是指这个事务执行之后,数据库的完整性约束没有被破坏,事务执行前后都是合法的一个数据状
态,比如这个数据库的主键要唯一,字段类型大小,长度要符合这要求,还有外界的约束要符合要求。这个一
致性,是事务追求的最终目标,前面所提到的原子性、持久性、隔离性,都是为了保证数据库最终状态的一致
性。
六、事务控制
1. 查看事务参数状态
show variables like '%commint%'2. 查看事务提交模式
SELECT @@autocommit;3. 修改事务提交模式:手动提交模式
set autocommit = false; 或 set autocommit = 0;上面语句执行之后,它之后的所有sql,都需要手动提交才能生效,直到恢复自动提交模式。
4. 恢复自动提交模式
set autocommit = true; 或 set autocommit = 1;5. 开启事务
START TRANSACTION 或 BEGIN;6. 提交事务
COMMIT;7. 回滚事务
ROLLBACK;8. 自动提交模式下开启事务
start transaction;
(1)
....
(3)
commit; 或 rollback;
此时,在(1)和(3)之间的语句是属于手动提交模式,其他的仍然是自动提交模式。注意:
MySQL的事务默认是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式的提交事务。
七、并发事务问题
1. 脏读
脏读即一个事务读到另外一个事务还没有提交的数据
模板一
比如B读取到了A未提交的数据。

模板二


2. 不可重复读
不可重复读即一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
模版一
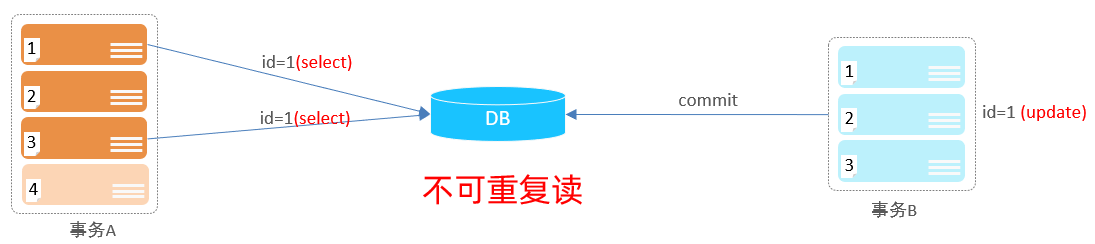
事务A两次读取同一条记录,但是读取到的数据却是不一样的。
模板二

3. 虚读/幻读
虚读/幻读即一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存
在,好像出现了 "幻影"。
模板一
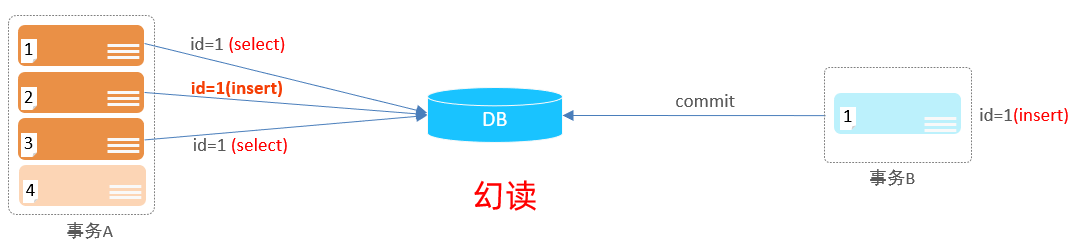
模板二


4. 第一类更新
一个事务覆撤销时,把已提交的另一个事务的更新数据覆盖看(严重)
5. 第二类更新
一个事务覆盖另外一个事务已经提交的数据,造成另外一个事务所做的操作丢失

八、事务隔离级别
1. 简介
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。
在标准 SQL 规范中定义了四种隔离级别:
READ UNCOMMITED < READ COMMITED < REPEATABLE READ < SERIALIZABLE

其中√表示可能出现的情况
2. Oracle 支持 2 种事务隔离级别
① READ-COMMITED(Oracle默认事务隔离级别)
② SERIALIZABLE
Oracle 支持 READ COMMITED(缺省)和 SERIALIZABLE
3. MySQL支持 4 种事务隔离级别
① read-uncommitted
② read-committed
③ repeatable-read(MySQL默认事务隔离级别)
④ serializable
MySQL 支持 四种隔离级别,缺省为 REPEATABLE READ,
默认情况下也不会出现幻读和第一类丢失的问题,所以只需处理第二类丢失更新的问题。
4. 隔离级别操作
查看当前会话隔离级别
SELECT @@tx_isolation;查看系统隔离级别
select @@global.tx_isolation;设置当前会话隔离级别
set session transaction isolation level repeatable read;设置系统隔离级别
set global transaction isolation level repeatable read;查看锁资源使用情况
select * from information_schema.INNODB_LOCKS;查看锁等待
select * from information_schema.INNODB_LOCK_WAITS;查看事务
select * from information_schema.INNODB_TRX;