【LLM学习之路】9月22日 第九天 自然语言处理
【LLM学习之路】9月22日 第九天
直接看Transformer
第一章 自然语言处理
自然语言处理发展史
只要看的足够多,未必需要理解语言
统计语言模型发展史
统计语言模型:
判断一个句子是否合理,就计算这个句子会出现的概率
缺点是句子越长越难计算
马尔可夫(Markov)假设是计算每个词语wi仅与前N-1个词语有关
也称之为N元模型,即使是使用三元、四元甚至是更高阶的语言模型,依然无法覆盖所有的语言现象。在自然语言中,上下文之间的关联性可能跨度非常大,例如从一个段落跨到另一个段落,这是马尔可夫假设解决不了的。
此时就需要使用 LSTM、Transformer 等模型来捕获词语之间的远距离依赖(Long Distance Dependency)了。
NNLM 模型
具体来说,NNLM 模型首先从词表 C 中查询得到前面 N−1 个词语对应的词向量 C(wt−n+1),…,C(wt−2),C(wt−1),然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过 Softmax 函数预测当前词语的概率。特别地,包含所有词向量的词表矩阵 C 也是模型的参数,需要通过学习获得。因此 NNLM 模型不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量(Word Embedding)。
词向量将词转化成一种分布式表示, 是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。词向量能够包含更多信息,并且每一维都有特定的含义。
Word2Vec 模型
Word2Vec 的模型结构和 NNLM 基本一致,只是训练方法有所不同,分为 CBOW (Continuous Bag-of-Words) 和 Skip-gram 两种,如图 1-7 所示。
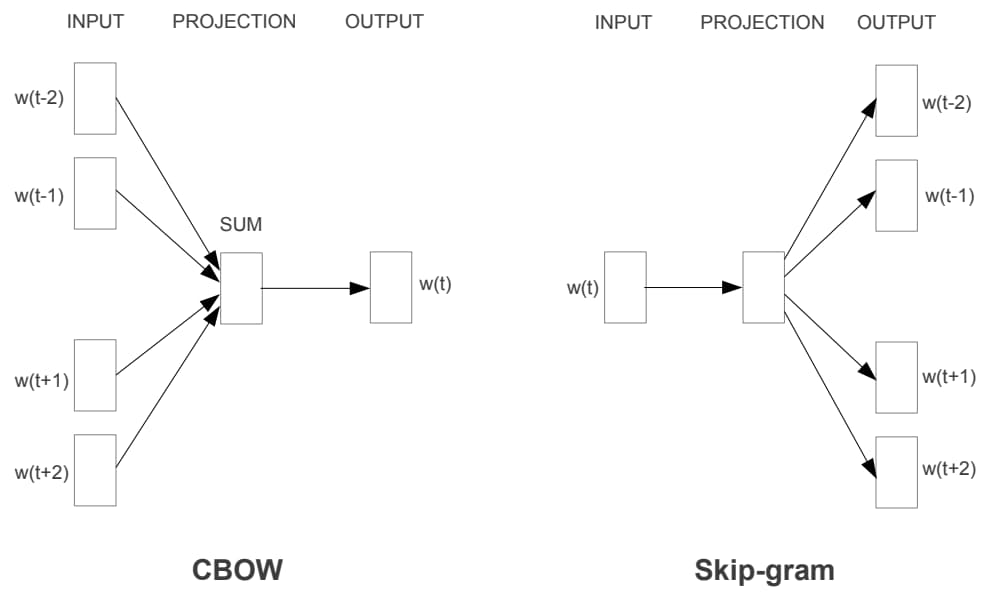
其中 CBOW 使用周围的词语 w(t−2),w(t−1),w(t+1),w(t+2) 来预测当前词 w(t),而 Skip-gram 则正好相反,它使用当前词 w(t) 来预测它的周围词语。
打破了语言模型“只通过上文来预测当前词”的固定思维
无法处理多义词问题,提出词语之间的互信息(Mutual Information)
对于多义词,可以使用文本中与其同时出现的互信息最大的词语集合来表示不同的语义。例如对于“苹果”,当表示水果时,周围出现的一般就是“超市”、“香蕉”等词语;而表示“苹果公司”时,周围出现的一般就是“手机”、“平板”等词语。
后来自然语言处理的标准流程就是先将 Word2Vec 模型提供的词向量作为模型的输入,然后通过 LSTM、CNN 等模型结合上下文对句子中的词语重新进行编码,以获得包含上下文信息的词语表示。
ELMo 模型
为了更好地解决多义词问题,2018 年研究者提出了 ELMo 模型(Embeddings from Language Models)。与 Word2Vec 模型只能提供静态词向量不同,ELMo 模型会根据上下文动态地调整词语的词向量。
ELMo 模型首先对语言模型进行预训练,使得模型掌握编码文本的能力;然后在实际使用时,对于输入文本中的每一个词语,都提取模型各层中对应的词向量拼接起来作为新的词向量。ELMo 模型采用双层双向 LSTM 作为编码器,从两个方向编码词语的上下文信息,相当于将编码层直接封装到了语言模型中。
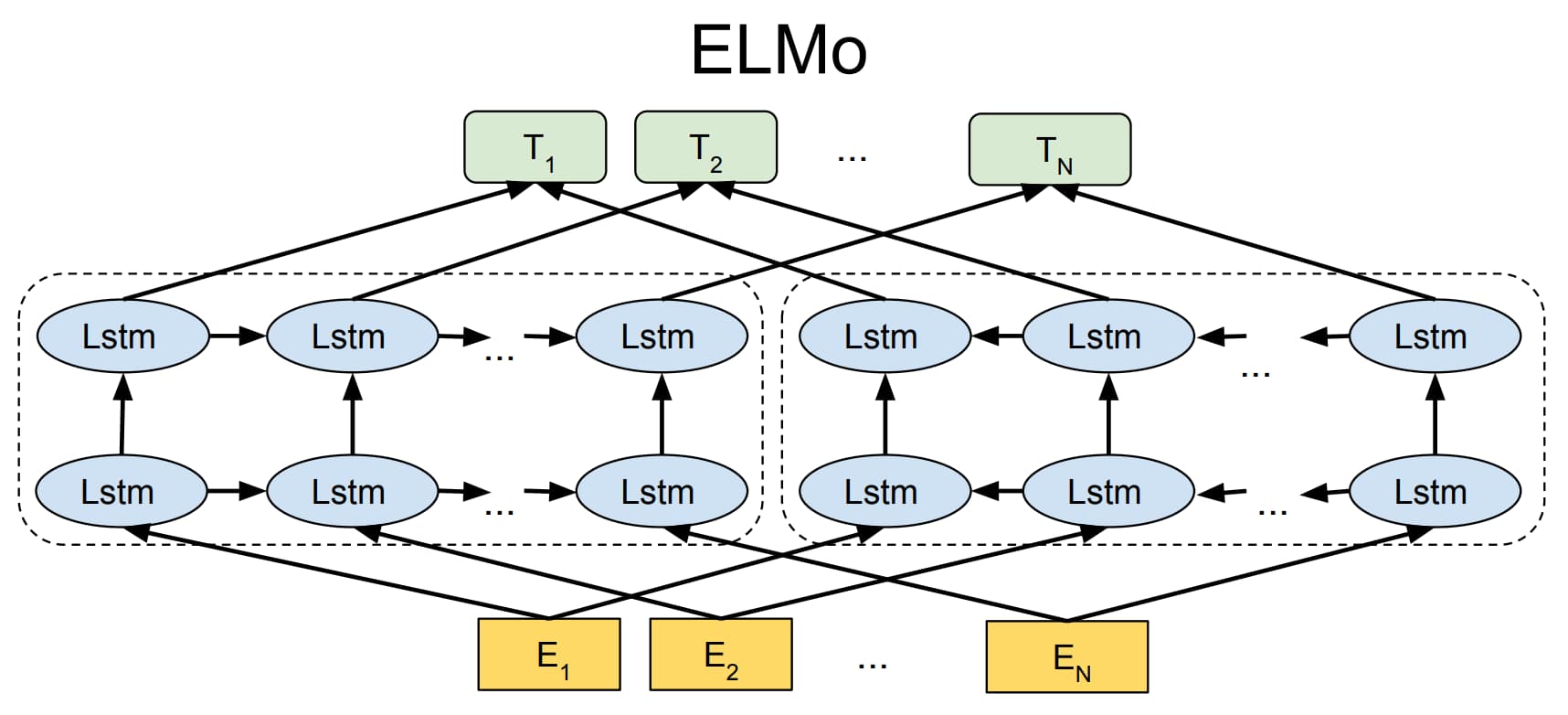
训练完成后 ELMo 模型不仅学习到了词向量,还训练好了一个双层双向的 LSTM 编码器。对于输入文本中的词语,可以从第一层 LSTM 中得到包含句法信息的词向量,从第二层 LSTM 中得到包含语义信息的词向量,最终通过加权求和得到每一个词语最终的词向量。
但是 ELMo 模型存在两个缺陷:首先它使用 LSTM 模型作为编码器,而不是当时已经提出的编码能力更强的 Transformer 模型;其次 ELMo 模型直接通过拼接来融合双向抽取特征的做法也略显粗糙。
BERT模型
终于出现了一位集大成者,发布时 BERT 模型在 11 个任务上都取得了最好性能。
BERT 模型采用和 GPT 模型类似的两阶段框架,首先对语言模型进行预训练,然后通过微调来完成下游任务。
BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且采用了类似 ELMo 模型的双向语言模型结构
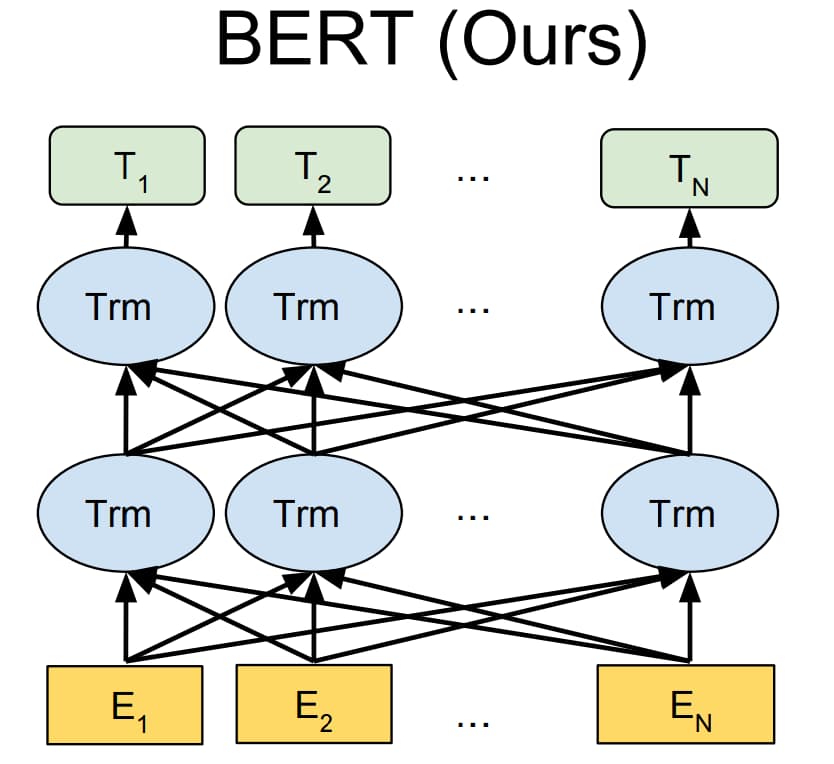
因此 BERT 模型不仅编码能力强大,而且对各种下游任务,BERT 模型都可以通过简单地改造输出部分来完成。
但是 BERT 模型的优点同样也是它的缺陷,由于 BERT 模型采用双向语言模型结构,因而无法直接用于生成文本。
大语言模型
除了优化模型结构,研究者发现扩大模型规模也可以提高性能。保持模型结构以及预训练任务基本不变的情况下,仅仅通过扩大模型规模就可以显著增强模型能力,尤其当规模达到一定程度时,模型甚至展现出了能够解决未见过复杂问题的涌现(Emergent Abilities)能力。例如 175B 规模的 GPT-3 模型只需要在输入中给出几个示例,就能通过上下文学习(In-context Learning)完成各种小样本(Few-Shot)任务,而这是 1.5B 规模的 GPT-2 模型无法做到的。
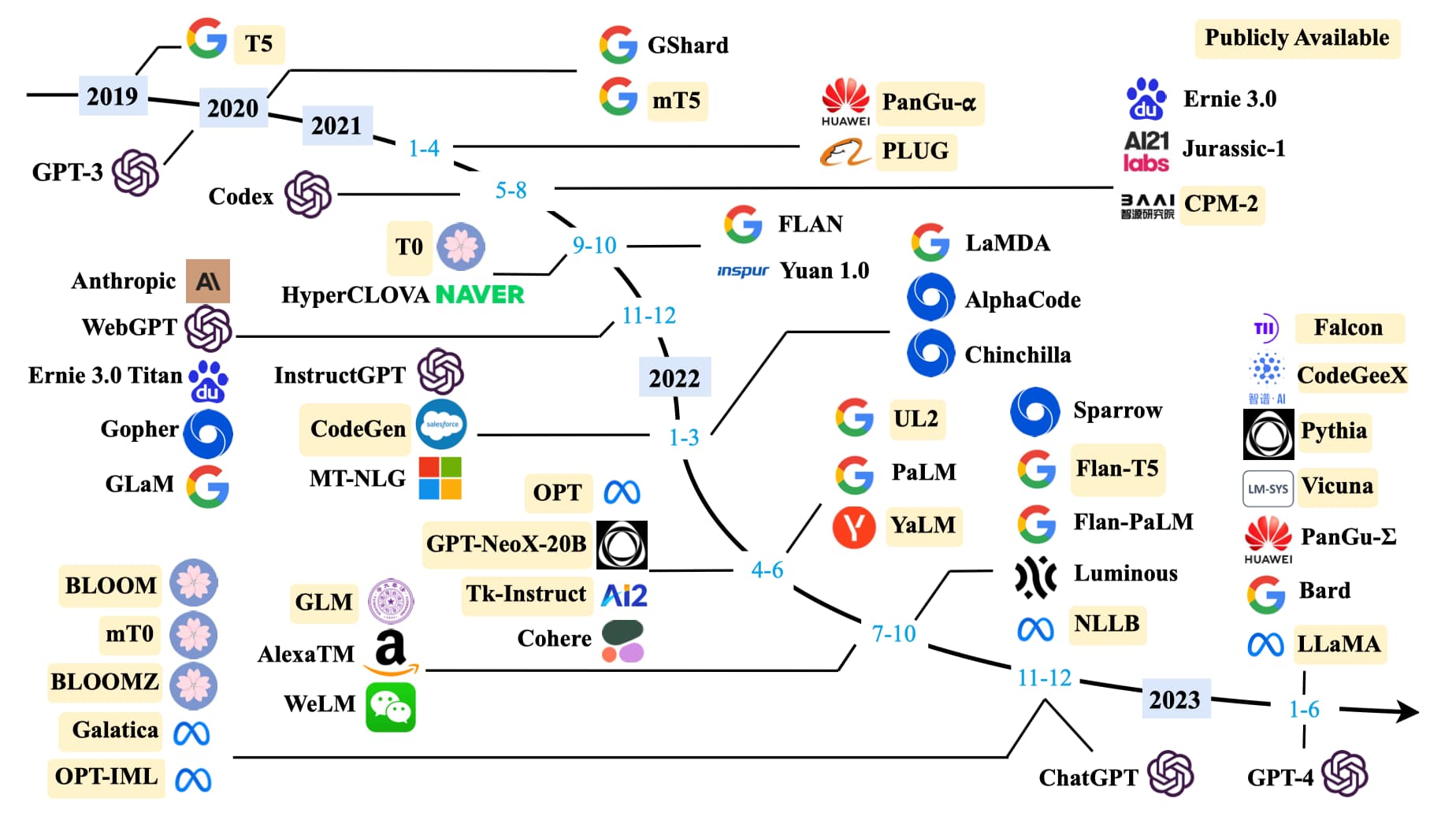
在规模扩展定律(Scaling Laws)被证明对语言模型有效之后,研究者基于 Transformer 结构不断加深模型深度,构建出了许多大语言模型