CVPR最牛图像评价算法!
目录
概述
一、论文思路
1.多任务学习框架:
2.视觉-语言对应关系:
3.动态损失权重:
4.模型优化和评估:
二、模型介绍
三、详细实现方法
1.图像编码器和语言编码器(Image Encoder and Language Encoder)
2.特征嵌入(Feature Embedding)
3.余弦相似度计算(Cosine Similarity Calculation)
4.联合概率计算(Joint Probability Calculation)
5.边际化(Marginalization)
6.损失函数(Loss Functions)
7.最终损失(Final Loss)
四、复现过程
一.代码结构
二.使用方法
环境设置
训练模型
测试模型
1.准备测试数据:
2.加载预训练模型:
3.运行测试脚本:
自己的思考:
可以改进的地方:
演示效果
核心逻辑
概述
这篇论文提出了一种基于视觉-语言对应关系的盲图像质量评估方法,通过多任务学习利用其他两个辅助任务的知识,来预测没有参考信息的图像质量。设计了一个多任务学习方案,通过计算所有标签组合并计算视觉-文本嵌入的余弦相似性来得到联合概率,从而推断出每个任务的预测结果,并设计了数据损失函数进行优化。
在三个任务——盲图像质量评估、场景分类和失真类型识别的综合实验中,结果表明所提出的方法能够从场景分类和失真类型识别任务中受益,并在多个图像质量评估数据集上超越了现有技术水平。
一、论文思路
这篇论文提出了一种基于视觉-语言对应关系的盲图像质量评估方法(BIQA),通过多任务学习方案来提升BIQA的性能。主要思路可以总结如下:
1.多任务学习框架:
作者提出了一种通用的多任务学习方案,将BIQA、场景分类和失真类型识别三个任务联合起来进行训练。通过这种方式,模型可以从其他任务中获取辅助知识,以提高BIQA的性能。
2.视觉-语言对应关系:
作者利用预训练的对比学习视觉-语言模型(CLIP)来获取图像和文本的嵌入表示。通过计算图像嵌入与所有候选文本嵌入之间的余弦相似度,可以得到三个任务的联合概率分布。
3.动态损失权重:
在多任务学习中,作者采用了一种简单而高效的方法来自动确定每个任务的损失权重。这种动态权重分配有助于模型在训练过程中更好地平衡不同任务的重要性。
4.模型优化和评估:
作者在多个BIQA数据集上进行了实验,结果表明所提出的方法在预测准确性、泛化能力和质量注释调整方面都优于现有的BIQA技术。
二、模型介绍
1.任务定义:除了盲图像质量评价BIQA任务外,还定义了场景分类(scene classification)和失真类型识别(distortion type identification)两个辅助任务。
2.数据准备:为现有的IQA数据集补充场景分类和失真类型标签,以便在多任务学习框架下联合训练。

3.视觉-语言表示:使用预训练的对比学习视觉-语言模型(CLIP)来获取图像和文本的嵌入表示。图像通过视觉编码器处理,文本通过语言编码器处理。
4.多任务学习:通过计算图像嵌入与所有候选文本嵌入之间的余弦相似度,得到三个任务的联合概率分布。然后,通过边际化这个联合分布,得到每个任务的边际概率,并进一步将离散的质量等级转换为连续的质量分数。
5.损失函数设计:为BIQA、场景分类和失真类型识别设计了三种类型的损失函数,包括排序损失、二元损失和多类损失,并通过动态权重分配来自动优化这些损失函数。
6.模型优化:在多个IQA数据集上联合优化整个方法,最小化加权损失函数的总和。损失权重根据训练动态自动调整。
7.训练过程:使用AdamW优化器,在多个数据集上训练模型,采用动态调整的学习率和余弦退火策略。

三、详细实现方法
1.图像编码器和语言编码器(Image Encoder and Language Encoder)

2.特征嵌入(Feature Embedding)

3.余弦相似度计算(Cosine Similarity Calculation)

4.联合概率计算(Joint Probability Calculation)

5.边际化(Marginalization)

6.损失函数(Loss Functions)

7.最终损失(Final Loss)

四、复现过程
一.代码结构

1.data文件夹:
这是示例图像文件,供demo代码测试时使用。
2.IQA_Database:
这是一个数据集文件夹,包含了不同的图像质量评估(IQA)数据库,例如 BID, ChallengeDB_release, CSIQ, databaserelase2, kadid10k, koniq-10k。这些数据库用于训练和评估图像质量评估模型。
3.BIQA_benchmark.py:
这是一个benchmark测试脚本,用于在不同的IQA数据库上测试模型的性能。
4.clip_biqa.png:
这是CLIP模型的结构框图。
5.demo.py 和 demo2.py:
这两个文件是演示脚本,展示了如何使用LIQE算法进行图像质量评估.
6.ImageDataset.py 和 ImageDataset2.py:
这些文件定义了图像数据集类,用于加载和处理图像数据,供模型训练和评估使用.
7.LIQE.pt:
这是LIQE模型的预训练权重文件。代码会加载这个文件以使用预训练的模型进行图像质量评估。
8.LIQE.py:
这是主要的LIQE算法实现文件,包含了LIQE算法的核心逻辑。
9.MNL_Loss.py:
这是定义了多类对数损失函数的文件,用于训练图像质量评估模型。
10.OutputSaver.py:
这个文件包含保存模型输出结果的函数,可能用于保存预测结果或中间计算结果。
11.README.md:
这是项目的说明文件,通常包含项目的介绍、安装和使用说明。
12.train_unique_clip_weight.py:
这是用于训练模型的脚本,包含了训练流程的实现。
13.utils.py:
这是包含各种实用函数的文件,可能用于数据预处理、图像操作等。
14.weight_methods.py:
这个文件可能包含了一些与权重处理相关的方法或工具函数。二.使用方法
环境设置
1.安装必要的库:torch 2.1.0,python3
2.下载和解压数据集:下载IQA数据库,并解压到 IQA_Database 文件夹下。
3.修改数据集路径(train_unique_clip_weight.py):


训练模型
1.准备训练数据:
确保 IQA_Database 文件夹中包含了所有需要的训练数据集。
可以根据 ImageDataset.py 和 ImageDataset2.py 文件中的定义来加载和处理图像数据。
2.运行训练脚本:
使用 train_unique_clip_weight.py 进行模型训练。该脚本定义了训练流程,包括数据加载、模型训练、损失计算等步骤。
参数解释:
–data_path:数据集的路径。
–epochs:训练的轮数。
–batch_size:每个批次的图像数量。
–lr:学习率。测试模型
1.准备测试数据:
确保测试图像文件(如 data/6898804586.jpg 和 data/I02_01_03.png)存在于 data 文件夹中。
2.加载预训练模型:
将 LIQE.pt 放置在合适的目录中,并确保代码能够正确加载预训练模型。
3.运行测试脚本:
使用 demo.py 或 demo2.py 进行模型测试,评估图像的质量。
自己的思考:
本文算法取得了很好的效果,且发表在cvpr上,除了算法本身的效果确实很好,而且结合了现在很火的多模态模型CLIP,将CLIP用到了IQA领域,并且结合多任务学习,方法上很新颖;再一个,作者的工作量也很大,为现有的六个质量评价数据集添加了两种标签。
可以改进的地方:
1.退化空间的进一步扩展:
尽管现有的退化空间已经非常大,但可以进一步研究如何通过更多类型和更复杂的退化来扩展这一空间,以更好地模拟真实世界中的复杂情况。2.模型架构优化:
当前的方法主要基于ResNet-50等常见架构,可以尝试使用更复杂或更适合BIQA任务的架构,如更深的神经网络或专门设计的模型,以进一步提高性能。3.对比学习中的噪声处理:
在对比学习过程中,可能存在一些噪声样本(如不同内容但相似质量的样本)。可以研究更有效的噪声处理方法,以进一步提升模型的鲁棒性。
演示效果
训练过程演示:
首先加载csv文件:

开始训练:

demo测试运行结果:
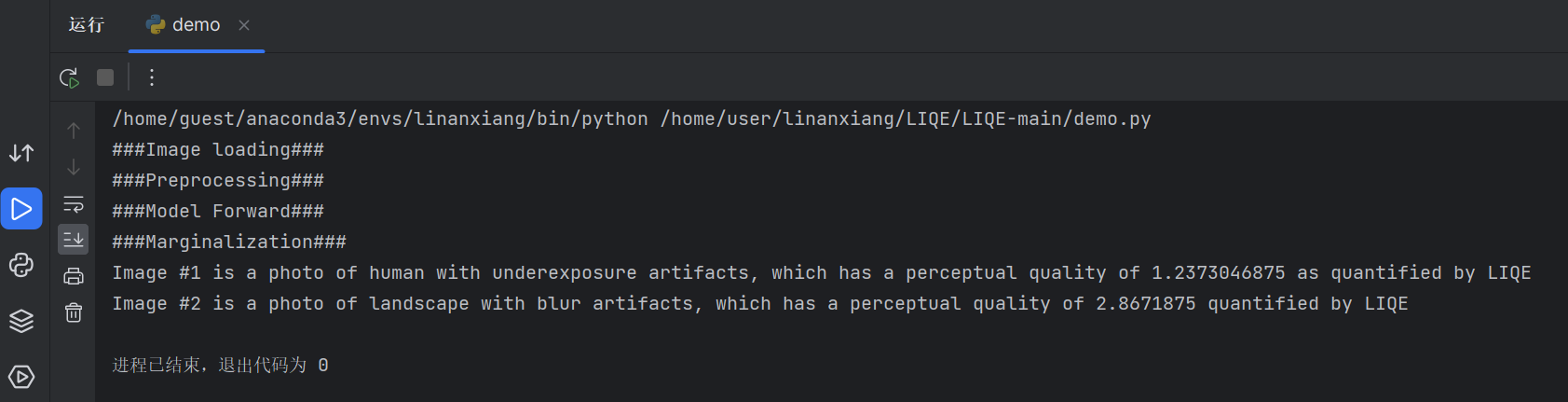
结果说明:
Image1经过LIQE算法后的质量评价结果:图像 #1 是一张曝光不足伪影的人体照片,其感知质量为 1.2373046875,由 LIQE 量化
Image2经过LIQE算法后的质量评价结果:图像 #2 是一张带有模糊伪像的风景照片,其感知质量为 2.8671875,由 LIQE 量化
核心逻辑
LIQE算法的核心逻辑:
class LIQE(nn.Module):
def __init__(self, ckpt, device):
super(LIQE, self).__init__()
self.model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
checkpoint = torch.load(ckpt, map_location=device)
self.model.load_state_dict(checkpoint)
joint_texts = torch.cat(
[clip.tokenize(f"a photo of a {c} with {d} artifacts, which is of {q} quality") for q, c, d
in product(qualitys, scenes, dists_map)]).to(device)
with torch.no_grad():
self.text_features = self.model.encode_text(joint_texts)
self.text_features = self.text_features / self.text_features.norm(dim=1, keepdim=True)
self.step = 32
self.num_patch = 15
self.normalize = Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
self.device = device
def forward(self, x):
x = x.to(self.device)
batch_size = x.size(0)
x = self.normalize(x)
x = x.unfold(2, 224, self.step).unfold(3, 224, self.step).permute(2, 3, 0, 1, 4, 5).reshape(-1, 3, 224, 224)
sel_step = x.size(0) // self.num_patch
sel = torch.zeros(self.num_patch)
for i in range(self.num_patch):
sel[i] = sel_step * i
sel = sel.long()
x = x[sel, ...]
image_features = self.model.encode_image(x)
image_features = image_features / image_features.norm(dim=1, keepdim=True)
logit_scale = self.model.logit_scale.exp()
logits_per_image = logit_scale * image_features @ self.text_features.t()
logits_per_image = logits_per_image.view(batch_size, self.num_patch, -1)
logits_per_image = logits_per_image.mean(1)
logits_per_image = F.softmax(logits_per_image, dim=1)
logits_per_image = logits_per_image.view(-1, len(qualitys), len(scenes), len(dists_map))
logits_quality = logits_per_image.sum(3).sum(2)
similarity_scene = logits_per_image.sum(3).sum(1)
similarity_distortion = logits_per_image.sum(1).sum(1)
distortion_index = similarity_distortion.argmax(dim=1)
scene_index = similarity_scene.argmax(dim=1)
scene = scenes[scene_index]
distortion = dists_map[distortion_index]
quality = 1 * logits_quality[:, 0] + 2 * logits_quality[:, 1] + 3 * logits_quality[:, 2] + \
4 * logits_quality[:, 3] + 5 * logits_quality[:, 4]
return quality, scene, distortion
if __name__ == '__main__':
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
ckpt = './LIQE.pt'
liqe = LIQE(ckpt, device)
x = torch.randn(1,3,512,512).to(device)
q, s, d = liqe(x)
感觉不错,点击我,立即使用