浮点型的详细介绍以及sizeof
昨天我们查看了各种整型的范围,那今天我们来看看浮点型float的范围。
float
用以下代码可以实现:
#include <stdio.h>
#include <float.h>
int main() {
printf("The maximum value of a float is: %e\n", FLT_MAX);
printf("The minimum value of a float (including negative) is: %e\n", -FLT_MAX);
return 0;
}和查看整型的范围类似,我们也需要包括一个头文件:float.h。
%e
我们同样也能看到占位符从%hd、%d、%ld、%lld、%hu、%u、%lu、%llu变成了%e,如果说前面是用来打印十进制的整数,那%e就是用来打印浮点数类型的,打印的形式是科学计数法。举个例子来感受一下:
#include <stdio.h>
int main()
{
float a = 100.234;
printf("%e\n", a);
}
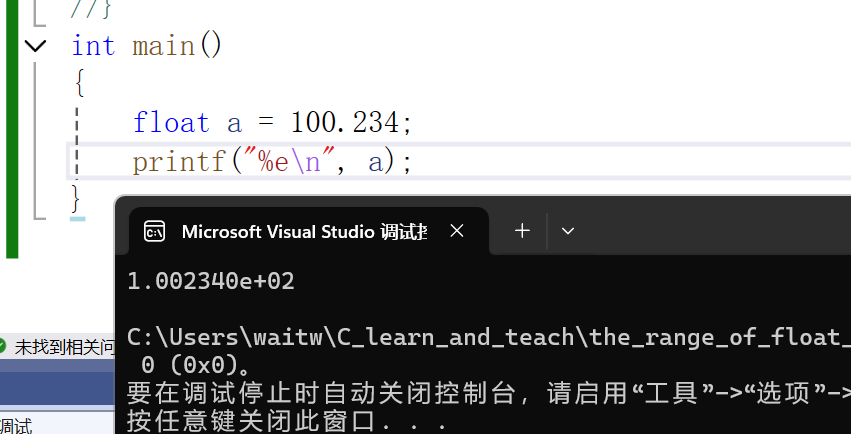
控制台输出的就是浮点数输出的格式。后面的+02表示指数部分是2,也可以用%E,输出的结果除了中间的e会变成E。其它都是相同的:

%e也可以保留小数的位数,和%f一样,在%的后面加一个点和数字。

现在我们就可以来看一下第一段代码的运行结果:
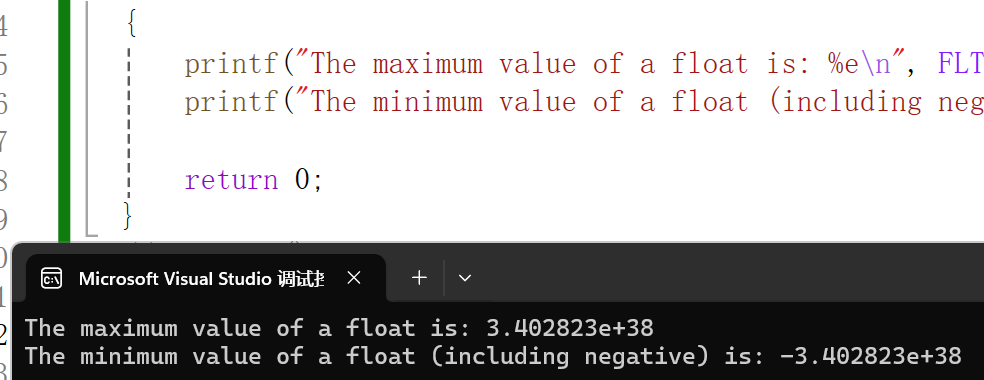
会发现它并不是涵盖了所有的小数,那就说明除了float还有其他方式来表示小数。浮点型中除了float还有double和long double。先来讲讲double
double(双精度)
先来定义一个double类型的变量:
#include <stdio.h>
int main()
{
double a = 100.234;
printf("%lf\n", a);
}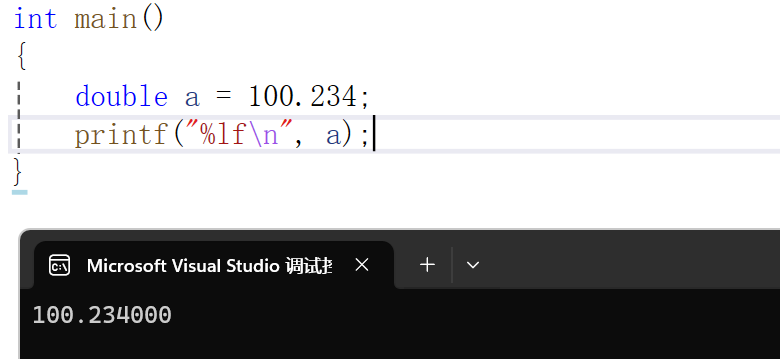
可以看到占位符从%f变成了%lf,其实double的精度(精度即能表示的小数位数更多)比float高,只不过默认情况下都是输出6位,我们也可以指定输出更多位。
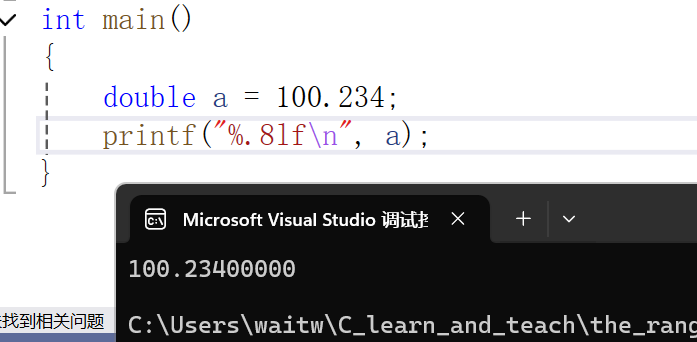
老样子,我们来看它所能包含的范围:
#include <stdio.h>
#include <float.h>//有些编译器是需要包含头文件<limits>
int main()
{
printf("The maximum negative value of a double is: %e\n", -DBL_MAX);
printf("The maximum value of a double is: %e\n", DBL_MAX);
return 0;
}
可以看到这个值比float的范围大了很多。
long double
也先来定义一个long double的变量:

#include <stdio.h>
int main()
{
long double a = 100.234;
printf("%llf\n", a);
}
占位符从%lf变成了%llf,同样也可以指定位数输出。
咱们也来看看它的范围:
#include <stdio.h>
#include <float.h>
int main()
{
printf("The maximum positive value of a long double is: %Le\n", LDBL_MAX);
printf("The maximum negative value of a long double is: %Le\n", -LDBL_MAX);
return 0;
}
咦,为什么和double是一样的?还记得昨天的long和int的范围也是一样的吗?是因为它们各自所占的内存是一样的,字节数是一样的。
那我们来看看它们占的字节数:
#include <stdio.h>
int main() {
printf("Size of float: %zu bytes\n", sizeof(float));
printf("Size of double: %zu bytes\n", sizeof(double));
printf("Size of long double: %zu bytes\n", sizeof(long double));
return 0;
}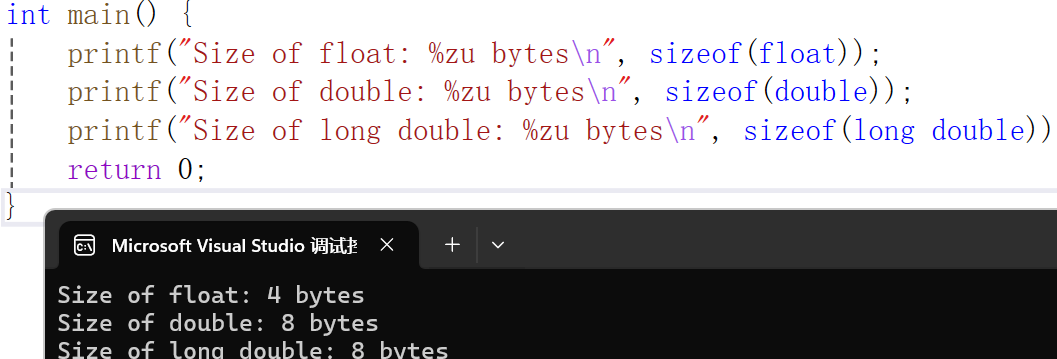
控制台输出的也证明我们的想法是对的!
同样地跟整型一样,为了提高内存使用效率,适时使用不同的浮点型来表示数据。
精度
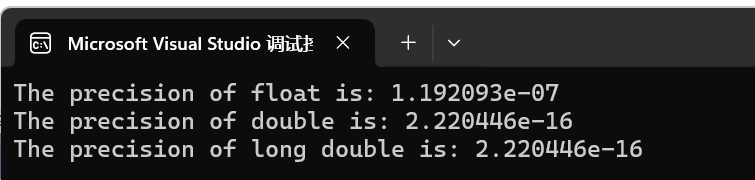
这里的精度指的是:当我们对一个数做加减法而变化量小于相对应的精度时,编译器是无法区分这个变化量的。所以精度也叫能够区分的最小差异。
#include <stdio.h>
#include <float.h>
int main() {
printf("The precision of float is: %e\n", FLT_EPSILON);
printf("The precision of double is: %e\n", DBL_EPSILON);
printf("The precision of long double is: %Le\n", LDBL_EPSILON);
return 0;
}
sizeof
前面我们在查看整型和浮点型所占内存的字节数时,用到了sizeof,它能够查看数据类型和变量以及表达式(但不会运算表达式,且可以省略括号)所占的字节数,所对应的占位符是%zu。
#include<stdio.h>
int main()
{
int a = 1;
printf("%zu", sizeof(a));//这里的括号也可以省略掉写成sizeof a
printf("%zu", sizeof(int));
}控制台:
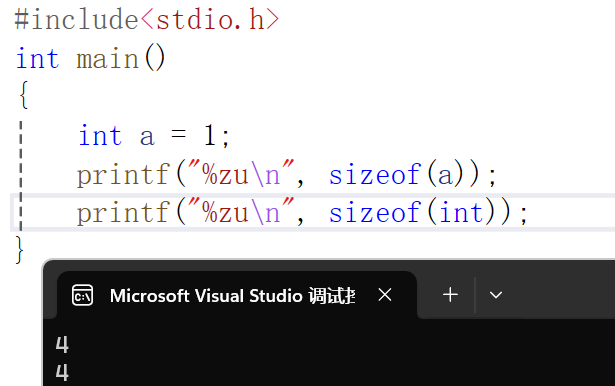
使用sizeof之后会返回一个值,但是C语言中只规定这个值是无符号整型,而没有具体说是哪个整型,对于不同的整型我们也看到了有不同的占位符,这样会很不方便,所以就又新加了一个类型,专门对应sizeof的返回值类型:size_t,占位符用%zu。
那我们来看为什么在进行sizeof内存长度的计算时不会对表达式进行运算:
输入以下代码:
#include<stdio.h>
int main()
{
short a = 1;
int b = 1;
printf("%zu\n", sizeof(a = b + 1));
printf("%d\n", a);
return 0;
}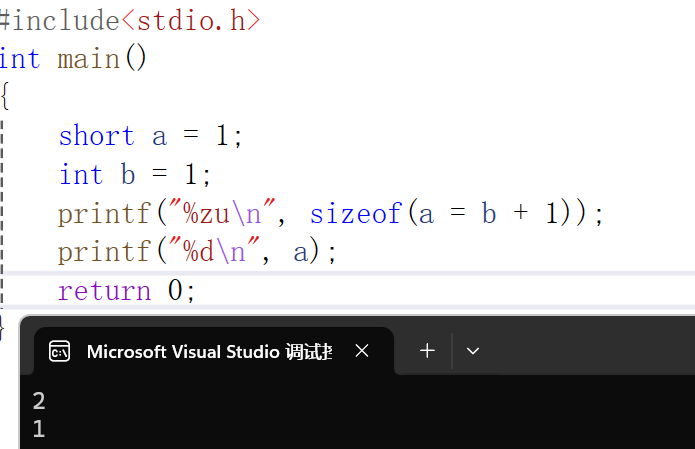
从输出结果中我们可以看到a依旧是1,并且我们说过赋值是从右到左,这就意味着最后表达式的数据类型由最左边变量的数据类型所决定。所以当a不是short而是int时,就像下面输出的是4(int的数据类型长度)
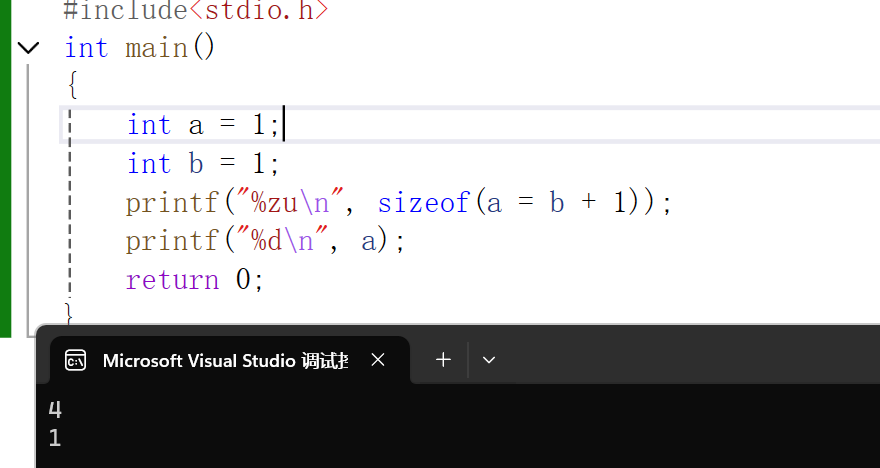
sizeof的表达式不计算
为什么表达式不会运算呢?其实是因为sizeof本身是在编译阶段被处理的,我们说过一份代码文件(.c)最后变成可执行程序需要经过两步,一是编译(包括链接),二是运行。而表达式真正的计算是需要在运行阶段的,sizeof在编译阶段就被处理出结果了,即使会涉及到计算赋值,也是由最左边的数据类型来决定最后的结果。同样地我们讲到库函数和宏定义的时候,它们也是在不同的阶段被处理的,比如库函数是在运行阶段才会被调用,而宏定义则是在预处理阶段(属于编译过程的一步)被对应到它的值(比如INT_MAX对应2的31次方-1)即文本替换。