SadTalker模型部署教程
一、介绍
SadTalker模型是一个基于深度学习的开源模型,主要是用于根据图片和音频文件自动生成人物说话的动画视频。该模型通过接收一张图片和一段音频文件,能够自动生成包含人脸动作(如张嘴、眨眼、移动头部等)的说话动画视频。
二、部署过程
环境配置要求:
系统:Ubuntu20.4系统,
显卡:RTX 3060 12G,
CUDA: 11.3 ,
miniconda3
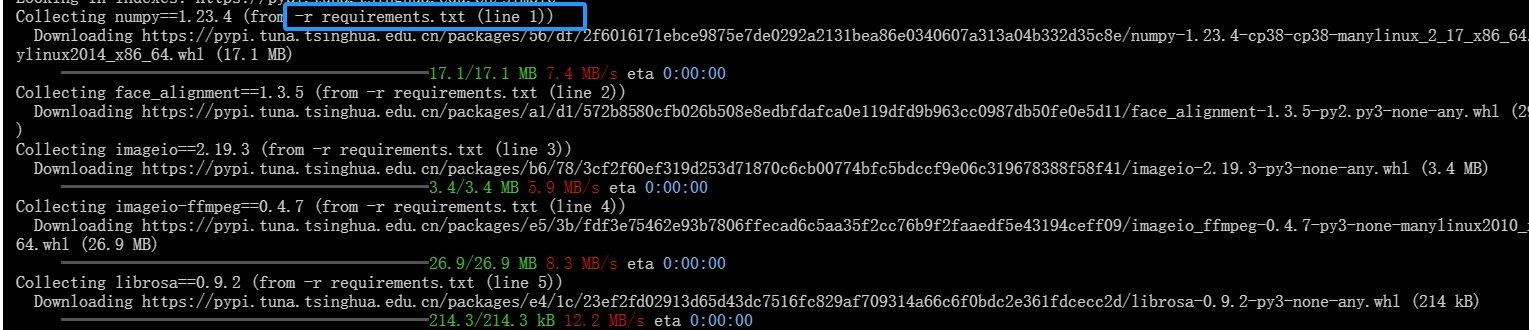
1.模型下载
下载SadTalker模型,输入下列指令:
git clone https://gitclone.com/github.com/OpenTalker/SadTalker.git

2.创建虚拟Python环境
首先使用命令进入SadTalker:
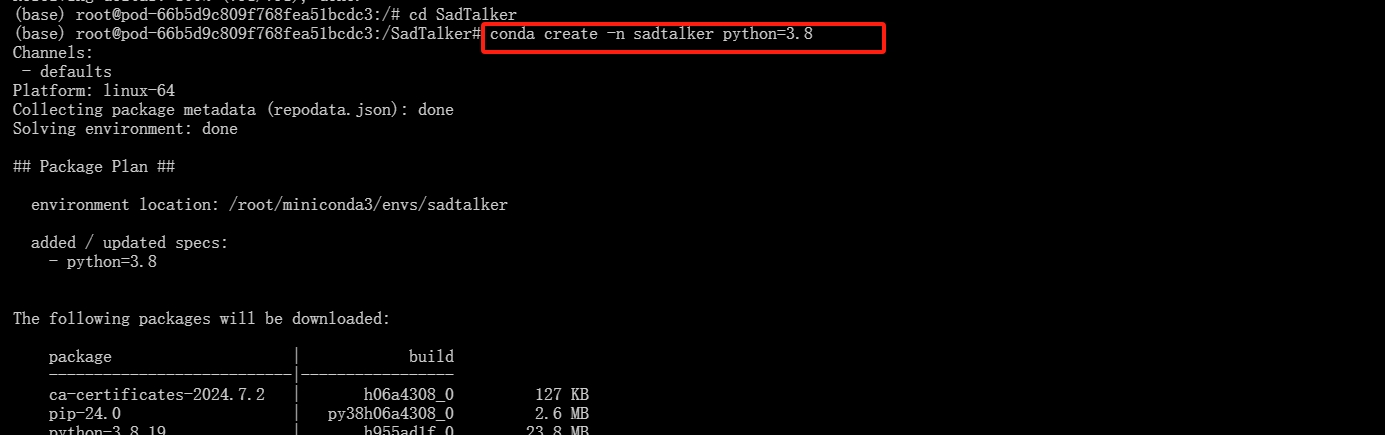
cd SadTalker使用下列命令创建名称为sadtalker,python版本号为3.8的虚拟环境
conda create -n sadtalker python=3.8
3.进入虚拟环境
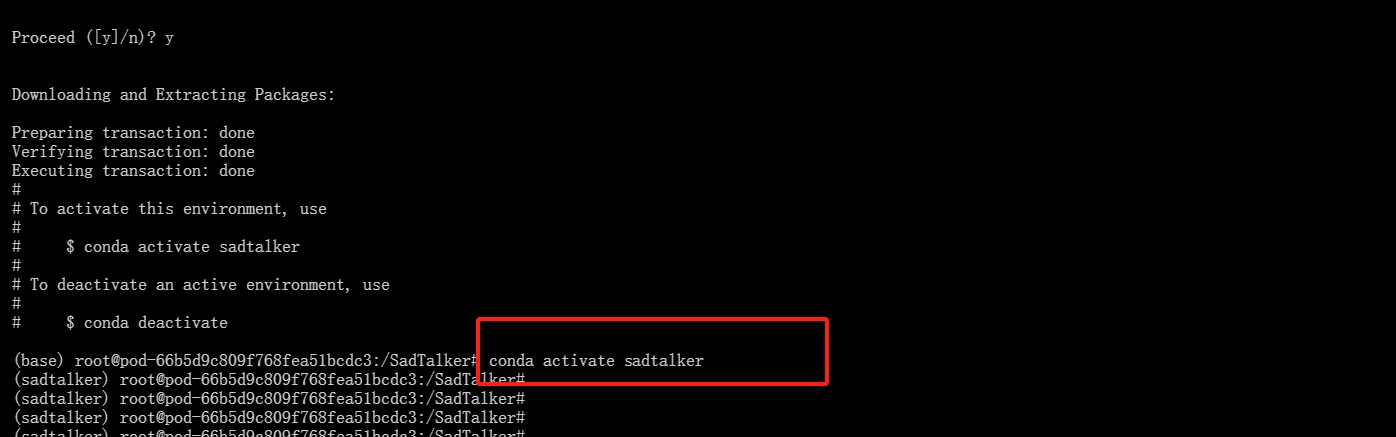
使用下列命令进入:
conda activate sadtalker
4.下载依赖包
使用下列命令:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt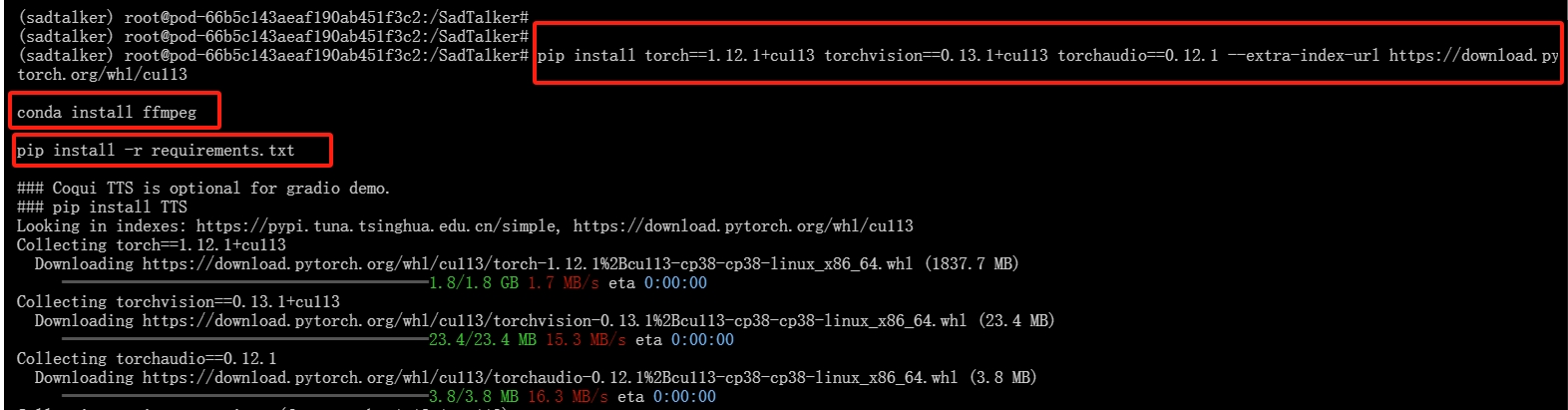
5.下载模型权重文件
使用下列命令进行下载:
bash scripts/download_models.sh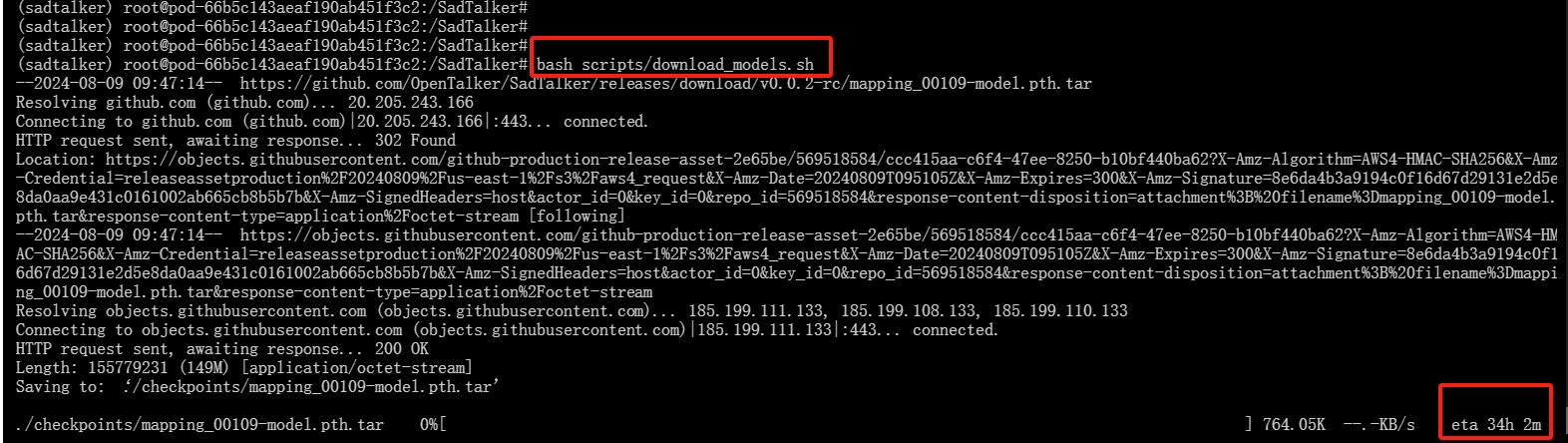
三、启动界面
gradio界面:(推荐)
python app_sadtalker.pyLinux/Mac OS:
bash webui.sh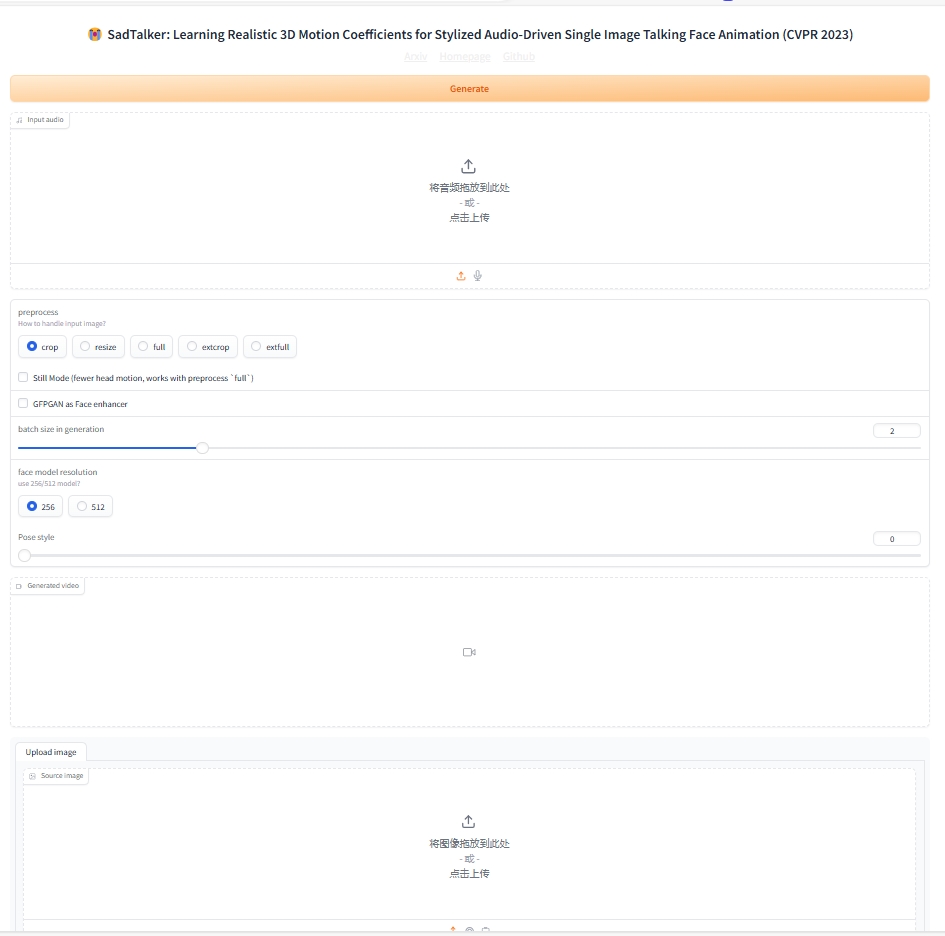
1.报错解决
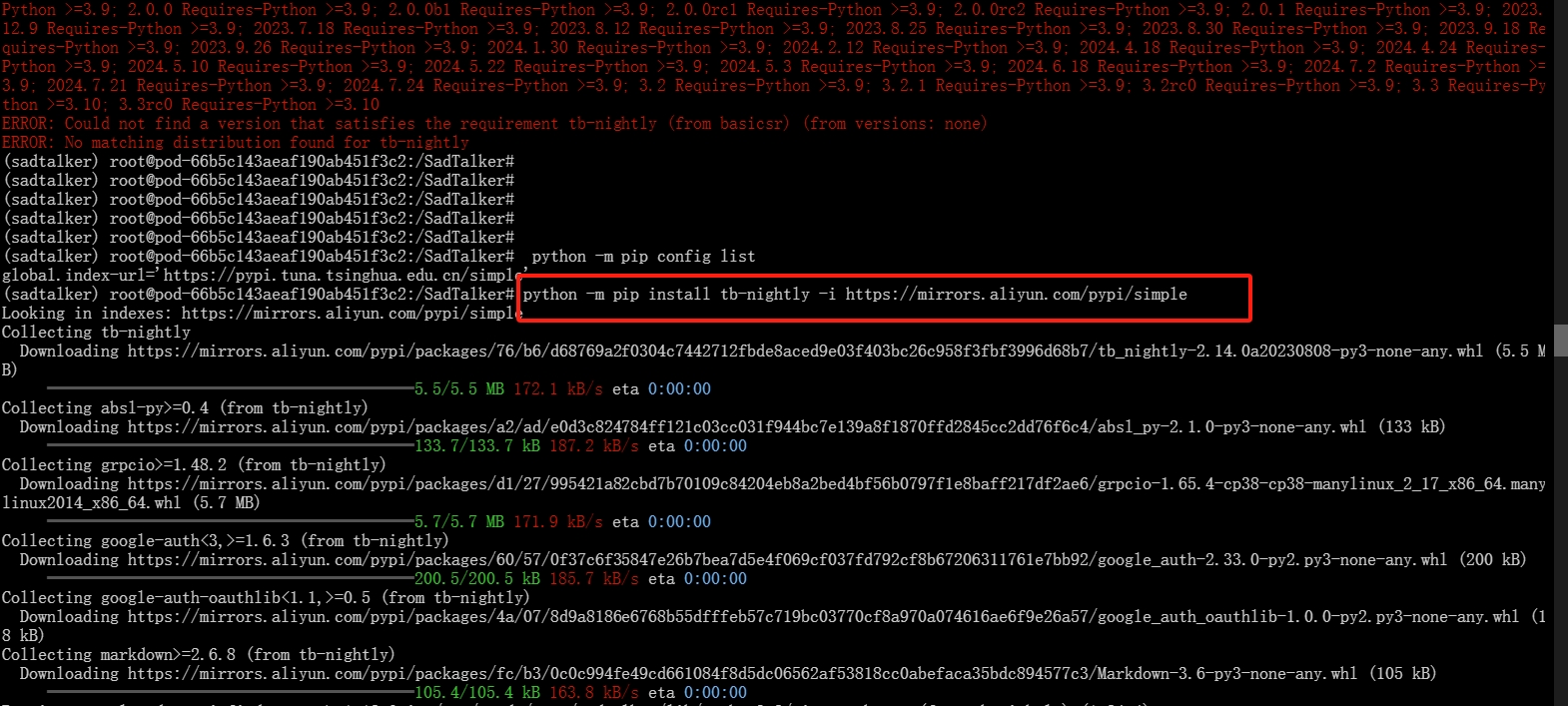
当下载出现“tb-nightly”报错,使用下列命令:
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple下载完成后再重新安装requirements
pip install -r requirements.txt