代码随想录Day 57|prim算法和kruskal算法精讲,题目:寻宝
提示:DDU,供自己复习使用。欢迎大家前来讨论~
文章目录
- 图论part07
- **prim算法精讲**
- 题目:53. 寻宝
- 解题思路:
- Prim算法
- Kruskal算法
- 总结
- Prim算法的核心步骤(三部曲):
- 关键数据结构:
- 算法流程:
- 初始状态
- 2
- 3
- 4
- 5
- 6
- 7
- 最后
- **kruskal算法精讲**
- 题目:[53. 寻宝(第七期模拟笔试) (kamacoder.com)](https://kamacoder.com/problempage.php?pid=1053)
- 解题思路
- 总结
图论part07
prim算法精讲
题目:53. 寻宝
53. 寻宝(第七期模拟笔试) (kamacoder.com)
解题思路:
最小生成树问题是图论中的经典问题,目的是在加权无向图中找到一个包含所有节点的子图(生成树),使得这棵树的总权重(边的权重和)最小。
Prim算法
- 逐步构建:从任意一个节点开始,逐步添加边和节点,直到所有节点都被包含在生成树中。
- 贪心选择:在每一步,选择一条连接已选择的节点集合和未选择的节点且权重最小的边。
- 数据结构:通常使用优先队列(最小堆)来快速找到当前最小的边。
Kruskal算法
- 边的排序:将图中的所有边按权重从小到大排序。
- 贪心选择:按排序后的顺序选择边,保证每次添加的边不会与已选择的边构成环。
- 数据结构:使用并查集来快速检测添加的边是否会造成环。
总结
- 目标:最小生成树的目标是以最小的成本连接图中的所有节点。
- 方法:
- Prim算法从节点出发,逐步构建最小生成树。
- Kruskal算法从边出发,按权重顺序构建最小生成树。
例如本题示例中的无向有权图为:
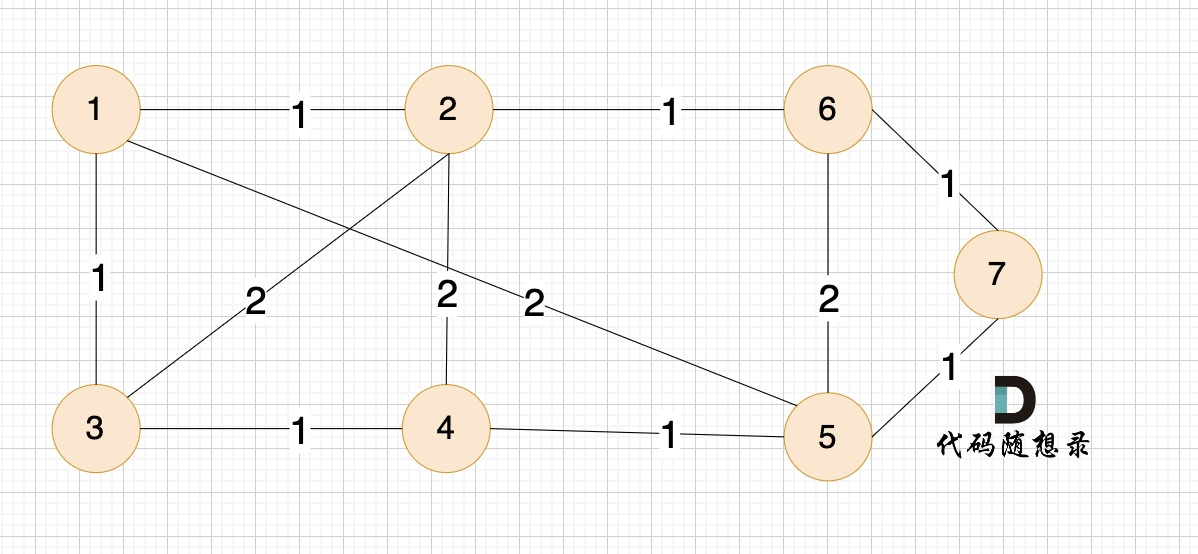
Prim算法的核心步骤(三部曲):
- 选择最近节点:从已有的最小生成树中选择一个距离最小的节点,该节点尚未包括在最小生成树中。
- 加入生成树:将选定的节点加入到最小生成树中。
- 更新距离:更新非最小生成树节点到最小生成树的距离。
关键数据结构:
- minDist数组:记录每个节点到最小生成树的最短距离。
算法流程:
- 从任意一个节点开始构建最小生成树。
- 使用minDist数组跟踪每个节点到最小生成树的最短边的距离。
- 每次循环选择一个未加入最小生成树的节点,该节点有最小的minDist值。
- 更新minDist数组,减去已加入最小生成树的节点相关的距离,以反映新的最短距离。
初始状态
初始化minDist数组为一个最大数,如10001,是为了让数组正确反映每个节点到最小生成树的初始最大距离,以便在算法执行过程中通过比较更新这些距离。
如图:
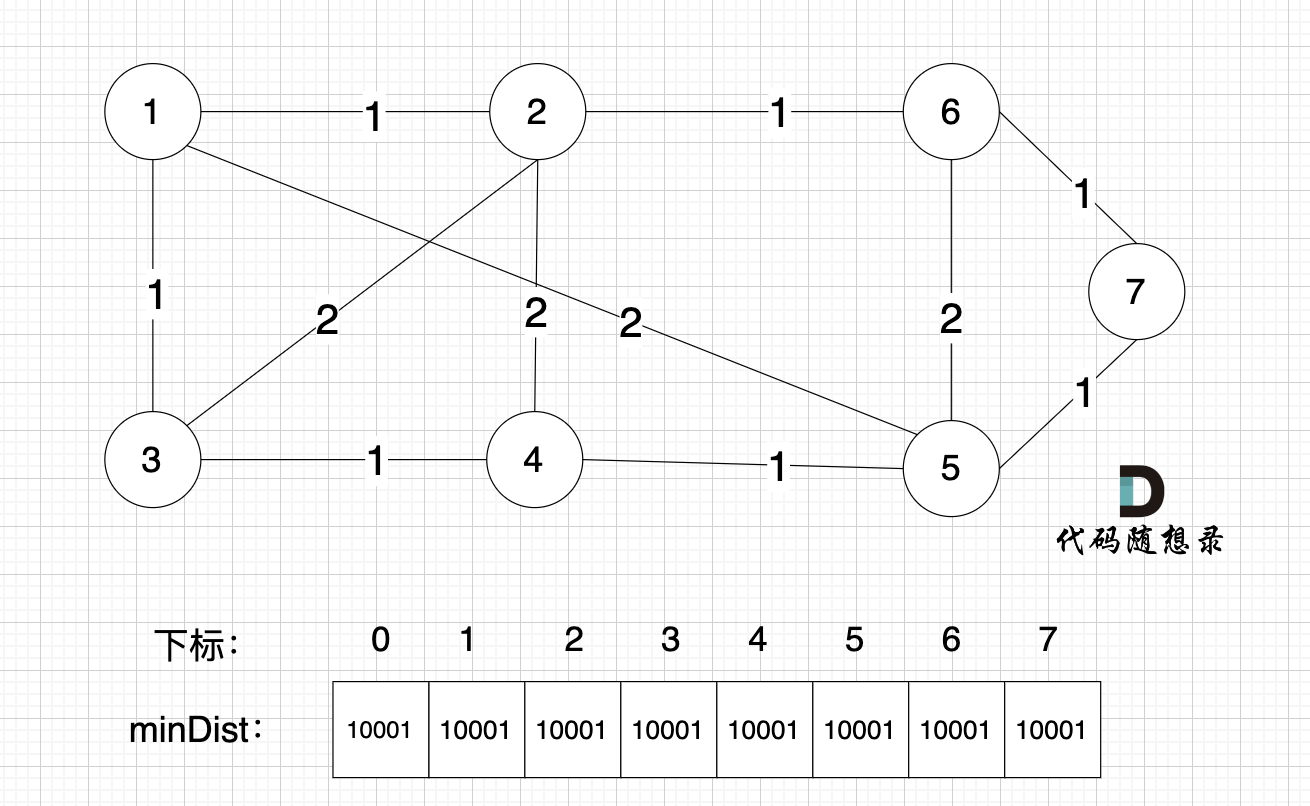
开始构造最小生成树
2
1、prim三部曲,第一步:选距离生成树最近节点
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那我们选择节点1 (符合遍历数组的习惯,第一个遍历的也是节点1)
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1 已经算最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,我们要更新所有节点距离最小生成树的距离,如图:
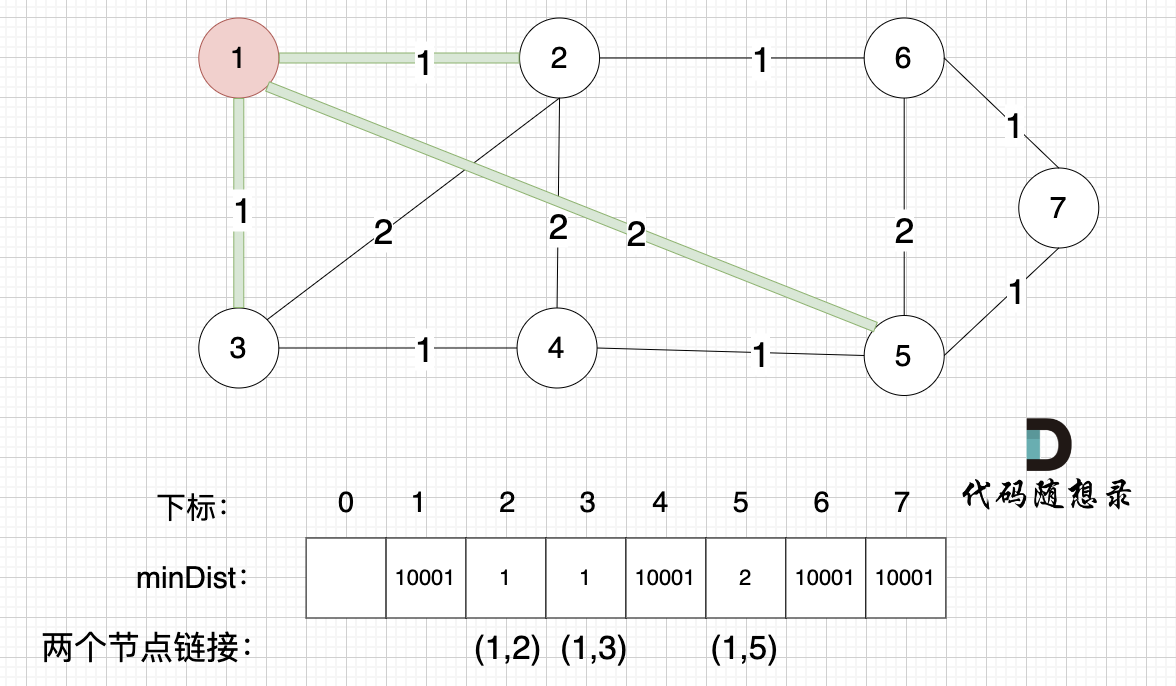
注意下标0,我们就不管它了,下标 1 与节点 1 对应,这样可以避免大家把节点搞混。
此时所有非生成树的节点距离 最小生成树(节点1)的距离都已经跟新了 。
- 节点2 与 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[2]。
- 节点3 和 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[3]。
- 节点5 和 节点1 的距离为2,比原先的 距离值10001小,所以更新minDist[5]。
注意图中我标记了 minDist数组里更新的权值,是哪两个节点之间的权值,例如 minDist[2] =1 ,这个 1 是 节点1 与 节点2 之间的连线,清楚这一点对最后我们记录 最小生成树的权值总和很重要。
3
1、prim三部曲,第一步:选距离生成树最近节点
选取一个距离 最小生成树(节点1) 最近的非生成树里的节点,节点2,3,5 距离 最小生成树(节点1) 最近,选节点 2(其实选 节点3或者节点2都可以,距离一样的)加入最小生成树。
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1 和 节点2,已经算最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,我们要更新节点距离最小生成树的距离,如图:
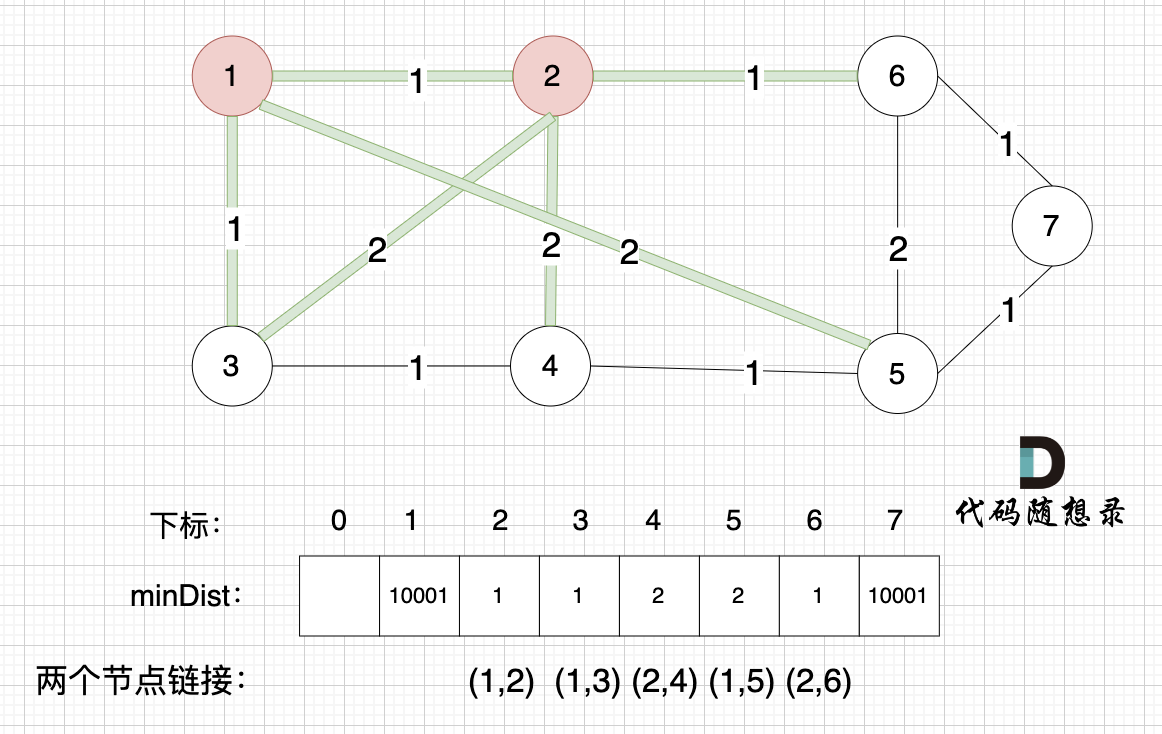
此时所有非生成树的节点距离 最小生成树(节点1、节点2)的距离都已经跟新了 。
- 节点3 和 节点2 的距离为2,和原先的距离值1 小,所以不用更新。
- 节点4 和 节点2 的距离为2,比原先的距离值10001小,所以更新minDist[4]。
- 节点5 和 节点2 的距离为10001(不连接),所以不用更新。
- 节点6 和 节点2 的距离为1,比原先的距离值10001小,所以更新minDist[6]。
4
1、prim三部曲,第一步:选距离生成树最近节点
选择一个距离 最小生成树(节点1、节点2) 最近的非生成树里的节点,节点3,6 距离 最小生成树(节点1、节点2) 最近,选节点3 (选节点6也可以,距离一样)加入最小生成树。
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1 、节点2 、节点3 算是最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
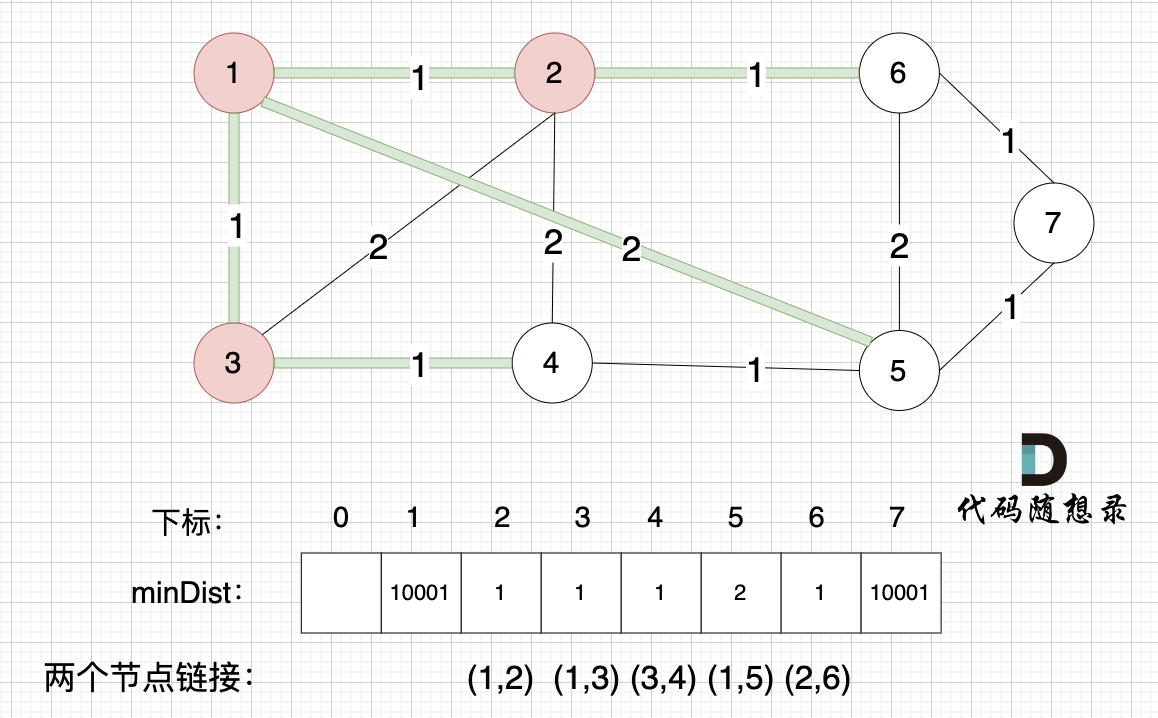
所有非生成树的节点距离 最小生成树(节点1、节点2、节点3 )的距离都已经跟新了 。
- 节点 4 和 节点 3的距离为 1,和原先的距离值 2 小,所以更新minDist[4]为1。
上面为什么我们只比较 节点4 和 节点3 的距离呢?
因为节点3加入 最小生成树后,非 生成树节点 只有 节点 4 和 节点3是链接的,所以需要重新更新一下 节点4距离最小生成树的距离,其他节点距离最小生成树的距离 都不变。
5
1、prim三部曲,第一步:选距离生成树最近节点
继续选择一个距离 最小生成树(节点1、节点2、节点3) 最近的非生成树里的节点,为了巩固大家对 minDist数组的理解,这里我再啰嗦一遍:
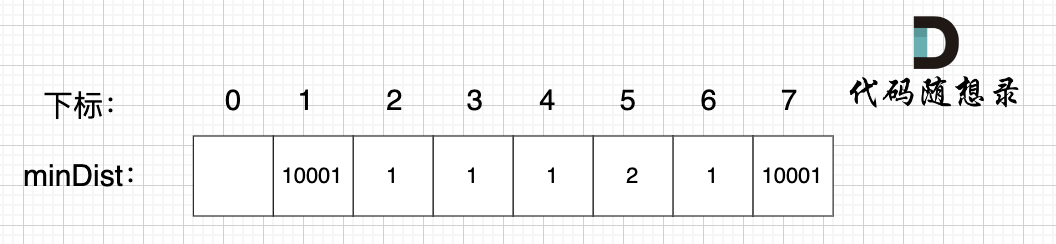
minDist数组 是记录了 所有非生成树节点距离生成树的最小距离,所以 从数组里我们能看出来,非生成树节点 4 和 节点 6 距离 生成树最近。
任选一个加入生成树,我们选 节点4(选节点6也行) 。
注意,我们根据 minDist数组,选取距离 生成树 最近的节点 加入生成树,那么 minDist数组里记录的其实也是 最小生成树的边的权值(我在图中把权值对应的是哪两个节点也标记出来了)。因为 最后我们要求 最小生成树里所有边的权值和。
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1、节点2、节点3、节点4 算是 最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
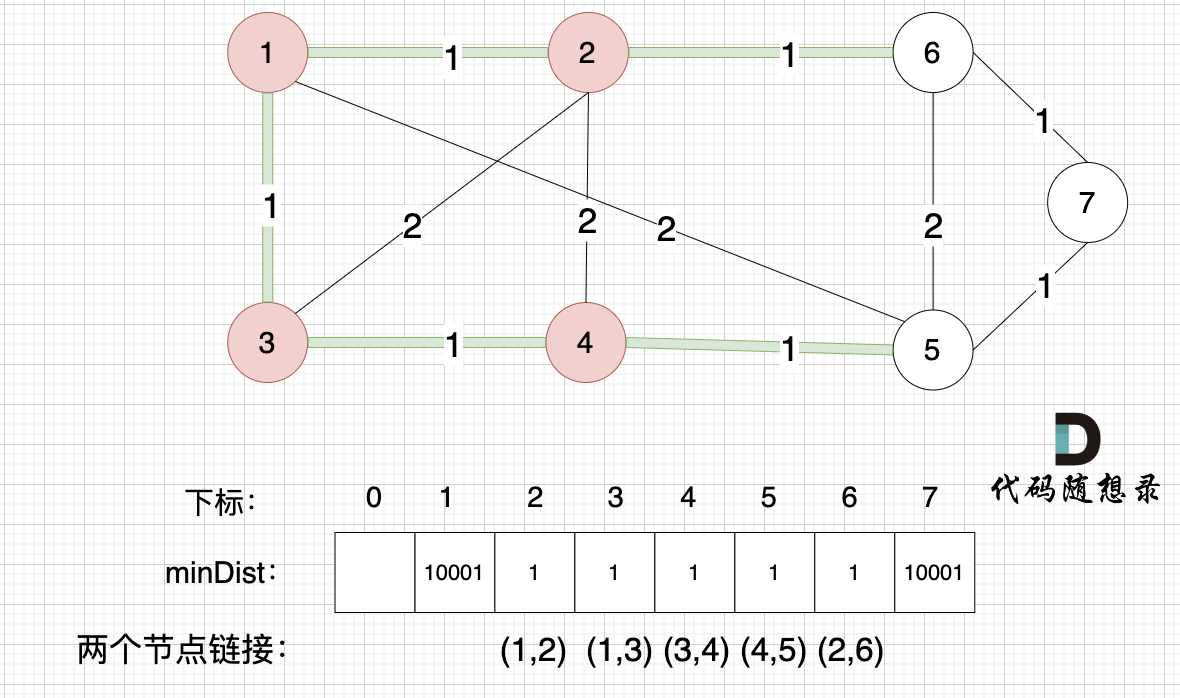
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 )的距离 。
- 节点 5 和 节点 4的距离为 1,和原先的距离值 2 小,所以更新minDist[5]为1。
6
1、prim三部曲,第一步:选距离生成树最近节点
继续选距离 最小生成树(节点1、节点2、节点3、节点4 )最近的非生成树里的节点,只有 节点 5 和 节点6。
选节点5 (选节点6也可以)加入 生成树。
2、prim三部曲,第二步:最近节点加入生成树
节点1、节点2、节点3、节点4、节点5 算是 最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
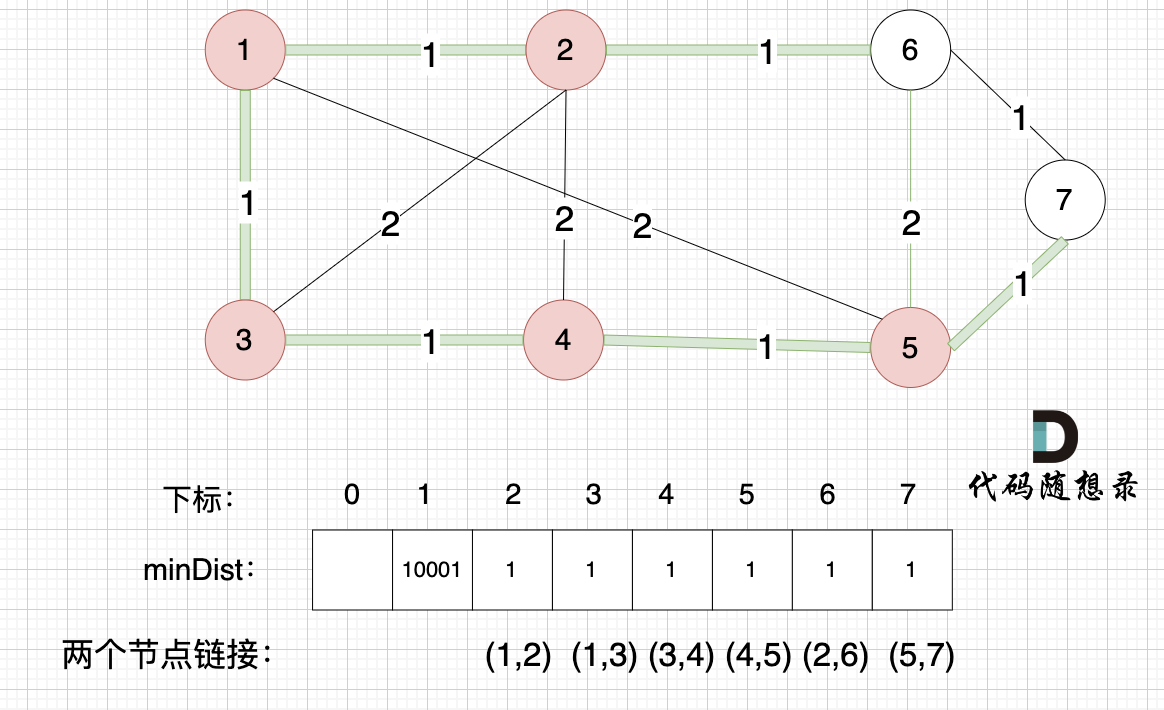
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)的距离 。
- 节点 6 和 节点 5 距离为 2,比原先的距离值 1 大,所以不更新
- 节点 7 和 节点 5 距离为 1,比原先的距离值 10001小,更新 minDist[7]
7
1、prim三部曲,第一步:选距离生成树最近节点
继续选距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)最近的非生成树里的节点,只有 节点 6 和 节点7。
2、prim三部曲,第二步:最近节点加入生成树
选节点6 (选节点7也行,距离一样的)加入生成树。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
节点1、节点2、节点3、节点4、节点5、节点6 算是 最小生成树的节点 ,接下来更新节点距离最小生成树的距离,如图:
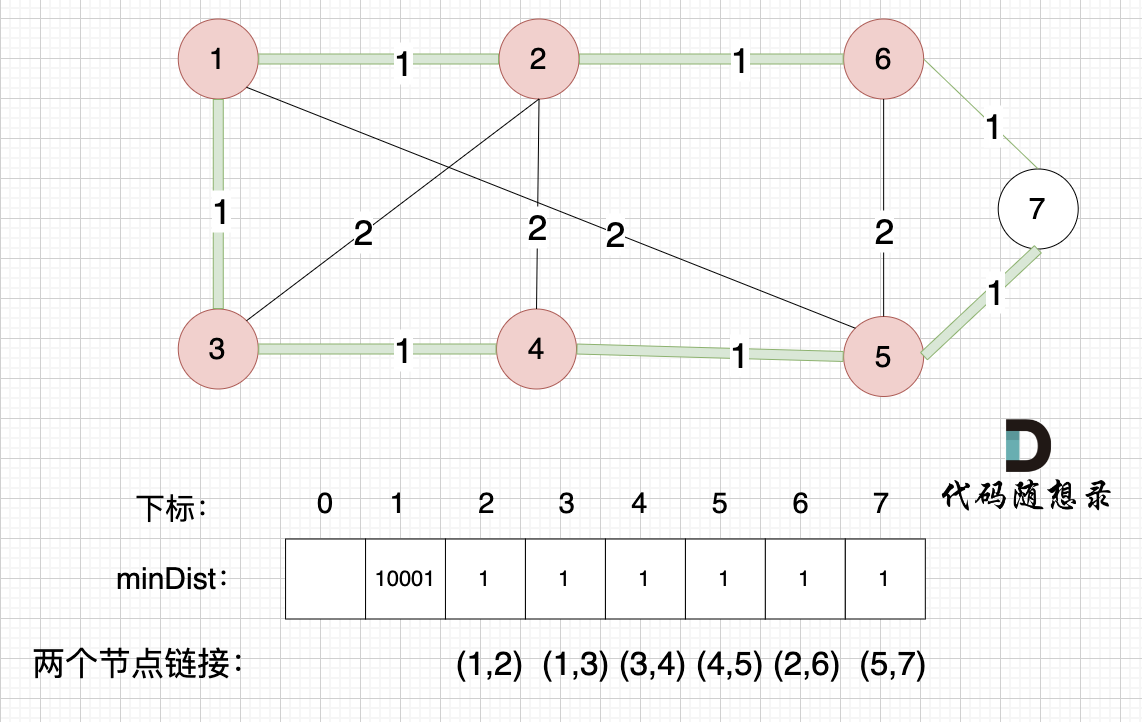
这里就不在重复描述了,大家类推,最后,节点7加入生成树,如图:
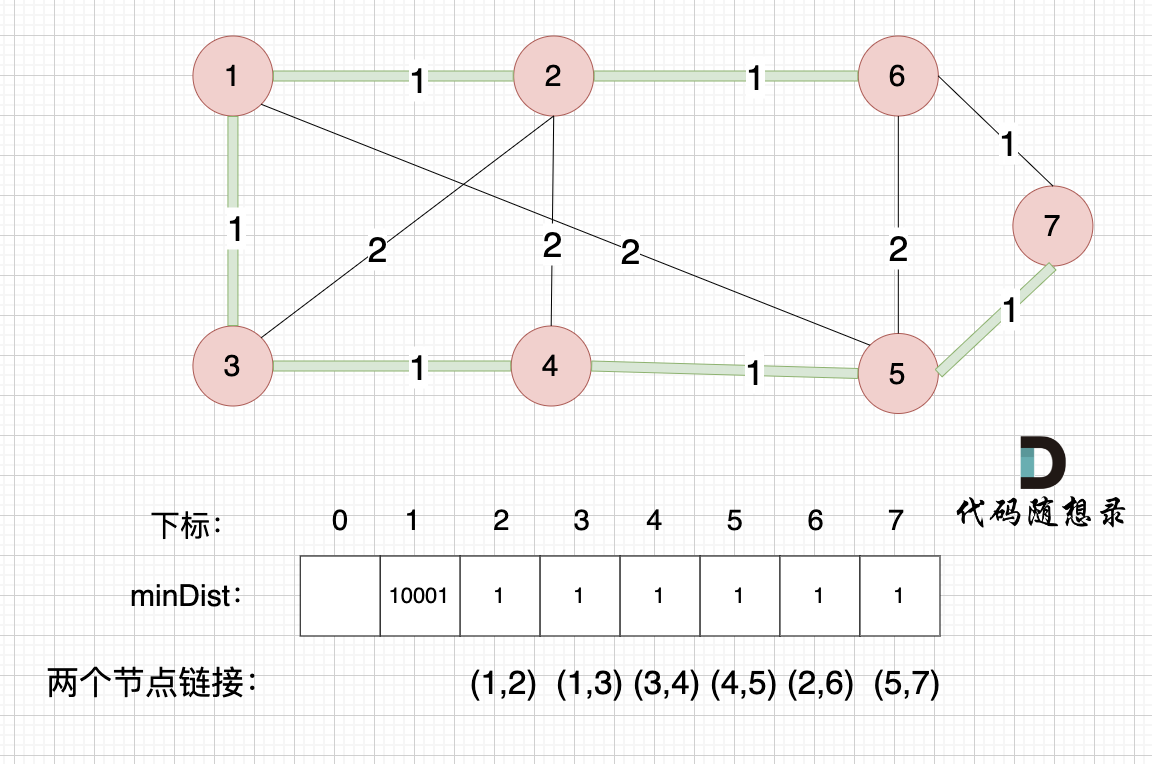
最后
在Prim算法的最后,我们成功构建了一棵最小生成树,其中绿色的边展示了连接所有节点的最小权值路径。通过始终选择距离已有最小生成树最近的节点加入,我们确保了总权值最小化。minDist数组在整个过程中起到了关键作用,它记录了所有非生成树节点到生成树的最小距离,这些距离实际上代表了最小生成树边的权值。随着算法的进行,我们不断更新minDist数组,最终,这个数组中的值累加起来,就得到了最小生成树的总权值。
以下代码,对 prim三部曲,做了重点注释,大家根据这三步,就可以 透彻理解prim。
#include<iostream>
#include<vector>
#include <climits>
using namespace std;
int main() {
int v, e;
int x, y, k;
cin >> v >> e;
// 填一个默认最大值,题目描述val最大为10000
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
while (e--) {
cin >> x >> y >> k;
// 因为是双向图,所以两个方向都要填上
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
vector<int> minDist(v + 1, 10001);
// 这个节点是否在树里
vector<bool> isInTree(v + 1, false);
// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起
for (int i = 1; i < v; i++) {
// 1、prim三部曲,第一步:选距离生成树最近节点
int cur = -1; // 选中哪个节点 加入最小生成树
int minVal = INT_MAX;
for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始
// 选取最小生成树节点的条件:
// (1)不在最小生成树里
// (2)距离最小生成树最近的节点
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 2、prim三部曲,第二步:最近节点(cur)加入生成树
isInTree[cur] = true;
// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下
// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢
for (int j = 1; j <= v; j++) {
// 更新的条件:
// (1)节点是 非生成树里的节点
// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边
result += minDist[i];
}
cout << result << endl;
}
时间复杂度为 O(n^2),其中 n 为节点数量。
kruskal算法精讲
题目:53. 寻宝(第七期模拟笔试) (kamacoder.com)
解题思路
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
下面我们画图举例说明kruscal的工作过程。
依然以示例中,如下这个图来举例。
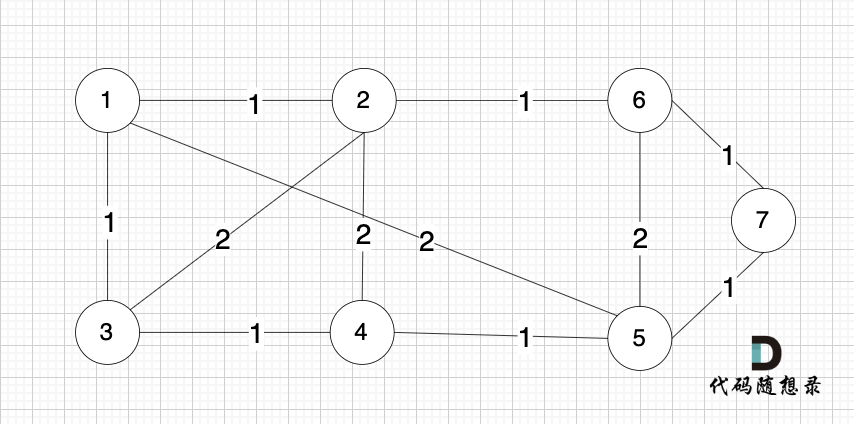
将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
开始从头遍历排序后的边。
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
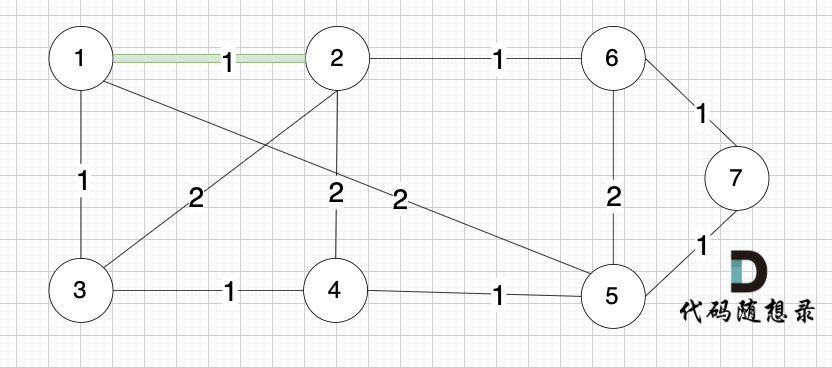
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。
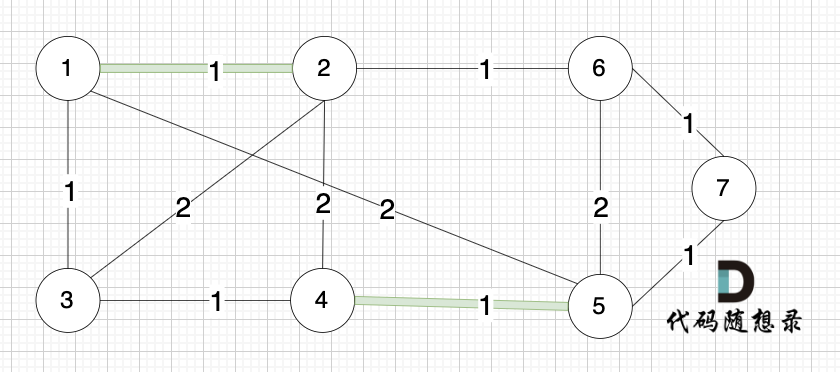
大家判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行
(这里在强调一下,以下选边是按照上面排序好的边的数组来选择的)
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。
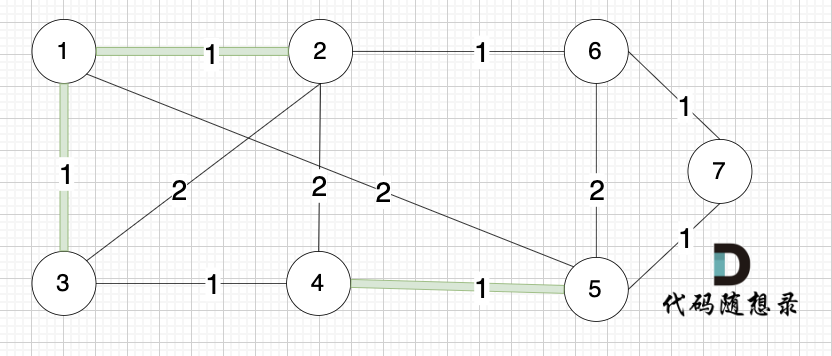
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。
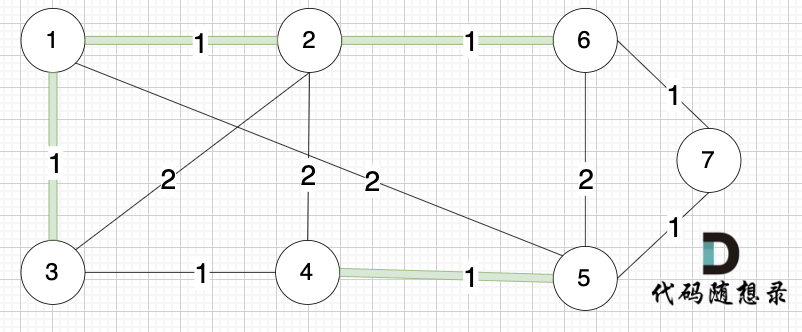
选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。
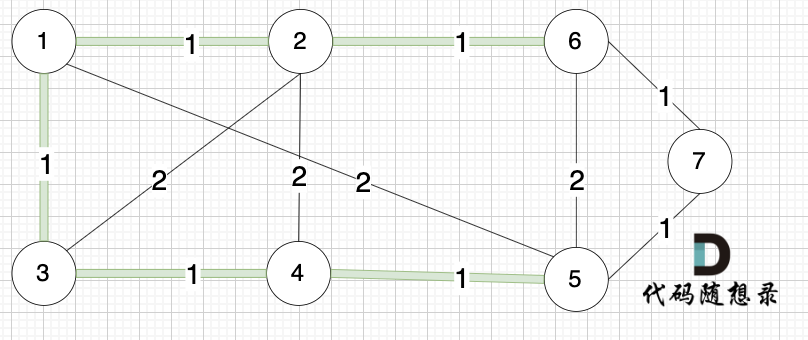
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。
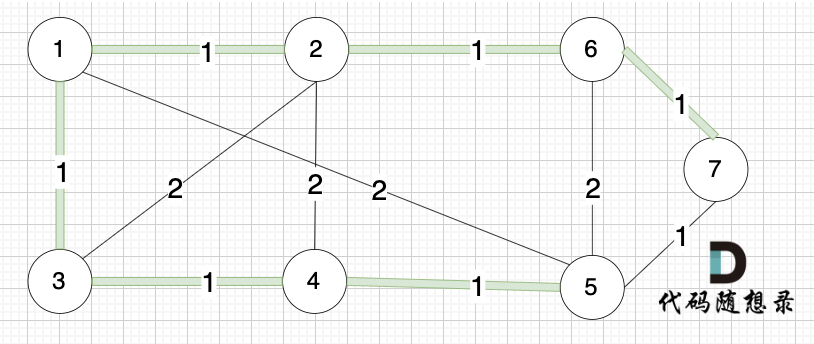
选边(5,7),节点5 和 节点7 在同一个集合,不做计算。
选边(1,5),两个节点在同一个集合,不做计算。
后面遍历 边(3,2),(2,4),(5,6) 同理,都因两个节点已经在同一集合,不做计算。
此时 我们就已经生成了一个最小生成树,即:
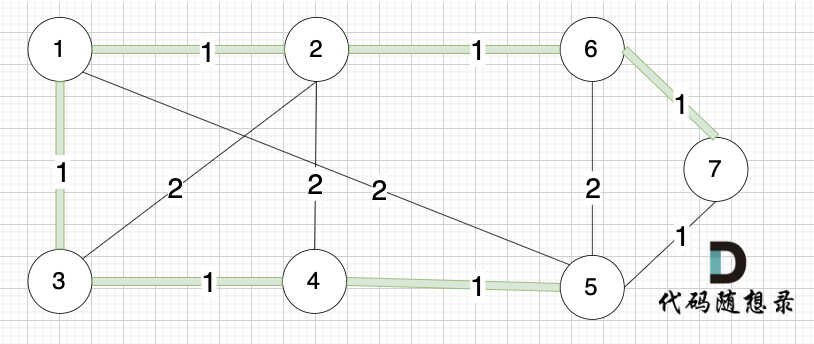
在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
并查集主要就两个功能:
- 将两个元素添加到一个集合中
- 判断两个元素在不在同一个集合
本题代码如下,已经详细注释:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// l,r为 边两边的节点,val为边的数值
struct Edge {
int l, r, val;
};
// 节点数量
int n = 10001;
// 并查集标记节点关系的数组
vector<int> father(n, -1); // 节点编号是从1开始的,n要大一些
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集的查找操作
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 并查集的加入集合
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
int main() {
int v, e;
int v1, v2, val;
vector<Edge> edges;
int result_val = 0;
cin >> v >> e;
while (e--) {
cin >> v1 >> v2 >> val;
edges.push_back({v1, v2, val});
}
// 执行Kruskal算法
// 按边的权值对边进行从小到大排序
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
return a.val < b.val;
});
// 并查集初始化
init();
// 从头开始遍历边
for (Edge edge : edges) {
// 并查集,搜出两个节点的祖先
int x = find(edge.l);
int y = find(edge.r);
// 如果祖先不同,则不在同一个集合
if (x != y) {
result_val += edge.val; // 这条边可以作为生成树的边
join(x, y); // 两个节点加入到同一个集合
}
}
cout << result_val << endl;
return 0;
}
时间复杂度:nlogn (快排) + logn (并查集) ,所以最后依然是 nlogn 。n为边的数量。
总结
Prim算法:
想象你在串珠子,你先拿起一个珠子作为起点,然后看看周围哪颗珠子离你最近,就用线把它串起来。接着,你再从这串珠子中找一个离得最远但还没串起来、并且离你最近的珠子,继续串。就这样一直串下去,直到所有的珠子都被串起来。Prim算法就是这样,每次都是选择离已有的树最近的新顶点加入。
Kruskal算法:
想象你在用一些小棒搭一座桥,这些小棒有长有短(代表不同的边权值)。你先把所有的小棒按照从短到长的顺序排好,然后从最短的小棒开始,如果用它搭桥不会形成环(比如桥已经绕回来了),那你就用它搭。接着,你继续找下一根小棒,重复这个过程,直到桥搭完,所有的顶点都连起来了。Kruskal算法就是这样,每次都是选择权值最小的边,只要它不会导致环,就加入到最小生成树中。