Chatgpt论文笔记——GPT1详细解读与可运行的代码
前言
论文:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
时间:2018年6月
贡献:
提出了大规模数据上无监督预训练然后在目标任务上有监督finetune的范式。
具体实现
当时由于NLP领域不存在像图像领域中ImageNet那样百万级别标注的数据(并且图像的像素包含了比句子更丰富的信息,百万级别的图像标注数据相当于千万级别的句子标注数据),所以当时NLP的发展比较缓慢。本文相当于开疆拓土采用了在大规模数据上进行无监督预训练然后再目标任务上进行有监督finetune的尝试。
最后实验的效果是在12个NLP任务上,9个取得了超过SOTA的效果:

模型结构
GPT的模型结构核心组建是transformer的decoder模块,为什么用transformer而不用经典的RNN或者LSTM,GRU之类呢?因为作者在论文中说到,相比于RNN,transformer学到的特征更加的稳健一些,这个可能还是跟transformer里面的self attention有关,它更加的结构化并且可以学习了token和token之间的关系,对句子的理解更加的深刻。
完整的GPT1模型结构也比较简单:
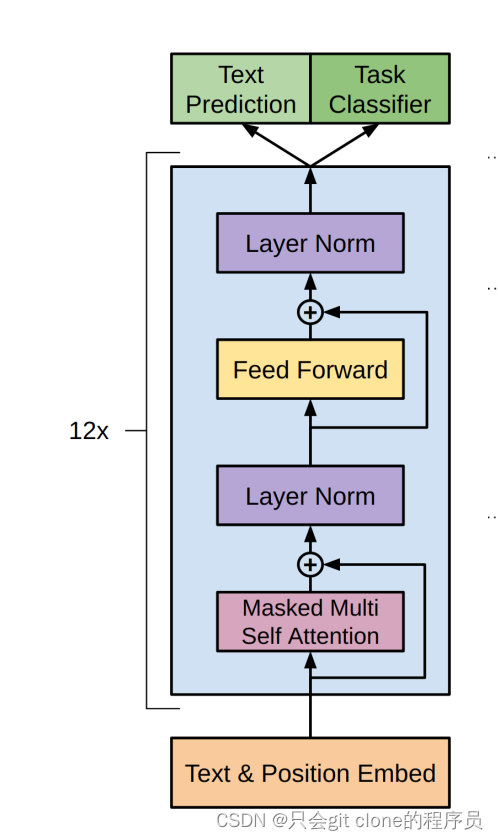
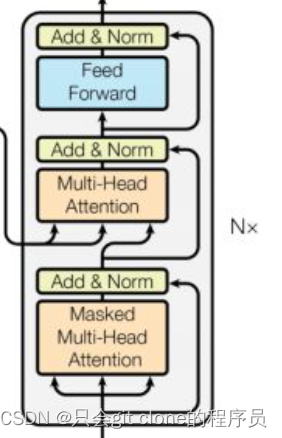
整体采用了12个transformer的decoder模块构成,其实这里说的decoder给我造成了很多误解,我记得transformer的decoder部分长这样:
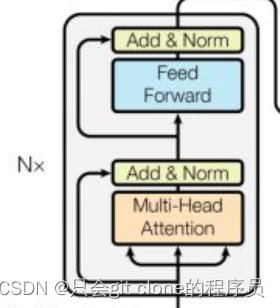
但是看GPT论文的结构又是transformer的encoder的样子:
所以一直没明白为啥说用的是decoder,仔细看了下别人实现的代码才发现了,主要是GPT仅仅用了单向的transformer,也就是mask multi head self attention,也就是transformer的decoder模块的这部分:
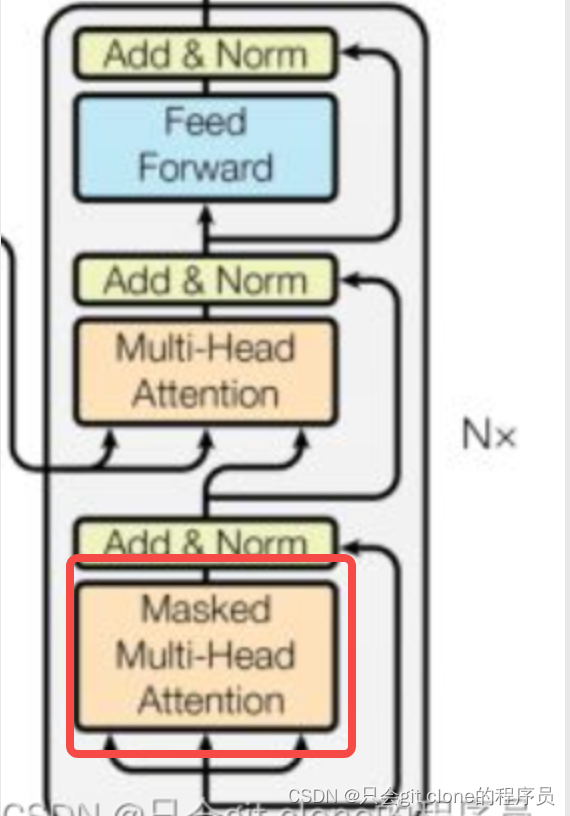
但是整个结构还是还是encoder一样的,只是MHA这个地方用了mask所以说成了用了decoder部分。
至于为什么用带Mask的MHA呢?
GPT中因为要完成语言模型的训练,也就要求Pre-Training预测下一个词的时候只能够看见当前以及之前的词,这也是GPT放弃原本Transformer的双向结构转而采用单向结构的原因。
代码
没有代码是不完整的,直接上模型结构的代码
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k, attn_pdrop):
super(ScaledDotProductAttention, self).__init__()
self.d_k = d_k
self.dropout = nn.Dropout(attn_pdrop)
def forward(self, q, k, v, attn_mask):
# |q| : (batch_size, n_heads, q_len, d_k)
# |k| : (batch_size, n_heads, k_len, d_k)
# |v| : (batch_size, n_heads, v_len, d_v)
# |attn_mask| : (batch_size, n_heads, q_len, k_len)
attn_score = torch.matmul(q, k.transpose(-1, -2)) / (self.d_k ** 0.5)
attn_score.masked_fill_(attn_mask, -1e9)
# |attn_scroe| : (batch_size, n_heads, q_len, k_len)
attn_weights = nn.Softmax(dim=-1)(attn_score)
attn_weights = self.dropout(attn_weights)
# |attn_weights| : (batch_size, n_heads, q_len, k_len)
output = torch.matmul(attn_weights, v)
# |output| : (batch_size, n_heads, q_len, d_v)
return output, attn_weights
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads, attn_pdrop):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
self.d_k = self.d_v = d_model // n_heads
self.WQ = nn.Linear(d_model, d_model)
self.WK = nn.Linear(d_model, d_model)
self.WV = nn.Linear(d_model, d_model)
self.scaled_dot_product_attn = ScaledDotProductAttention(self.d_k, attn_pdrop)
self.linear = nn.Linear(n_heads * self.d_v, d_model)
def forward(self, Q, K, V, attn_mask):
# |Q| : (batch_size, q_len(=seq_len), d_model)
# |K| : (batch_size, k_len(=seq_len), d_model)
# |V| : (batch_size, v_len(=seq_len), d_model)
# |attn_mask| : (batch_size, q_len, k_len)
batch_size = Q.size(0)
q_heads = self.WQ(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
k_heads = self.WK(K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
v_heads = self.WV(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2)
# |q_heads| : (batch_size, n_heads, q_len, d_k), |k_heads| : (batch_size, n_heads, k_len, d_k), |v_heads| : (batch_size, n_heads, v_len, d_v)
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1)
# |attn_mask| : (batch_size, n_heads, q_len, k_len)
attn, attn_weights = self.scaled_dot_product_attn(q_heads, k_heads, v_heads, attn_mask)
# |attn| : (batch_size, n_heads, q_len, d_v)
# |attn_weights| : (batch_size, n_heads, q_len, k_len)
attn = attn.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v)
# |attn| : (batch_size, q_len, n_heads * d_v)
outputs = self.linear(attn)
# |outputs| : (batch_size, q_len, d_model)
return outputs, attn_weights
class PositionWiseFeedForwardNetwork(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForwardNetwork, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.gelu = nn.GELU()
nn.init.normal_(self.linear1.weight, std=0.02)
nn.init.normal_(self.linear2.weight, std=0.02)
def forward(self, inputs):
# |inputs| : (batch_size, seq_len, d_model)
outputs = self.gelu(self.linear1(inputs))
# |outputs| : (batch_size, seq_len, d_ff)
outputs = self.linear2(outputs)
# |outputs| : (batch_size, seq_len, d_model)
return outputs
class DecoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, attn_pdrop, resid_pdrop):
super(DecoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, n_heads, attn_pdrop)
self.dropout1 = nn.Dropout(resid_pdrop)
self.layernorm1 = nn.LayerNorm(d_model, eps=1e-5)
self.ffn = PositionWiseFeedForwardNetwork(d_model, d_ff)
self.dropout2 = nn.Dropout(resid_pdrop)
self.layernorm2 = nn.LayerNorm(d_model, eps=1e-5)
def forward(self, inputs, attn_mask):
# |inputs| : (batch_size, seq_len, d_model)
# |attn_mask| : (batch_size, seq_len, seq_len)
attn_outputs, attn_weights = self.mha(inputs, inputs, inputs, attn_mask)
attn_outputs = self.dropout1(attn_outputs)
attn_outputs = self.layernorm1(inputs + attn_outputs)
# |attn_outputs| : (batch_size, seq_len, d_model)
# |attn_weights| : (batch_size, n_heads, q_len(=seq_len), k_len(=seq_len))
ffn_outputs = self.ffn(attn_outputs)
ffn_outputs = self.dropout2(ffn_outputs)
ffn_outputs = self.layernorm2(attn_outputs + ffn_outputs)
# |ffn_outputs| : (batch_size, seq_len, d_model)
return ffn_outputs, attn_weights
class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, seq_len, d_model, n_layers, n_heads, d_ff, embd_pdrop, attn_pdrop, resid_pdrop,
pad_id):
super(TransformerDecoder, self).__init__()
self.pad_id = pad_id
# layers
self.embedding = nn.Embedding(vocab_size, d_model)
self.dropout = nn.Dropout(embd_pdrop)
self.pos_embedding = nn.Embedding(seq_len + 1, d_model)
self.layers = nn.ModuleList(
[DecoderLayer(d_model, n_heads, d_ff, attn_pdrop, resid_pdrop) for _ in range(n_layers)])
nn.init.normal_(self.embedding.weight, std=0.02)
def forward(self, inputs):
# |inputs| : (batch_size, seq_len)
positions = torch.arange(inputs.size(1), device=inputs.device, dtype=inputs.dtype).repeat(inputs.size(0), 1) + 1
position_pad_mask = inputs.eq(self.pad_id)
positions.masked_fill_(position_pad_mask, 0)
# |positions| : (batch_size, seq_len)
outputs = self.dropout(self.embedding(inputs)) + self.pos_embedding(positions)
# |outputs| : (batch_size, seq_len, d_model)
attn_pad_mask = self.get_attention_padding_mask(inputs, inputs, self.pad_id)
# |attn_pad_mask| : (batch_size, seq_len, seq_len)
subsequent_mask = self.get_attention_subsequent_mask(inputs).to(device=attn_pad_mask.device)
# |subsequent_mask| : (batch_size, seq_len, seq_len)
attn_mask = torch.gt((attn_pad_mask.to(dtype=subsequent_mask.dtype) + subsequent_mask), 0)
# |attn_mask| : (batch_size, seq_len, seq_len)
attention_weights = []
for layer in self.layers:
outputs, attn_weights = layer(outputs, attn_mask)
# |outputs| : (batch_size, seq_len, d_model)
# |attn_weights| : (batch_size, n_heads, seq_len, seq_len)
attention_weights.append(attn_weights)
return outputs, attention_weights
def get_attention_padding_mask(self, q, k, pad_id):
attn_pad_mask = k.eq(pad_id).unsqueeze(1).repeat(1, q.size(1), 1)
# |attn_pad_mask| : (batch_size, q_len, k_len)
return attn_pad_mask
def get_attention_subsequent_mask(self, q):
bs, q_len = q.size()
subsequent_mask = torch.ones(bs, q_len, q_len).triu(diagonal=1)
# |subsequent_mask| : (batch_size, q_len, q_len)
return subsequent_mask
class GPT(nn.Module):
def __init__(self,
vocab_size,
seq_len=512,
d_model=768,
n_layers=12,
n_heads=12,
d_ff=3072,
embd_pdrop=0.1,
attn_pdrop=0.1,
resid_pdrop=0.1,
pad_id=0):
super(GPT, self).__init__()
self.decoder = TransformerDecoder(vocab_size, seq_len, d_model, n_layers, n_heads, d_ff,
embd_pdrop, attn_pdrop, resid_pdrop, pad_id)
def forward(self, inputs):
# |inputs| : (batch_size, seq_len)
outputs, attention_weights = self.decoder(inputs)
# |outputs| : (batch_size, seq_len, d_model)
# |attention_weights| : [(batch_size, n_heads, seq_len, seq_len)] * n_layers
return outputs, attention_weights
if __name__ == '__main__':
model = GPT(vocab_size=10000)
print(model)
input = torch.ones(16, 128).long()
out = model(input)
print(out[0].shape)
看着很长,其实代码很简单,就是翻译这张图:
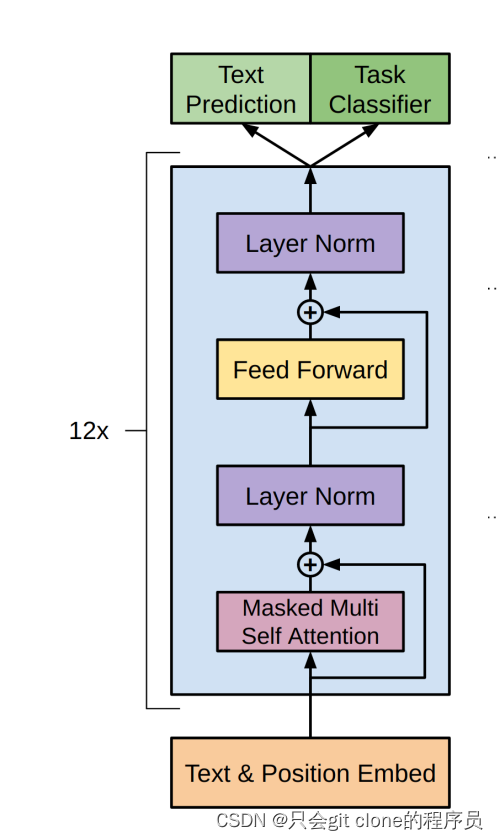
首先GPT这个类就是定义了12层transformer的decoder构成的:
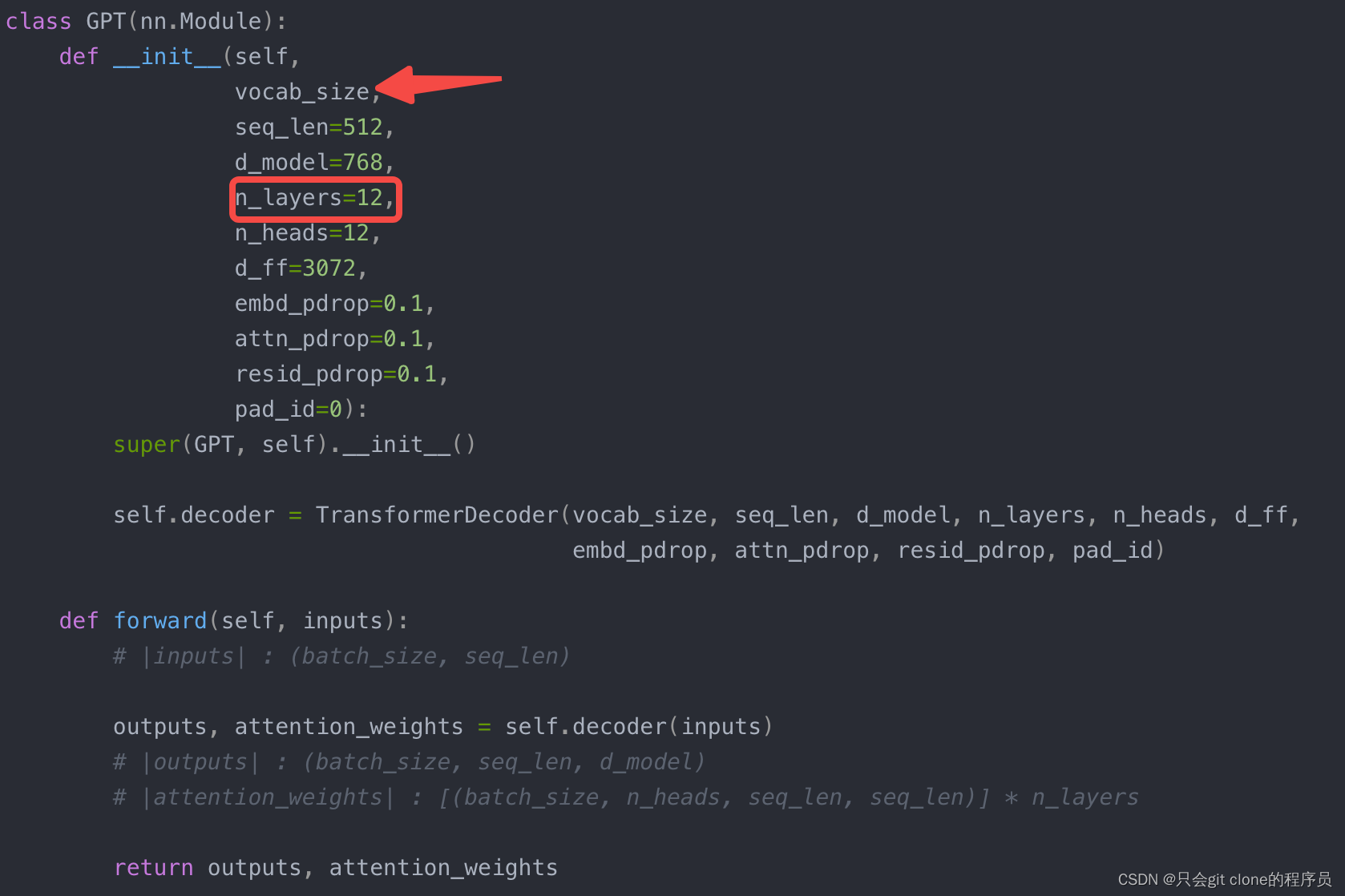
vocab_size是词典的大小,就比如说英文一共有10w个单词,那么vocab_size就是10w。用来配合nn.embedding
模块把单词抽成embedding。
然后每个decoder里面就是对着图写代码了,其中比较核心的就是两个mask:
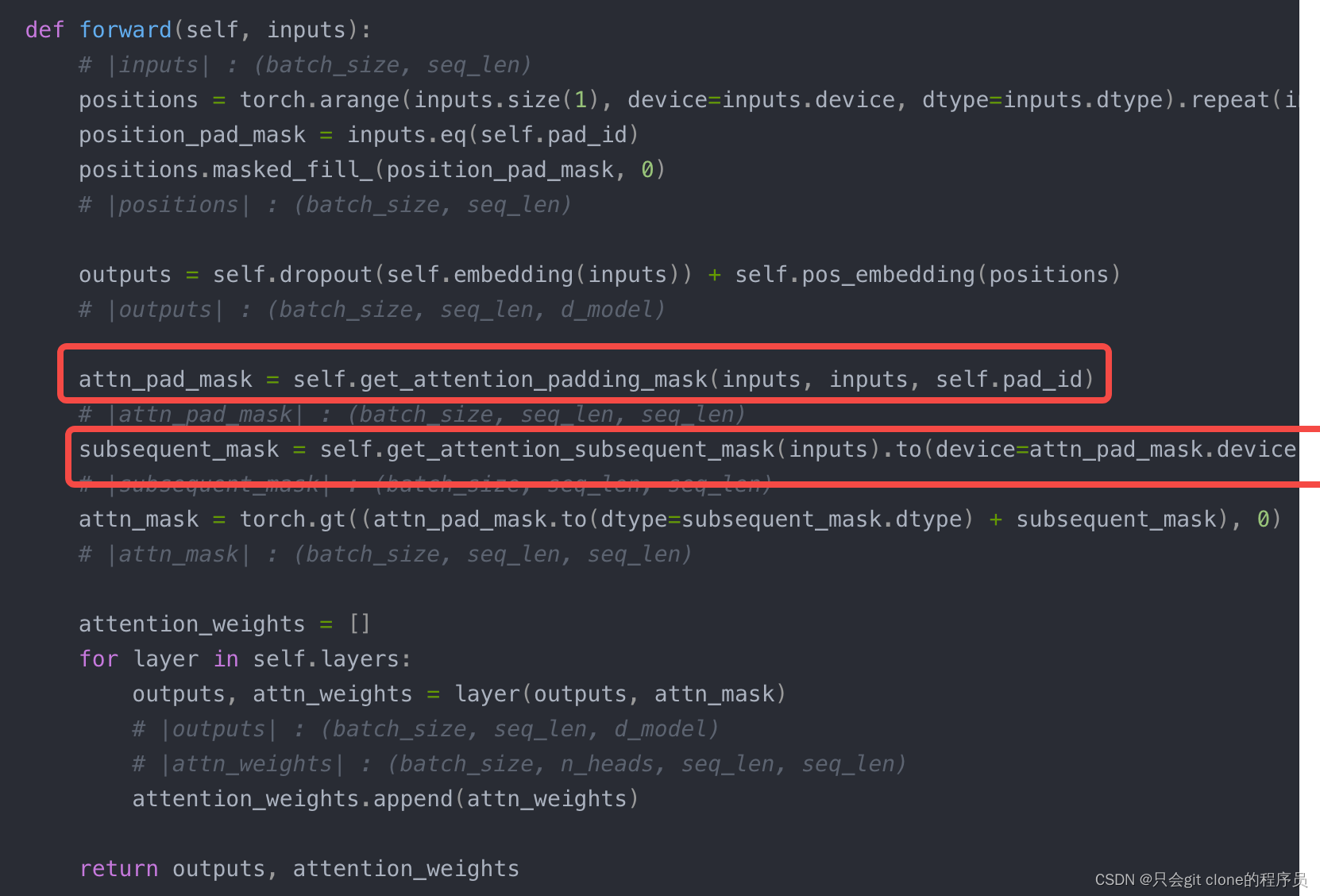
- 第一个mask很好理解,因为句子的长度不一样,比如【good morning】和【nice to meet you】,一个长度是2一个是4,这样两个句子没办法组成训练数据,所以一般会把短的padding一下成【good morning pad pad】这样就长度一样可以组成训练数据了,图上第一个pad mask就是用于【good morning pad pad】这个里面那些是pad的部分,然后不参与self attention的计算。
- 第二个mask就是之前我困惑的地方为啥叫decoder,decoder用的是带mask的MHA,这个mask就是图上的第二个框,他把某个单词后的单词都进行的mask。举个例子,还是【nice to meet you】,对于nice单词它的mask就是【0,1,1,1】,对于meet单词,它的mask就是【0,0,0,1】,这样从左往右相当于去了全1矩阵的上三角的1,所以这里的mask用pytorch的triu实现的:
subsequent_mask = torch.ones(bs, q_len, q_len).triu(diagonal=1)