Kafka学习笔记(一)Kafka基准测试、幂等性和事务、Java编程操作Kafka
文章目录
- 前言
- 4 Kafka基准测试
- 4.1 基于1个分区1个副本的基准测试
- 4.2 基于3个分区1个副本的基准测试
- 4.3 基于1个分区3个副本的基准测试
- 5 Java编程操作Kafka
- 5.1 引入依赖
- 5.2 向Kafka发送消息
- 5.3 从Kafka消费消息
- 5.4 异步使用带有回调函数的生产消息
- 6 幂等性
- 6.1 幂等性介绍
- 6.2 Kafka幂等性实现原理
- 7 Kafka事务
- 7.1 Kafka事务介绍
- 7.2 事务操作API
- 7.3 Kafka事务编程
- 7.3.1 需求
- 7.3.2 创建Topic
- 7.3.3 编写生产者
- 7.3.4 创建消费者
- 7.3.5 消费旧Topic数据并生产到新Topic
- 7.3.6 测试
- 7.3.7 模拟异常测试事务
前言
Kafka学习笔记(一)Linux环境基于Zookeeper搭建Kafka集群、Kafka的架构
4 Kafka基准测试
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。 我们可以通过基准测试,了解到软件、硬件的性能水平,主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
4.1 基于1个分区1个副本的基准测试
- 1)创建1个分区1个副本的Topic
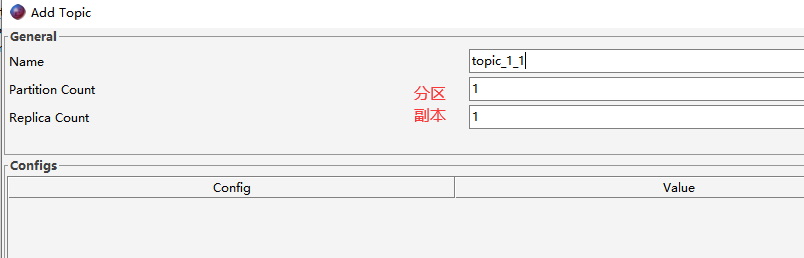
- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_1_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
命令解释:
- bin/kafka-producer-perf-test.sh 性能测试脚本
- –topic Topic的名称
- –num-records 指定生产数据量(默认5000W)
- –throughput 指定吞吐量,即限流(-1不指定)
- –record-size record数据大小(字节)
- –producer-props bootstrap.servers 指定Kafka集群地址
- acks=1 ACK模式
执行以上命令,结果如下:

- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_1_1 --fetch-size 1048576 --messages 5000000 --timeout 100000
命令解释:
- bin/kafka-consumer-perf-test.sh 消费消息基准测试脚本
- –broker-list 集群Broker列表
- –topic Topic的名称
- –fetch-size 每次拉取的数据大小
- –messages 总共要消费的消息个数
- –timeout 超时时间
执行以上命令,结果如下:

4.2 基于3个分区1个副本的基准测试
- 1)创建3个分区1个副本的Topic

- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_3_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
| 指标 | 3分区1副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| 吞吐量 | 10900.822140 records/sec | 8994.536718 records/sec | 提升↑ |
| 吞吐速率 | 10.40 MB/sec | 8.58 MB/sec | 提升↑ |
| 平均延迟时间 | 2508.37 ms avg latency | 3418.50 ms avg latency | 提升↑ |
| 最大延迟时间 | 47436.00 ms max latency | 50592.00 ms max latency |
- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_3_1 --fetch-size 1048576 --messages 5000000 --timeout 100000
| 指标 | 3分区1副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| data.consumed.in.MB 共计消费数据量 | 4768.4021 | 4768.3716 | |
| MB.sec 每秒消费数据量 | 28.5637 | 21.1589 | 提升↑ |
| data.consumed.in.nMsg 共计消费消息数量 | 5000032 | 5000000 | |
| nMsg.sec 每秒消费消息数量 | 29951.2517 | 22186.7235 | 提升↑ |
4.3 基于1个分区3个副本的基准测试
- 1)创建1个分区3个副本的Topic
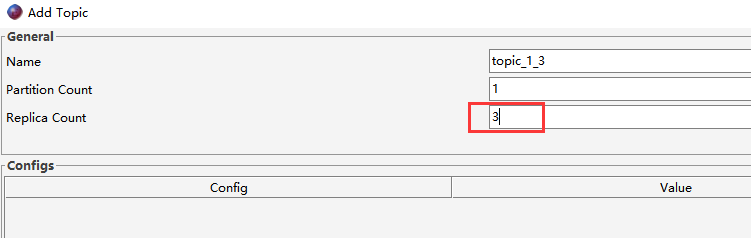
- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_1_3 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
| 指标 | 1分区3副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| 吞吐量 | 4323.273652 records/sec | 8994.536718 records/sec | 下降↓ |
| 吞吐速率 | 4.12 MB/sec | 8.58 MB/sec | 下降↓ |
| 平均延迟时间 | 7533.70 ms avg latency | 3418.50 ms avg latency | 下降↓ |
| 最大延迟时间 | 32871.00 ms max latency | 50592.00 ms max latency |
可见,副本越多,生产消息的性能反而下降。
- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_1_3 --fetch-size 1048576 --messages 5000000 --timeout 100000
| 指标 | 1分区3副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| data.consumed.in.MB 共计消费数据量 | 4768.3716 | 4768.3716 | |
| MB.sec 每秒消费数据量 | 46.9504 | 21.1589 | 下降↓ |
| data.consumed.in.nMsg 共计消费消息数量 | 5000000 | 5000000 | |
| nMsg.sec 每秒消费消息数量 | 49231.0116 | 22186.7235 | 下降↓ |
同样,副本越多,消费消息的性能也下降。
5 Java编程操作Kafka
创建一个Maven项目,测试Java变成操作Kafka。
5.1 引入依赖
<!-- kafka_demo\pom.xml -->
<!-- kafka客户端工具 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
5.2 向Kafka发送消息
public class KafkaProducerTest {
public static void main(String[] args) {
// 1.创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.245.130:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2.创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 3.调用send发送1-100消息到`my_topic`主题
for(int i = 0; i < 100; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("my_topic", null, i + ""));
// 调用一个Future.get()方法等待响应
future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 4. 关闭生产者
producer.close();
}
}
执行以上代码,查看此时my_topic主题中的消息:
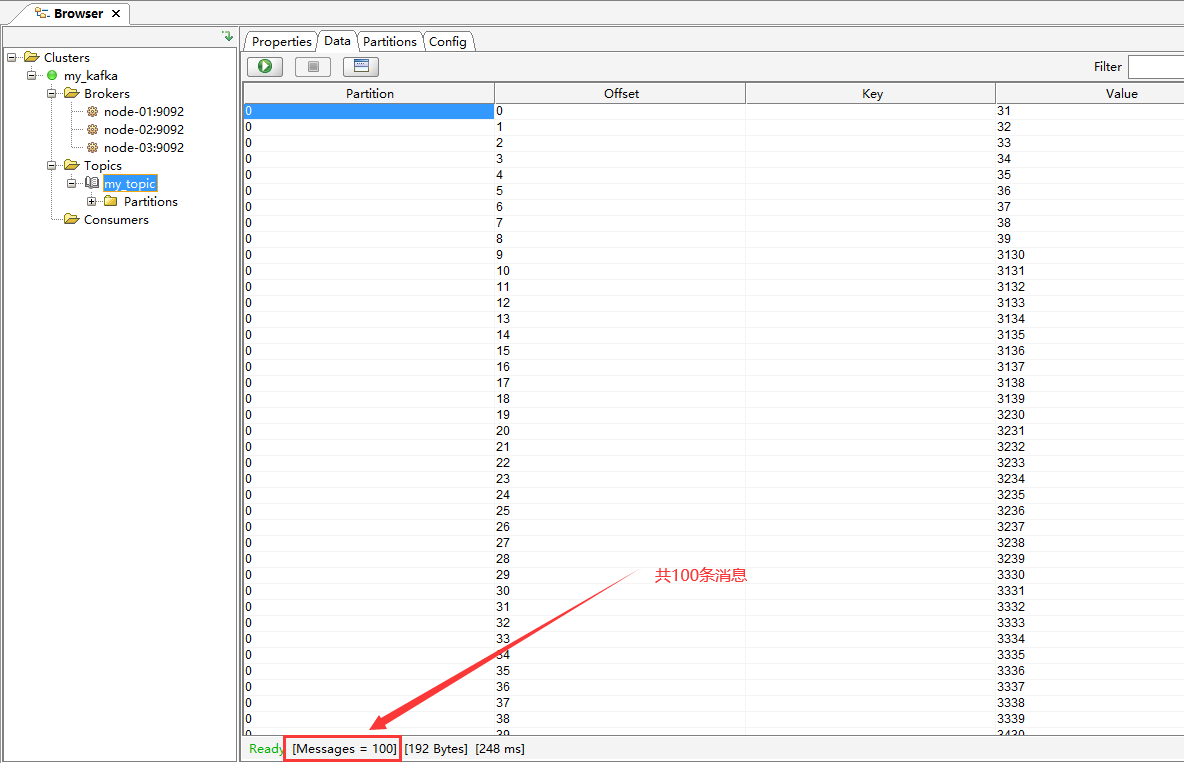
5.3 从Kafka消费消息
public class KafkaConsumerTest {
public static void main(String[] args) throws InterruptedException {
// 1.创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node-01:9092,node-02:9092,node-03:9092");
// 消费者组(可以使用消费者组将若干个消费者组织到一起),共同消费Kafka中topic的数据
// 每一个消费者需要指定一个消费者组,如果消费者的组名是一样的,表示这几个消费者是一个组中的
props.setProperty("group.id", "my_group");
// 自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 拉取的key、value数据的
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2.创建Kafka消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
// 3. 订阅要消费的主题
// 指定消费者从哪个topic中拉取数据
kafkaConsumer.subscribe(Arrays.asList("my_topic"));
// 4.使用一个while循环,不断从Kafka的topic中拉取消息
while(true) {
// Kafka的消费者一次拉取一批的数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));
System.out.println("消息总数:" + consumerRecords.count());
// 5.将将记录(record)的offset、key、value都打印出来
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
// 主题
String topic = consumerRecord.topic();
// offset:这条消息处于Kafka分区中的哪个位置
long offset = consumerRecord.offset();
// key\value
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);
}
Thread.sleep(1000);
}
}
}
执行以上代码,查看打印日志:
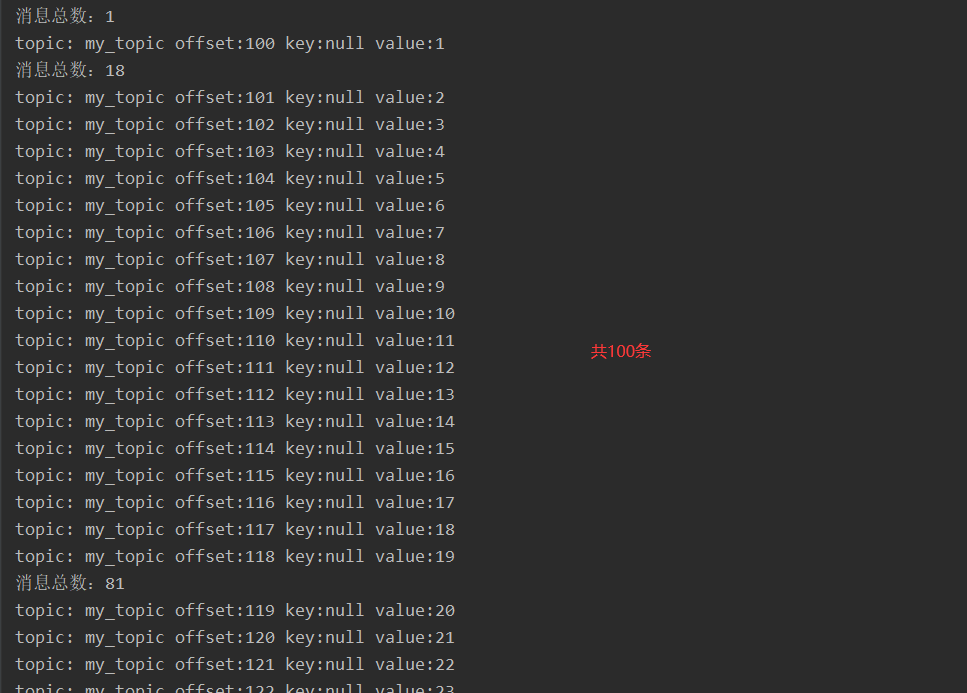
5.4 异步使用带有回调函数的生产消息
如果想知道消息是否成功发送到Kafka,或者成功发送消息到Kafka后执行一些其他动作,就可以使用带有回调函数的发送方法来发送消息。
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
props.put("bootstrap.servers", "node-01:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-100消息到指定Topic test
for(int i = 1; i <= 100; i++) {
// 一、同步方式
// 获取返回值Future,该对象封装了返回值
// Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("my_topic", null, i + ""));
// 调用一个Future.get()方法等待响应
// future.get();
// 二、带回调函数异步方式
producer.send(new ProducerRecord<String, String>("my_topic", null, i + ""), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null) {
System.out.println("发送消息出现异常!");
}
else {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
System.out.println("发送消息到Kafka中的名字为" + topic + "的主题,第" + partition + "分区,第" + offset + "条数据成功!");
}
}
});
}
// 4. 关闭生产者
producer.close();
}
执行以上代码,查看打印日志:

6 幂等性
6.1 幂等性介绍
在HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源,对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,任意多次请求执行,对资源本身所产生的影响均与一次请求执行的影响相同。
实现幂等性的关键就是服务端可以区分请求是否重复,过滤掉重复的请求。要区分请求是否重复有两个要素:
- 唯一标识:要想区分请求是否重复,请求中就得有唯一标识。例如支付请求中,订单号就是唯一标识。
- 记录下已处理过的请求标识:光有唯一标识还不够,还需要记录下哪些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复交易,拒绝掉。
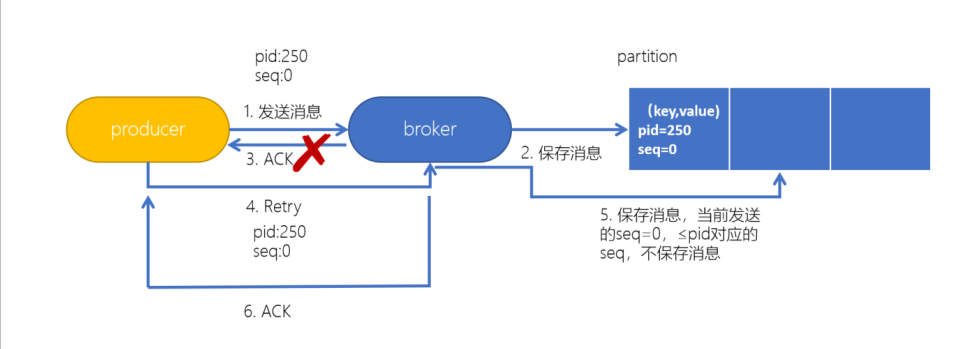
如上图所示,当再次发送的消息(seq=0)和上次发送的消息(seq=0)重复时,不保存新的消息。
6.2 Kafka幂等性实现原理
为了实现生产者的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID:每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler:针对每个生产者(对应PID)发送到指定的<Topic, Partition>的消息都对应一个从0开始单调递增的Sequence Number。
而生产者想要实现幂等性,只需要添加以下配置:
// 实现幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
7 Kafka事务
7.1 Kafka事务介绍
通过事务机制,Kafka可以实现对多个Topic的多个Partition的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个Topic 的哪个Partition,最终结果都是要么全部写成功,要么全部写失败。
开启事务,必须开启幂等性,Kafka的事务机制,在底层依赖于幂等生产者。
7.2 事务操作API
要开启Kafka事务,生产者需要添加以下配置:
// 配置事务的id,开启了事务会默认开启幂等性
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional");
消费者则需要添加以下配置:
// 设置隔离级别
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
// 关闭自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
Producer接口中定义了以下5个事务相关方法:
- 1.
initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作 - 2.
beginTransaction(开始事务):启动一个Kafka事务 - 3.
sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交 - 4.
commitTransaction(提交事务):提交事务 - 5.
abortTransaction(放弃事务):取消事务
7.3 Kafka事务编程
7.3.1 需求
在Kafka的Topic[ods_user]中有一些用户数据,数据格式如下:
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
现在要编写程序,将用户的性别转换为男、女(1-男,0-女),转换后将数据写入到Topic[dwd_user]中。要求使用事务保障,要么消费了数据的同时写入数据到新Topic,提交offset;要么全部失败。
7.3.2 创建Topic
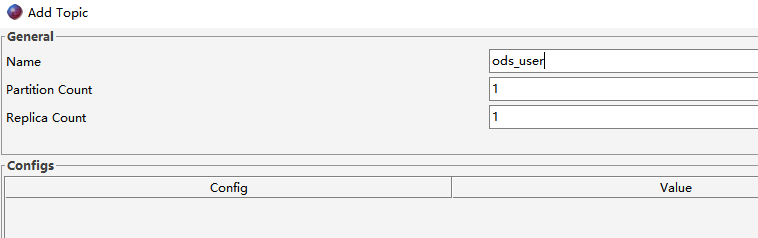
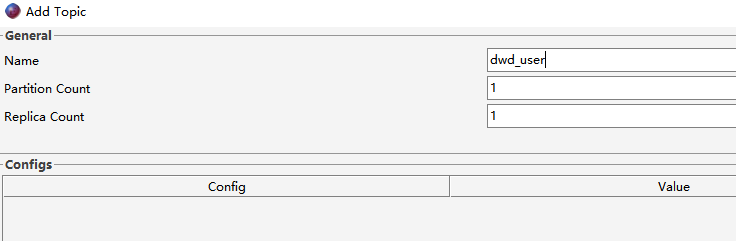
启动生产者控制台程序,准备发送消息到Topic[ods_user]:
[root@node-01 kafka01]$ bin/kafka-console-producer.sh --broker-list 192.168.245.130:9092 --topic ods_user
>
启动消费者控制台程序,准备从新Topic[dwd_user]消费消息:
[root@node-01 kafka01]$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.245.130:9092 --topic dwd_user --from-beginning --isolation-level read_committed
7.3.3 编写生产者
private static KafkaProducer<String, String> createProducer() {
// 1.创建用于连接Kafka的Properties配置
Properties props = new Properties();
// 配置事务的id,开启了事务会默认开启幂等性
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional");
props.put("bootstrap.servers", "192.168.245.130:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2.创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
return producer;
}
7.3.4 创建消费者
private static KafkaConsumer<String, String> createConsumer() {
// 1.创建Kafka消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092");
props.setProperty("group.id", "my_group");
// 关闭自动提交offset
props.setProperty("enable.auto.commit", "false");
// 事务隔离级别
props.put("isolation.level", "read_committed");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2.创建Kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 3.订阅要消费的主题
consumer.subscribe(Arrays.asList("ods_user"));
return consumer;
}
7.3.5 消费旧Topic数据并生产到新Topic
public static void main(String[] args) {
KafkaProducer<String, String> producer = createProducer();
KafkaConsumer<String, String> consumer = createConsumer();
// 1.初始化事务
producer.initTransactions();
while (true) {
try {
// 2.开启事务
producer.beginTransaction();
// 定义Map结构,用于保存分区对应的offset
Map<TopicPartition, OffsetAndMetadata> offsetCommits = new HashMap<>();
// 3.拉取ods_user的消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : records) {
System.out.println("原始消息:" + record.value());
// 4.保存偏移量
offsetCommits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1));
// 5.进行转换处理
String[] fields = record.value().split(",");
fields[1] = fields[1].equalsIgnoreCase("1") ? "男" : "女";
String newMsg = fields[0] + "," + fields[1] + "," + fields[2];
// 6.将新消息生产到dwd_user
producer.send(new ProducerRecord<>("dwd_user", newMsg));
System.out.println("新消息:" + newMsg);
}
// 7.提交偏移量到事务
producer.sendOffsetsToTransaction(offsetCommits, "my_group");
// 8.提交事务
producer.commitTransaction();
} catch (ProducerFencedException e) {
// 9.放弃事务
producer.abortTransaction();
}
}
}
7.3.6 测试
执行上述main()方法,然后向Topic[ods_user]发送消息:

main()方法日志打印:
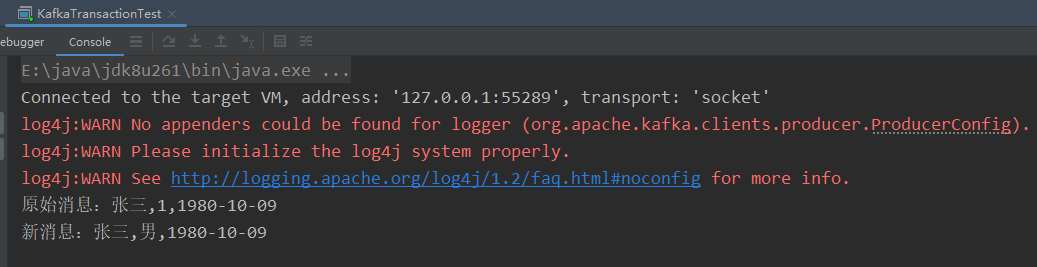
从新Topic[dwd_user]消费消息:

7.3.7 模拟异常测试事务
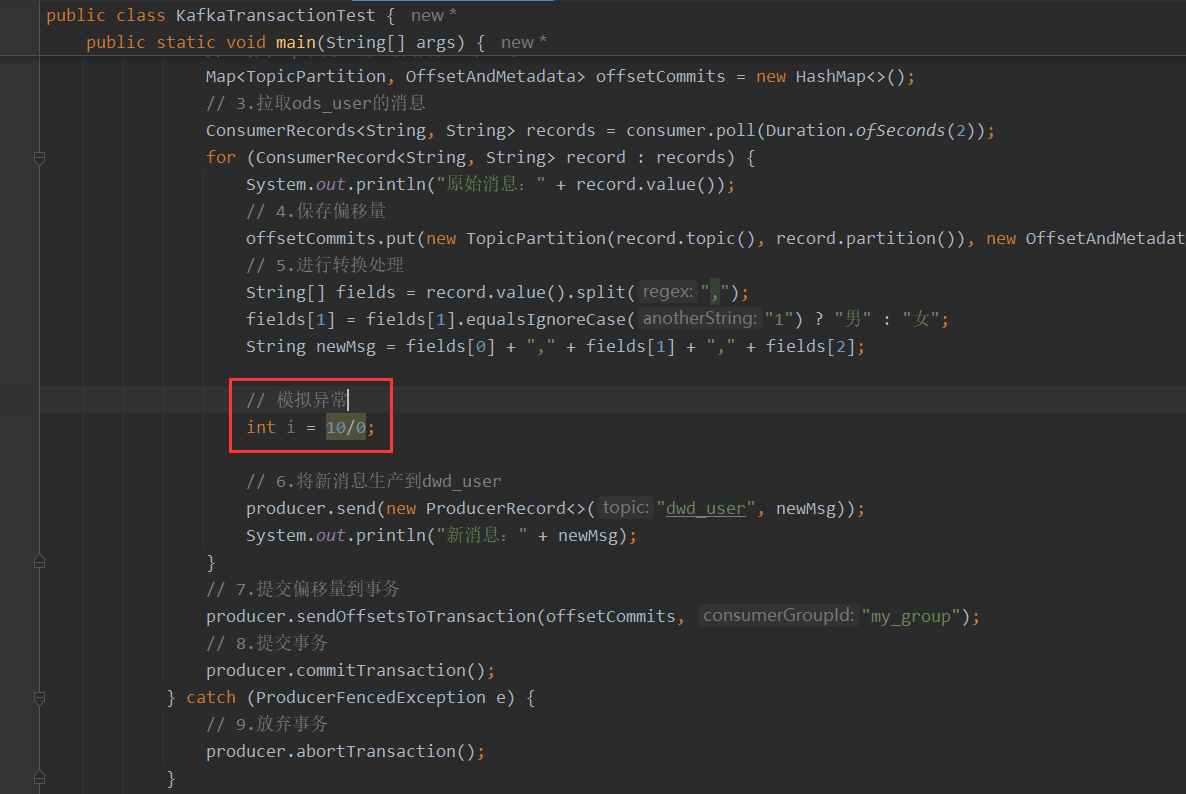
假设在进行转换处理的时候出现异常。再次向Topic[ods_user]发送消息,程序会读取到消息,但转换报错:
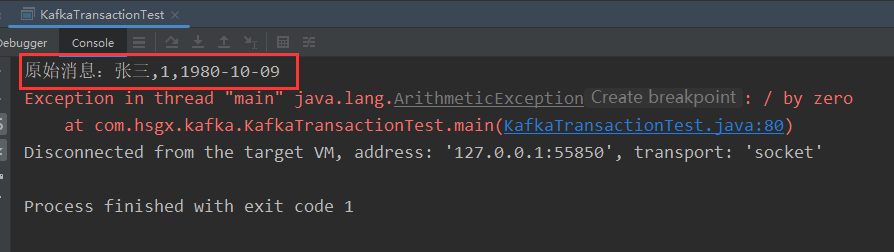
再次重启main()方法,还是可以读取到消息,但转换报错。说明消息一直都没有被消费成功,offset没有被提交,Kafka事务生效了。
…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记