【JVM】垃圾释放方式:标记-清除、复制算法、标记-整理、分代回收
文章目录
- 1. 标记-清除
- 2. 复制算法
- 4. 标记-整理
- 4. 分代回收
把标记为垃圾的对象的内存空间进行释放。主要有三种释放方式
1. 标记-清除
把标记为垃圾的对象,直接释放掉(最朴素的做法)

此时就是把标记为垃圾的对象所对应的内存空间直接释放。但这样的释放会产生“内存碎片”问题
- 上述释放方式,就可能会产生很多小的,但是离散的空闲内存空间
- 这样就可能会导致后续申请内存失败
- 因为内存申请都是一次申请一个连续的空间
- 申请
1M内存空间,此时1M都是连续的
- 如果存在很多内存碎片,就可能导致总的空闲空间远远超过
1MB,但是并不存在比1M大的连续空间。此时,去申请内存就会失败
类似于,你去吗房子,需要一次性付
30W首付。你的总存款超过了30W,但是可能分散在不同的卡上,所以就没法完成上述的支付操作
一般不会使用这个方案,内存碎片问题,比较致命
2. 复制算法
复制算法的核心就是:不直接释放内存,而是把不是垃圾的对象,复制到内存的另一半里面。
- 然后就把左侧空间整体释放掉
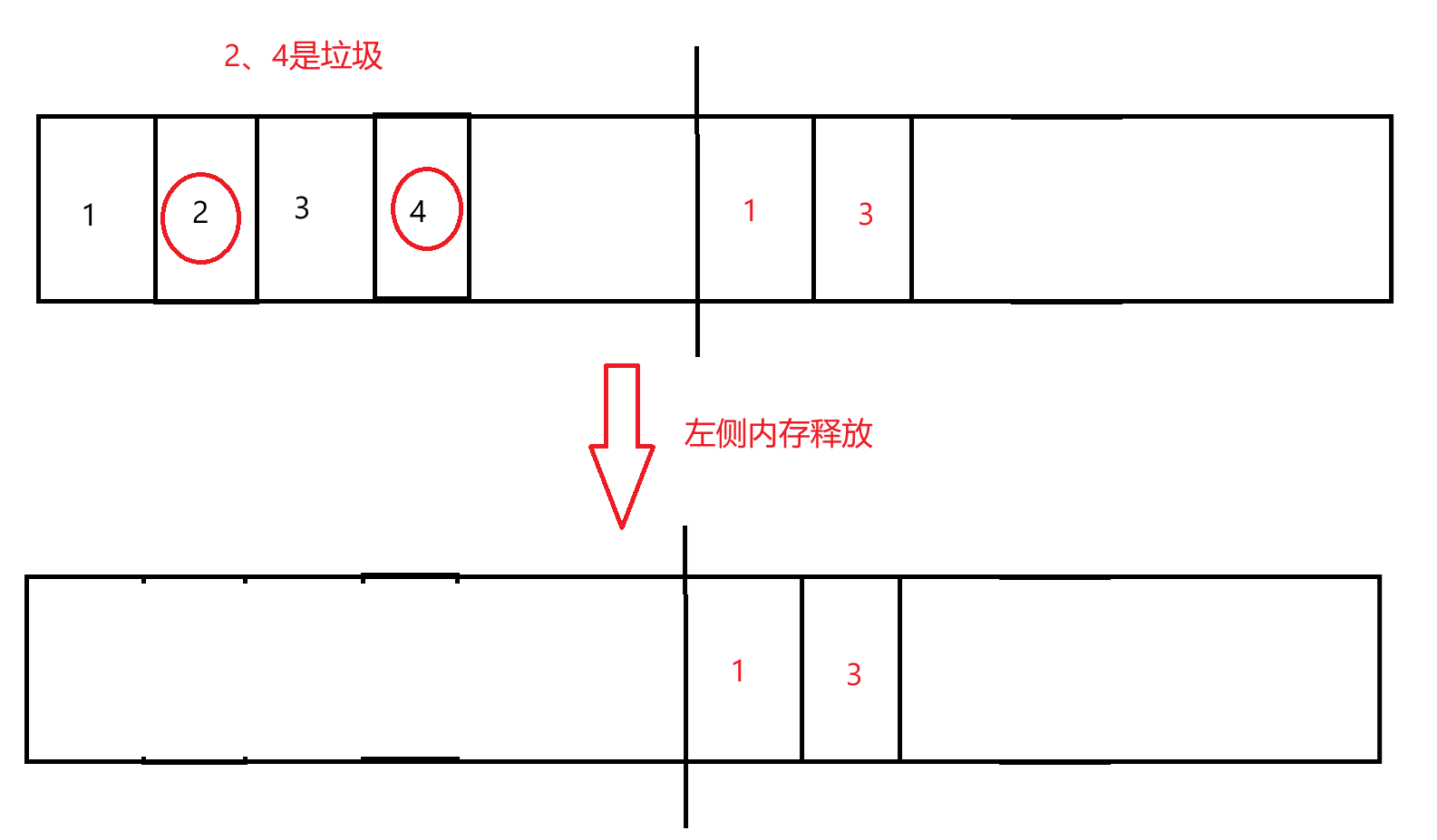
确实能规避内存碎片问题,但是也有缺点:
-
总的可用内存变少了(买两碗豆浆,喝一碗倒一碗)
-
如果每次要复制的对象比较多,此时复制的开销也就很大了。
需要是当这一轮 GC 的过程中,大部分对象都释放,少数对象存活,这个时候适合用复制
4. 标记-整理
类似于顺序表删除中间元素,中间有个“搬运”的过程
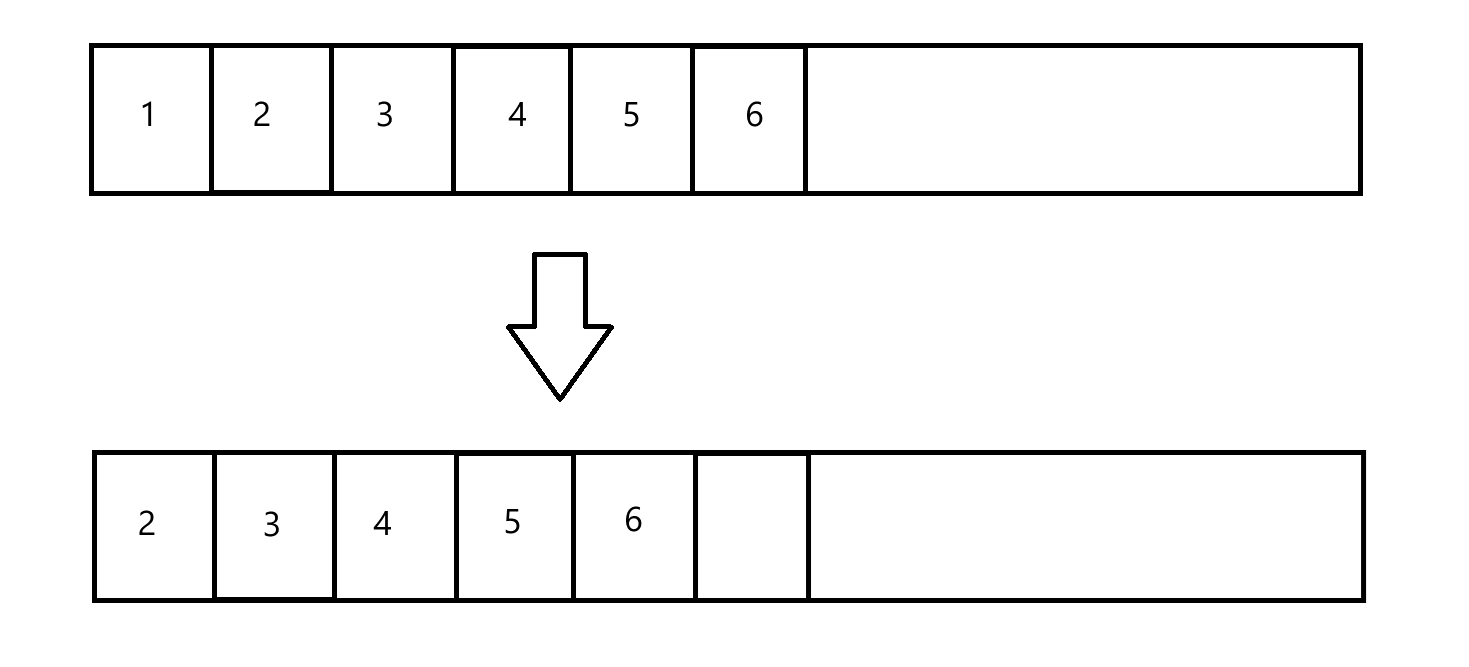
- 若要删除 1,就把 2 往前搬,覆盖掉 1,3 覆盖掉 2… 最后把后面的内存释放
通过这个过程,也可以解决内存碎片问题,并且这个过程也不像复制算法一样,需要浪费过多的内存空间。但是,这里的搬运内存的开销很大
因此,JVM 没有直接使用上述的方案,而是结合上述思想,高出了一个“综合性”方案,取长补短
4. 分代回收
依据不同种类的对象,采取不同的方式
引入概念:对象的年龄
- JVM 中,有专门的线程负责周期性扫描/释放
- 一个对象如果被线程扫描了一次,可达了(不是垃圾),年龄就+1(初始年龄相当于是 0)
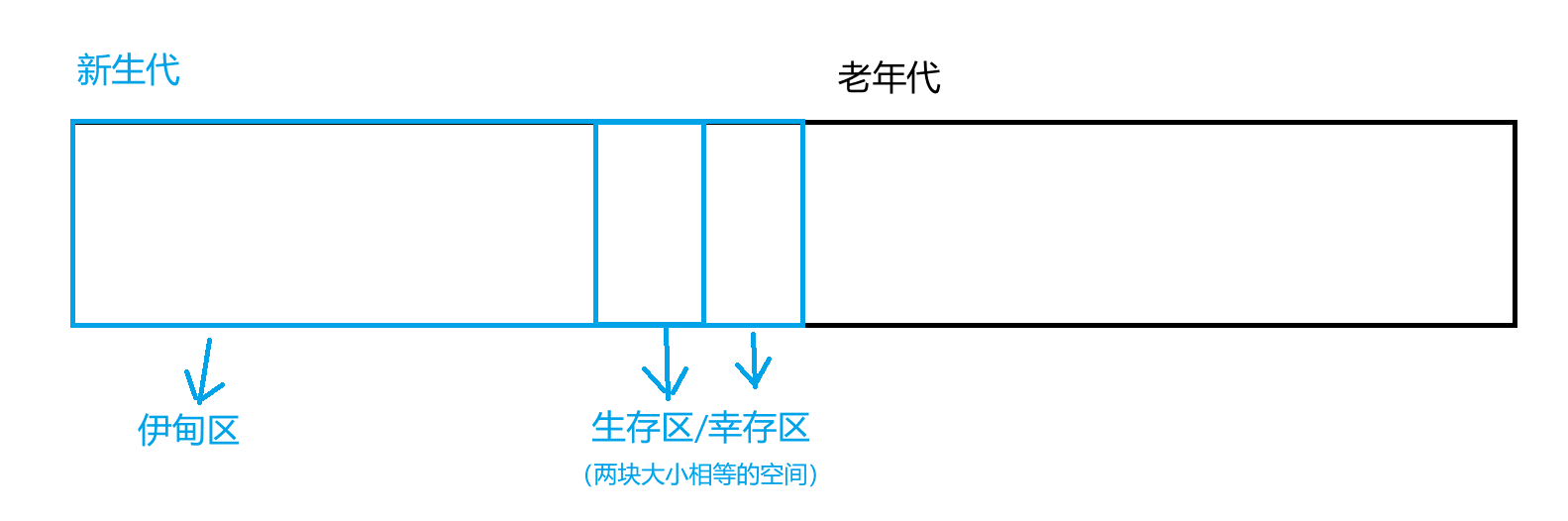
JVM 中就会跟对象年龄的差异,把整个堆内存分为两个大的部分:新生代(年龄小的对象)/老年代(年龄大的对象)
年龄也是会占内存的,每个对象有一个“对象头”,在对象头里有一个属性来存储年龄
-
当我们代码中
new出一个新的对象,这个对象就是被创建在伊甸区,在伊甸区会有很多对象- 一个经验规律:伊甸区中的对象,大部分是活不过第一轮 GC 的(朝生夕死,生命周期非常短)
-
第一轮 GC 扫描完成之后,少数在伊甸区中幸存的对象,就会通过复制算法,复制到生存区
- 后续的 GC 扫描线程还会持续的扫描,不仅要扫描伊甸区,还要扫描生存区的对象
- 生存区中的大部分对象也会在扫描中被标记为垃圾
- 少数存活的,就会继续使用复制算法,复制到另一个生存区中
- 只要这个对象能够在生存区中继续存活,就会被复制算法继续拷贝到另一半的生存区中
- 每经历一轮 GC,对象的年龄就会
+1
每一次拷贝不仅仅只有生存区的对象进行互相拷贝,还有来自伊甸区的对象
-
如果这个对象在生存区中, 经过了若干轮 GC 仍然健在,JVM 就会认为,这个对象生命周期大概很长,就会把这个对象从生存区拷贝到老年代
-
老年代的对象,当然也要被 GC 扫描,但是扫描频次就会大大降低了
老年代的对象,要寄早寄了。既然没有寄,说明其生命周期应该是很长的,频繁 GC 扫描意义也不大,白白浪费时间。不入放到老年代,降低扫描频率
- 对象在老年代寿终正寝,此时 JVM 就会按照标记整理的方式,释放内存
上述过程,也是非常好理解的。这个过程和我们找工作是一模一样的
- 伊甸区:一个公司收到很多的简历,然后安排笔试。笔试的过程就会使绝大部分的人被刷掉,少数的人能进入到面试环节
- 生存区:进入面试环节,面试有很多轮,每一轮也会刷掉一批人
- 老年代:通过了上述层层筛选,拿到 offer,进入公司入职了。
- 进入公司后也会有绩效考评、末位淘汰,但周期比较长,远远超过笔试和面试
上述分代回收是 JVM GC 中的核心思想。但是 JVM 实际的垃圾回收的实现细节上,还会存在一些变数和优化
垃圾收集器就是具体实际的情况
课件列出了 7 个垃圾收集器,主要掌握 CMS,G1(ZGC)