优化Kafka存储:热冷数据分层策略

最初,在存储系统领域,数据分层是一种降低数据存储成本的策略。其具体做法是将不常访问的数据整合到更为经济(但性能可能稍弱)的存储阵列中。例如,闲置一年或更久的数据可以从昂贵的闪存层转移至相对经济的 SATA 磁盘层。尽管固态硬盘(SSD)和闪存成本较高,但仍可归类为高性能存储类别。一般来说,那些被频繁使用且对性能要求极高的小数据集通常存储在闪存中。
随着客户不断寻求将数据分层或归档至公共云的替代方案,云数据分层逐渐受到欢迎。目前,公共云提供了对象存储和文件存储的混合选项。像 Amazon S3 和 Azure Blob(Azure Storage)这样的对象存储类别,既具备显著的成本效益,又拥有对象存储的诸多优点,同时还无需复杂的设置和管理。
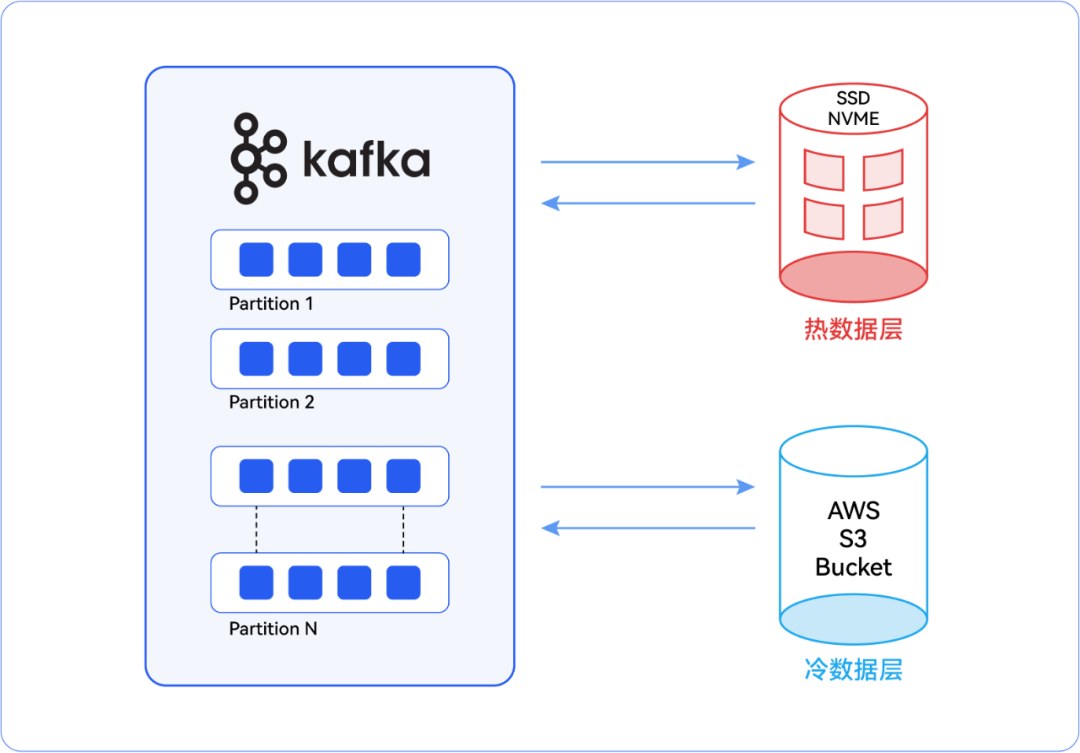
从多节点 Kafka 集群的角度来看,“热” 数据和 “冷” 数据有着不同的定义。那些被摄入 Kafka 主题,并在经过各种数据管道后到达下游应用程序以供快速检索的数据,可称之为 “热” 数据。比如炼油厂各类关键设备的物联网传感器事件就属于热数据。而那些同样被摄入 Kafka 主题,但下游应用程序较少访问的数据则可称为 “冷” 数据。例如电子商务应用程序中通过从第三方仓库系统摄入产品数量等方式实现的库存更新数据就属于冷数据。冷数据可以从集群中移出,转移至成本效益更高的存储解决方案中。
根据下游应用程序的需求对摄入 Kafka 主题的数据进行分类后,我们可以在 Kafka 集群中将数据层指定为热数据的热层和冷数据的冷层。对于热数据层,由于需要快速检索数据,所以可以利用高性能存储选项,如 NVMe(非易失性内存表达)或 SSD(固态硬盘)。同样,可扩展的云存储服务(如 Amazon S3)则适用于冷层。被认定为冷数据的历史数据和较少被访问的数据非常适合存储在冷层中。当然,摄入 Kafka 主题的数据量以及保留期也是选择云存储的重要决定因素。
Kafka 主题的基本执行过程
▏热数据层
正如前面所提到的,热数据层可以使用 SSD 或 NVMe,冷数据层则使用可扩展的云存储。这一配置可以在 Kafka 的 server.properties 文件中完成。在这个文件中,提到了主题的默认设置,并且提供了按主题进行覆盖的选项。如果没有为特定主题提供具体的值,那么就会使用 server.properties 文件中所提到的参数。不过,利用这个选项,我们能够在 server.properties 文件中覆盖已创建主题的配置。--config
在这种情形下,我们期望创建的主题能够将热层数据存储在一个目录中,而这个目录的位置应当处于能够提供高速访问的存储设备上(比如 SSD 或 NVMe 设备)。
第一步,我们应该在 server.properties 文件中禁用自动创建主题。默认情况下,如果主题不存在,Kafka会自动创建它们。但是,在分层存储场景中,禁用自动创建主题可能更可取,以便对主题配置进行更大的控制。我们需要在 server.properties 文件中添加以下键值对:
-
#Disable 自动创建主题
auto.create.topics.enable=false第二步,更新属性,指向提供高速访问的存储设备的位置:log.dirs
log.dirs=/path/to/SSD or / NVMe devices for hot tier最后,使用 server.properties 文件中的选项指向为热数据层创建的主题:--config
topic.config.my_topic_for_hot_tier= log.dirs=/path/to/SSD or NVMe devices for hot tier根据我们独特的使用案例和需求,我们可能还需要调整 server.properties 文件中的其他键值对,例如 :
log.retention.hours(日志保留小时数)
default.replication.factor(默认复制因子)
log.segment.bytes(日志段字节数)
▏冷数据层
对于冷数据层而言,如前文所述,可以采用可扩展的云存储服务,例如 Amazon S3。在 Kafka 中配置冷数据层存在两种选择。其一,使用 Confluent 内置的 Amazon S3 Sink 连接器;其二,在 Kafka 的 server.properties 文件中配置 Amazon S3 存储桶。
Amazon S3 Sink 连接器能够将数据从 Apache Kafka® 主题导出至 S3 对象,支持 Avro、JSON 或者 Bytes 格式。它会定期从 Kafka 中轮询数据,并将其上传至 S3。在从指定主题消费记录并将这些记录组织到不同分区后,Amazon S3 Sink 连接器会把每个分区的记录批次发送到一个文件中,随后该文件会被上传到 S3 存储桶。我们可以使用 confluent connect plugin install 命令来安装这个连接器,或者手动下载 ZIP 文件,并且必须在集群中运行 Connect 的每台机器上安装该连接器。
除此之外,我们还可以在Kafka的 server.properties 文件中进行配置,并按照以下步骤为冷数据层创建一个主题,该主题利用S3存储桶:
-
更新属性,指向S3存储位置。我们需要确保为Kafka设置了所有必要的AWS凭据和权限,以便写入指定的S3存储桶。log.dirs
log.dirs=/path/to/S3 bucket -
我们可以使用内置脚本来创建一个将使用冷层(S3)的主题。在这里,我们需要为该特定主题设置配置,以指向S3路径。
Kafka-topics.shlog.dirs
bin/kafka-topics.sh --create --topic our_s3_cold_topic --partitions 5 --replication-factor 3 --config log.dirs=s3://our-s3-bucket/path/to/cold/tier --bootstrap-server <<IP address of broker>>:9092-
根据我们的需求和S3存储的特性,我们可以调整Kafka中特定于冷数据层的配置,例如修改 server.properties 中的 log.retention.hours 值。
说在最后
最后,在 Apache Kafka 集群中对热数据和冷数据进行分层,无疑是一项极具智慧的策略。这种分层方式能够依据数据的独特特性,精准地优化存储资源,实现存储资源的高效配置。
如今,随着越来越多的企业积极投身于实时数据流的应用,以期推动业务的蓬勃发展。在这个过程中,存储的可扩展性与成本效益已成为决定企业成败的关键因素。只有那些能够敏锐地洞察到这一趋势,并果断采取行动的企业,才能在激烈的市场竞争中立于不败之地。
通过明智地实施高性能且成本效益高的存储层,企业不仅能够在存储性能方面达到最佳状态,更能在成本管理上做到游刃有余。这意味着企业可以在不牺牲性能的前提下,有效地控制成本,为企业的可持续发展奠定坚实的基础。同时,这种优化存储资源的方式也为企业在数据驱动的时代中赢得了更多的竞争优势,使企业能够更加从容地应对各种挑战,开启更加辉煌的未来篇章。
- end -