爬虫请求响应以及提取数据
爬虫请求响应以及提取数据
回顾:
网页给客户端响应数据, 有哪些写法(在爬虫入门之爬虫原理以及请求响应这篇博客咯嘛有提到)?
1.响应对象.text(获取网页数据的时候会用到)
2.响应对象.content(将图片, 音频或视频等数据存放到文件的时候会用到)
那这一篇文章, 介绍一个新的写法:
响应对象.json(), 这个方法在获取网页数据所对应的请求数据时会用到
什么情况下会使用
当再浏览器对应的响应中看到的数据结构有点像python中的字典或者列表(因为浏览器中不叫字典或者列
表,只是说数据格式类似)
我们通过代码的案例, 来讲解响应对象.json()的写法。
代码:
import requests
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?
timestamp=1726832959000&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&
attrId=1&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'
res = requests.get(url)
# print(type(res.text)) # 如果使用响应对象.text 那么得到的数据永远都是字符串类型
# print(type(res.json()))# 如果使用响应对象.text 那么得到的数据都是字典类型
data = res.json() # 使用data变量存储字典数据 字典更方便取值
# 结合循环编写解析的代码
count = 1 # 输出的序号
for i in data['Data']['Posts']:
# 岗位名称
RecruitPostName = i['RecruitPostName']
# 所在城市
LocationName = i['LocationName']
# 岗位内容
Responsibility = i['Responsibility']
print(count,RecruitPostName,LocationName,Responsibility)
count += 1
这个url怎么来的, 首先打开腾讯招聘

接着点击技术类那个框, 跳转到如下页面:
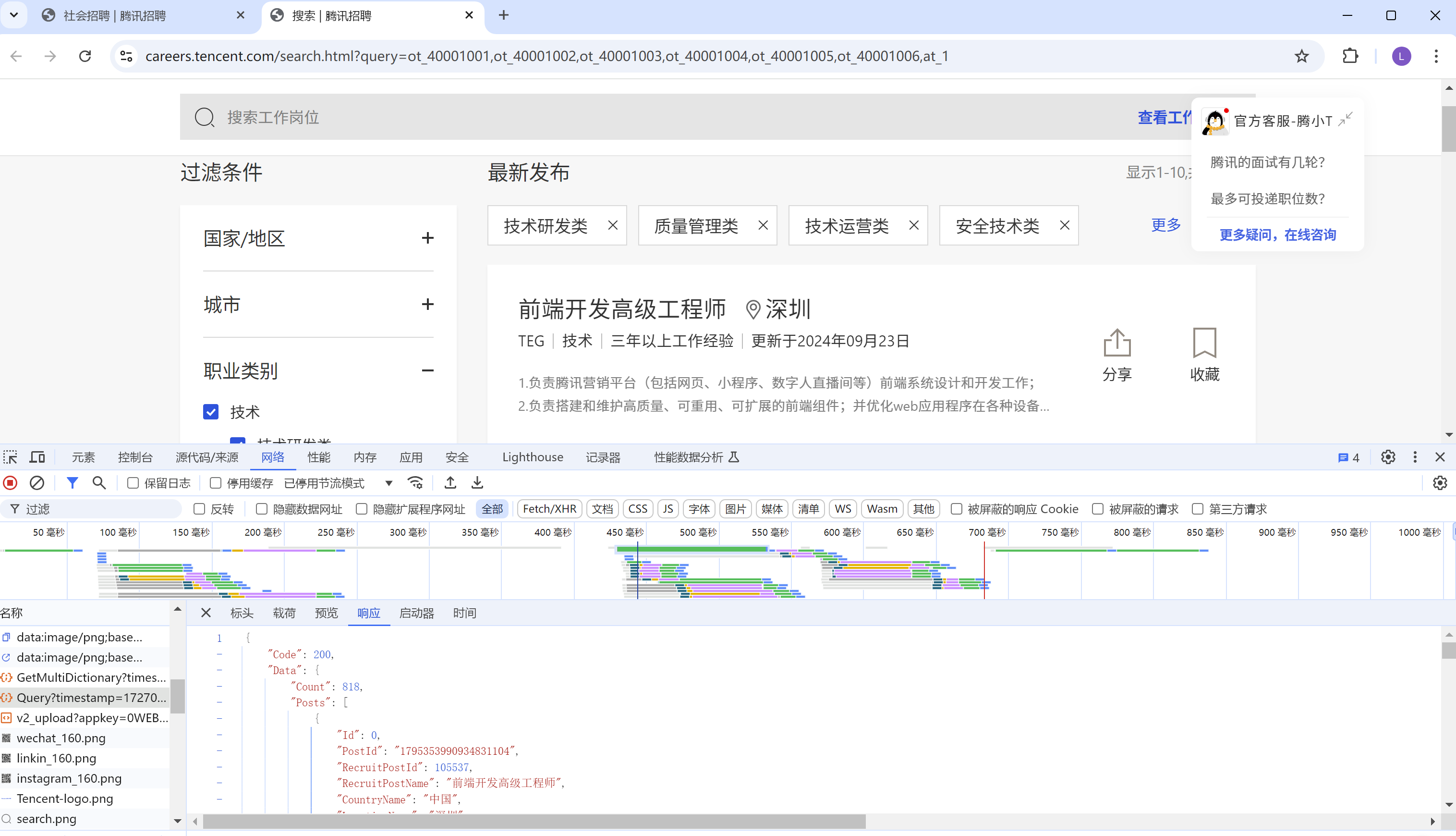
然后再请求中找到Query……, 这个就是我们需要爬取的数据请求。
每个网站, 需要爬取的数据请求都不一样, 这个需要自己找。
我们双击那个请求, 可以发现, 后台返回了数据。
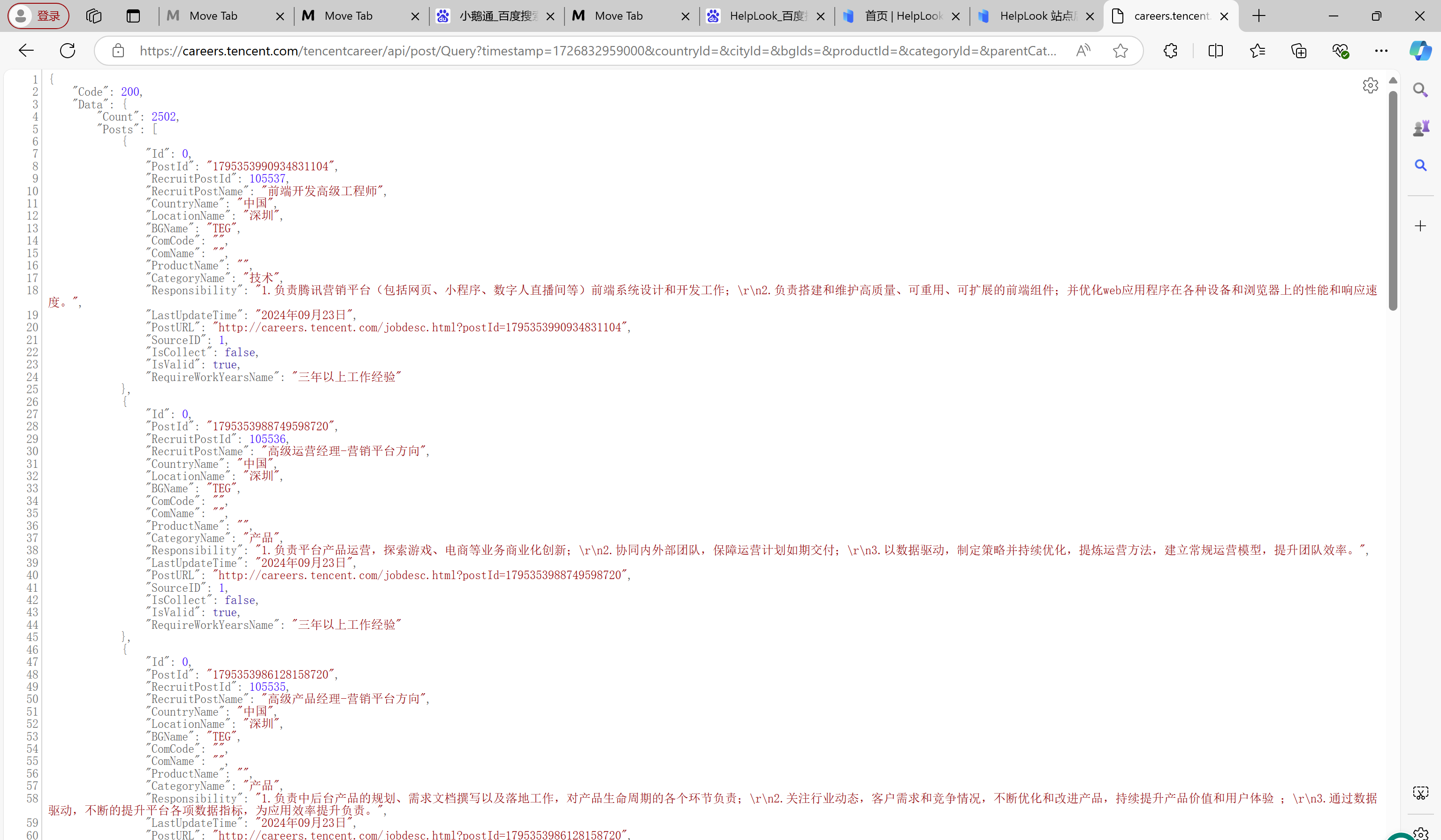
所以url就是https://careers.tencent.com/tencentcareer/api/post/Query?
timestamp=1726832959000&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&
attrId=1&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn, 也就是请求。
说明:
data = res.json()这句话, 使用data变量存储字典数据, 因为字典更方便取值
我们可以发现请求里面, 有个Posts的列表(数组), 所以我们先要获取到那个列表再循环, 使用for i in data[‘Data’][‘Posts’]这句话进行循环, 因为Posts列表再Data里面, 所以要data[‘Data’][‘Posts’]这样写。然后在循环里面, 有三行代码, 获取岗位名称, RecruitPostName = i[‘RecruitPostName’], 获取所在城市, LocationName = i[‘LocationName’], 获取岗位内容, Responsibility = i[‘Responsibility’]。因为岗位名称、所在城市、岗位内容这三个东西都在Posts列表里面, 而i就是每一次遍历出来的列表里面的一条数据, 所以可以用i[‘字段名’]这么写。
伪装
url = 'https://movie.douban.com/j/chart/top_list?
type=10&interval_id=100%3A90&action=&start=0&limit=20'
# 响应的数据格式:[{},{}] 列表嵌套字典
res = requests.get(url)
data = res.json()
print(data) # 报错
# 得到的响应数据不是一个纯列表或者纯字典的时候 就会报如下错误
# requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
# 改响应对象.text输出
print(res.text) # 当前获取到的数据是空字符串 为什么浏览器可以正常得到数据,而爬虫得不到
结果:

为什么会报错?
原因: 对方识别了当前的客户端是爬虫, 所以不给数据
如何解决: 我们需要用到伪装
如何实现伪装: 在请求头当中带上请求头(从浏览器复制过来)
修改过后的代码:
# 使用字典保存请求头信息
url = 'https://movie.douban.com/j/chart/top_list?
type=10&interval_id=100%3A90&action=&start=0&limit=20'
# 响应的数据格式:[{},{}] 列表嵌套字典
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/128.0.0.0 Safari/537.36'
}
# 携带请求头的方式:headers参数传参
res = requests.get(url,headers=headers)
data = res.json()
print(data)
print(text)
此时此刻, 我们就能够获取到数据啦!
我们看一个完整的一个案例, 爬取豆瓣电影的数据:
import requests
url = 'https://movie.douban.com/j/chart/top_list?type=10&interval_id=100%3A90&action=&start=0&limit=20'
# user-agent对应的是客户端的版本信息Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# print(response.text)
# print(type(response.json()))
data = response.json()
count = 1
for i in data:
# i = 第一次循环取出的是 列表种的第一个字典 对应的是一个电影信息
# 电影名
title = i['title']
# 演员表
actors = i['actors']