前沿论文 M5Product 组会 PPT

对比学习(Contrast learning):对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。假设一个试图理解世界的新生婴儿。在家里,假设有两只猫和一只狗。即使没有人告诉你它们是“猫”和“狗”,这个婴儿仍可能会意识到,与狗相比,这两只猫看起来很相似。

作者从理论论文和实践论文的角度都表明,具有不同模态的大规模数据集可以有效地增强对生成特征的区分,从而提高视觉语言任务的性能。然而,目前的进展受到缺乏这种大规模多样化模态数据集的严重限制,最大的公共多模态数据集只包含文本、图像模态和无类别信息[41]。作者采集了结构化和音视频数据来进行训练。

大多数多模态预训练数据集是从社交网站收集的(例如,Twitter和Facebook),并且仅限于为指定任务收集的两种模式。这些数据集可以根据其模态组成分为四类,即,音频/文本、视频/文本、图像/文本等。CMU-MOSEI主要关注情感分析,XMedia用于跨模态检索。除了上述数据集,还有几个电子商务数据集。Dress Retrieval [9],RPC checkout [48]和Product1M [55]是典型的电子商务多模态数据集。可以看出他们的模态只有图片和文本。

近年来,针对视觉-文本多模态学习,研究者们提出了多种视觉语言预训练模型。它们可以粗略地分为两类:1)单流模型,其Transformer层共同对视觉和文本输入进行concat操作,例如VL-bert [42],Image-BERT [37],VideoBERT [44],MMT [12],HERO [26],VisualBERT [27]和UNITER [7]。2)图像和文本输入不连接的双流模型,例如ViLBERT [30],LXMERT [45],CLIP [38]和DALL-E [39]。

读ppt

之前的研究引发了两个关键挑战:
(1)模态交互:如何通过扩展到大量模态的优雅方法,实现从不同模态之间的单峰,双峰,三峰甚至多模态关系中学习共同表示。
(2)模态噪声:如何在训练过程中减少模态噪声(不完整的模态)的影响。后面作者使用零插补进行去除,发现对模型效果有所提高。


读PPT

作为一个真实世界的数据集,与传统的多模态数据集不同,它并不是一个完整的配对数据集。具体来说,这个数据集包含的样本只包含部分模态(即不同类型的数据),而且数据的分布是长尾分布。这意味着大部分样本可能集中在少数几种模态上,而其他模态的样本则相对较少。

方法框架中最下面是SCALE首先对五个模态数据进行处理,然后得到特征,同样每个模态有一个CLS特征来对其他特征进行综合。然后进行对比学习。在由单独的模态编码器处理之后,不同模态的令牌特征被连接并馈送到联合共Transformer(Joint Co-Transformer,JCT)模块中以捕获不同模态之间的令牌关系。

针对每种模态进行了代理任务,利用了之前的掩码区域预测任务(MRP)、掩码语言建模任务(MLM)。为了利用表,视频和音频模态的特性,作者进一步提出了掩码实体建模任务(MEM),掩码帧预测任务(MFP),掩码音频建模任务(MAM)。比如在MLM任务中,模型需要预测输入句子中被随机掩盖(mask)的单词。具体来说,在给定的句子中,某些单词会被特殊的[MASK]标记替换,模型的目标是预测这些被掩盖的单词。

定义了一个针对每个模态的损失函数,其中,
t
¬
m
s
k
t_{\neg m s k}
t¬msk表示围绕屏蔽令牌
t
m
s
k
t_{msk}
tmsk的未屏蔽令牌,
θ
θ
θ表示网络参数,并且
M
i
M_i
Mi和
M
¬
i
{M}_{\neg i}
M¬i分别是第
i
i
i模态和剩余模态。比如预测一个文本模态的单词,给定其他模态的信息和其他未被掩码的令牌。

首先比较文本特征与图像特征之间的相似性,这需要看上一张图片,特征传入了这个Inter-Modality Scores,生成对应的分数。同样计算其他模态之间的相似性(如音频与视频、文本与结构化数据等)。将所有模态之间的相似性得分整合成一个得分矩阵
S
S
S。计算模态匹配分数
S
′
=
S
⋅
s
o
f
t
m
a
x
(
S
)
S' = S \cdot softmax(S)
S′=S⋅softmax(S)。利用
S
′
S'
S′ 来加权模态间损耗和模态内损耗,优化模型。
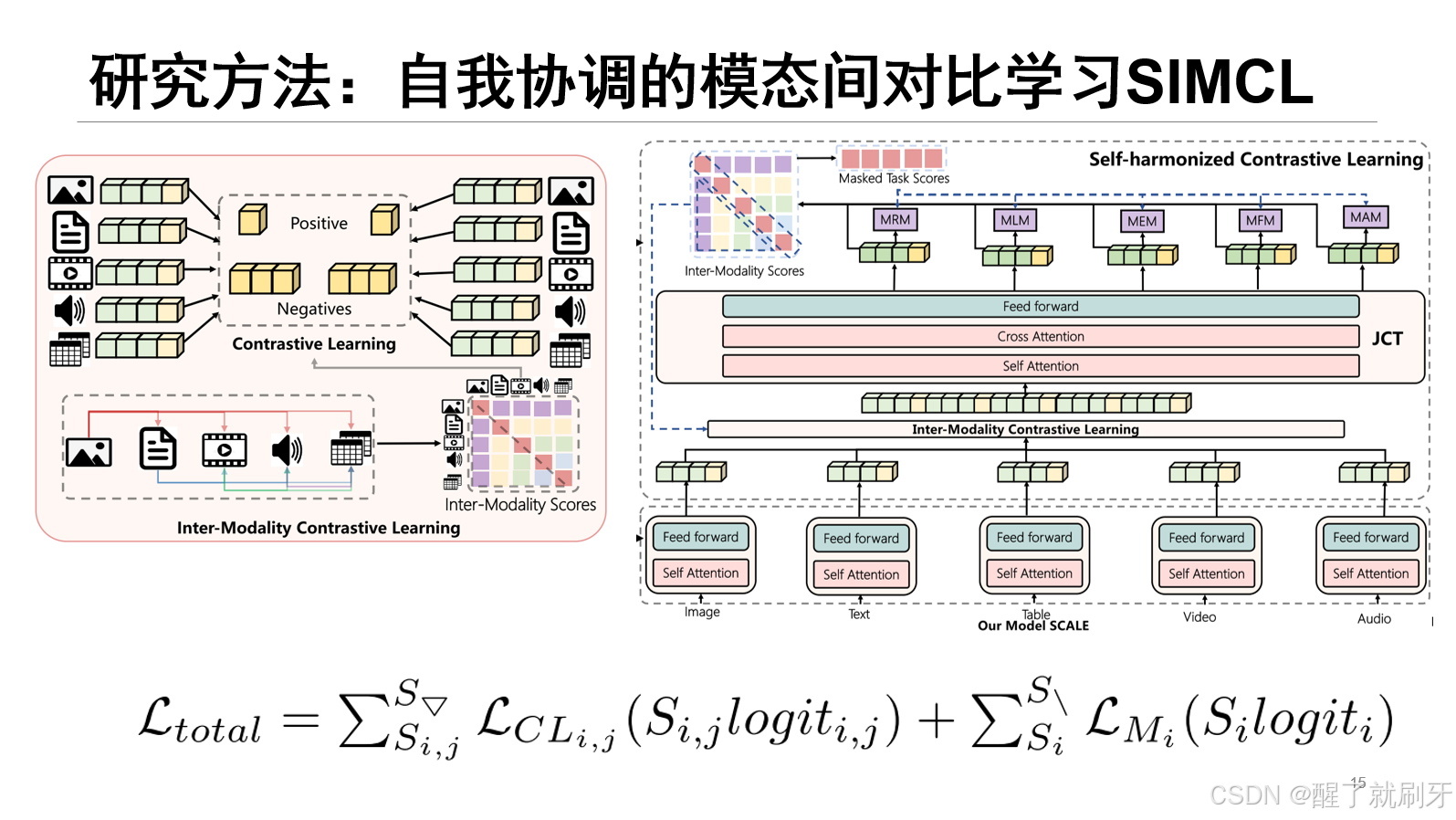
选择三角形部分
S
∇
S_{\nabla}
S∇来加权模态间损耗
L
C
L
L_{CL}
LCL,并且使用对角部分S来约束模态内损耗
L
M
i
L_{Mi}
LMi,从而得到加权损耗:
L
t
o
t
a
l
=
∑
S
i
,
j
S
▽
L
C
L
i
,
j
(
S
i
,
j
l
o
g
ı
˙
t
i
,
j
)
+
∑
S
i
S
∖
L
M
i
(
S
i
l
o
g
ı
˙
t
i
)
\mathcal{L}_{t o t a l}=\sum_{S_{i,j}}^{S_{\bigtriangledown}}\mathcal{L}_{C L_{i,j}}\left(S_{i,j}l o g\dot{\imath}t_{i,j}\right)+\sum_{S_{i}}^{S_{\setminus}}\mathcal{L}_{M_{i}}\left(S_{i}l o g\dot{\imath}t_{i}\right)
Ltotal=Si,j∑S▽LCLi,j(Si,jlog˙ti,j)+Si∑S∖LMi(Silog˙ti)
其中
l
o
g
i
t
logit
logit是损失
l
o
g
i
t
logit
logit。我们可以看到这个图中首先特征给到Inter-Modality Scores 然后两种得分 分别给到对比学习和五个代理任务。