强化学习之DQN算法
前言:
在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。
1. 什么是DQN?
深度Q网络(Deep Q-Network, DQN) 是深度学习与强化学习相结合的一种算法,它通过使用神经网络来逼近Q值函数,从而解决高维度的状态空间问题。DQN是由Google DeepMind团队提出的,并在经典的Atari游戏上展现了优越的性能。
强化学习的目标是在环境中通过一系列的动作使得累计奖励最大化。在DQN算法中,我们通过Q学习的方式,使用神经网络来逼近动作值函数 Q ( s , a ) Q(s, a) Q(s,a),即在给定状态 s s s 下选择动作 a a a 所能获得的预期奖励。
2. DQN的原理
DQN算法的核心思想在于通过深度神经网络逼近Q函数,并使用经验回放和目标网络来稳定训练过程。
2.1 Q学习回顾
Q学习是一种基于价值的强化学习方法,其基本更新公式为:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中:
- s s s 是当前状态,
- a a a 是当前动作,
- r r r 是执行动作后的即时奖励,
- γ \gamma γ 是折扣因子,
- α \alpha α 是学习率。
我们通过迭代更新 Q ( s , a ) Q(s, a) Q(s,a) 来逼近最优的Q值函数。
2.2 DQN的改进
在DQN中,Q函数 Q ( s , a ; θ ) Q(s, a; \theta) Q(s,a;θ) 通过一个深度神经网络进行逼近,神经网络的参数为 θ \theta θ。然而,直接使用神经网络逼近Q值会导致训练不稳定,为了解决这个问题,DQN提出了两个关键的改进:
-
经验回放(Experience Replay): 在强化学习过程中,连续的样本往往具有高度相关性,这会导致模型收敛不稳定。经验回放的做法是将智能体与环境交互过程中产生的样本存储在一个回放池中,然后随机抽取一批样本用于训练。这种随机抽取的方式可以打破样本之间的相关性,从而提高模型的稳定性。
-
目标网络(Target Network): 在Q学习中,我们需要使用当前的Q值来更新目标Q值。在DQN中,直接使用同一个网络来计算目标Q值会导致更新不稳定。目标网络的做法是引入一个与主网络结构相同但参数冻结的目标网络,每隔固定步数将主网络的参数复制给目标网络,以此来稳定训练。
DQN的损失函数为:
L ( θ ) = E ( s , a , r , s ′ ) ∼ D [ ( y − Q ( s , a ; θ ) ) 2 ] L(\theta) = \mathbb{E}_{(s, a, r, s') \sim D} \left[ \left( y - Q(s, a; \theta) \right)^2 \right] L(θ)=E(s,a,r,s′)∼D[(y−Q(s,a;θ))2]
其中目标值 y y y 为:
y = r + γ max a ′ Q ( s ′ , a ′ ; θ − ) y = r + \gamma \max_{a'} Q(s', a'; \theta^-) y=r+γa′maxQ(s′,a′;θ−)
其中 θ − \theta^- θ− 为目标网络的参数, D D D 是经验回放池中的数据。
3. 案例分析
我们使用OpenAI Gym库中的CartPole环境来演示DQN的应用。CartPole是一种经典的控制问题,目标是通过控制小车的运动保持竖直的杆子不倒。
3.1 环境介绍
在CartPole环境中,状态包括小车的位置、速度、杆子的角度和角速度。动作空间包括两个离散的动作:向左或向右施加力。奖励是在杆子不倒的每一个时间步获得+1,直到杆子倒下或超出边界。
3.2 代码实现
以下是基于DQN的CartPole环境的部分代码:
# 定义DQN代理
class DQN:
'''DQN算法'''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device) # Q网络
# 目标网络
self.target_q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net.load_state_dict(self.q_net.state_dict()) # 初始化目标网络
self.target_q_net.eval() # 目标网络设置为评估模式
# 使用Adam优化器
self.optimizer = optim.Adam(self.q_net.parameters(), lr=learning_rate)
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 计数器,记录更新次数
self.device = device
def take_action(self, state):
'''epsilon-贪婪策略采取动作'''
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
with torch.no_grad():
q_values = self.q_net(state)
action = q_values.argmax().item()
return action
def update(self, transition_dict):
'''更新Q网络'''
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
# 当前Q值
q_values = self.q_net(states).gather(1, actions)
# 下个状态的最大Q值
with torch.no_grad():
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
# 计算目标Q值
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
# 计算损失
loss = F.mse_loss(q_values, q_targets)
# 优化模型
self.optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 反向传播
self.optimizer.step() # 更新参数
# 更新epsilon
if self.epsilon > 0.01:
self.epsilon *= 0.995
# 更新目标网络
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict())
self.count += 1
运行结果:
奖励函数曲线如下:
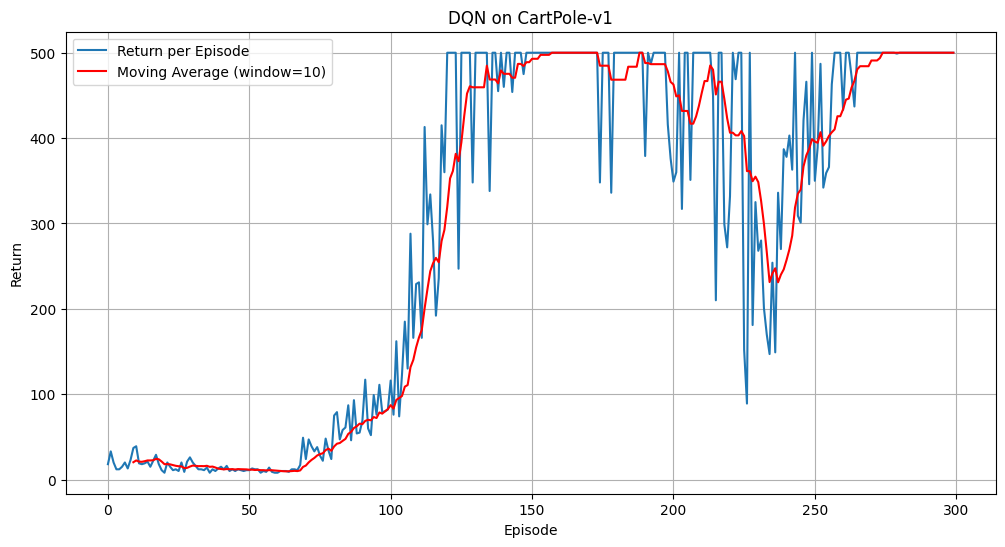
其中,蓝色曲线为奖励函数曲线,红色曲线为滑动平均奖励函数曲线。
4. 总结
DQN算法通过结合深度学习和强化学习,解决了传统Q学习在大规模状态空间中的难题。它引入的经验回放和目标网络极大地提升了训练的稳定性。通过上文的CartPole示例,我们可以看到如何使用DQN进行环境交互并学习策略。