【2024CANN训练营第二季】Ascend C概述
什么是算子
算子在神经网络中的定义
算子对应网络中层或者节点的计算逻辑
算子的数学含义
算子在数学中的定义:
一个函数空间到函数空间上的映射O:X->X;
广义:
对任何函数进行某一项操作都可以认为是一个算子。比如微分算子,不定积分算子等。
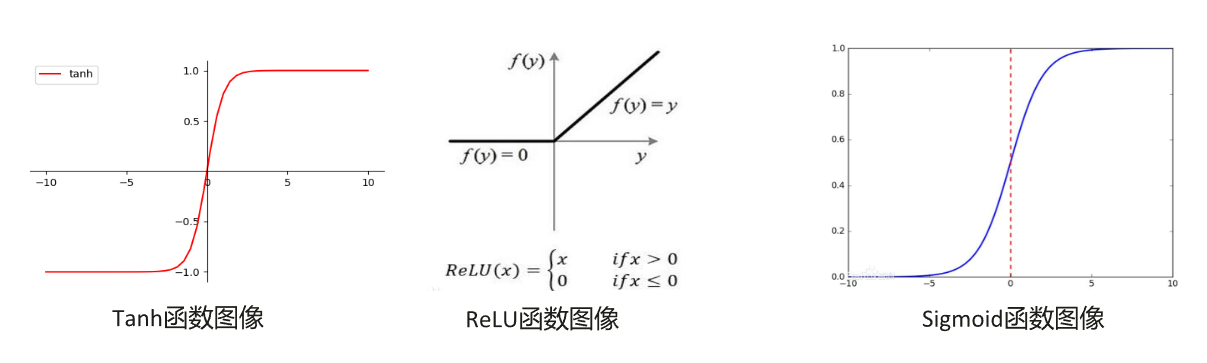
常见算子举例:tanh、ReLU、sigmoid等。
算子的基本概念
算子名称
算子的名称:用于标志网络中的某个算子,同一个网络中算子的名称需要保持唯一。
算子类型
网络中每一个算子根据算子类型进行算子实现的匹配,相同类型的算子的实现逻辑相同。在一个网络中同一类型的算子可能存在多个。
数据容器(Tensor)
算子在网络执行时,还需要一个重要的输入:数据,算子执行完后,也会有对应的数据输出,这种承载算子数据的容器定义为:张量(Tensor)
张量 Tensor
张量(Tensor)是存储算子输入数据与输出数据的容器,而张量描述符(TensorDesc)是对输入数据与输出数据的描述,张亮描述符的数据结构包括以下属性:
- 名称:用于对Tensor进行索引,不同Tensor的name需要保持唯一
- 形状:Tensor的形状,比如(10,)或者(1024,1024)或者(2,3,4)等。形式(i1,i2,…in),其中i1到in均为正整数。
- 数据类型:指定Tensor对象的数据类型。例如:float16,float32.int8,int16,int32,unint8,unit16,bool等。不同计算操作支持的数据类型也不同。
- 数据排布格式:数据的物理排布格式,定义了解数据的维度
什么是AscendC算子
基本概念
Ascend C算子是CANN针对算子开发场景推出的编程语言,通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。使用Ascend C编程语言开发的算子称之为Ascend C算子。
Ascend C自定义算子的优势
- C/C++原始编程,最大化匹配用户的开发习惯
- 编程模型屏蔽硬件差异,编程范式提高开发效率
- 多层级API封装,从简单到灵活,兼顾易用与高效
- 孪生调试,CPU侧模拟NPU侧的行为,可优化在CPU侧调试
什么场景需要开发自定义算子
一般情况下,无需自己开发算子,需要自己开发自定义算子的场景有以下:
- 推理场景下,将第三方框架模型使用ATC工具转换为适配Ascend平台的离线模型时遇到不支持的算子。
- 推理场景下,应用程序中的某些逻辑涉及到数学运算,开发者可以将这些操作通过自定义算子的方式进行实现,然后在APP中对算子进行调用,从而利用Ascend进行加速
- 训练场景下,将第三方框架的网络训练脚本迁移到Ascend平台遇到了不支持算子
- 网络调优时,发现某算子性能较低,想重新开发一个高性能算子替换性能较低的算子。
Ascend 介绍
Ascend AI处理器介绍

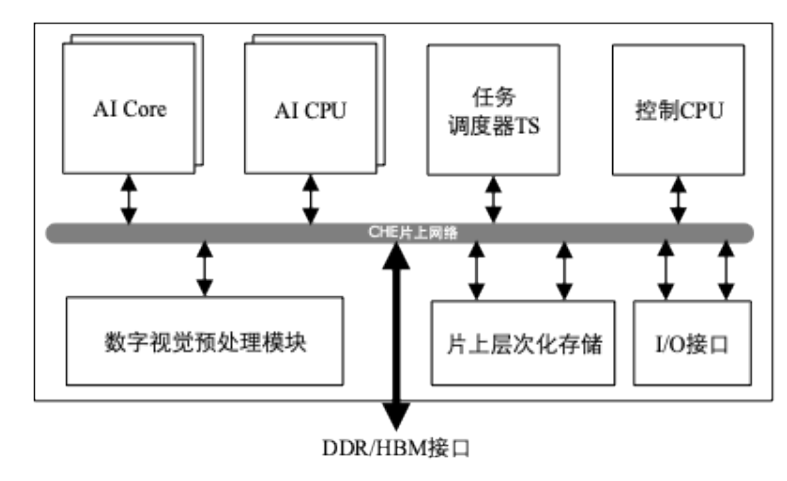
昇腾AI处理器芯片的逻辑结构
- 芯片系统控制处理器(Control CPU)
- 面向计算密集型任务的AI计算核心(AI Core)
- 面向非矩阵计算任务的AI处理器(AI CPU)
- 层次化的片上系统缓存/缓冲区
- 数字视觉与处理模块(DVPP:Digital Vision Pre-Processing)
- I/O接口
基于Ascend处理器的产品形态

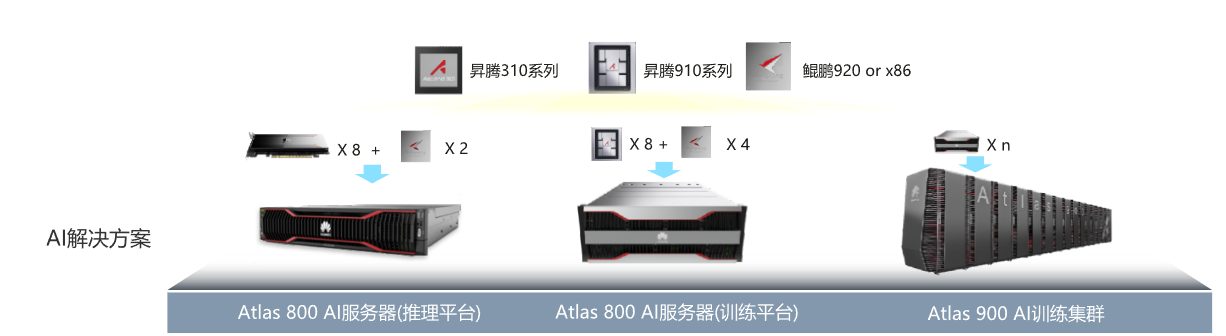
Atals开发者套件
华为Atlas 200I DK A2开发者套件
- 以Ascend310系列AI处理器为核心的一个开发者板产品,包括1个AI Core,4个TAISHAN处理器核(最大主频1.8GHz)
- 将昇腾AI处理器的核心功能通过该板上的外围接口开放出来,方便用户快速便捷接入并使用昇腾AI处理器强大的处理能力

昇腾CANN:向下使能处理器并行加速,向上使能高效开发
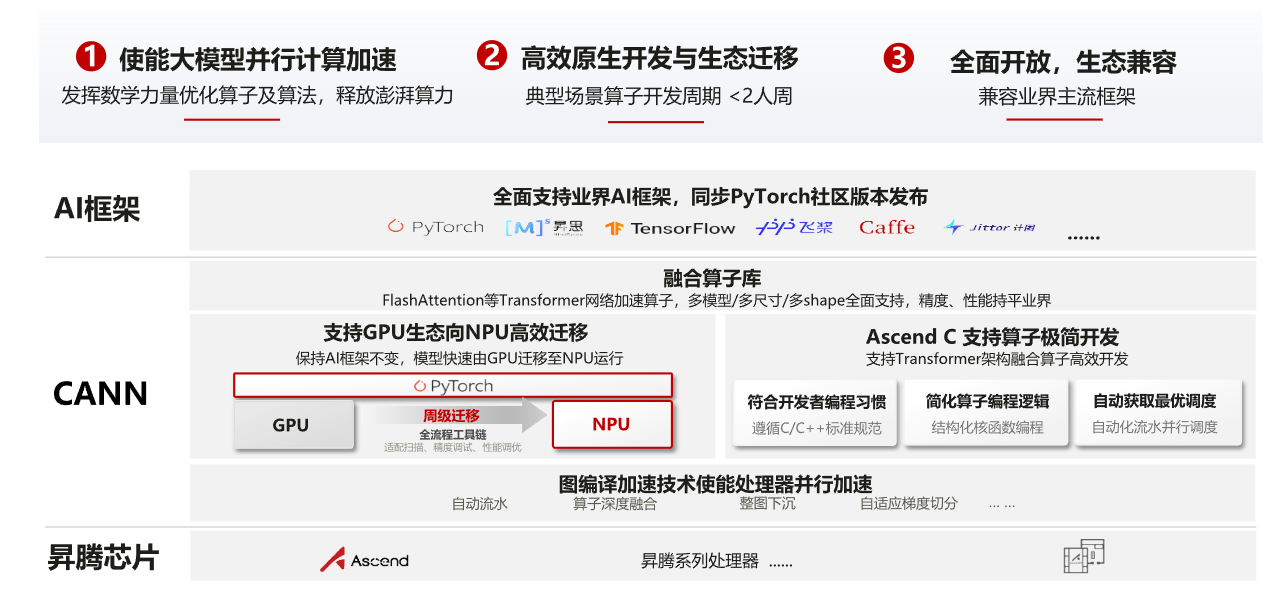
AscendCL:昇腾计算语言开放接口

AICore
AI Core是昇腾AI处理器的计算核心,采用华为自研的达芬奇架构,通常也被叫做DaVinci Core
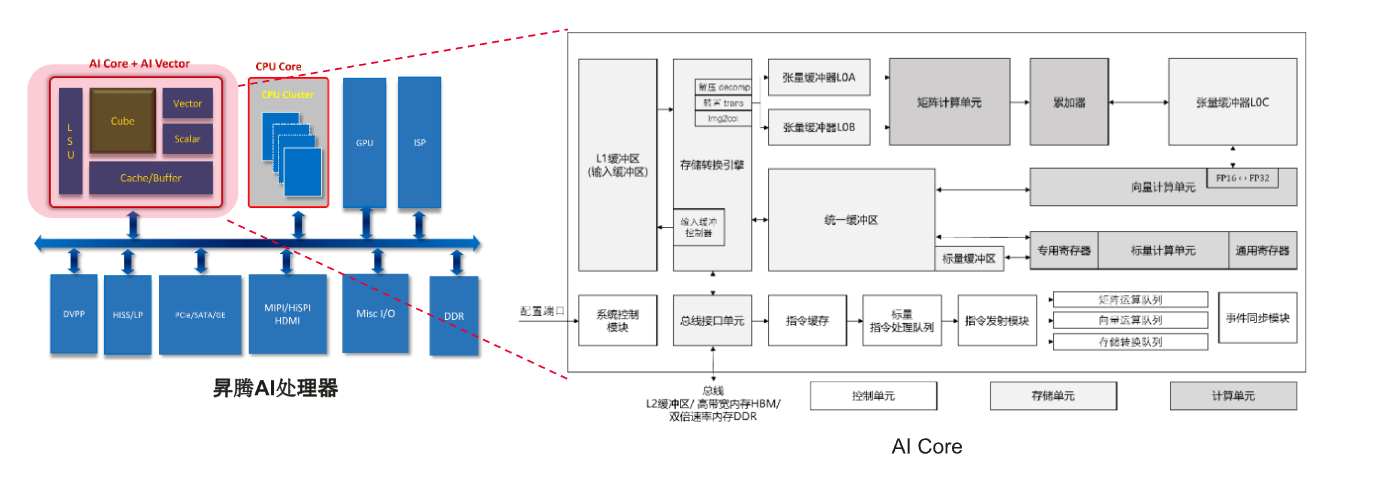
达芬奇架构的主要部分:
- 计算单元:包含三种基础计算资源(矩阵计算单元、向量计算单元、标量计算单元)
- 存储系统:AI Core的片上存储单元和相应的数据通路构成了存储系统
- 控制单元:整个计算过程提供了指令控制,相当于AI Core的司令部,负责整个AI Core的运行。
AI Core:计算单元-矩阵计算单元
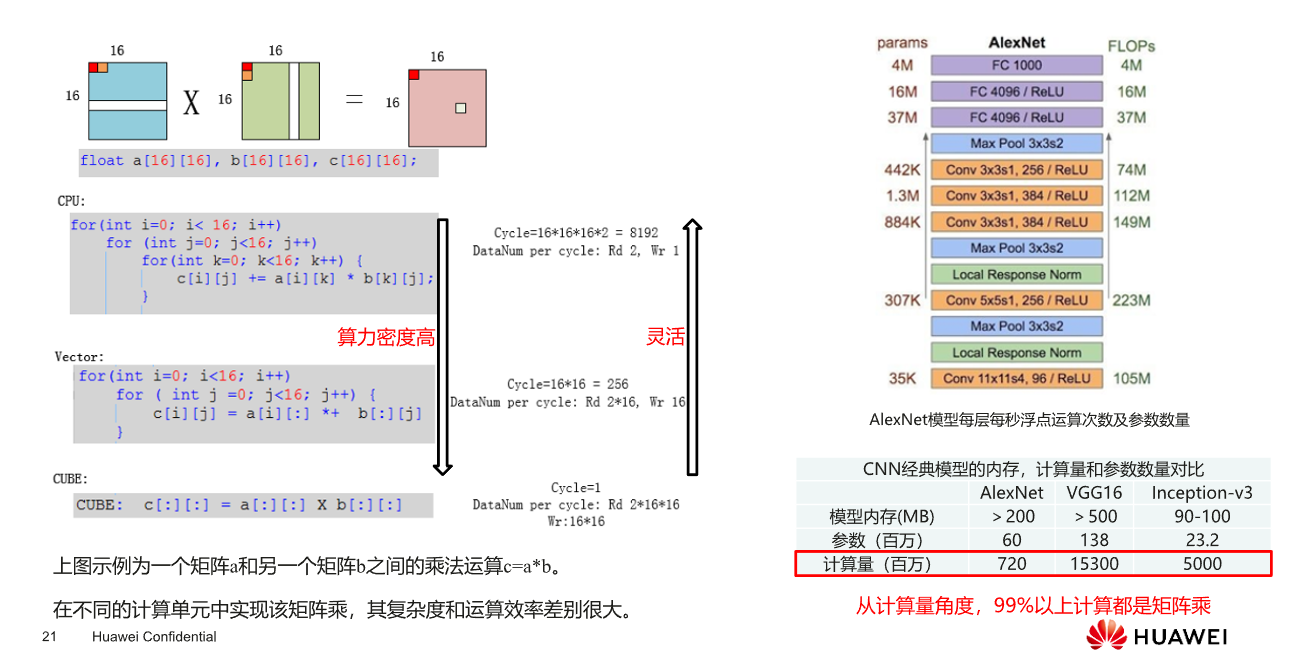
计算架构
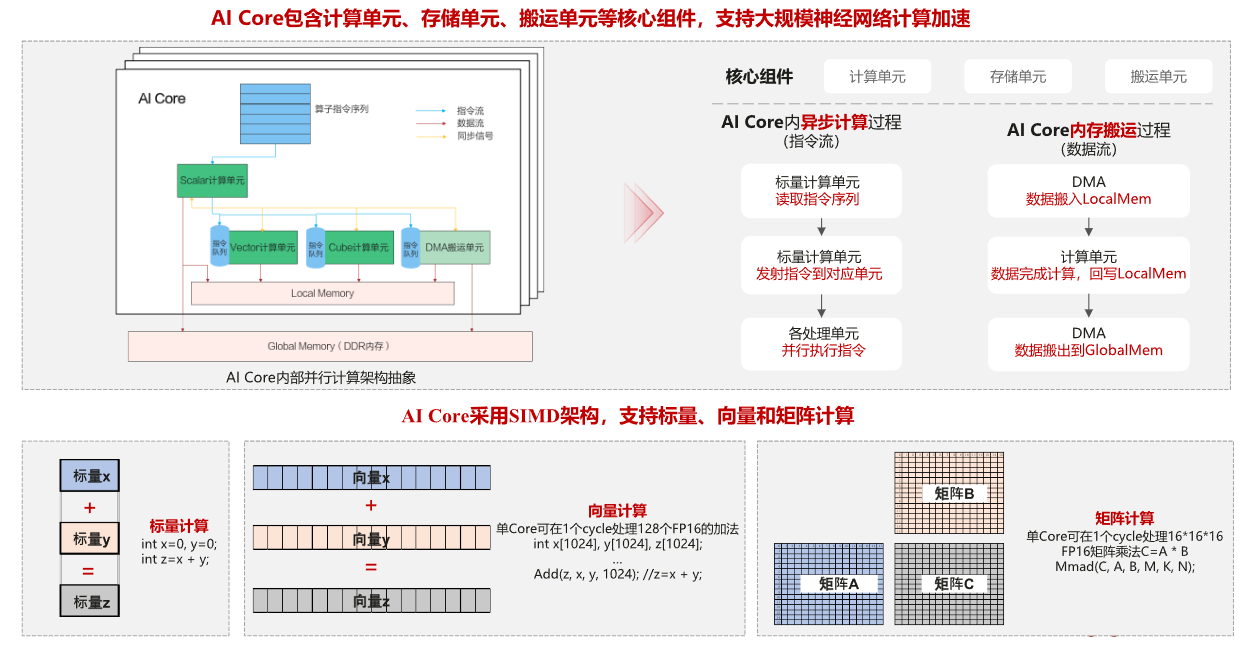
使用Ascend C编程语言开发的算子运行的AI Core上,AI Core是昇腾AI处理器中的计算核心,一个AI处理器内部有多个AI Core,AI Core中包含计算单元、存储单元、搬运单元等核心组件
计算单元:
- Scalar计算单元 :执行地址计算、循环控制等标量计算工作,并把向量计算、矩阵计算、数据搬运、同步指令发射给对应单元执行
- Cube计算单元:负责执行矩阵运算
- Vector计算单元:负责执行向量计算
存储单元:
AI Core的内部存储,统称为Local Memory
与此相对应,AI Core的外部存储称之为Global Memory
搬运单元:
负责在Gloabl Memory和Local Memory之间搬运数据,包含搬运单元MTE2(Memory Transfer Engine:数据搬入单元),MTE3(数据搬出单元)