Apache Seatunnel Zeta引擎-启动脚本分析
Apache SeaTunnel Zeta引擎的集群模式启动的第一步是执行bin/seatunnel-cluster.sh脚本,所以先来学习下这个脚本。
脚本执行流程分析
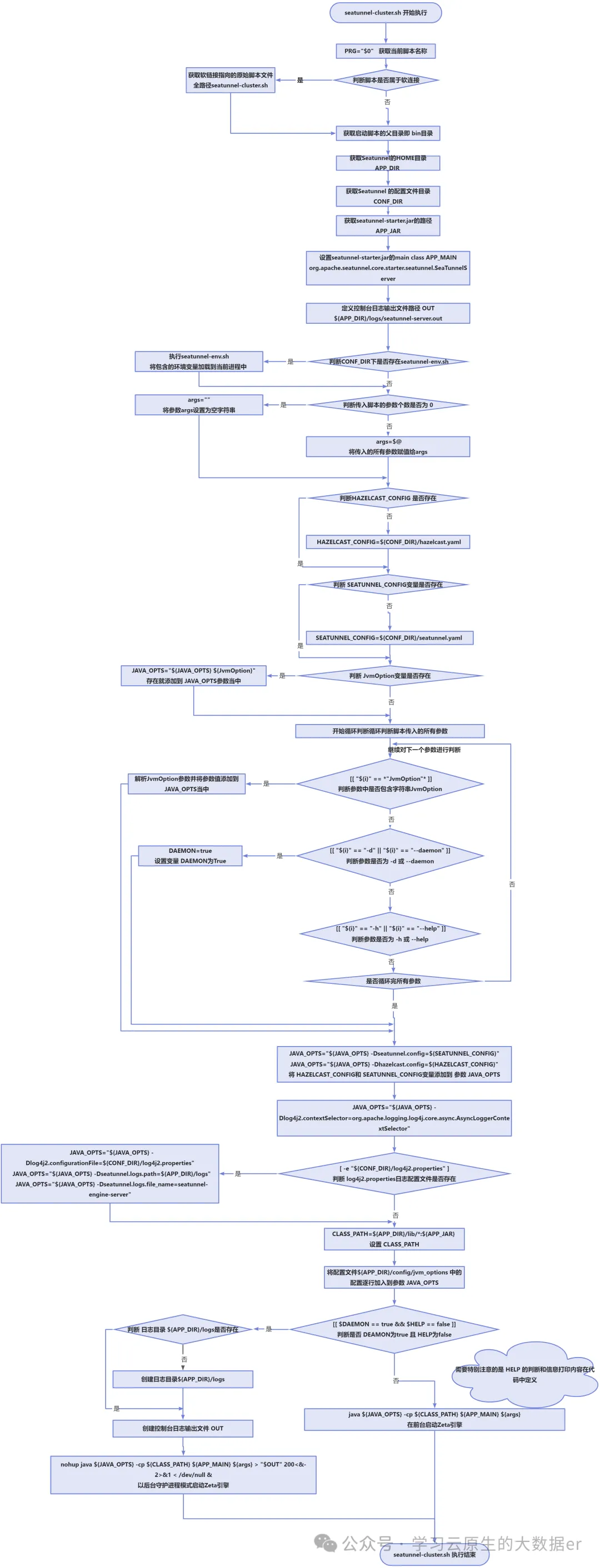
脚本简要注释
#!/bin/bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
##########
# set -e 当脚本出现异常时马上退出,后续命令不再执行
# set -u 把未定义的变量视作错误,默认情况下Bash会把未定义的变量视为空,不会报错
##########
set -eu
# resolve links - $0 may be a softlink
#$0返回当前值行的shell脚本的名称
PRG="$0"
# -h 表示 如果 FILE 存在且是一个符号连接则为真
while [ -h "$PRG" ] ; do
# shellcheck disable=SC2006
ls=`ls -ld "$PRG"` # -d 仅列出当前目录本身
# shellcheck disable=SC2006
link=`expr "$ls" : '.*-> \(.*\)$'` # 提取软连接的目标路径
# 如果 link 以 / 开头,则 为true 否则为 false
if expr "$link" : '/.*' > /dev/null; then
PRG="$link" # 以 / 开头表明 路径为全路径
else
# shellcheck disable=SC2006
PRG=`dirname "$PRG"`/"$link" # 不以 / 开头说明 link只是 文件名称,需要拼接全路径
fi
done
PRG_DIR=`dirname "$PRG"` # 返回启动脚本的父目录bin
APP_DIR=`cd "$PRG_DIR/.." >/dev/null; pwd` # 进入启动脚本的父目录bin 的上级目录,即软件HOME目录
CONF_DIR=${APP_DIR}/config # 配置文件路径
APP_JAR=${APP_DIR}/starter/seatunnel-starter.jar # starter jar 路径
APP_MAIN="org.apache.seatunnel.core.starter.seatunnel.SeaTunnelServer" # starter jar main class
OUT="${APP_DIR}/logs/seatunnel-server.out" # 定义控制台日志输出文件
HELP=false
if [ -f "${CONF_DIR}/seatunnel-env.sh" ]; then # 判断是否存在 seatunnel-env.sh
# . seatunnel-env.sh 在当前进程中执行 shell脚本,从而使脚本中定义的变量函数在当前shell中生效而不是在子shell 中
# 使得脚本中的环境设置对当前进程持续生效
. "${CONF_DIR}/seatunnel-env.sh" # 如果存在则加载其中的环境变量
fi
# $# 参数的个数
if [ $# == 0 ] # 判断参数的个数是否为0
then
args=""
else
args=$@ # $@ 脚本传入的所有参数
fi
set +u # 取消对未设置变量的使用报错
# SeaTunnel Engine Config
if [ -z $HAZELCAST_CONFIG ]; then # -z 字符串长度为 0 则为真
HAZELCAST_CONFIG=${CONF_DIR}/hazelcast.yaml # 当不存在变量 $HAZELCAST_CONFIG 时 ,设置该变量的值
fi
if [ -z $SEATUNNEL_CONFIG ]; then
SEATUNNEL_CONFIG=${CONF_DIR}/seatunnel.yaml # 当不存在变量 $SEATUNNEL_CONFIG 时 ,设置该变量的值
fi
if test ${JvmOption} ;then # 如果变量不为空 则 test 返回true
JAVA_OPTS="${JAVA_OPTS} ${JvmOption}"
fi
for i in "$@" # 循环脚本传输的参数
do
if [[ "${i}" == *"JvmOption"* ]]; then # 如果参数包含 JvmOption 则将该变量的值赋给 JVM_OPTION
JVM_OPTION="${i}"
JAVA_OPTS="${JAVA_OPTS} ${JVM_OPTION#*=}"
elif [[ "${i}" == "-d" || "${i}" == "--daemon" ]]; then
DAEMON=true
elif [[ "${i}" == "-h" || "${i}" == "--help" ]]; then
HELP=true
fi
done
JAVA_OPTS="${JAVA_OPTS} -Dseatunnel.config=${SEATUNNEL_CONFIG}"
JAVA_OPTS="${JAVA_OPTS} -Dhazelcast.config=${HAZELCAST_CONFIG}"
# Log4j2 Config
JAVA_OPTS="${JAVA_OPTS} -Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector"
if [ -e "${CONF_DIR}/log4j2.properties" ]; then
JAVA_OPTS="${JAVA_OPTS} -Dlog4j2.configurationFile=${CONF_DIR}/log4j2.properties"
JAVA_OPTS="${JAVA_OPTS} -Dseatunnel.logs.path=${APP_DIR}/logs"
JAVA_OPTS="${JAVA_OPTS} -Dseatunnel.logs.file_name=seatunnel-engine-server"
fi
# Server Debug Config
# Usage instructions:
# If you need to debug your code in cluster mode, please enable this configuration option and listen to the specified
# port in your IDE. After that, you can happily debug your code.
# JAVA_OPTS="${JAVA_OPTS} -Xdebug -Xrunjdwp:server=y,transport=dt_socket,address=5001,suspend=y"
CLASS_PATH=${APP_DIR}/lib/*:${APP_JAR} #设置CLASS_PATH
while read line # 用while 循环读取输入文件中的每一行
do
if [[ ! $line == \#* ]] && [ -n "$line" ]; then # 如果字符串不以 # 开头,同时非空 则为真
JAVA_OPTS="$JAVA_OPTS $line"
fi
done < ${APP_DIR}/config/jvm_options # 将jvm_options中设置的jvm配置加入 到 JAVA_OPTS
if [[ $DAEMON == true && $HELP == false ]]; then ## 如果参数 不是help 并且 为 daemon 时 自动创建日志目录
if [[ ! -d ${APP_DIR}/logs ]]; then
mkdir -p ${APP_DIR}/logs
fi
touch $OUT # 创建控制台输出日志文件
# 启动Java应用程序
# ${JAVA_OPTS} java虚拟机的启动参数
# ${CLASS_PATH} 类路径
# ${APP_MAIN} Java应用程序主类
# ${args}传给java应用程序的主要参数
nohup java ${JAVA_OPTS} -cp ${CLASS_PATH} ${APP_MAIN} ${args} > "$OUT" 200<&- 2>&1 < /dev/null &
else
java ${JAVA_OPTS} -cp ${CLASS_PATH} ${APP_MAIN} ${args}
fi
脚本一些特别说明
JVM相关参数
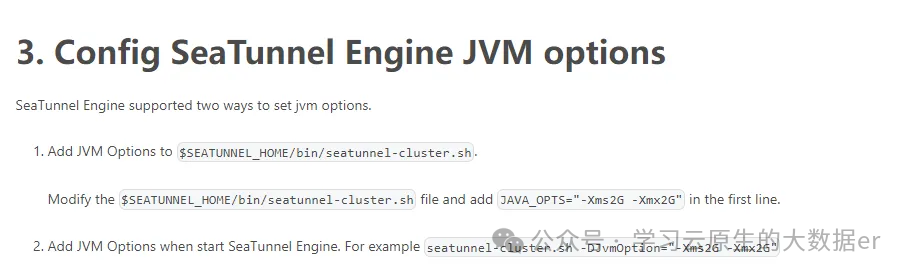
根据对脚本的分析可知,共有三处可以配置和制定JVM相关参数
执行脚本时通过命令行参数传入
可以在执行seatunnel-cluster.sh脚本时传入jvm参数,但是格式比如符合如下要求:需要格式为key=value的格式,key中必须包含字符串JvmOption,value则是具体的JVM配置项。如:
bash seatunnel-cluster.sh JvmOption="-Xms2G -Xmx2G"
bash seatunnel-cluster.sh xJvmOptionx="-Xms2G -Xmx2G"
bash seatunnel-cluster.sh -DJvmOption="-Xms2G -Xmx2G"添加脚本
在seatunnel-cluster.sh脚本第一行添加JAVA_OPTS="-Xms2G -Xmx2G"。
以上两种方式官网部署文档皆有说明,如下:
在配置文件jvm_options中指定
在启动脚本中有一部分代码是对 位于CONF_DIR下的jvm_options中的配置逐行加载。
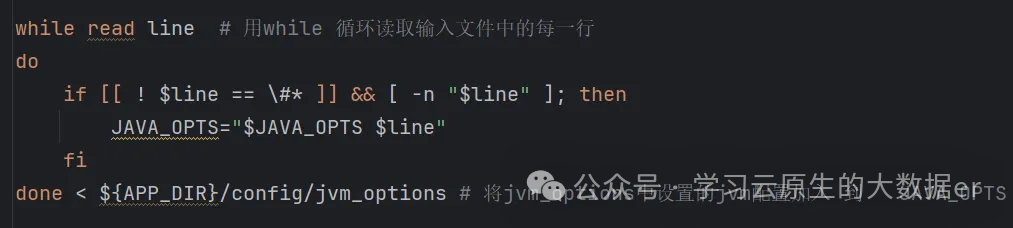
虽然以上三种均会把相关配置加载到JAVA_OPTS,但是我个人更推荐通过配置文件jvm_options的方式来指定,这样既避免了对seatunnel-cluster.sh脚本进行修改,又可以以文件的形式将详细配置保存下来。
为启动脚本seatunnel-cluster.sh创建软链
根据对启动脚本的分析,允许使用 软链的方式启动seatunnel zeta服务, 可以用于在服务器中集中管理 各种服务启动脚本的场景。
用户可以通过软链固定服务启动路径,如在/usr/bin目录下指定seatunnel-cluster.sh的软链:
cd /usr/bin
ln -snf /opt/soft/seatunnel/apache-seatunnel-2.3.5/bin/seatunnel-cluster.sh seatunnel-cluster
则可通过如下命令启动服务:
/usr/bin/seatunnel-cluster
日志目录配置
根据对脚本的分析,seatunnel zeta的目录被设置为${APP_DIR}/logs, 在脚本中进行硬编码以变量seatunnel.logs.path传入JAVA_OPTS, 然后log4j2.properties通过该变量读取的日志目录的配置。
如果需要自定义目录的配置:
要么修改
seatunnel-cluster.sh指定自定义的日志目录要么修改
log4j2.properties文件放弃从环境变量读取seatunnel.logs.path, 直接指定自定义的日志目录。
目前来看以上两种方式都不够友好,另外结合seatunnel-cluster.sh在执行过程中会加载seatunnel-env.sh。
在对当前日志目录配置的逻辑不进行大的调整的前提下,如果把日志相关目录的配置开放到seatunnel-env.sh对于需要自定义日志目录的用户来说会更为友好,当然这需要对脚本做一定的修改。
附录
附录为脚本执行流程的文字描述,作为对执行流程图无法表达的内容的补充:
脚本大意如下
首先获取当前执行脚本的名称,然后判断执行为脚本文件是否属于软链接,如果是软连接则获取软连接指向的原始脚本文件,并获取seatunnel-cluster.sh所在目录bin,根据获取到的bin目录获取Seatunnel的HOME目录并赋值为APP_DIR,同时设置 配置文件目录 为CONFIG_DIR,并且定义seatunnel-starter.jar的路径为APP_JAR。
设置org.apache.seatunnel.core.starter.seatunnel.SeaTunnelServer为 main classAPP_MAIN,定义控制台日志输出文件 为OUT。
判断是否存在seatunnel-env.sh, 如果存在则执行该脚本将环境变量加载到当前进程。
判断传入的参数个数,如果为0,则将参数置为"", 否则将所有参数赋给arg。
判断HAZELCAST_CONFIG变量是否存在,不存在则将hazelcast.yaml文件路径赋值给它。
判断SEATUNNEL_CONFIG变量是否存在,不存在则将seatunnel.yaml文件路径赋值给它。
判断JvmOption变量是否存在,若存在就添加到JAVA_OPTS参数当中。
循环判断脚本传入的所有参数
若参数包含字符串JvmOption, 则认定该参数为 JVM配置,并且从该参数开头删除第一个=及=之前的字符,将剩下的内容添加到参数JAVA_OPTS当中。
这一点说明,可以在启动脚本时传递 JVM参数,但是对格式有一定要求,即 需要格式为 key=value的格式,key中必须包含字符串JvmOption,value 则是具体的JVM配置项。
若参数为-d或--daemon, 则将变量DAEMON设置为 true。
若参数为-h或--help, 则将变量HELP设置为true。
将HAZELCAST_CONFIG和SEATUNNEL_CONFIG变量添加到 参数JAVA_OPTS
将日志配置-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector添加到参数JAVA_OPTS
判断log4j2.properties日志配置文件是否存在,若存在则将-Dlog4j2.configurationFile=${CONF_DIR}/log4j2.properties、-Dseatunnel.logs.path=${APP_DIR}/logs、-Dseatunnel.logs.file_name=seatunnel-engine-server添加到参数JAVA_OPTS
设置CLASS_PATH,然后将jvm_options配置文件中的配置逐行加入到 参数JAVA_OPTS
- 如果变量
DEAMON为true并且 变量HELP为false:
1. 判断日志目录 ` ${APP_DIR}/logs`是否存在,不存在则创建
2. 创建控制台日志输出文件
3. 运行命令 `nohup java ${JAVA_OPTS} -cp ${CLASS_PATH} ${APP_MAIN} ${args} > "$OUT" 200<&- 2>&1 < /dev/null &`后台启动 `Seatunnel ` Zeta 引擎- 如果变量
DEAMON为true并且 变量HELP为true:
1. 运行命令`java ${JAVA_OPTS} -cp ${CLASS_PATH} ${APP_MAIN} ${args}`前台运行 `Seatunnel Zeta引擎`- 如果变量
DEAMON为false:
1. 运行命令`java ${JAVA_OPTS} -cp ${CLASS_PATH} ${APP_MAIN} ${args}`前台运行 `Seatunnel Zeta引擎`到此为止,已经完成整个脚本的执行,成功启动SeaTunnel Zeta引擎。以上为作者个人学习解读,如果错误之处,欢迎批评指正!!!
本文由 白鲸开源科技 提供发布支持!