通过监控和警报驯服人工智能野兽

AI 是一头野兽。它需要不断地被喂养。它需要喂什么?当然是数据,而且是大量的。请记住,数据和 AI 是同一枚硬币的两面。人们经常忘记,最初构建 AI 模型的原因是因为它们被馈送到数百 PB 到 EB 的数据,当然,这些数据存储在 MinIO Enterprise Object Store 上,要使此类模型有效,需要数千次。但是,当管理如此大规模的数据时,不可能查看单个日志或节点来尝试理解它。您需要的是数据状态和整个集群基础架构的整体视图。硬盘驱动器(SSD、NVMe 等)是最常见的基础设施之一,通常需要监控并在需要时更换。硬盘驱动器由于各种原因而发生故障,而 MinIO 完全能够全速运行,即使同时出现多个驱动器故障,具体取决于擦除码的计算,而不会出汗。但是当足够多的驱动器出现故障时,物理学就会接管。如果未及时更换这些发生故障的驱动器,或者驱动器数超过纠删码配置的驱动器数。这可能会产生级联效应,例如,从 Kafka 队列读取请求的 ETL 作业可能会运行缓慢或完全挂起,因为它无法从 MinIO 存储桶中读取,因为太多驱动器已停用太长时间。手动执行上述任何操作都是不可能的,因此在这篇文章中,我们将向您展示如何在 Web 浏览器中可视化集群指标,并且我们将设置警报,以便在需要更换驱动器或驱动器空间不足等内容时,我们会收到警报。
先决条件
我们希望这篇文章简洁明了,因此以下是我们希望您在继续下一步之前已经设置的一些先决条件。
-
启动并运行 MinIO Enterprise 部署。
-
在 Docker 中运行的 Grafana(用于可视化)
-
在 Docker 中运行的 Prometheus(用于存储指标和警报)
收集 Metrics 数据
我们将配置 Prometheus 服务,以从 MinIO 部署中抓取和显示指标数据。除此之外,我们还将在 MinIO 指标上设置警报规则以触发 AlertManager 操作。将以下抓取配置添加到您的 Prometheus 容器中。
global:
scrape_interval: 60s
scrape_configs:
- job_name: minio-job
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/cluster
scheme: https
static_configs:
- targets: [minio.example.net]
-
设置适当的 scrape_interval 值,以确保每个抓取操作在下一个操作开始之前完成。建议的值为 60 秒。由于要抓取的指标数量众多,某些部署需要更长的抓取间隔。要减少 MinIO 和 Prometheus 服务器上的负载,请选择满足监控要求的最长间隔。
-
将 job_name 设置为与 MinIO 部署关联的值。使用唯一值来确保部署指标与该 Prometheus 服务收集的任何其他指标隔离。
-
以 MINIO_PROMETHEUS_AUTH_TYPE 设置为 “public” 开始的 MinIO 部署可以省略 bearer_token 字段。
-
对于不使用 TLS 的 MinIO 部署,将方案设置为 http。
-
使用解析为 MinIO 部署的主机名设置 targets 数组。这可以是任何单个节点,也可以是处理与 MinIO 节点连接的负载均衡器/代理。
在 MinIO,我们建议您监控以下指标并发出警报。
| Metric | Description |
| minio_node_drive_free_bytes | 驱动器上的总可用存储空间。 |
| minio_node_drive_free_inodes | 可用 inode 总数。 |
| minio_node_drive_latency_us | 驱动器 API 存储操作的平均最后一分钟延迟(以 μs 为单位)。 |
| minio_node_drive_offline_total | 此节点中脱机的驱动器总数。 |
| minio_node_drive_online_total | 此节点中联机的驱动器总数。 |
| minio_node_drive_total | 此节点中的驱动器总数。 |
| minio_node_drive_total_bytes | 驱动器上的总存储空间。 |
| minio_node_drive_used_bytes | 驱动器上使用的总存储空间。 |
| minio_node_drive_errors_timeout | 自服务器启动以来的驱动器超时错误总数。 |
| minio_node_drive_errors_availability | 自服务器启动以来驱动器 I/O 错误、权限被拒绝和超时的总数。 |
| minio_node_drive_io_waiting | 等待驱动器的 I/O 操作总数。 |
以下查询示例返回 Prometheus 为名为 minio-job 的抓取作业每 5 分钟收集一次的指标:
minio_node_drive_free_bytes{job-"minio-job"}[5m]
minio_node_drive_free_inodes{job-"minio-job"}[5m]
minio_node_drive_latency_us{job-"minio-job"}[5m]
minio_node_drive_offline_total{job-"minio-job"}[5m]
minio_node_drive_online_total{job-"minio-job"}[5m]
minio_node_drive_total{job-"minio-job"}[5m]
minio_node_drive_total_bytes{job-"minio-job"}[5m]
minio_node_drive_used_bytes{job-"minio-job"}[5m]
minio_node_drive_errors_timeout{job-"minio-job"}[5m]
minio_node_drive_errors_availability{job-"minio-job"}[5m]
minio_node_drive_io_waiting{job-"minio-job"}[5m]
为了收到警报,让我们创建几个警报规则
groups:
- name: minio-alerts
rules:
- alert: NodesOffline
expr: avg_over_time(minio_cluster_nodes_offline_total{job="minio-job"}[5m]) > 0
for: 10m
labels:
severity: warn
annotations:
summary: "Node down in MinIO deployment"
description: "Node(s) in cluster {{ $labels.instance }} offline for more than 5 minutes"
- alert: DisksOffline
expr: avg_over_time(minio_cluster_drive_offline_total{job="minio-job"}[5m]) > 0
for: 10m
labels:
severity: warn
annotations:
summary: "Disks down in MinIO deployment"
description: "Disks(s) in cluster {{ $labels.instance }} offline for more than 5 minutes"
上述配置将提醒您要在 MinIO 集群上监控的两件可以说是最重要的事情。节点和磁盘。如果其中任何一个低于 Erasure Code 设置所需的最低计数,则您可能会开始看到一些数据可访问性问题。同样,物理学在某个点之后接管。
可视化指标
要可视化指标,请首先下载由 MinIO 核心工程师策划的 Dashboard template 链接的配置。对于使用服务器端加密(SSE-KMS 或 SSE-S3)运行的 MinIO 部署,控制面板包括 KMS 的指标。这些指标包括状态、请求错误率和请求成功率。
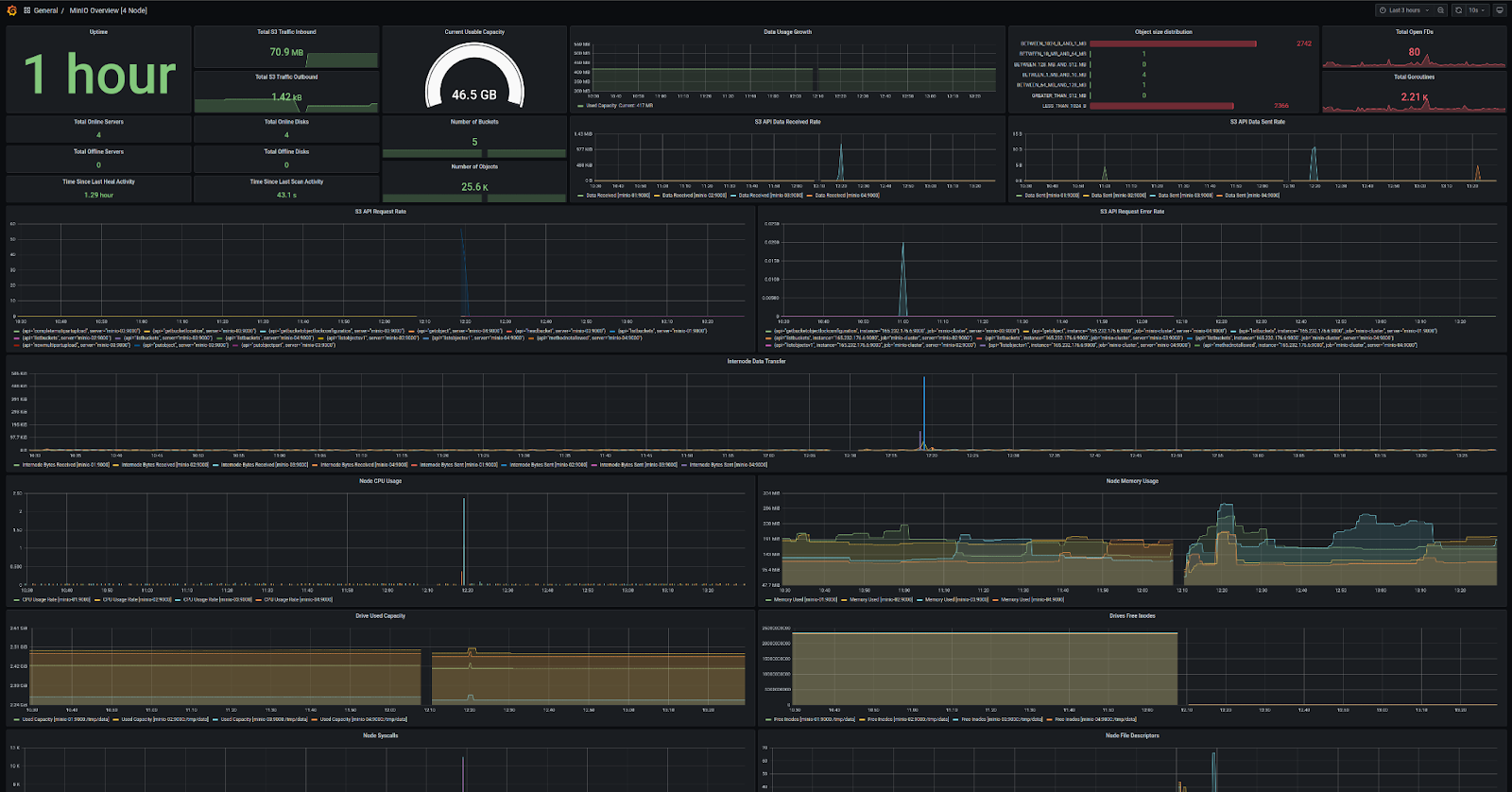
存储桶指标如下所示。
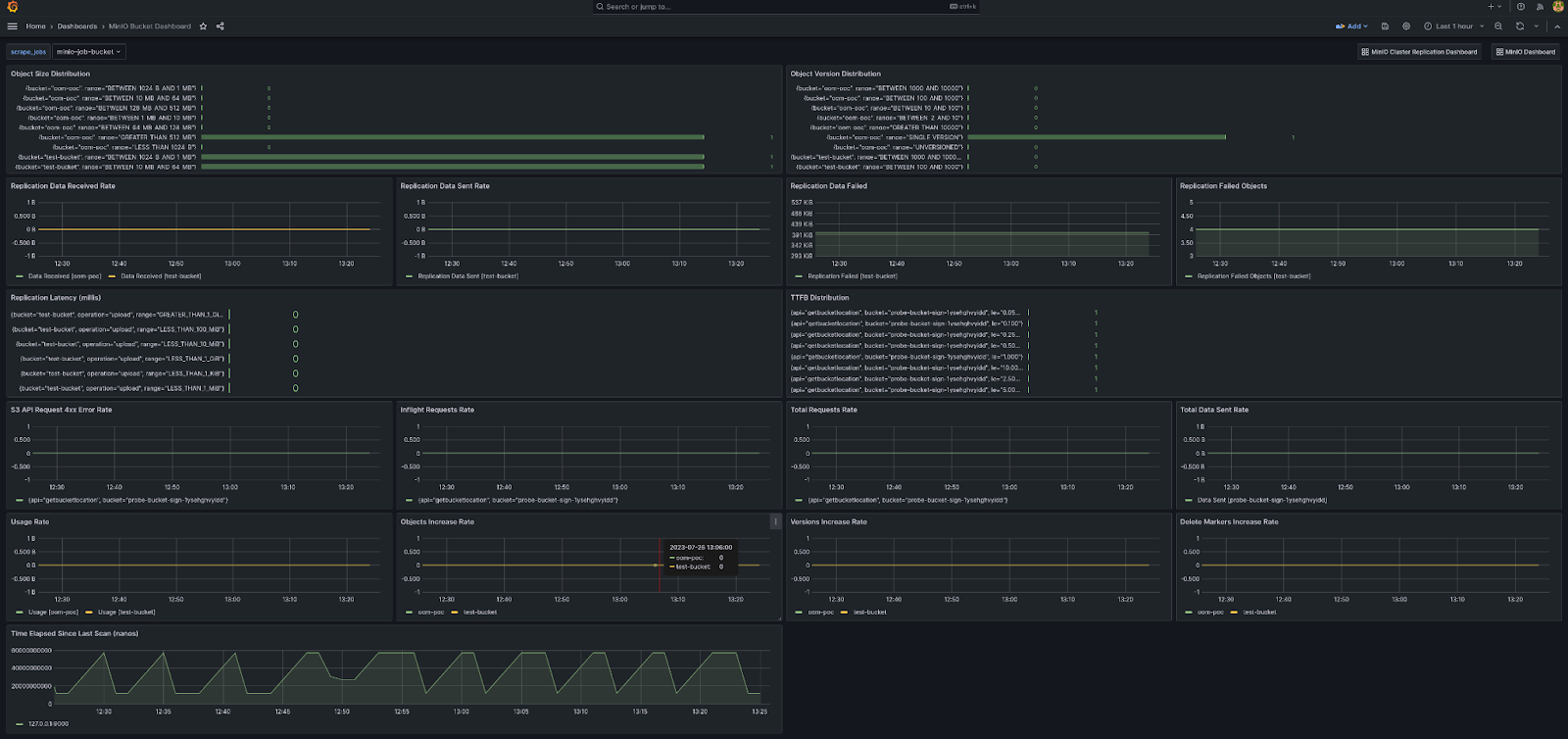
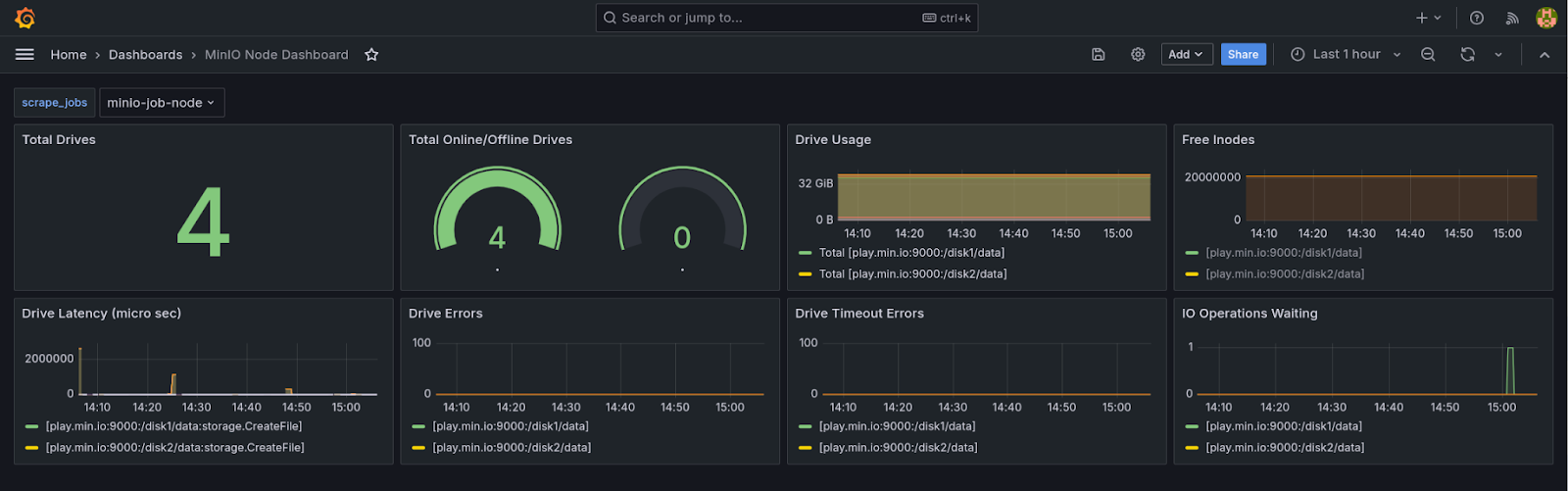
Node Metrics (节点指标) 为您提供每个节点的更多详细信息。
最后但并非最不重要的一点是 Replication dashboard
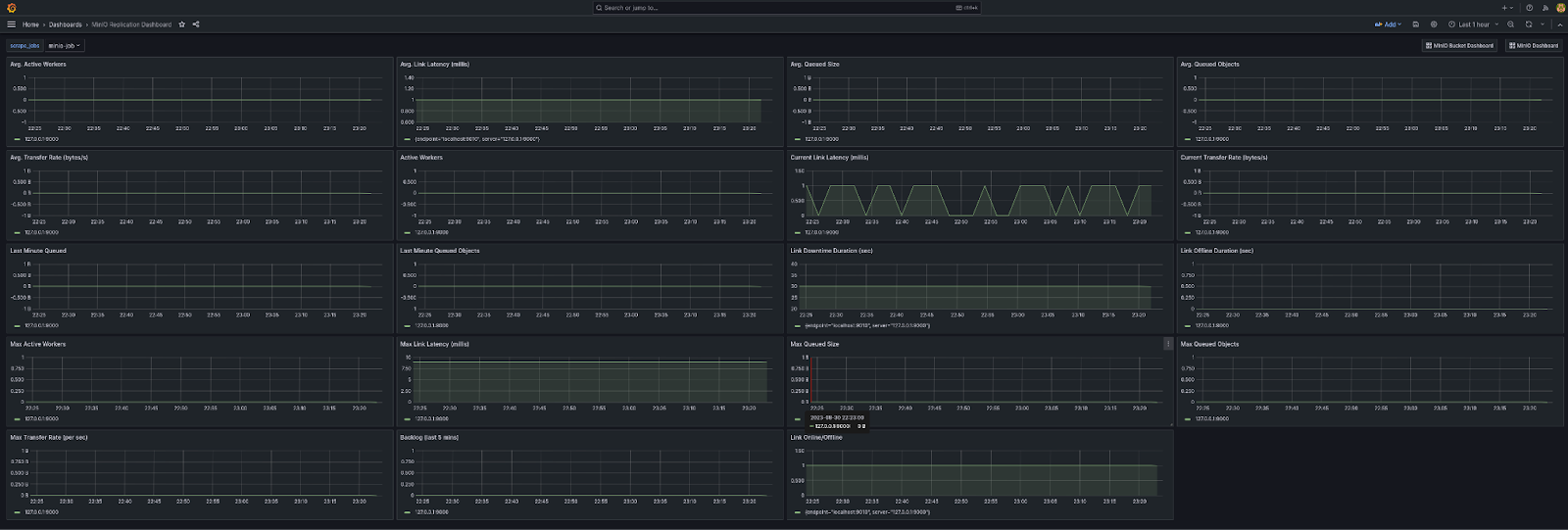
在几个月的时间里,对数据进行模式可视化与监控基础设施的任何其他部分一样重要。
掌握 AI 数据基础架构
MinIO Enterprise Object Store 可能是目前最简单、最轻量级的对象存储解决方案之一。事实上,人们一次又一次地将 MinIO 的易于安装和使用评为考虑 MinIO 的前三个因素之一。

虽然 MinIO 可以让您在合理的范围内搬起石头砸自己的脚(与 Ceph 不同),但您只能在不正确维护和监控基础设施的情况下走到这一步。只要对基础设施进行监控并就可能的问题发出警报,您就可以掌握 AI 数据存储基础设施,确保每个人都能随时以闪电般的速度使用它。在 MinIO,我们不仅注重简单性,还注重管理基础设施的最佳实践。