第T5周:Tensorflow实现运动鞋品牌识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
根据鞋子的品牌logo判断鞋子所属的品牌
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Tensorflow 2.10.0
(二)具体步骤
1.查询tf版本及使用GPU
import pathlib
import matplotlib.pyplot as plt
import PIL.Image
import tensorflow as tf
from tensorflow.keras import models, layers
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
print(tf.__version__)
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用0号GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存按需使用
tf.config.set_visible_devices([gpu0], "GPU") # 指定运行时GPU
2.10.0
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2.导入数据
本次数据放在根目录的datasets/shoes文件夹下:
# 导入数据
data_dir = "./datasets/shoes/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:", image_count)
nike_shoes = list(data_dir.glob('train/nike/*.jpg'))
print("NIKE品牌鞋子图片数量为:", len(nike_shoes))
adidas_shoes = list(data_dir.glob('train/adidas/*.jpg'))
print("ADIDAS品牌鞋子图片数量为:", len(adidas_shoes))
shoes = PIL.Image.open(nike_shoes[0])
shoes.show()
shoes = PIL.Image.open(adidas_shoes[0])
shoes.show()
图片总数为: 578
NIKE品牌鞋子图片数量为: 251
ADIDAS品牌鞋子图片数量为: 251


3.加载数据
# 加载数据
batch_size = 32
image_height = 224
image_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory="./datasets/shoes/train/",
seed=123,
image_size=(image_height, image_width),
batch_size=batch_size
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='./datasets/shoes/test/',
seed=123,
image_size=(image_height, image_width),
batch_size=batch_size
)
class_names = train_ds.class_names
print(class_names)
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype('uint8'))
plt.title(class_names[labels[i]])
plt.axis("off")
plt.show()
Found 502 files belonging to 2 classes.
Found 76 files belonging to 2 classes.
['adidas', 'nike']

4.检查数据
# 检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 224, 224, 3)
(32,)
5.配置数据集
# 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
6.构建CNN网络
CNN的输入是张量形式的(长、宽、颜色通道 ),例如(224,224,3)。看下面的图输入层要求的长,宽都是224,彩色图片是RGB3颜色通道。这也就解释了上面为啥设置image_height,image_width都为224。
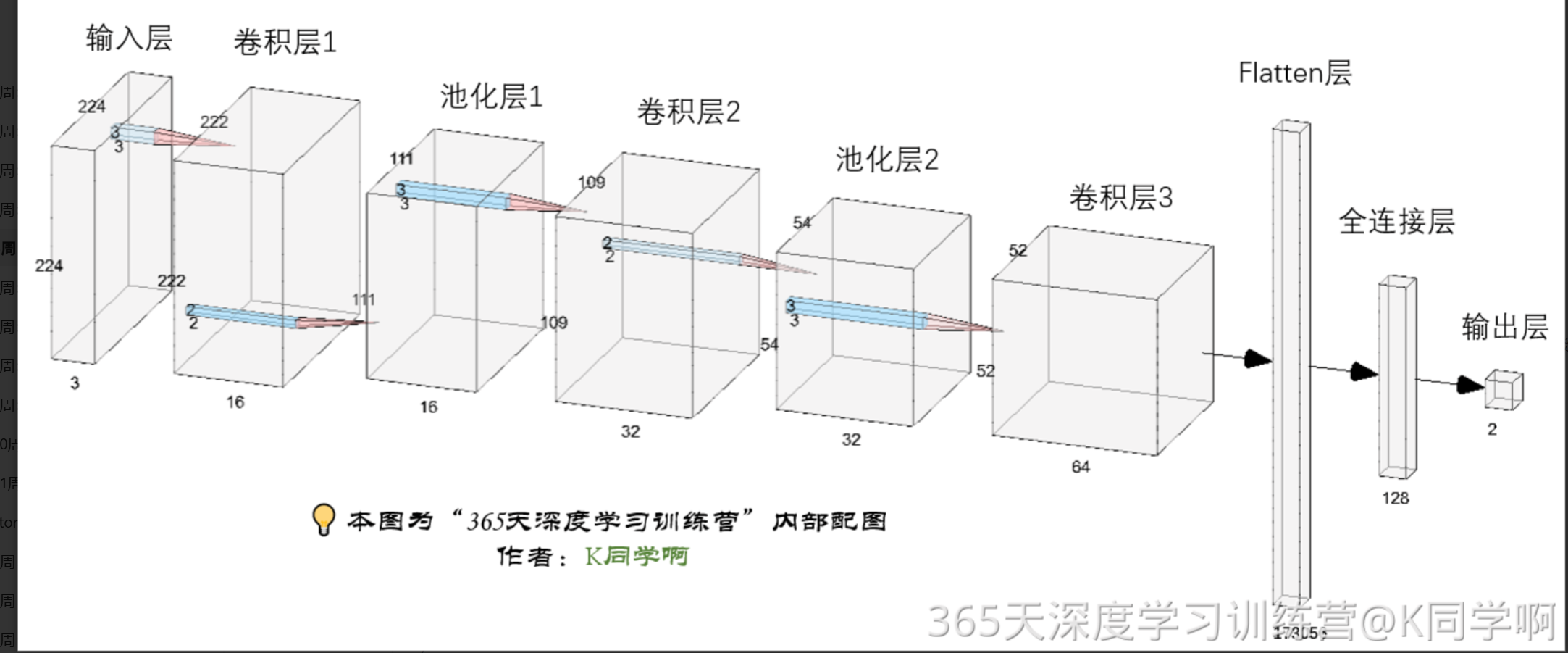
# 构建CNN网络
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(image_height, image_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(image_height, image_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.3), # 防止过拟合
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
tf.keras.layers.Dropout( rate, noise_shape=None, seed=None, kwargs )
使用是防止过拟合,提高模型的泛化能力。
过拟合:模型在训练数据中表现优秀,但在测试数据或者新数据中表现糟糕的情况。
泛化:就是指模型对于未见过的数据上的表现能力
参数:
rate: 0-1之间的小数,让神经元以一定的概率rate停止工作,提高模型的活化能力。
noise_shape:这是一个1维整数张量,表示将与输入进行乘法运算的二值dropout掩码的形状。例如,如果您的输入具有形状(batch_size, timesteps, features),并且您希望dropout掩码在所有时间步长上都相同,则可以使用noise_shape=(batch_size, 1, features)。
seed:随机种子
model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (AverageP (None, 111, 111, 16) 0
ooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Averag (None, 54, 54, 32) 0
ePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
dropout_1 (Dropout) (None, 52, 52, 64) 0
flatten (Flatten) (None, 173056) 0
dense (Dense) (None, 128) 22151296
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22,175,138
Trainable params: 22,175,138
Non-trainable params: 0
_________________________________________________________________
7.训练模型
# 训练模型
initial_learning_rate = 0.1
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate, # 初始学习率大小
decay_steps=10, # 衰减步数,每10步衰减一次,指数函数衰减
decay_rate=0.92, # 学习率的衰减率,决定了学习率如何衰减,通常0-1之间取值
staircase=True # True-阶梯式衰减,False-连续衰减
)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(
optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
epochs = 50
# 保存最佳模型参数
checkpointer = ModelCheckpoint(
filepath="./models/shoes-best-model.h5", # 模型保存位置
monitor='val_accuracy', #
verbose=1,
save_best_only=True,
save_weights_only=True
)
# 设置早停
earlystopper = EarlyStopping(
monitor='val_accuracy', # 被监测的数据
min_delta=0.001, # 在被监测数据中被认为是提升的最小变化
patience=20, # 没有进步的训练轮数,在这之后训练会停止
verbose=1 # 详细信息模式,被callback后显示详细信息的意思
)
# 模型训练
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper]
)
Epoch 1/50
2024-10-11 17:45:39.484537: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8101
2024-10-11 17:45:41.041697: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] INTERNAL: ptxas exited with non-zero error code -1, output:
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
2024-10-11 17:45:42.421090: I tensorflow/stream_executor/cuda/cuda_blas.cc:1614] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
14/16 [=========================>....] - ETA: 0s - loss: 9620.0186 - accuracy: 0.4589
Epoch 1: val_accuracy improved from -inf to 0.50000, saving model to ./models\shoes-best-model.h5
16/16 [==============================] - 8s 59ms/step - loss: 8393.6611 - accuracy: 0.4661 - val_loss: 0.7509 - val_accuracy: 0.5000
Epoch 2/50
16/16 [==============================] - ETA: 0s - loss: 0.7177 - accuracy: 0.4721
Epoch 2: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.7177 - accuracy: 0.4721 - val_loss: 0.6996 - val_accuracy: 0.5000
Epoch 3/50
16/16 [==============================] - ETA: 0s - loss: 0.6997 - accuracy: 0.4920
Epoch 3: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6997 - accuracy: 0.4920 - val_loss: 0.6931 - val_accuracy: 0.5000
Epoch 4/50
16/16 [==============================] - ETA: 0s - loss: 0.6963 - accuracy: 0.5040
Epoch 4: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6963 - accuracy: 0.5040 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 5/50
16/16 [==============================] - ETA: 0s - loss: 0.6976 - accuracy: 0.4920
Epoch 5: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6976 - accuracy: 0.4920 - val_loss: 0.6948 - val_accuracy: 0.5000
Epoch 6/50
16/16 [==============================] - ETA: 0s - loss: 0.6964 - accuracy: 0.4761
Epoch 6: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6964 - accuracy: 0.4761 - val_loss: 0.6936 - val_accuracy: 0.5000
Epoch 7/50
16/16 [==============================] - ETA: 0s - loss: 0.6944 - accuracy: 0.4821
Epoch 7: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6944 - accuracy: 0.4821 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 8/50
16/16 [==============================] - ETA: 0s - loss: 0.6939 - accuracy: 0.4980
Epoch 8: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6939 - accuracy: 0.4980 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 9/50
16/16 [==============================] - ETA: 0s - loss: 0.6941 - accuracy: 0.4841
Epoch 9: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6941 - accuracy: 0.4841 - val_loss: 0.6934 - val_accuracy: 0.5000
Epoch 10/50
16/16 [==============================] - ETA: 0s - loss: 0.6951 - accuracy: 0.4980
Epoch 10: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6951 - accuracy: 0.4980 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 11/50
16/16 [==============================] - ETA: 0s - loss: 0.6962 - accuracy: 0.4721
Epoch 11: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6962 - accuracy: 0.4721 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 12/50
16/16 [==============================] - ETA: 0s - loss: 0.6946 - accuracy: 0.4940
Epoch 12: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 28ms/step - loss: 0.6946 - accuracy: 0.4940 - val_loss: 0.6942 - val_accuracy: 0.5000
Epoch 13/50
16/16 [==============================] - ETA: 0s - loss: 0.6942 - accuracy: 0.4681
Epoch 13: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6942 - accuracy: 0.4681 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 14/50
16/16 [==============================] - ETA: 0s - loss: 0.6949 - accuracy: 0.4920
Epoch 14: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6949 - accuracy: 0.4920 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 15/50
16/16 [==============================] - ETA: 0s - loss: 0.6948 - accuracy: 0.4841
Epoch 15: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6948 - accuracy: 0.4841 - val_loss: 0.6935 - val_accuracy: 0.5000
Epoch 16/50
15/16 [===========================>..] - ETA: 0s - loss: 0.6942 - accuracy: 0.4723
Epoch 16: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6944 - accuracy: 0.4681 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 17/50
16/16 [==============================] - ETA: 0s - loss: 0.6935 - accuracy: 0.4920
Epoch 17: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6935 - accuracy: 0.4920 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 18/50
16/16 [==============================] - ETA: 0s - loss: 0.6935 - accuracy: 0.4801
Epoch 18: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6935 - accuracy: 0.4801 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 19/50
16/16 [==============================] - ETA: 0s - loss: 0.6935 - accuracy: 0.5000
Epoch 19: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6935 - accuracy: 0.5000 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 20/50
16/16 [==============================] - ETA: 0s - loss: 0.6934 - accuracy: 0.4880
Epoch 20: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6934 - accuracy: 0.4880 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 21/50
16/16 [==============================] - ETA: 0s - loss: 0.6941 - accuracy: 0.4721
Epoch 21: val_accuracy did not improve from 0.50000
16/16 [==============================] - 0s 26ms/step - loss: 0.6941 - accuracy: 0.4721 - val_loss: 0.6933 - val_accuracy: 0.5000
Epoch 21: early stopping
结果看到,预设的epochs是50轮,结果在训练中第21轮就早停了,因为val_accuracy一直没有进步。
(三)总结
- 如何调整学习率?
- 优化器怎么选择?
- epochs有什么设置原则?