ElasticSearch基本概念
本文内容参考了田雪松老师编著的《Elastic Stack应用宝典》
对比关系型数据库
- 索引(Index)相当于库
- 映射类型(Mapping Type)相当于表
- 文档(Document)相当于行
- 文档字段(Field)相当于列
索引
Elasticsearch没有引入库的概念,而是将文档的容器直接称为索引(Index)。而这里的索引就是倒排索引,或者更准确的说是一组倒排索引。因为Elasticsearch中所有数据的检索都必须要通过倒排索引来检索,离开了倒排索引文档就相当于不存在。所以从检索的角度来看,文档以倒排索引的形式表现其存在性。
编入索引的信息包括文档ID、词项在字段中出现的频率、词项在字段中的次序、词项在字段中的起止偏移量等信息。
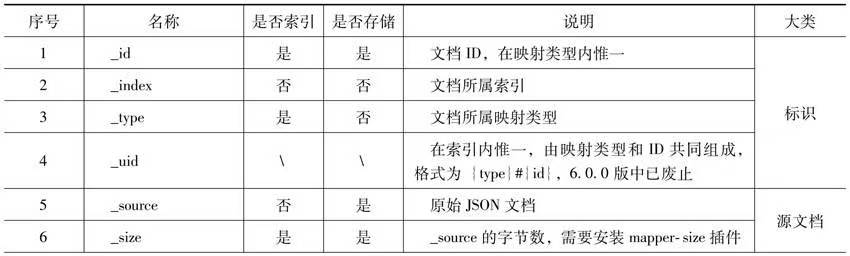
文档ID
文档ID是词项来源文档的编号,是文档的惟一标识,可用于存在性检索。文档ID由文档中的元字段_id保存。
词频
词项在字段中出现的频率一般称为词频(Term Frequency),它可以反映检索结果的相关性,词项在文本中出现的频率越高与检索的相关性也就越高。
词序
词项在字段中的次序(以下简称词序)记录的是某一词项在所有词项中的次序,主要用于短语查询(Phrase Query)。
词项偏移量
词项在字段中的起止偏移量(以下简称词项偏移量),给出了词项在字段中的实际位置,一般用于高亮检索结果。
例如,在“Elasticsearch is a search engine”中,search这个词项在整个文本中只出现了1次,所以它的词频为1;而search之前还有3个词项,所以词序为3(词序起始位置为0);最后,由于search在整个短语中的位置是第19~24之间,所以偏移量为[19,25)
映射类型
映射类型(Mapping Type)是定义文档与索引映射关系的一种方式。
在Elasticsearch版本6之前,一个索引中是可以定义多个映射类型。事实上,映射类型这个概念的引入使得Elasticsearch的这些概念在整体上都变得混乱,Elasticsearch官方已经开始弱化映射类型的概念。
在6.0版本以后映射类型的概念还将延续,但在映射中只能有一个映射类型,而不允许再定义多个映射类型;而在7.0版本以后,映射类型的概念被彻底删除。
索引是存储文档的容器,文档在存储前会做文档分析并编入倒排索引。而文档从全文数据到索引的转变由映射(Mapping)定义,这是另一个在Elasticsearch中非常重要的概念。映射介于文档与索引之间,所以一般是在创建索引时指定文档与索引的映射关系。映射的概念比较难理解,想要理解它就得先理解Elasticsearch中的文档概念。
文档
在Elasticsearch中,数据存储和检索的基本单元是文档。Elasticsearch的文档使用JSON格式。Elasticsearch对外开放的接口以REST为主,而REST本身也是以JSON为通用数据交换格式。可以预先定义好属性和数据类型。为了明确概念,文档的JSON属性为字段(Field),即文档字段,以区别在其他领域中使用的JSON属性。
文档字段
文档字段(Field)可以理解为文档的一个结构化特征。由于文档中的数据分散在各个字段中,所以索引文档肯定都是针对文档字段进行的。在默认情况下,文档的所有字段都会创建倒排索引。这可以通过字段的index参数来设置,其默认值为true,即字段会被编入索引。在编入索引时,一般不会将字段值整体编入。比如text类型的字段来说,它们会被解析为词项后再以词项为单位编入索引。
元字段
文档字段可以分为两类:一类是元字段(Meta-field);另一类是用户定义的业务字段。元字段不需要用户定义,在任一文档中都存在,例如在前面提及的文件ID字段_id就是一个元字段。在名称上它们有一个显著的特征,就是它们都以下划线“_”开头。在学习这些字段时,要从字段索引和字段存储两方面理解它们。有些元字段只是为了存储,它们会出现在文档检索的结果中,但却不能通过这个字段本身做检索,比如_source字段。而有些元字段则只是为了索引,它会创建一个索引出来,用户可以在这个索引上检索文档,但这个字段却不会出现最终的检索结果中,如_all字段。此外,也并不是所有元字段都是默认开启的,有些元字段是需要在索引中配置开启才可使用的。
_type
_id和_uid都是文档的标识符,在版本6之前_id仅在映射类型内惟一,而_uid由_type和_id组成并在索引内惟一;
但在6.0.0版之后,映射类型在索引内仅有一个,所以_uid已经被废止,而_id则在索引内惟一。
_source
尽管在默认情况下所有的字段都会被索引,但是这些字段的原始值是不会被编入索引中的。这意味着用户可以通过某一字段的词项检索到文档,但并不能直接取到这个字段的原始值。因为字段的索引最多只包含上述四项内容,并不包含字段原始值。
为什么字段原始值不会被编入索引呢?这显然还是出于对性能与效率的考量。还是以“Elasticsearch is a search engine”这段文本为例,文档分析后会提取出5个词项并编入索引。如果这5个词项都在索引中保留字段的原始值,那么这段文本就要被保留5次。而对于很多文档来说,它们的文本内容要比这大得多,如果都保留下来这对于存储空间的浪费将是十分惊人的。
尽管单个字段的原始值不会被保存,但索引提供了一个叫_source的字段用于存储整个文档的原始值。_source字段有一个特性,那就是这个字段在默认情况下是不会被索引的,但是每个查询默认都会带着_source字段返回。_source字段保存的源文档信息是在索引文档时以JSON形式传递过来的最原始文档。
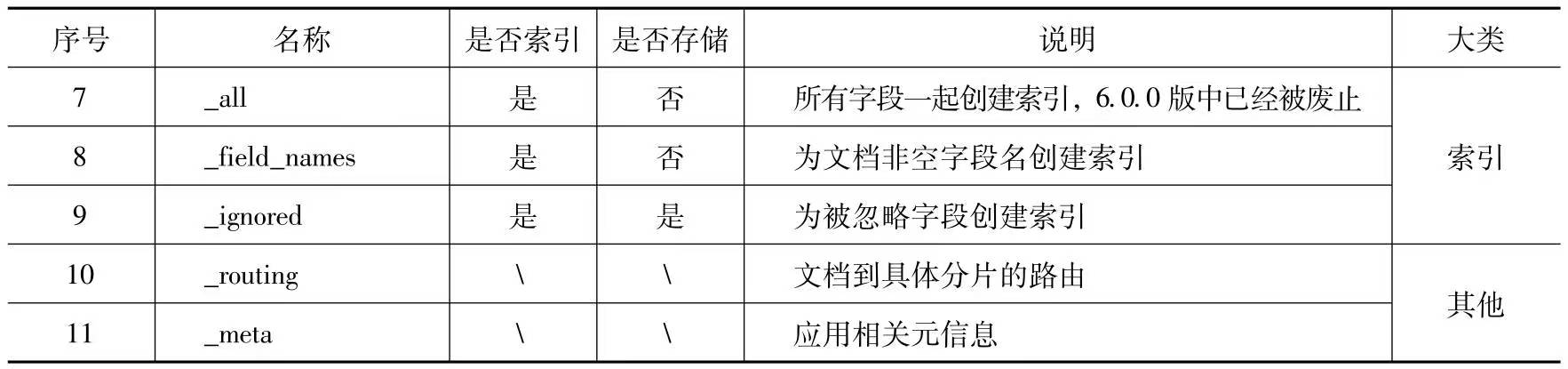
_field_names
_field_names字段用于给所有有值的字段名称做索引,这可以用于检索某一字段是否存在。