统一多模态大模型!PUMA:多粒度策略笑傲图像生成、编辑、修复、着色和条件图像生成和理解六大任务

文章链接:https://arxiv.org/pdf/2410.13861
项目链接:https://github.com/rongyaofang/PUMA


亮点直击
多粒度特征处理: PUMA 能够同时处理粗粒度和细粒度的视觉特征,适应不同任务的需求,如文本到图像生成和图像编辑,解决了现有模型在多样性和精确可控性之间的平衡问题。
统一多模态框架: PUMA 通过统一的多模态大模型框架,无缝集成图像生成与理解,适用于从多样化图像生成到精确图像编辑等多种任务,扩展了多模态模型的应用范围。
两阶段训练策略: 首先微调预训练的扩散模型进行图像解码,然后训练自回归多模态模型生成多尺度图像特征,优化了多任务处理的性能。
广泛的多模态任务适应性: PUMA 通过在语言-视觉数据集上的大规模预训练和指令微调,展示了其在图像理解、文本到图像生成、图像修复等多种任务中的出色表现。

-
a) 图像生成任务中的多样性和可控性权衡:多样化的文本到图像生成需要高多样性和保真度,而条件生成和修剪等任务需要对图像进行高可控性。
-
b) 引入的PUMA是一种统一的多模态大语言模型,可以处理和生成多粒度视觉表示,平衡视觉生成任务的多样性和可控性。它擅长图像理解、多样化的文本到图像生成、编辑、修复、着色和条件图像生成。
总结速览
解决的问题:
现有的多模态大模型(MLLMs)在视觉内容生成方面没有充分解决不同图像生成任务对粒度的需求差异,尤其是从文本到图像生成的多样性需求以及图像编辑中的精确可控性。
提出的方案:
提出了一种名为PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)的模型,旨在通过统一多粒度视觉特征作为MLLMs的输入和输出,优雅地解决不同任务的粒度需求。
应用的技术:
采用了多模态预训练和任务特定的指令微调,将多粒度视觉生成功能融入到统一的MLLM框架中。
达到的效果:
PUMA在广泛的多模态任务中表现出色,能够适应不同视觉任务的粒度需求,向真正统一的MLLM迈出了重要一步。



方法
现有的方法通常仅优化细粒度或粗粒度特征,从而在精确控制和生成多样性之间存在权衡。为克服这一局限性,本文提出了PUMA,一个统一的多粒度MLLM范式。本文的方法能够在统一的MLLM框架中同时处理多个层次的特征粒度,促进跨多种多模态任务的无缝转换。
本文的框架包括三个关键组成部分:图像编码器、基于不同粒度特征的图像解码器集合以及多粒度自回归MLLM。这些组件协同工作,以提取、处理和生成多尺度图像特征,适应各种任务特定的粒度需求。为了优化MLLM,采用了预训练和指令微调的两阶段过程,使其能够执行包括图像理解、生成、编辑和条件图像生成在内的多种任务。
图像编码与多粒度特征提取
统一多粒度范式利用语义图像编码器提取多尺度特征,形成多样化视觉任务处理的基础。采用了CLIP语义图像编码器来处理输入图像 并生成初始的高分辨率特征 ,其中 和 代表最高分辨率特征网格的空间维度, 表示通道维度。在设置中,特征大小为 ,因此最高分辨率特征 有256个视觉tokens。
为了获得多粒度表示,通过连续应用核大小为2、步长为2的二维平均池化来导出较低分辨率特征。
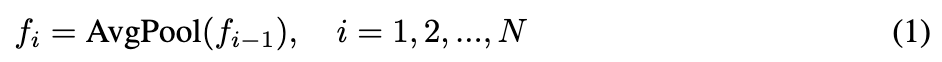
当 是额外粒度层级的数量时,该过程生成一系列具有逐渐粗糙分辨率的特征网格,从保留详细空间信息和局部纹理的细粒度特征,到捕捉物体部分和区域结构的中层特征,再到表示粗粒度语义概念的特征。这些特征分别表示为 , , , 和 ,它们分别具有256、64、16、4和1个视觉token。
多粒度视觉解码
不同粒度的图像特征编码了不同层次的信息。采用基于扩散模型的解码器,因为它们能够灵活处理多尺度特征。在处理粗粒度语义特征时,解码器能够有效地利用它们学习到的图像先验,补充缺失的细粒度信息,并生成多样化且语义对齐的图像。另一方面,在处理细粒度特征时,它们能够准确重构精确的图像细节。这种在不同粒度下生成或重构图像的多样性使基于扩散模型的解码器非常适合多粒度的方法。
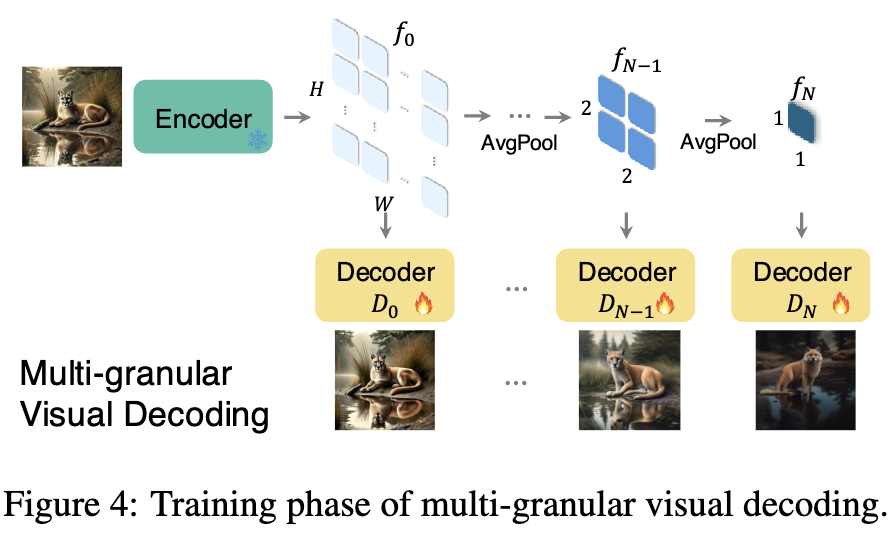
开发了一组专用的基于扩散模型的图像解码器 ,对应于特征尺度 。这些解码器能够在各种粒度层级上进行图像的视觉解码。将每个粒度层级 的图像解码过程公式化为 ,其中 是解码后的图像, 是粒度层级 的特征图, 是扩散过程中的随机噪声向量。
利用了预训练的SDXL模型作为解码框架,并微调这些预训练模型,以根据不同的粒度特征生成或重构图像。通过在SDXL中修改条件输入机制,使其通过交叉注意力接受多粒度特征 ,利用了模型固有的能力来解码连贯的图像。
下图4展示了不同粒度图像解码的训练过程,其中图像编码器被冻结以保留语义属性。
下图3展示了多粒度解码器的视觉解码能力。这些可视化结果显示了在不同粒度下解码图像的保真度,细粒度特征能够生成与原始输入更接近的重构图像,而粗粒度特征则根据输入图像的语义引导生成图像。这验证了本文方法在保留和利用多粒度视觉信息方面的有效性。

该多粒度解码框架与层次化特征提取相结合,为MLLM架构的后续阶段奠定了基础,为后期训练阶段中的多样化视觉任务铺平了道路。
自回归MLLM中的渐进多粒度图像建模
为了利用一个能够适应各种具有不同粒度需求的视觉-语言任务的统一框架,设计了一个自回归MLLM来处理和生成文本tokens及多粒度图像特征。
自回归MLLM,记为 ,逐步处理文本和多粒度图像特征,如下图2所示。模型逐个tokens地处理特征,在每个粒度级别内依次预测每个token,并从最粗的粒度级别 逐渐过渡到最细的粒度级别 。这种方法允许模型在获取更多详细信息时逐步改进其预测。
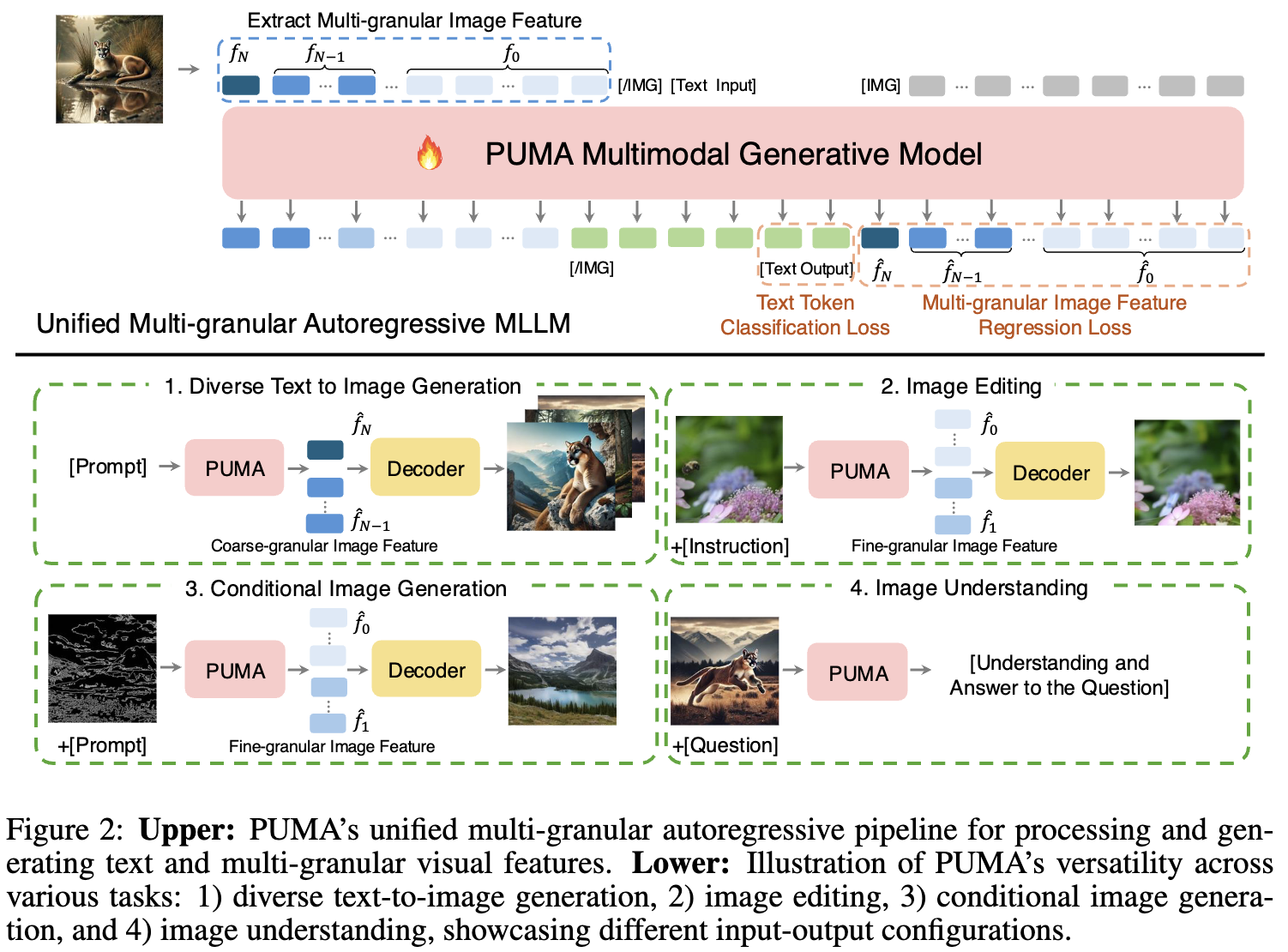
将输入序列构建为文本tokens和来自多个粒度级别的展平图像特征tokens的拼接。该渐进方法使模型能够捕捉不同尺度间的依赖关系,从粗略的全局结构到精细的局部细节。
MLLM通过自回归的下一个token预测目标进行训练,结合了文本和图像的损失。

第一个项表示文本tokens预测的交叉熵损失,其中 是文本tokens。第二个项是图像特征预测的回归损失,其中 和 分别是第 个粒度级别的真实特征tokens和预测特征tokens。 是第 个粒度级别的视觉tokens数量。系数 允许在训练过程中调整每个粒度级别的重要性。
多模态预训练和指令微调
为了展示统一多粒度范式的有效性,为PUMA实施了一个全面的两阶段训练流程:首先是多模态预训练,随后是任务特定的指令微调。这种方法使模型首先获得广泛的多模态能力,然后在后续的指令微调阶段专注于目标视觉语言任务。
多模态预训练:多模态预训练利用了一组多样化的大规模数据集:Laion-2B、Laion-Aesthetics、GRIT、The Pile、OCR-VQA-200K 和 LLaVAR。这些数据集的组合提供了丰富的图文对、文本数据和特定的视觉问答样本。为了增强模型对图文关系的双向理解,采用了一种动态训练策略,随机交替每个图文对的文本生成图像和图像生成文本任务。
指令微调:在预训练之后,进行针对性的指令微调,使模型适应特定的视觉语言任务。为了评估PUMA在不同任务类型上的表现,针对四种任务分别微调了四个模型,每个模型都从预训练检查点初始化。
-
高质量的文本生成图像:利用 Laion-Aesthetics 和 JourneyDB 数据集,专注于生成美观且多样化的图像。
-
精确的图像操作:通过SEED-Edit数据集进行训练,实现准确且可控的图像编辑。
-
条件图像生成:利用 MultiGen-20M 数据集的子集(包括轮廓生成、修复、和着色)使模型具备在特定条件和限制下生成图像的能力。
-
图像理解:通过 LLaVA-OneVision 和 Cambrian 数据集的子集进行微调,以增强模型的图像理解能力。数据集中关于数学/推理以及重复数据被移除。
实验
实验结果如下:首先详细描述了实验设置。再评估了多粒度特征编码和基于扩散的多粒度图像解码器的有效性。随后展示了 PUMA 在多项任务中的多功能性:多样化的文本生成图像、图像编辑、条件图像生成和视觉语言理解。
设置
统一多粒度多模态语言模型 (MLLM) 采用 LLaMA-3 8B 作为语言模型骨干,使用 CLIP-Large (224×224 输入) 作为图像编码器。图像解码器则初始化自预训练的 SDXL 模型。
多粒度视觉解码
通过编码器生成的多尺度特征和专门的视觉解码器评估模型的多粒度视觉解码能力。目标有两个:一是使用细粒度特征(如 和 )实现精确的重构,二是使用粗粒度特征(如 和 )实现高多样性的语义引导图像生成。需要指出的是,本小节中验证了多粒度编码器和解码器 (前面图4),并未使用多模态语言模型 (MLLM)的部分。
细粒度图像重构
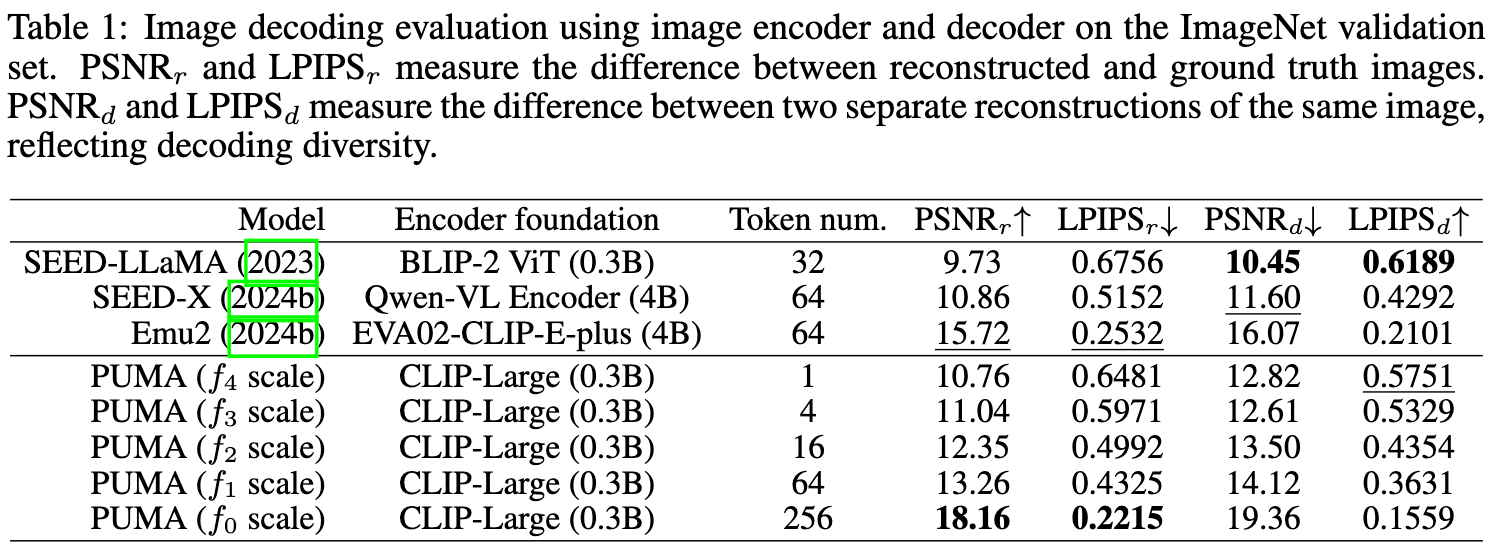
细粒度图像重构对于保持图像细节至关重要,但对模型如 SEED-LLaMA、SEED-X 和 Emu2 而言是个重大挑战。SEED-LLaMA 和 SEED-X 在详细重构上表现不佳,限制了它们在不使用如条件图像输入(SEED-X 中使用的)等额外技术的情况下精确操作图像的能力。Emu2 尝试通过将其图像编码器扩大至40亿参数来改进重构。本文的方法则通过更高效的架构实现了优越的重构质量。
这里使用了 CLIP-Large 编码器(0.3亿参数),其参数量仅为 Emu2 的十分之一,并在细粒度层次上实现了256个tokens的图像嵌入。下表1展示了使用 级别特征在 ImageNet 验证集上实现的18.16 PSNRr 和 0.2215 LPIPSr 重构结果,这些结果优于 Emu2 的重构性能,并显著超越了 SEED-LLaMA 和 SEED-X(未使用条件输入)。
下图5也直观展示了本文方法在重构质量上的优越性。

语义引导的生成
虽然细粒度重构对于精确图像操作至关重要,但如文本生成图像等任务则需要在语义准确性和输出多样性之间取得平衡。本文的方法利用粗粒度特征(如 )实现语义引导的图像生成,同时保持输出多样性。为了量化这种语义引导的多样性,对相同的图像输入进行两次解码,使用不同的随机种子生成两张图像,并测量它们的差异,分别以 PSNRd 和 LPIPSd 表示。表1展示了不同视觉解码模型和特征尺度下的多样性结果。值得注意的是, 和 级别解码器比 SEED-X 和 Emu2 的解码器生成了更多样的样本,同时仍然保留了输入的核心语义,正如上图5所示。这证明了本文的方法在任务如文本生成图像中有效地平衡了语义准确性与生成多样性。
多样化文本生成图像
本文的方法可以通过利用粗粒度特征( 和 级别)生成多样化的输出。这一能力使得本文的模型能够生成与文本条件相对应的多样化图像。下图6展示了在使用固定文本提示并利用 和 特征尺度生成图像时,本文的模型实现了高生成多样性。

结果还表明, 级别的输出表现出更高的多样性,而 级别的结果则显示了更好的一致性。相比之下,Emu2 的生成结果显示出较低的多样性。为进行定性评估,下图7展示了模型在不同提示词下生成的文本生成图像。

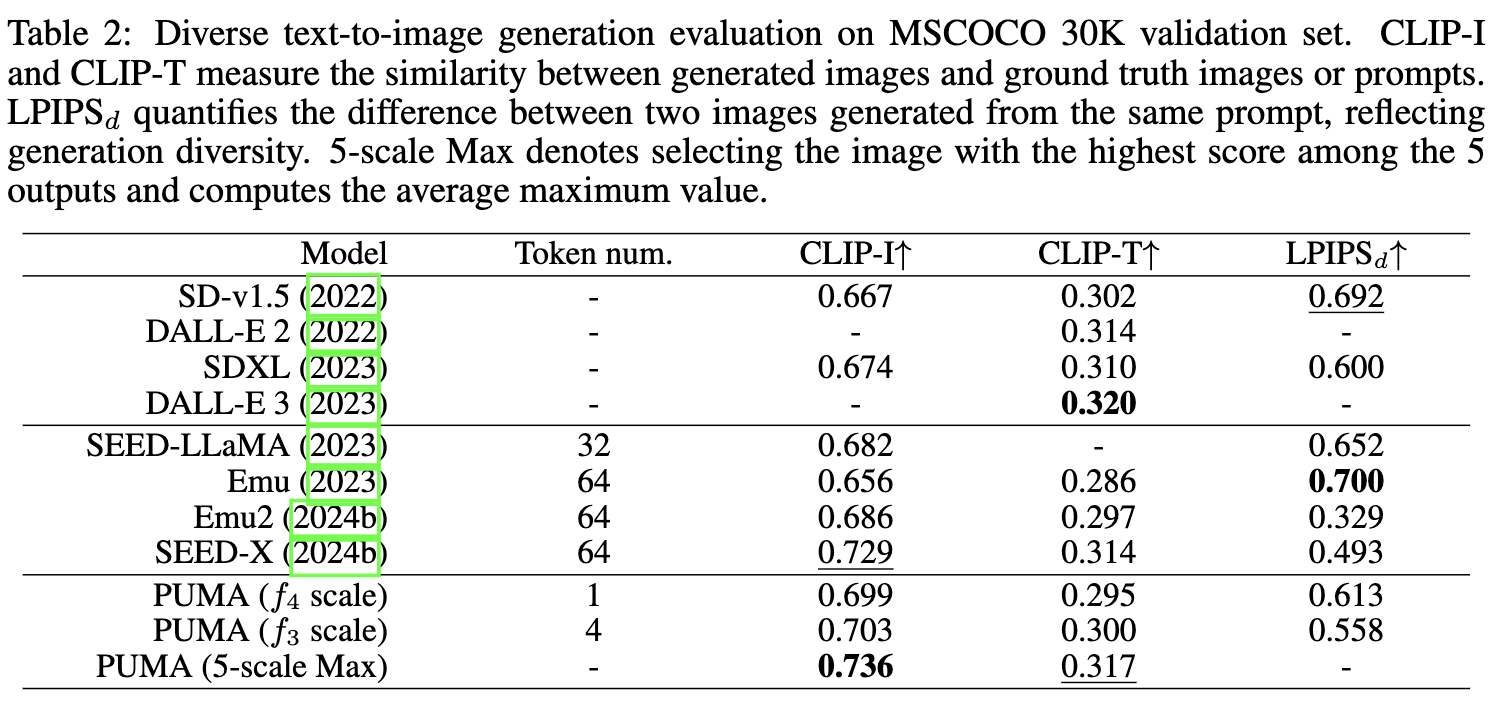
为定量评估,在 MSCOCO 30K 验证数据集上评估了模型,并在下表2中展示了 CLIP-I、CLIP-T 和 LPIPSd 指标,前两者衡量一致性,而 LPIPSd 衡量生成多样性。与近期工作相比,本文的模型在生成质量、多样性和提示词相关性上表现出了优越的性能。
图像编辑
为了评估PUMA的图像编辑能力,在Emu-Edit测试基准上进行了评估。结果显示在下表3中,包括CLIP-I、CLIP-T和DINO得分。CLIP-I和DINO得分衡量模型保留源图像元素的能力,而CLIP-T反映输出图像与目标标题之间的一致性。
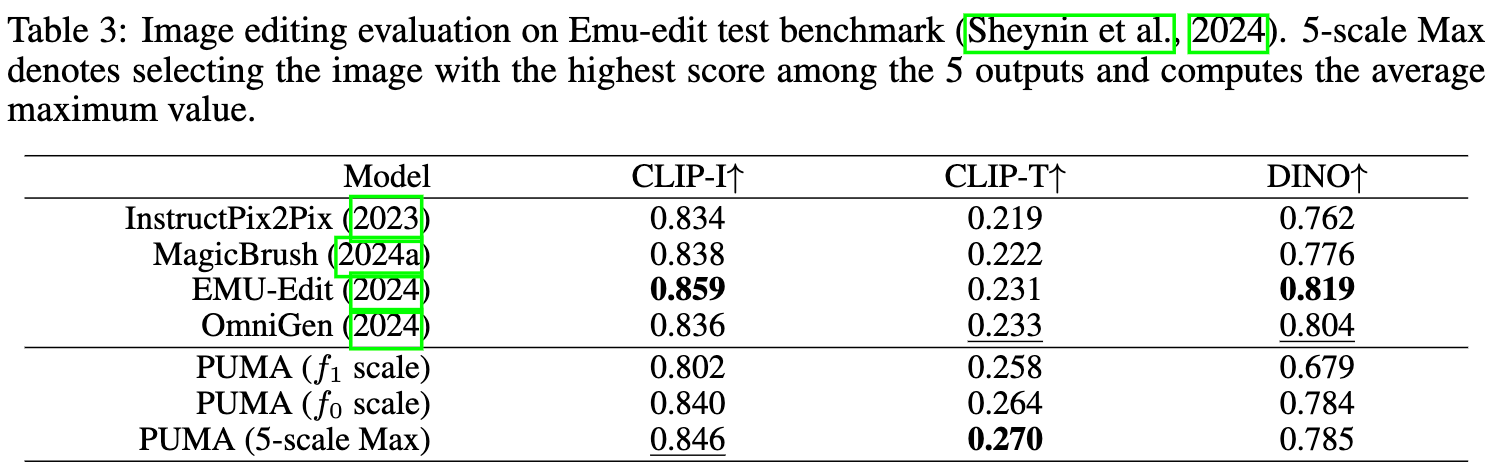
发现表明,PUMA展示了强大的保留能力,仅次于当前的最先进模型EMU-Edit。值得注意的是,PUMA在CLIP-T得分上显著更高,甚至超越了最先进模型,这表明其在编辑图像与目标标题之间的对齐能力更强。图8中的可视化结果展示了PUMA在图像操控任务中的有效性。

条件图像生成
使用来自multigen-20M数据集中一部分任务(包括边缘到图像、修复和上色)来训练PUMA的条件图像生成能力。前面图8展示了这些任务的结果,其中特征尺度的输出在保留图像细节方面表现最佳,尤其是在修复和上色任务中。而尺度则提供了更好的整体视觉保真度,但生成多样性有限。
图像理解
在多个MLLM基准(如MMB、MME、GQA、VQAv2、POPE和Vizwiz)上评估了PUMA的图像理解性能。该评估的结果见下表4。尽管PUMA的参数数量相对较少(8B参数),且使用了224 × 224分辨率的图像编码器,但它在图像理解性能上展现出竞争力,并且在许多情况下优于其他统一理解和生成模型。
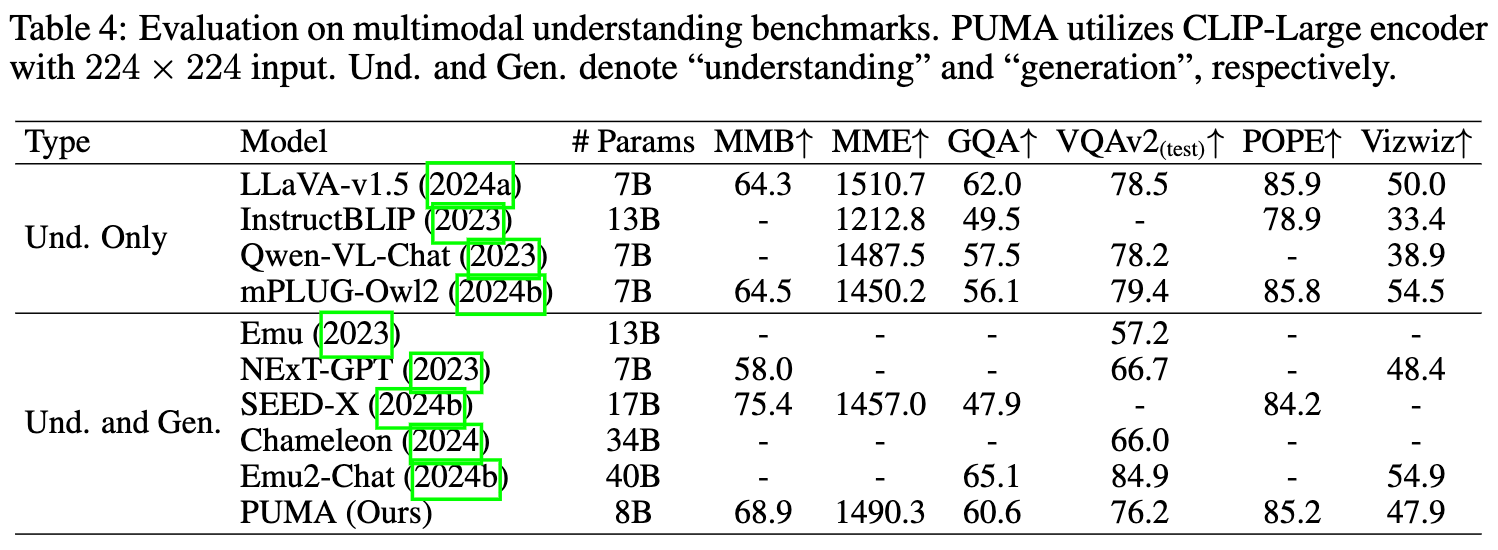
值得注意的是,在某些指标上,PUMA的表现甚至超过了一些仅进行理解的基线模型。这种性能可以归因于PUMA使用多粒度连续视觉tokens作为输入到MLLM。关于不同尺度特征输入对图像理解任务影响的详细消融研究可在附录中找到,为PUMA的多粒度策略的有效性提供了进一步的见解。
消融研究
本文进行了消融研究,以分析特征尺度选择对需要精细控制的任务的影响。下图9比较了在图像编辑和上色任务中使用和特征尺度生成的输出结果。结果显示,尺度特征无法保留关键的图像细节,而尺度特征则保留了精确操控任务所需的细粒度信息。

结论
本文介绍了PUMA,一种新的统一多粒度MLLM,它整合了视觉生成和理解中的各种粒度任务。通过利用多粒度表示,PUMA有效地解决了图像生成任务中平衡多样性和可控性的挑战。本文的方法在多种视觉任务中展示了优越的性能,包括多样化的文本到图像生成、图像编辑、修复、上色、条件生成和理解。PUMA在单一框架内适应不同粒度需求的能力标志着MLLM能力的重大进步。这项工作为更通用和强大的多模态人工智能系统开辟了新可能性,助力实现多模态领域的人工通用智能的更广泛目标。




参考文献
[1] PUMA: Empowering Unified MLLM with Multi-granular Visual Generation