【李宏毅】-各种各样的self-attention
如何使自注意力机制变得高效?
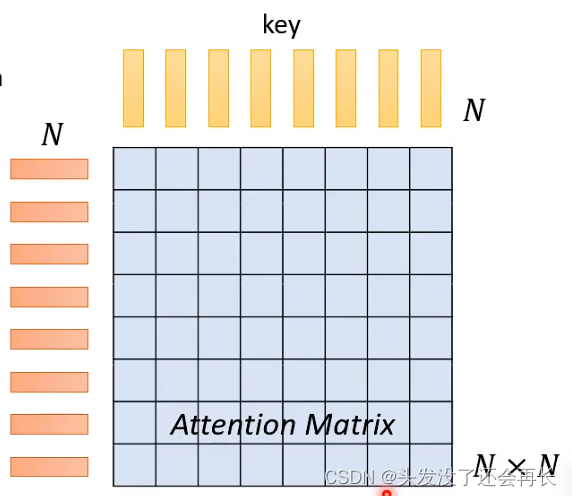
在这篇博客中有讲关于注意力机制,其中,我们需要计算三个矩阵——Q,K,V ,如果序列长度为N,那么三个矩阵的大小都是NxN,这将导致注意力机制计算量很大!
跳过那些由人类已有知识可以知道的矩阵单元的计算
fill in some values with human knoeledge!
1.Local Attenetion / Truncated Attenetion
只计算周围邻居的注意力,其他的设置为0
2.Stride Attention
看N跳邻居,这个N是自己定义的
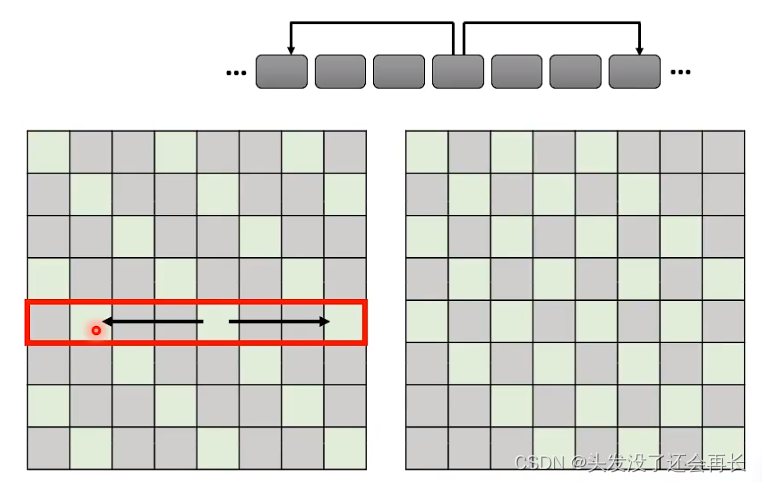
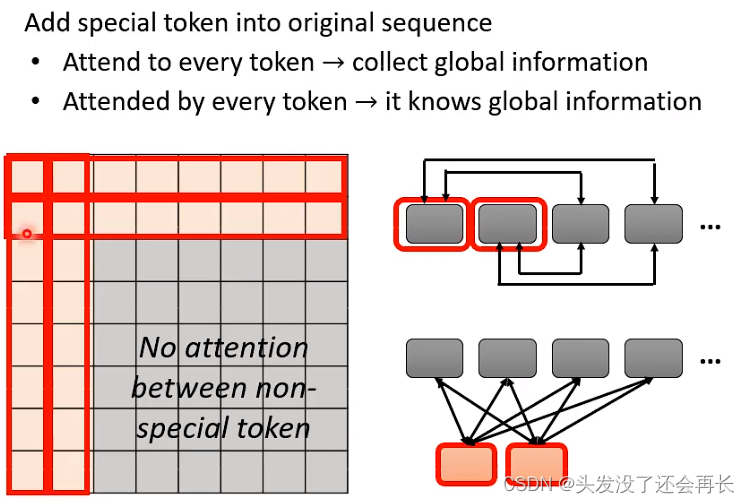
3.Global Attention
选择一些token作为special token,可以从原来的句子中直接选一些token,也可以是外部知识中的token作为special token。
这些special token会与其他所有的token计算attention,即,既会attend,也会被attend。
如果选择前两个token作为special token,计算的结果如上图矩阵所示。
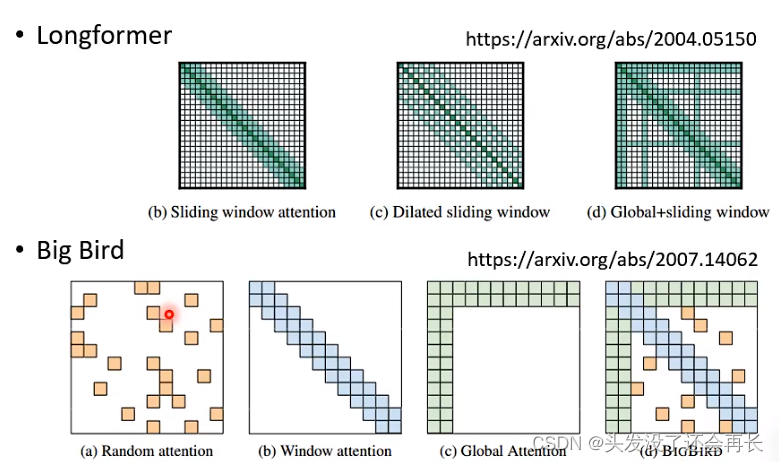
如何选择这些方法呢?
小孩子才做选择。。。
differend heads use different patterns!!!

许多的选择
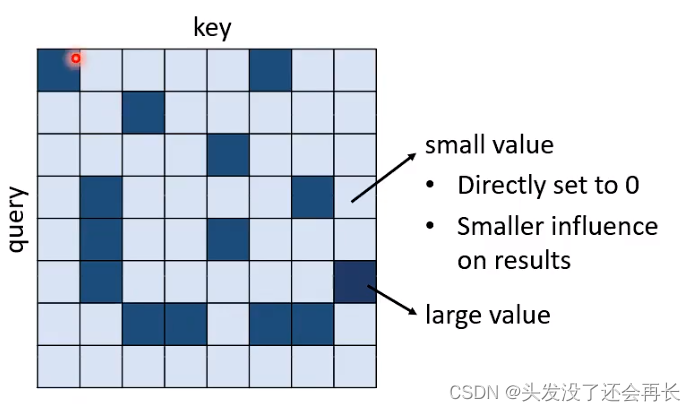
只关注重要的部分
直观的想法是,我们只计算那些attention值可能会很大的部分,而值很小的部分我们不再计算
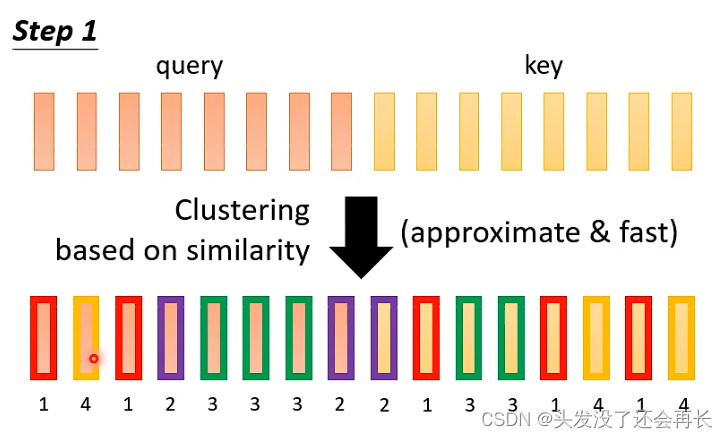
如何快速判断出small value和large value?
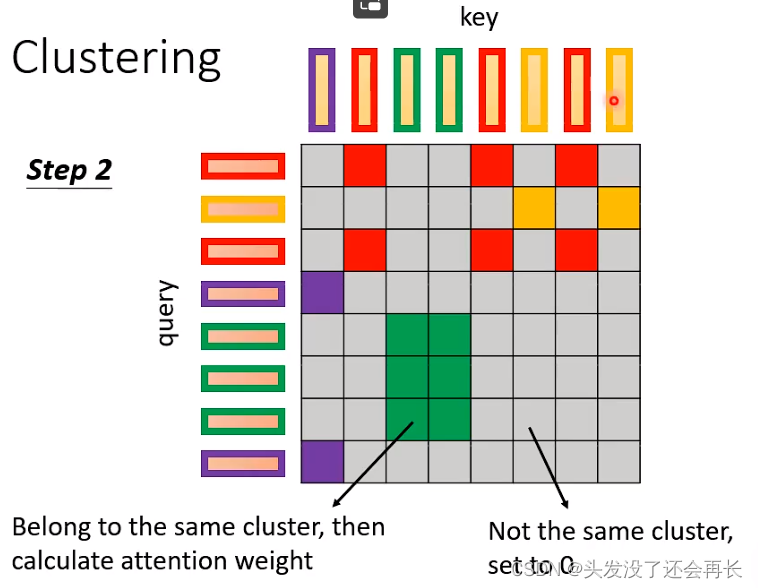
Clustering
先计算每一个vector的类别,进行分类。
当query和key对应的vector的类别是相同的,就计算value,否则,置为零。
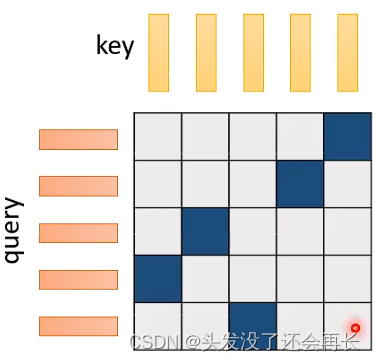
能否直接让model去学习判断是否计算attention呢?
在此之前讲述的方法,都是人类来判断是否需要计算attention,我们需要一个方法,让model学习判断。
Leanable Patterns——Sinkhorn sorting Network
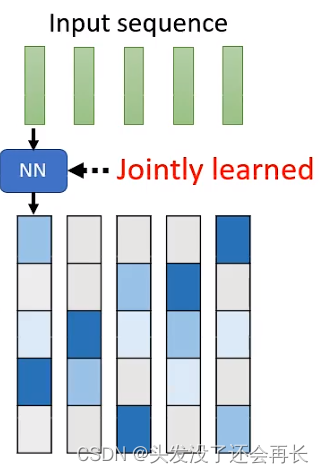
首先,我们定义key和query矩阵的部分值为1,部分值为0,为1的部分是需要计算attention的,而为0的部分是不需要计算attention的,在此之前,都是认为觉得是否需要计算,但是我们想通过下面的方法让model去学习。
然后,我们让输入的sequence都经过一个neural network,得到长度为N的vector(N与注意力矩阵相同),最后,输入的sequence就得到了一个大小和注意力矩阵相同的矩阵。我们让这个网络自己去学习,逐渐向我们想要的只有值为0和1的矩阵靠近。
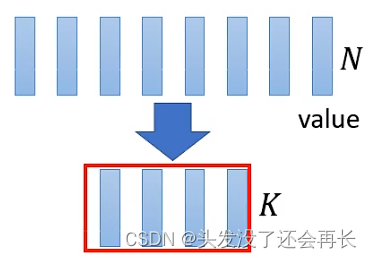
我们真的需要NxN的attention matrix吗?
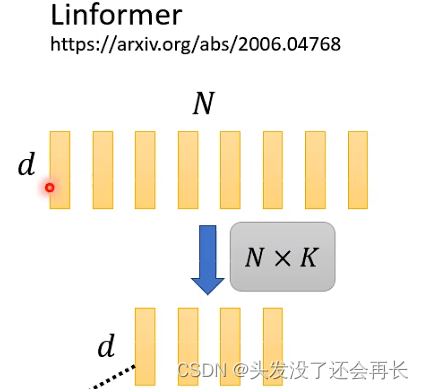
Linformer做的事情是,只计算一个小的matrix。
首先,从N个key中,只选择K个Key
同样,从N个value中,只选择K个value然后,计算这K个value和K个Key,来得到一个小的矩阵
但是,query的vector是不能减少的,因为query的数量对应这output的数量 。
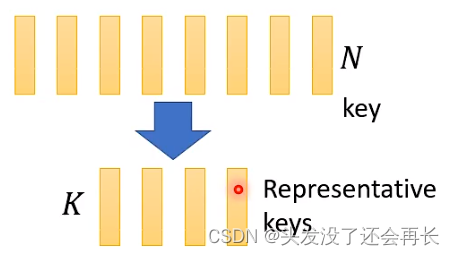
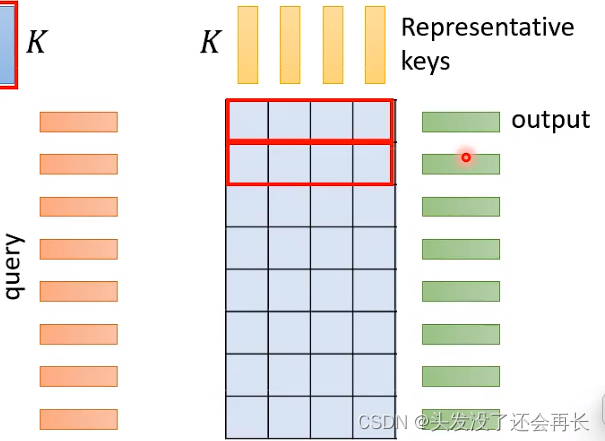
如何选择K个key和K个value
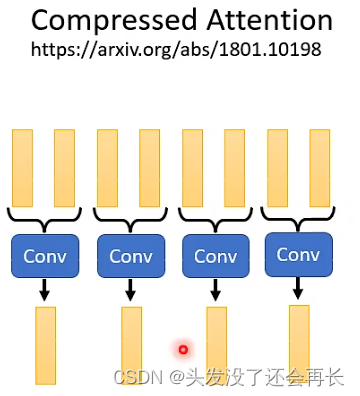
- Compressed Attention
使用CNN
- Linformer
使用线性计算用dxN的矩阵,乘上一个NxK的矩阵