密集向量(Dense Vectors):最大化机器学习中数据的潜力

机器学习得把数据弄得适合算法处理才行,比如通常得把那些原始数据转换成数值向量,就是那种高维的数组。这些向量,不管是稀疏的还是密集的,都是机器学习算法里头的大块头。
说到密集向量(Dense Vectors),这可是把复杂数据转换成高维数值表示的基础。每个向量里的元素都有具体的数值,每个数值都对整个向量的意义有影响。这跟稀疏向量(Sparse Vectors)不一样,稀疏向量里头大部分是零,只记录那些非零的元素和它们的位置。但密集向量就不一样,它不省略任何元素,每个位置的数值都很重要。也就是说,稀疏向量主要是用零来填充的,关注的是元素的缺失,但密集向量就紧凑多了,能提供更丰富的信息。

这篇文章就来讲讲密集向量,看看密集向量比稀疏向量好在哪儿,以及它们在各个领域的机器学习算法里是怎么被广泛使用的。
理解密集向量
机器学习里的密集向量,你可以把它想象成一个数组,里面每个位置的数字都挺重要的。比如说,单词"king",它可能对应一个三维的密集向量,像[0.2, -0.1, 0.8]这样。这个向量里的每个数字,比如0.2、-0.1、0.8,都是从数据里面学来的,代表了"king"这个词的语义和上下文特征。这和那种大部分是零的稀疏向量不一样,密集向量里的每个数字都是有含义的。
数学上说,这些密集向量是待在高维空间里的。你可以在这些向量上做加法或者点积这样的操作,这样就能发现数据之间的联系。在这个大空间里,密集向量能帮我们精确地测量出两个东西有多像或者差多少,这对做聚类、分类和回归这些任务特别有用。比如,那个"king - man + woman = queen"的向量操作,就是靠密集向量才能做到的。
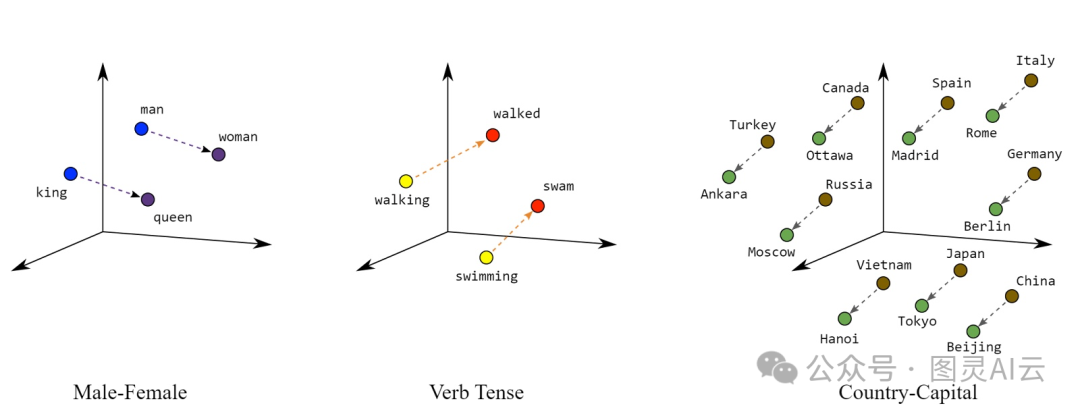
图:密集向量可以捕捉各种语义关系,来源:Google Developers
密集向量就是把那些复杂的数据转换成一种丰富、详细的格式,这样人工智能模型处理起来就轻松多了。无论是分析图片里的复杂图案,还是预测聊天机器人接下来会说啥,密集向量都能让AI系统变得更聪明、更懂你。
在计算机视觉这块,有些模型,比如视觉变换器(ViT),就是用密集向量把图像和文字都编码到同一个向量空间里,这样就能匹配到相似度超高的图像和文字。
在自然语言处理(NLP)领域,像Word2Vec这样的技术,就是把单词转换成密集向量。所以,像"king"和"queen"这样的词,在向量空间里的位置就挨得挺近的,这就能准确地反映出它们之间的语义关系。BERT这个模型做得更进一步,它能生成考虑到上下文的嵌入向量。比如,"bank"这个词在"river bank"和"bank account"里的意思不一样,BERT就能通过不同的向量来捕捉这种上下文的含义,这对于做情感分析或者语言翻译这些任务来说超级重要。
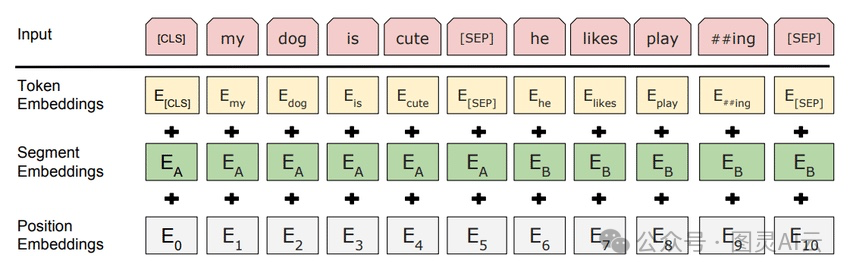
图:BERT嵌入利用密集向量转换文本输入,来源:BERT论文
应用和用例
密集向量真的在改变AI领域的游戏规则。比如说,在文本分类这块,Google的T5模型就用上了密集向量,这让搜索结果和对语言的理解都更精准了。还有,在生成文本的时候,像OpenAI的GPT-4这样的工具,就是用它神经网络处理过的密集向量来理解和创造那些细腻的文本内容。
在推荐系统里,密集向量也是大显身手,它让系统能在同一个向量空间里代表用户和项目,这样就能算出它们之间的相似度,然后根据用户的喜好和项目的特点来推荐产品。举个例子,Spotify就是用密集向量来定制个性化的音乐播放列表的。
要优化AI模型里的密集向量嵌入,有几个好办法。一个是降维,用PCA这样的方法可以减小向量的大小,同时保留重要的信息,还能提升计算效率。另一个是向量归一化,就是把向量的长度统一化,这对于那些依赖距离计算的模型特别关键。
还可以微调嵌入,让它们更适合特定的任务,这在特定领域的上下文中尤其有效。这里可以用迁移学习,就是把预训练的嵌入调整到新数据上,这样可以低成本、快速地提升模型的准确性。
不过,计算效率的挑战还是挺大的,特别是在处理高维向量和大型数据集的时候。这时候,高效的算法和向量数据库就能派上用场了。虽然密集向量比稀疏向量更好地解决了数据稀疏性的问题,但还是要确保模型能专注于相关的特征,避免过拟合。像dropout《一文了解:LLM Dropout》和正则化这样的技术,在这种情况下就很有用了。
未来趋势和创新
AI和机器学习的最新趋势显示,我们在用密集向量这方面取得了挺大的进步。我们现在看到的这些创新的嵌入技术,让向量的表达能力更强了。比如,从Word2Vec这种静态模型发展来的上下文和动态嵌入,能更精确地捕捉语言的微妙之处。
像BERT、GPT这样的变换器模型,彻底改变了我们对密集向量在理解上下文和语义上的认识。
将来,我们可能会看到更复杂的嵌入技术,它们不仅能捕捉语言的细微差别,还能整合多种数据,比如文本、图像和音频。这样我们对复杂数据集的理解就会更深入、更全面。而且,未来的密集向量模型可能在跨领域和语言的知识转移方面做得更好,这对于创建需要更少特定领域训练数据的更通用的AI系统来说,是向前迈出的一大步。
另外,如果能在不丢失重要信息的情况下减少密集向量的维度,那AI模型的效率就会更高,也能在资源有限的环境中使用。
密集向量已经成为人工智能的基石,大大提高了机器学习解决方案的效果。这些向量能捕捉数据中的复杂模式和细微差别,让我们在从自然语言处理到医疗保健分析等各个领域有了更全面的理解。它们在推动创新和促进更精细的AI算法方面的作用,是绝对不能忽视的。
对于想加强自己AI能力的朋友来说,整合密集向量嵌入非常关键。利用这项技术,我们可以从那些原始、混乱的数据中提取出更深入的见解,把我们的项目带到一个新的水平。
参考:
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(https://arxiv.org/abs/1810.04805)
-
https://developers.google.com/machine-learning/guides/text-classification/step-3