51c大模型~合集4
我自己的原文哦~ https://blog.51cto.com/whaosoft/11500102
#AutoGPT
爆火AutoGPT进阶版来了:定制节点、多智能体协同
当然,下一代 AutoGPT 仍是开源的。
还记得去年 AI 大牛 Andrej Karpathy 大力宣传的「AutoGPT」项目吗?它是一个由 GPT-4 驱动的实验性开源应用程序,可以自主实现用户设定的任何目标,展现出了自主 AI 的发展趋势。
一年多的时间,该项目的 GitHub 星标总数已经超过了 16 万,足可见其持续受欢迎的程度。
GitHub 地址:https://github.com/Significant-Gravitas/AutoGPT
昨日,项目作者在社媒 X 上宣布了下一代「AutoGPT」的到来,目前是 Pre-alpha 版本。与前代相比,下一代「AutoGPT」让构建、运行和共享 AI 智能体变得比以往任何时候都更容易,同时可靠性也大大提升。
图源:https://x.com/SigGravitas/status/1812803289739633018
作者展示了如何使用下一代「AutoGPT」快速构建、部署并使用 Reddit 营销智能体,可以自动回复评论,执行其他复杂任务。新系统不再像初版「AutoGPT」那样不可靠和低效。
当被问到该项目是否可以构建多智能体驱动的应用程序时, 作者给出了肯定回答并表示这是构建该项目的重要原因。
现在,你可以设计一个图表,让多个专家智能体协同解决问题。SubGraphs 也即将发布,可以帮助简化复杂图表的处理。
该项目还可以自定义添加节点,并且手动编写新块(下文提到的关键特性)非常简单。作者发现,这方面 Claude 做得非常出色,可以完美地创建自定义块。
当然,该项目的两个主要组件(即下文提到的 Server 和 Builder)可以在不同的机器上运行。
不过,对于下一代「AutoGPT」,作者承认它仍处于非常早期的阶段,存在缺陷且比较基础,但还是希望从一开始就与大家分享并开源出来。
主要组件和关键特性
该项目具有以下两个主要组件,分别是后端的 AutoGPT Server 和前端的 AutoGPT Builder。其中 Server 负责创建复合多智能体系统,将 AutoGPT 智能体和其他非智能体组件用作其原语(primitive)。
- AutoGPT Server (Backend):
- https://github.com/Significant-Gravitas/AutoGPT/tree/master/rnd/autogpt_server
- AutoGPT Builder (Frontend):
- https://github.com/Significant-Gravitas/AutoGPT/tree/master/rnd/autogpt_builder
设置和运行 Server 和 Builder 的具体步骤如下:
- 导航到 AutoGPT GitHub 存储库;
- 单击「代码」(Code)按钮,然后选择「下载 ZIP」;
- 下载后,将 ZIP 文件解压到你选择的文件夹中;
- 打开解压的文件夹并导航到「rnd」目录;
- 进入「AutoGPT Server」文件夹;
- 在「rnd」目录中打开一个终端窗口;
- 找到并打开 AutoGPT Server 文件夹中的 README 文件;
- 将 README 中的每个命令复制并粘贴到你的终端中(重要提示:等待每个命令完成后再运行下一个命令);
- 如果所有命令运行均无错误,请输入最后一个命令「poetry run app」;
- 在终端中看到服务器正在运行;
- 导航回「rnd」文件夹;
- 打开「AutoGPT builder」文件夹;
- 打开此文件夹中的 README 文件;
- 在终端中运行以下命令:
npm installnpm run dev
Once the front-end is running, click the link to navigate to localhost:3000.- 前端运行后,单击链接导航到「localhost:3000」;
- 单击「构建」(Build)选项;
- 添加几个块来测试功能;
- 将块连接在一起;
- 单击「运行」;
- 检查你的终端窗口。此时应该看到服务器已收到请求、正在处理请求并已执行请求。
按照以上步骤,你就可以成功地设置并测试 AutoGPT。
视频来源:https://github.com/Significant-Gravitas/AutoGPT/tree/master/rnd/
除了两个主要组件外,下一代「AutoGPT」的关键特性是使用「块」(Blocks)来构建智能体。你可以将一些高度模块化的功能结合起来,创建自定义行为。
目前,项目已经为 Reddit 发帖、Discord 消息发送和维基百科摘要获取等操作提供了相应的块。同时在设计时追求易创建和使用。以下是维基百科摘要获取的块示例:
class GetWikipediaSummary(Block):
class Input(BlockSchema):
topic: str
class Output(BlockSchema):
summary: str
def **init**(self):
super().__init__(
id="h5e7f8g9-1b2c-3d4e-5f6g-7h8i9j0k1l2m",
input_schema=GetWikipediaSummary.Input,
output_schema=GetWikipediaSummary.Output,
test_input={"topic": "Artificial Intelligence"},
test_output={"summary": "Artificial intelligence (AI) is intelligence demonstrated by machines..."},
)
def run(self, input_data: Input) -> BlockOutput:
response = requests.get(f"https://en.wikipedia.org/api/rest_v1/page/summary/{input_data.topic}")
summary_data = response.json()
yield "summary", summary_data['extract']作者表示,这仅仅是个开始,未来还将添加更多块,并改进 UI,大幅提升整体体验和功能。
#PROVER-VERIFIER GAMES IMPROVE LEGIBILITY OF LLM OUTPUTS
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
如果 AI 模型给的答案一点也看不懂,你敢用吗?
随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。
获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。
对于大型语言模型来说,我们也可以采用类似的方法。
不过,在采用这种方法时,确保语言模型生成的是易于理解的文本,这件事非常重要,尤其是在处理数学、编码这样的复杂任务时。
如下图所示,你让 AI 写一个快速排序算法,AI 很快就写出来了,而且答案很简洁。但不会写代码的你要怎么判断 AI 写得对不对呢?
OpenAI 在一篇最新的论文中研究了这个问题。
- 论文标题:PROVER-VERIFIER GAMES IMPROVE LEGIBILITY OF LLM OUTPUTS
- 论文链接:https://cdn.openai.com/prover-verifier-games-improve-legibility-of-llm-outputs/legibility.pdf
他们发现,如果以「得到正确答案」为目标,要求大语言模型生成答案,它们给出的答案可能会很难懂。人类评估员在判断这些答案时,犯错的可能性会加倍。
所以他们的目标是在训练高级语言模型的过程中,让它们生成那些较简单的模型也能够轻松验证的文本。他们发现,这样的文本不仅对简单模型友好,对于人类来说也更可读。
那么,具体是怎么实现的呢?这还要提到 2021 年的一篇论文 ——「Learning to Give Checkable Answers with Prover-Verifier Games」。在这篇论文中,Cem Anil 等人提出了一个名为「Prover-Verifier Games(证明者 - 验证者博弈)」的博弈论框架。该框架由两个相互竞争的学习者组成:一个可信的验证者(Verifier)网络试图选择正确的答案,另一个更强大但不可信的证明者(Prover)网络试图说服验证者接受特定的答案,而不管其正确性如何。该框架的目标是从博弈中产生一个可靠的证明协议。
OpenAI 在这项新研究中借鉴了这个框架,让两个大模型(较强的为证明者,较弱的为验证者)互相博弈,直到二者达到一种平衡。此时,证明者给出的答案既有一定的可读性,又保持了合理的正确性。
OpenAI 表示,通过提高模型输出的可读性,可以使人工智能的应用更加有效和可信,这对于需要精确沟通的各个领域都是有益的。
值得一提的是,这篇论文来自 OpenAI 的超级对齐团队,其中几位作者在今年早些时候已经离开 OpenAI,团队也已经分崩离析。其中一位作者透露,这是该团队的最后一篇论文。
一个直观的例子
为了提高模型输出的可读性,OpenAI 优化了一些小学数学问题的思维链(CoT),让它能够被较弱的模型理解。举例如下:
问题:肖娜(Shawna)的父亲的年龄是肖娜的五倍。肖娜现在的年龄是阿莉娅(Aliya)的三倍。如果阿莉娅 3 岁,那么肖娜的父亲多少岁?
这么做的目的是为了验证经过这种训练的模型,它的输出是否更加直接易懂。
这种方法在只对训练集做了一些优化的情况下,让模型的性能提升了 50%。同时,模型输出的答案也更好懂了,这也帮助需要评估这些答案正确性的人类用户更准确地做出判断。OpenAI 认为,进一步缩小可读性强的模型和能力强的模型之间的性能差距,是未来对齐研究中一个关键的目标。
「证明者」和「验证者」是怎么在训练中博弈的?
为了激励强力模型(证明者)生成可读性更强的文本,研究者采用了一种训练方案,要求强力模型生成的答案能够被较弱的模型(验证者)轻松验证。具体来说,他们使用了 GPT-4 系列中的大模型和小模型。它们在预训练数据量上相差约三个数量级。它们都接受了一些基于人工标注的数学推导训练,但未经过广泛的后训练。
首先,研究团队让证明者模型尝试解决一系列数学问题。由于证明者模型自身可能出错,它生成的一些答案可能不正确。接下来,他们将这些答案交由验证者模型进行检验,并在以下两个阶段之间进行多轮的交替验证:
- 「验证者」训练:研究团队训练较弱的「验证者」模型,验证「证明者」给出的答案是否正确。
- 「证明者」训练:研究团队指示性能较强的「证明者」模型扮演「有用」或「狡猾」的戏份。
- 当「证明者」被设定为「有用」时,研究团队将奖励「验证者」打分高的正确答案。
- 当「证明者」被设定为「狡猾」时,研究团队反而奖励「验证者」打分高的错误答案。
研究团队发现,最初,狡猾的「证明者」能够轻松生成让「验证者」信服的错误答案。然而,这些错误答案将会进入下一轮的「验证者」训练中,相同的漏洞在下一轮中,将不再具有说服力。因此,「证明者」将被迫在每一轮中探索不同的策略。
当狡猾的「证明者」再也无法生成让「验证者」信服的错误解决方案时,训练宣告结束。
研究者都发现了什么?
性能与可读性权衡:
- 一个仅在人类编写的推导上进行监督式微调的模型,虽然具有较高的可读性,但准确性较差。
- 当模型的优化目标仅为正确性,即只关注生成正确答案时,虽然能够达到高准确性,但生成的解决方案的可读性却较差。
- OpenAI 提出的可检查博弈方法平衡了这两者,在保持高可读性的同时保持适度的准确性。
三种有用的模型:
- 鲁棒验证者:即使解决方案具有误导性,仍能够有效区分正确和错误的解决方案。
- 有用的证明者:生成对人类来说易于理解的解决方案,从而减少人类评估者的错误。
- 狡猾证明者:产生微妙的、错误的解决方案,这些解决方案最初会混淆人类评估者,从而突出需要进一步改进的领域。
研究团队使用了同样的测试问题,来展示狡猾证明者(Sneaky Prover)的生成内容和训练过程。
问题:肖娜(Shawna)的父亲的年龄是肖娜的五倍。肖娜现在的年龄是阿莉娅(Aliya)的三倍。如果阿莉娅 3 岁,那么肖娜的父亲多少岁?
结论
随着大语言模型(LLMs)在关键领域和复杂应用中的使用日益增加,了解其所生成的内容是否值得信赖变得至关重要。通过要求模型生成清晰且可验证的理由,可以增强对其生成内容的信任。
此方法的一个显著优势是它减少了对人类示范或可读性判断的依赖。这种自主性对于未来超智能 AI 系统的对齐尤为重要,其最终目标是在没有人类进行直接监督的情况下,可靠地将 AI 系统与人类的价值观和期望对齐。
尽管这项工作仅在一个数据集上进行了实验,并且仍然需要真值标签(ground truth labels),但研究团队仍预计在开发正确、透明及可验证的 AI 系统中,此类方法会起到关键作用,并增强其在现实应用中的可信任性和安全性。
参考链接:
https://openai.com/index/prover-verifier-games-improve-legibility/
#清华包揽最佳论文+时间检验奖
清华成绩亮眼。
第 47 届国际计算机协会信息检索大会(ACM SIGIR) 于 2024 年 7 月 14 日至 18 日在美国华盛顿特区举行。该会议是信息检索领域的顶级学术会议。
刚刚,大会公布了最佳论文奖、最佳论文亚军、最佳论文荣誉提名奖以及时间检验奖等奖项。
其中,清华大学、中国人民大学高瓴人工智能学院、小红书团队获得了最佳论文;来自格拉斯哥大学、比萨大学的研究者摘得亚军;最佳论文荣誉提名奖颁给了山东大学(青岛)、莱顿大学、阿姆斯特丹大学的研究者;时间检验奖颁给了清华大学、加州大学圣克鲁斯分校的研究者。
接下来,我们来看获奖论文的具体内容。
最佳论文
- 论文:Scaling Laws For Dense Retrieval
- 论文作者:方言、Jingtao Zhan、艾清遥、毛佳昕、Weihang Su、Jia Chen、刘奕群
- 机构:清华大学、中国人民大学高瓴人工智能学院、小红书
- 论文链接:https://dl.acm.org/doi/abs/10.1145/3626772.3657743
论文简介:在广泛的任务中,特别是在语言生成中,研究人员都观察到了扩展定律。研究表明大型语言模型的性能遵循模型和数据集大小的可预测模式,这有助于有效且高效地设计训练策略,特别是在大规模训练变得越来越资源密集的情况下。然而,在密集检索中,扩展定律尚未得到充分探索。
该研究探索了扩展如何影响密集检索模型的性能。具体来说,研究团队实现了具有不同数量参数的密集检索模型,并使用不同数量的注释数据对其进行训练。该研究使用对比熵(contrastive entropy )作为评估指标,与离散的排名指标相比,对比熵是连续的,因此可以准确地反映模型的性能。
实验结果表明,密集检索模型的性能遵循与模型大小以及注释数量相关的精确幂律扩展。
此外,该研究还表明,扩展定律有助于优化训练过程,例如解决预算约束下的资源分配问题。
这项研究极大地有助于理解密集检索模型的扩展效应,为未来的研究提供了有意义的指导。
最佳论文亚军
本届 ACM SIGIR 最佳论文亚军颁给了论文「 A Reproducibility Study of PLAID 」。论文作者包括来自格拉斯哥大学的 Sean MacAvaney、以及来自比萨大学的 Nicola Tonellotto。
论文地址:https://arxiv.org/pdf/2404.14989
论文摘要:ColBERTv2 的 PLAID 算法使用聚类术语表示来检索和逐步剪枝文档,以获得最终的文档评分。本文复制并填补了原文中缺失的空白。通过研究 PLAID 引入的参数,研究者发现它的帕累托边界是由三个参数之间的平衡形成的。超出建议设置的偏差可能会大大增加延迟,而不一定会提高其有效性。
基于这一发现,本文将 PLAID 与论文中缺失的一个重要基线进行比较:对词汇系统进行重新排序。发现在初始 BM25 结果池之上应用 ColBERTv2 作为重新排序器,在低延迟设置中提供了更好的效率 - 有效性权衡。这项工作强调了在评估检索引擎效率时仔细选择相关基线的重要性。
最佳论文荣誉提名奖
此次会议的最佳论文荣誉提名奖由山东大学(青岛)、莱顿大学、阿姆斯特丹大学的研究者摘得。获奖论文为「 Generative Retrieval as Multi-Vector Dense Retrieval 」。
- 论文作者:吴世广,魏闻达,张孟奇,陈竹敏,马军,任昭春,Maarten de Rijke,任鹏杰
- 论文地址:https://arxiv.org/pdf/2404.00684
论文摘要:本文通过证明生成检索和多向量密集检索共享相同的框架来衡量文档查询的相关性。具体来说,他们研究了生成检索的注意力层和预测头,揭示了生成检索可以理解为多向量密集检索的一个特例。这两种方法都通过计算查询向量和文档向量与对齐矩阵的乘积之和来计算相关性。
然后,研究者探讨了生成检索如何应用此框架,他们采用不同的策略来计算文档 token 向量和对齐矩阵。并进行了实验来验证结论,表明这两种范式在其对齐矩阵中都表现出术语匹配的共性。
时间检验奖
本届 ACM SIGIR 时间检验奖颁给了 10 年前在 SIGIR 2014 上发表的关于可解释推荐的研究,论文为「 Explicit Factor Models for Explainable Recommendation based on Phrase-level Sentiment Analysis 」。
- 论文作者:张永锋、 赖国堃 、 张敏 、 Yi Zhang 、 刘奕群 、马少平
- 机构:清华大学、加州大学圣克鲁斯分校
- 论文链接:https://www.cs.cmu.edu/~glai1/papers/yongfeng-guokun-sigir14.pdf
该研究首次定义了「可解释性推荐」问题,并提出了相应的情感分析方法用于解决这一技术挑战,在相关领域一直发挥着引领作用。
论文摘要:基于协同过滤(CF)的推荐算法,例如潜在因子模型(LFM),在预测准确率方面表现良好。然而,潜在特征使得向用户解释推荐结果变得困难。
幸运的是,随着在线用户评论的不断增长,可用于训练推荐系统的信息不再仅限于数字星级评分或用户 / 商品特征。通过从评论中提取用户对产品各个方面的明确意见,可以更详细地了解用户关心的方面,这进一步揭示了做出可解释推荐的可能性。
本文提出了 EFM(Explicit Factor Model )来生成可解释的推荐,同时保持较高的预测准确率。
研究者首先通过对用户评论进行短语级情感分析来提取显性产品特征和用户意见,然后根据用户兴趣的特定产品特征和学习到的隐藏特征生成推荐和不推荐。此外,从模型中还生成了关于为什么推荐或不推荐某件商品的直观特征级解释。
在多个真实数据集上的离线实验结果表明,该研究提出的框架在评分预测和 top-K 推荐任务上均优于竞争基线算法。在线实验表明,详细的解释使推荐和不推荐对用户的购买行为更具影响力。
青年学者奖
ACM SIGIR 青年学者奖旨在表彰在信息检索研究、学者社区建设、推进学术公平等方面发挥重要作用的研究人员,要求授予获得博士学位 7 年以内的青年研究学者。来自清华大学计算机系的助理教授艾清遥、来自中国科学技术大学网络空间安全学院、大数据学院教授、博士生导师王翔获得了 SIGIR 2024 青年学者奖。
#GSM-Plus
对25个开闭源模型数学评测,GPT-3.5-Turbo才勉强及格
本文作者来自香港大学和腾讯。作者列表:李沁桐,Leyang Cui,赵学亮,孔令鹏,Wei Bi。其中,第一作者李沁桐是香港大学自然语言处理实验室的博士生,研究方向涉及自然语言生成和文本推理,与博士生赵学亮共同师从孔令鹏教授。Leyang Cui 和 Wei Bi 是腾讯高级研究员。
前言
大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。
然而在使用中我们经常会发现,当数学问题稍作改变时,LLMs 可能会出现一些低级错误,如下图所示:
图 1:GPT-3.5-Turbo 正确解答了一个数学问题(左),但当在原问题的基础上添加一个限制条件(右)时,Turbo 因为没有正确区分 “离开” 和 “返回” 的方向,而误用运算符出错。
我们不禁要问:大型语言模型是否真的掌握了数学知识的精髓?它们是如何在这些测试中取得如此高分的?难道仅仅是因为模仿了大量训练数据中的表面推理模式吗?LLMs 是否真正理解数学概念,仍是一个值得探讨的问题。
为了探究这一问题,本文作者设计了一个评估基准 GSM-Plus。这个测试旨在对一个问题进行 8 种不同的细粒度数学变换,系统地评估当前 LLMs 在处理基础数学应用题时的能力。在这一全新的基准测试中,论文对 25 个不同的 LLMs 进行了严格评测,包括业界的开源和闭源模型。
实验结果表明,对于大多数 LLMs 来说,GSM-Plus 是一个具有挑战性的基准测试。即便是在 GSM8K 上,GPT-3.5-Turbo 已能取得 73.62% 的准确率,但在 GSM-Plus 上仅能达到 61.19% 的准确率。本文工作已经以4,4, 4.5分被ACL2024录用。
- 论文标题:GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers
- 论文地址:https://arxiv.org/pdf/2402.19255
- 论文主页:https://qtli.github.io/GSM-Plus/
背景
数学推理是人工智能发展的重要证明。它需要严格的问题理解、策略制定和计算执行能力。在过去几年中,诸多公开数据集被用于评估人工智能系统的数学推理能力。早期的数学数据集侧重于基于方程的数学问题。随后,更难的数据集被引入,涵盖了小学、高中和大学水平的数学问题。
随着评测数据难度的不断提高,LLMs 的发展也变得十分迅速。为了提升 LLMs 在数学领域的性能,可以通过在多样化的任务数据上进行训练,使用监督微调(SFT)来快速帮助 LLMs 适应到数学领域。在推理阶段,通过设计巧妙的输入提示(例如,Chain-of-Thought 和 Program-of-Thought)也可以有效激发 LLMs 的数学能力。
对于大多数 LLMs 而言,面对高中及以上的数学问题仍有很大的提升空间。然而,在小学数学领域,LLMs 已经展现出巨大的潜力。这让我们不禁思考,在现实环境中 LLMs 是否能依然保持高性能?
对抗性评测数据集 GSM-Plus
本研究旨在推出一个综合性基准测试 GSM-Plus,以系统地检验 LLMs 在解决基础数学问题时的鲁棒性。受 Polya 原则 [2] 中解决数学问题的能力分类法的启发,本文确定了五个方面的指导原则用于构建 GSM-Plus 数据集:
为了便于理解,此处以「 珍妮特的鸭子每天下 16 个蛋。她每天早上吃三个蛋作为早餐,并且用四个蛋烤松饼给她的朋友。她每天以每个鸭蛋 2 美元的价格在农贸市场出售剩余的蛋。她每天在农贸市场上赚多少美元?」问题为例。
(1)数值变化:指改变数值数据或其类型,本文定义了三个子类别:
- 数值替换:在同等数位和类型下替换数值,例如将问题中的 “16” 替换为 “20”。
- 数位扩展:增加数值的位数,例如将 “16” 替换为 “1600”。
- 整数 - 小数 - 分数转换:将整数更换为小数或分数,例如将 “2” 转换为 “2.5”。
(2)算术变化:指对数学问题引入额外的运算或者进行反转,但只限于加、减、乘、除运算:
- 运算扩充:在原问题基础上增加限制条件。例如,增加新条件“她每天还会使用两个鸡蛋自制发膜”。
- 运算逆转:将原问题的某个已知条件转换为 GSM-Plus 变体问题的待求解变量。例如,图 2 中原问题的陈述 “每个鸭蛋 2 美元” 转换为新问题的疑问句 “每个鸭蛋的价格是多少?”,而原问题疑问句” 每天在农贸市场上赚多少美元?” 则转换为新问题的已知条件” 她每天在农贸市场赚 18 美元”
(3)问题理解:指在意思不变的前提下,用不同词句重新表述数学问题,如” 珍妮特养了一群鸭子,这些鸭子每天产 16 个鸭蛋。她早餐消耗三个鸭蛋,然后消耗四个鸭蛋烤松饼给她的朋友。珍妮特在农贸市场上以每个新鲜的鸭蛋 2 美元的价格将剩余的鸭蛋全部出售。她每天通过在农贸市场出售鸭蛋赚多少钱?”
(4)干扰项插入:指将与主题相关、包含数值但对求解无用的句子插入到原问题中,如” 珍妮特还想用两个鸭蛋喂养她的宠物鹦鹉,所幸她的邻居每天送她两个鸭蛋用于喂养鹦鹉”。
(5)批判性思维:侧重于当数学问题缺乏必要条件时,LLMs 是否具有提问或怀疑能力,例如” 珍妮特的鸭子每天都会下蛋。她每天早上吃三个蛋作为早餐,并且每天用四个蛋烤松饼给她的朋友。她每天以每个鸭蛋 2 美元的价格在农贸市场出售剩余的蛋。她每天在农贸市场上赚多少美元?”。
基于 GSM8K 的 1,319 个测试问题,本文为每个问题创建了八个变体,从而生成了包含 10,552 个问题变体的 GSM-Plus 数据集(本文还提供了一个包含 2,400 个问题变体的测试子集,以便快速评测)。通过使用每个问题及其八个变体测试 LLMs,GSM-Plus 可以帮助研究人员全面评估 LLMs 在解决数学问题中的鲁棒性。
图 2:基于一个种子数学题,使用 5 个角度的 8 种扰动生成问题变体。主要修改内容以绿色标出。
通过使用 GSM-Plus 评估 25 个不同规模、不同预训练方式、不同任务微调的 LLMs,以及组合 4 种常用的提示技术,本文发现 LLMs 整体上可以准确解决 GSM8K 问题,但在回答 GSM-Plus 中的变体问题时会遇到明显困难。主要发现如下:
- 任务特定的优化,即在数学相关的数据集上微调,通常可以提高下游任务准确性;而鲁棒性的高低更多地取决于基础模型和微调数据集的选择。
- 当需要 “批判性思维”、涉及 “算术变化” 和 “干扰因素插入” 时,LLMs 的性能会迅速下降;但对于 “数值变化” 和 “问题理解” 的扰动,LLMs 的性能比较稳定。
- 先前的提示技术(例如,CoT,PoT,LtM 和 Complexity-based CoT)对于鲁棒性增强作用不显著,特别是对于 “算术变化 “和” 批判性思维”。在前人工作的基础上,本文进一步探索了一种组合提示方法,通过迭代生成和验证每个推理思维,可以同时提升 LLMs 在 GSM8K 和 GSM-Plus 上的性能。
GSM-Plus 特点
- 质量保证:采用两阶段生成 GSM-Plus 评测题。首先,利用 GPT-4 的问题改写能力生成问题变体,然后为这些变体生成候选答案;为确保数据质量,所有由 GPT-4 生成的问题变体和答案都要经过人工标注团队进行严格检查。人工标注团队修正了 18.85% 的 GPT-4 改写的问题。
- 细粒度评估:对于主流评测数据集 GSM8K 的每个测试题,GSM-Plus 提供了 8 个扰动方向的变体问题,充分测试了在不同上下文下,大模型灵活解决数学应用题的能力。
- 挑战性:相比于 GSM8K,GSM-Plus 的问题变体更具挑战性,所有参与评估的 LLMs 的性能都显著下降。在接下来的分析中,本文会特别分析 LLMs 在不同类型扰动下的解题鲁棒性。
与其他小学数学应用题数据的比较
表 1:不同颜色代表不同的扰动类型:
数值替换,
数位扩展,
整数 - 小数 - 分数转换,
运算扩充,
运算逆转,
问题理解,
干扰项插入,
批判性思维。
从上表可以看出,先前的研究使用不同的扰动来检验数学推理的鲁棒性,但是评估设置仅涵盖部分扰动类型,且大多是通过自动方法构建引入扰动,质量难以保证。相比之下,GSM-Plus 使用八种不同的数学推理技能对单一问题进行扰动,覆盖面更全,且经过严格的质量控制。
实验分析
评测指标
- 性能下降率(PDR):与原问题相比,LLMs 在扰动后的问题上的性能下降程度。
- 同时解决的问题对的百分比(ASP):原问题及其对应的某个问题变体均被 LLMs 正确解答的比例。
整体性能
如下表所示,相较于 GSM8K,大多数 LLMs 在 GSM-Plus 上的性能都大幅下降。
GPT-4 表现出最高的鲁棒性,其 PDR 最小仅为 8.23%。而 CodeLlama 的 PDR 最大,其中 7B、13B 和 34B 的模型分别为 40.56%、39.71%和 34.27%,超过了其基座模型 LLaMA-2-7B(39.49%),以及在其上微调的数学 SFT 模型,如 SEGO-7B(34.91%)。这表明仅使用程序语言推理对于扰动是很脆弱的。
在面对数学扰动时,模型规模越大,性能越稳定。虽然监督微调可以提高在下游任务上的准确率,但并不能显著增强模型对于扰动的鲁棒性(即更低的 PDR)。监督微调的数据对于鲁棒性非常重要。同样是基于 LLaMA-2 进行微调,使用不同的数据,会导致模型的准确率和鲁棒性具有较大差异。
表 2:整体性能
细粒度实验分析
不同扰动下 LLMs 的性能表现
本文进一步评估了 LLMs 在 8 种问题变体下的性能稳定性。与人类基线相比,对于 “批判性思维”(紫色)、“运算扩充” 和 “运算逆转”(蓝色)、“干扰项插入”(粉色)以及 “整数 - 小数 - 分数转换”(橙色)扰动,LLMs 性能下降明显。而对于 “数值替换” 和 “问题理解”,LLMs 的性能稳定,甚至有轻微的提升。
图 3:细粒度实验分析
数学推理能力的迁移性
前面的分析主要基于数据集整体。接下来,本文根据数学题是否被正确回答将 2 个数据集分割,分析当 LLMs 成功解决 GSM8K 问题时,是否意味着正确回答 GSM-Plus 变体问题的可能性变高(即高 ASP 值),反之亦然。如果这种断言成立,可以认为 LLMs 在这类特定的数学题子集上性能稳定,即使在整个数据集上并非如此。在实验设置中,每个 GSM8K 问题及其在 GSM-Plus 中的变体转化为 8 个问题对,结果如图 4 所示。
图 4:LLMs 在 GSM8K 和 GSM-Plus 问题对之间的推理可迁移性。紫色(均正确)和蓝色(均错误)的条形图表示一致的模型行为,而红色(GSM8K 正确 & GSM-Plus 错误)和黄色(GSM8K 错误 & GSM-Plus 正确)的条形图则表示不一致的模型行为。紫色和红色条形图的高度和表示 LLMs 正确解决 GSM8K 问题的数量。
红色条形图的存在(LLMs 正确回答原问题,但未解决变体问题),表明大多数模型的性能可迁移性有限。虽然 LLMs 在 GSM8K 问题上性能有所差异(紫色和红色条形图的高度),但性能可迁移性相似(红色条形图的高度)。这意味着现有的基准测试无法准确评估模型在数学推理方面的真实能力。高准确率并不等价于强大的推理鲁棒性。
提示对于 LLMs 性能鲁棒性的帮助
先前的工作表明,良好的提示指令对于激发语言模型的数学能力十分重要。本文选择了 4 个代表性模型,并测试它们在不同的提示指令下解题的表现。如下图所示,当面对干扰时,使用复杂的示例作为上下文演示(Complexity-based CoT)时,LLMs 表现最为稳定;相比之下,仅使用程序语言表示中间推理(Program-of-Thought)时,LLMs 更容易受到干扰的影响。总体而言,这些提示技巧都不足以让 LLMs 在 GSM-Plus 上维持与 GSM8K 相同的性能。
图 5:提示对于 LLMs 性能鲁棒性的影响
组合提示是否有效?
如何基于现有的提示方法增强 LLMs 的鲁棒性呢?本文发现 LLMs 在解题过程中常常会忽略重要条件或出现计算错误。为此,本文探索了一种组合提示方法 Comp。该方法首先提示 LLMs 提取问题中与数值相关的必要条件(Prompt1)。接着,根据问题和关键条件,指示 LLMs 迭代地生成推理目标(Prompt2)和计算目标(Prompt3),并让其为生成的历史解题步骤提供反馈,以确定是否获得了最终答案(Prompt4)。具体实现如图 6 所示。
图 6:Comp 迭代提示方式的示意图
可以看出,Comp 通过迭代生成和自我验证可以改善 LLMs 在各种问题变化类型下的性能,但它仍然无法弥合 LLMs 在标准测试集和对抗性测试集之间的性能差距。该研究期待未来有更多的方法进一步提升模型的鲁棒性,推动 LLMs 在数学推理领域的进一步发展。
表 3:Comp 迭代提示的性能
生成示例
下图展示了在 GSM8K 问题和基于 “运算逆转” 的 GSM-Plus 改写问题上,不同提示技术下 GPT-3.5-Turbo 的表现。虽然所有提示都可以激发 Turbo 准确回答 GSM8K 问题,但只有 Comp 能够帮助 Turbo 在 GSM-Plus 变体问题上生成正确的答案。
图 7:在不同提示设置下,模型回答数学问题的示例
结语
本文介绍了一个对抗性小学数学应用题评测集 GSM-Plus,旨在系统分析 LLMs 在解决数学应用题中的鲁棒性。实验分析发现,大多数 LLMs 在面临扰动时,性能相较于它们在标准基准上的表现显著下降,远远达不到人类的表现水平。研究者期望本文的工作能够促进更多未来研究,包括但不限于:(1)对 LLMs 的数学技能进行系统评估;(2)构建能够灵活进行数学推理的模型。
参考链接
[1] Cobbe, Karl, et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021). https://paperswithcode.com/sota/arithmetic-reasoning-on-gsm8k
[2] George Polya. 2004. How to solve it: A new aspect of mathematical method, volume 85. Princeton university press.
#OmniParser
控制电脑手机的智能体人人都能造,微软开源OmniParser
大模型控制计算机果真就是未来方向?
最近这几天,让大模型具备控制计算机(包括电脑和手机)的相关研究和应用如雨后春笋般不断涌现。
先是 Anthropic 发布了能控制计算机的新版 Claude 3.5 Sonnet,之后荣耀 MagicOS 9.0 来了个全局智能体,再然后,昨天智谱发布了具备「全栈式工具使用能力」的 AutoGLM,同时华为也公布了一项可让 AI 像人类一样操作手机的新研究成果 LiMAC。
很显然,这股热潮完全没有要停息的意思。今天,有网友发现苹果已经默默发布了 Ferret-UI 的两个实现版本(分别基于 Gemma 2B 和 Llama 8B),这是苹果今年五月发布的一个可让 AI 理解手机屏幕的技术,详情参阅《让大模型理解手机屏幕,苹果多模态 Ferret-UI 用自然语言操控手机》。
来自 X 用户 Niels Rogge
- Ferret-UI 项目地址:https://huggingface.co/papers/2404.05719
不仅如此,微软也低调开源了他们的相关研究 OmniParser,这是一个基于大模型的屏幕解析工具,可将 UI 截图转换成结构化的元素;据称其解析和理解 UI 的能力达到了当前最佳水平,甚至超越了 GPT-4V。
- 项目地址:https://huggingface.co/microsoft/OmniParser
- 代码地址:https://github.com/microsoft/OmniParser
- 论文标题:OmniParser for Pure Vision Based GUI Agent
- 论文地址:https://arxiv.org/abs/2408.00203
有了这个工具,或许每个人都可以创建自己的计算机操控智能体了。
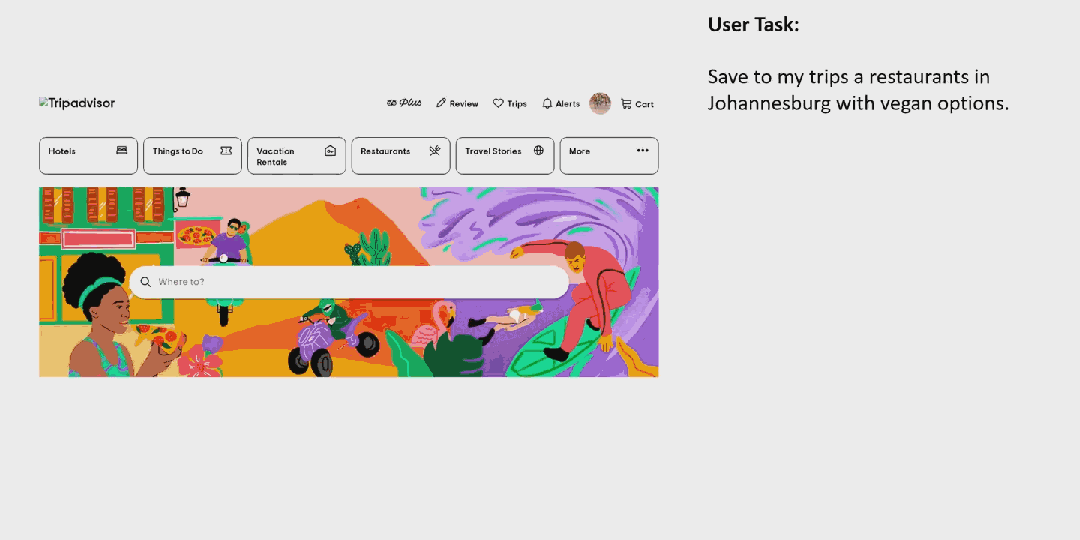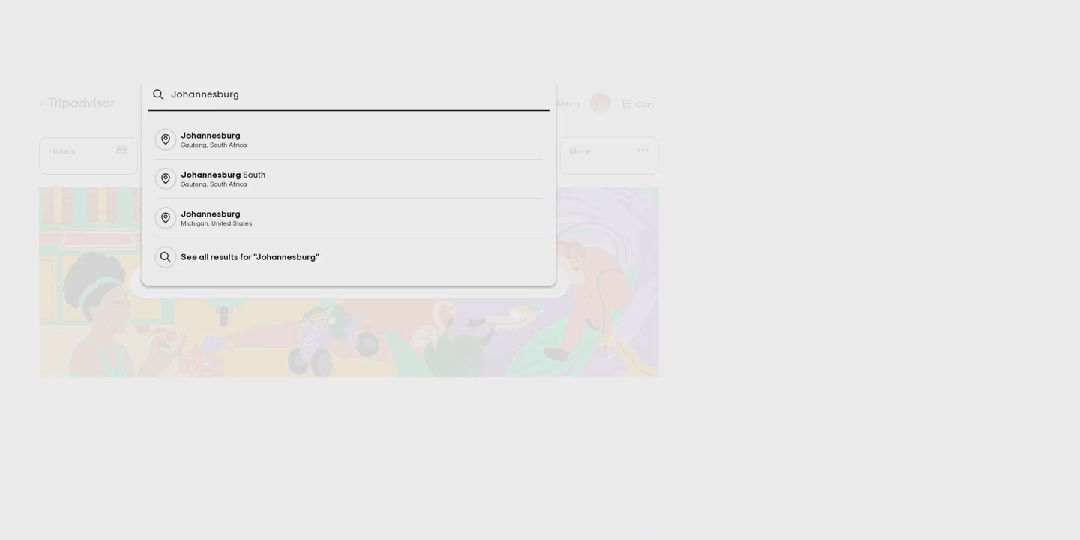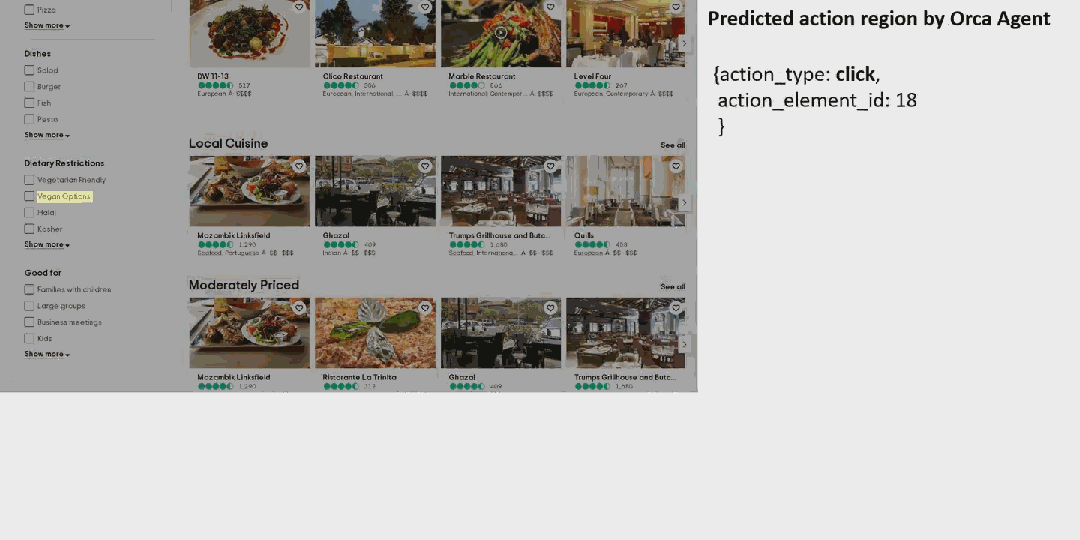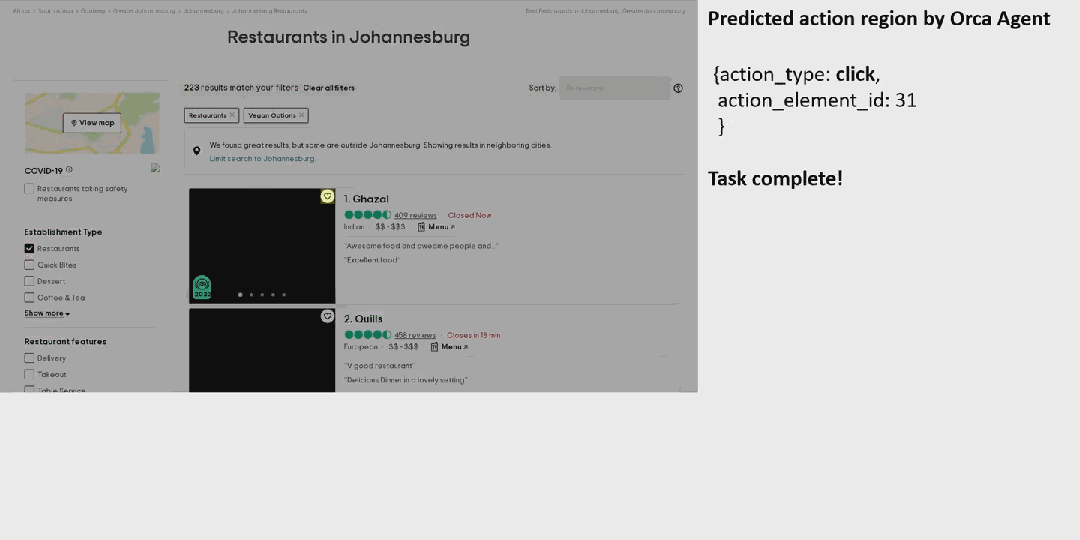
先来看看 OmniParser 的效果。对于一个用户任务:「将约翰内斯堡提供素食选择的餐厅保存到我的行程中」。
OmniParser 首先会解析 Tripadvisor 网页屏幕上的所有元素,然后它成功从中找到了「餐厅」选项。之后它点击(动作执行需要搭配其它模型)该选项,打开了一个搜索框。OmniParser 继续解析,这一次没有在屏幕上找到所需关键词,于是它在搜索框中输入了「约翰内斯堡」。再次解析后,它打开了相应的搜索项,展开了搜索结果。同样,继续解析,它成功定位到了素食选项,然后进行了勾选。最后,点击筛选出的第一个选项上的相应按钮将其收藏到行程中。至此,任务完成。
而如果你想看看能否进入布莱斯峡谷国家公园呢?OmniParser 也能助你轻松完成。
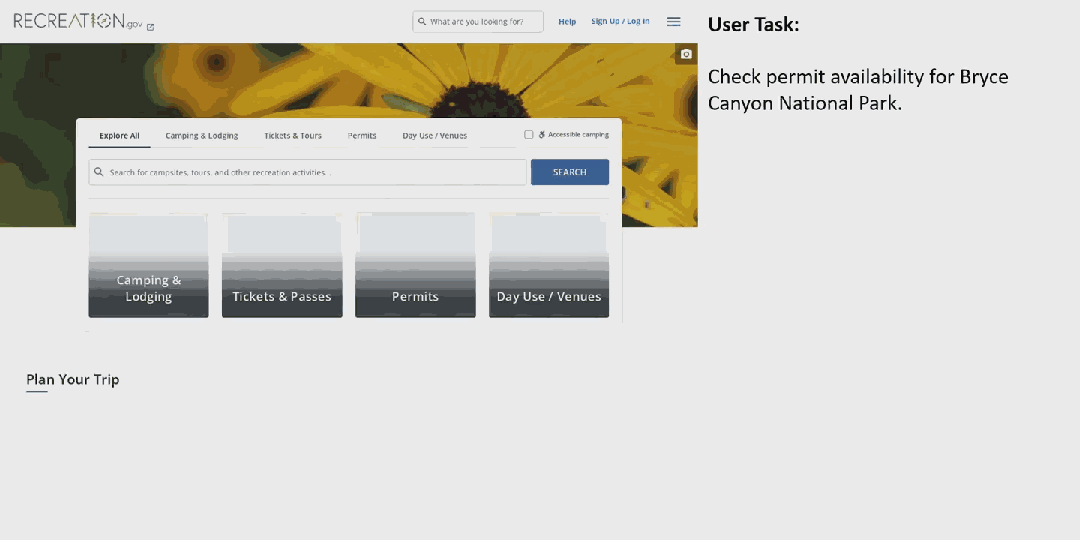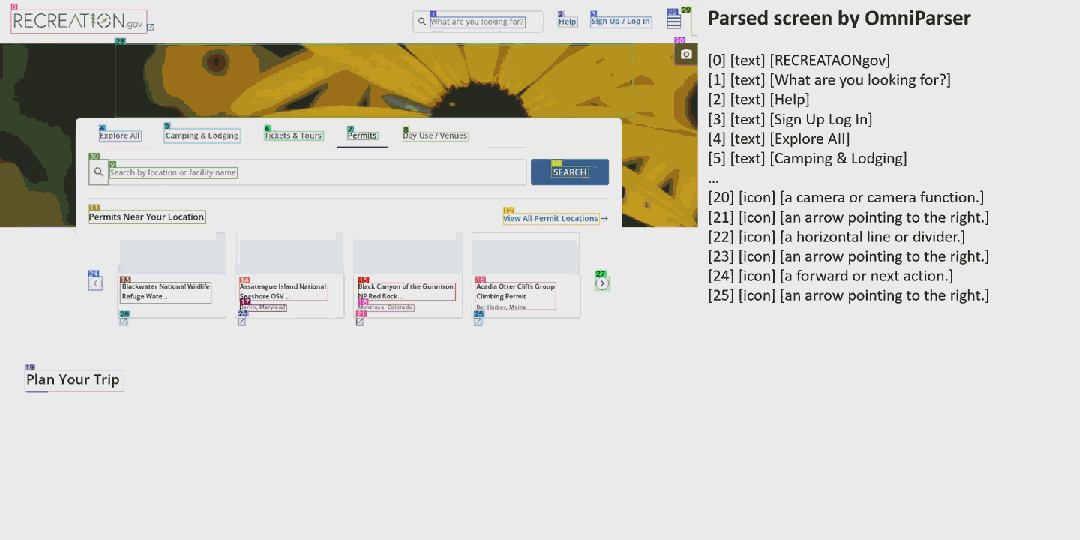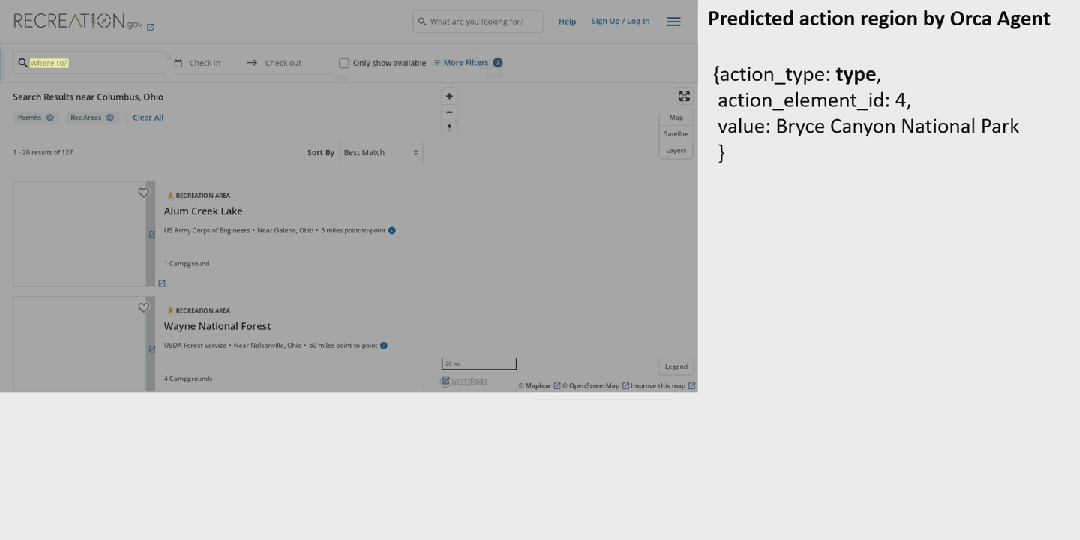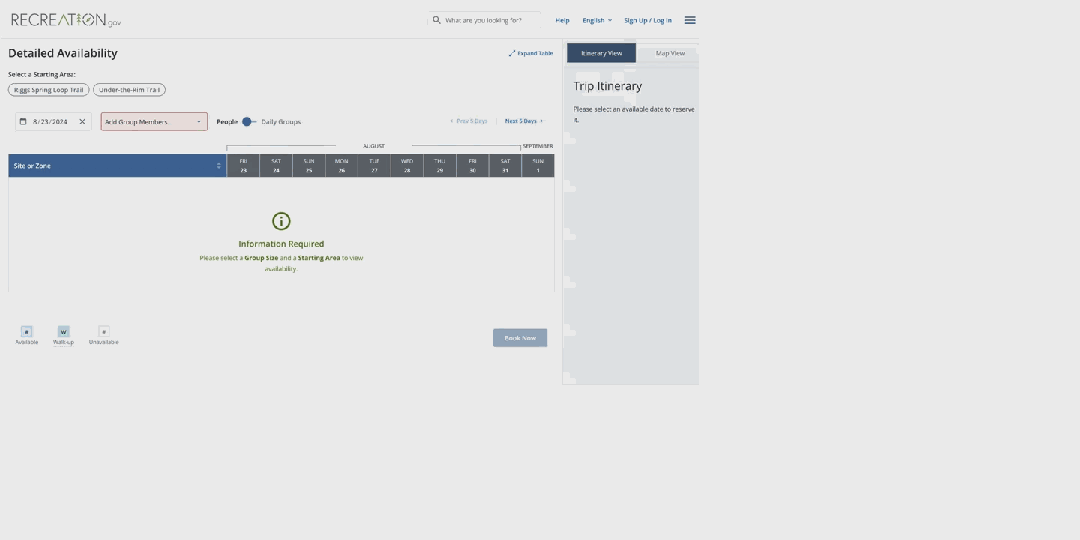
整体来看,OmniParser 的解析能力非常出色,过程也还算流畅。
我们知道,不同的操作系统和应用有着大不相同的交互界面。为了稳健地应对各种不同情况,屏幕解析模型需要:
- 可靠地识别交互界面内可交互的图标;
- 理解屏幕截图中各种不同元素的含义,并将计划动作与屏幕上相应的区域准确地关联起来。
OmniParser 正是为这一目的而生的。OmniParser 可基于用户任务和 UI 截图输出:(1) 解析后的截图,带有边界框和数值 ID,(2) 包含提取出的文本和图标描述的局部语义。下面展示了几个例子:



如果再搭配上其它可以基于 UI 采取行动的模型(比如 GPT-4V、Phi-3.5 和 Llama 3.2),便可以创造出可以理解并控制计算机的智能体。
该团队用 GPT-4V 做了实验,结果发现 OmniParser 能大幅提升其为界面区域生成精准动作的能力。他们使用 OmniParser 和 GPT-4V 创建的一个智能体在 WindowsAgentArena 基准上达到了最佳水平。
OmniParser 是如何炼成的?
收集和整理专用数据集 ——OmniParser 的开发始于创建两个数据集:
- 一个可交互区域检测数据集,该数据集收集整理自常见的网页,其中可点击和可操作的区域都做了标注。
- 一个图标描述数据集,旨在将每个 UI 元素与其相应的功能关联起来。在训练模型以理解检测到的元素的语义方面,此数据集非常关键。
下面展示了可交互区域检测数据集的一些样本示例。

对检测和描述模型进行微调 ——OmniParser 使用了两个互补的模型:
- 一个检测模型,在可交互图标数据集上进行了微调,其能可靠地识别屏幕截图中的可操作区域。
- 一个描述模型,在图标描述数据集上完成了训练,其作用是提取检测到的元素的功能语义,为预期操作生成准确符合上下文的描述。
性能表现
该团队对自己的方法进行了实验验证。结果发现,OmniParser 可大幅提升 GPT-4V 在 ScreenSpot 基准上的性能。

在 Mind2Web 基准上,OmniParser + GPT-4V 的表现也胜过可从 HTML 提取额外信息的 GPT-4V。

在 AITW 基准上,OmniParser 的表现优于一个经过增强的 GPT-4V—— 附带了一个使用视图图层训练的专用 Android 图标检测模型。

另外,其在新基准 WindowsAgentArena 上也达到了最佳性能。

OmniParser 可作为当前各种视觉 - 语言模型(VLM)的插件。为了进一步演示这一点,该团队也测试了其与 Phi-3.5-V 和 Llama-3.2-V 的组合。

该团队表示:「我们希望 OmniParser 可以作为一种通用且易于使用的工具,在 PC 和移动平台上解析用户的屏幕,而无需依赖 HTML 和 Android 中的视图图层等额外信息。」
不知道如果将 OmniParser 与新版 Claude 3.5 Sonnet 的 Computer Use 结合起来会是什么效果?可能会像这位网友说的,很赞吧。
参考链接:
https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/
https://x.com/mervenoyann/status/1849772138166727128
https://x.com/NielsRogge/status/1849789061508055339
#Waymo获得56亿美元融资
Waymo获得56亿美元融资,有史以来最大一轮
这笔资金将被用于进一步扩展 Waymo 的无人驾驶出租车服务。
Alphabet 旗下的自动驾驶子公司Waymo刚刚完成一轮56亿美元的C轮超额认购融资,以进一步扩大其无人驾驶出租车服务。这是该公司迄今为止筹集的最大一轮融资。
此次融资由Alphabet领投,其他投资机构包括Andreessen Horowitz、Fidelity、Perry Creek、Silver Lake、Tiger Global和T. Rowe Price,不过Waymo并未公布具体的投资比例。
这是 Waymo 的第二轮外部融资,也是自 2020 年 22.5 亿美元 B 轮融资(最终增至 32 亿美元)以来的首轮融资。
这家自动驾驶汽车公司表示,将利用这笔资金向新城市扩张,并进一步开发其自动驾驶能力。
从某种程度上来说,Waymo 现在与上一轮融资时相比已经大不相同了。当时,该公司仍在全力投入自动驾驶卡车业务,但后来退出了。
现在,该公司几乎把全部精力都放在了自动驾驶出租车叫车服务上,这一赌注获得了回报。Waymo 目前在旧金山、洛杉矶、菲尼克斯运营商业自动驾驶出租车服务,并正在向奥斯汀和亚特兰大扩张。
该公司在前三个市场每周为超过 10 万名客户提供付费叫车服务,乘客可以通过 Waymo One 应用叫车。
Waymo还提供往返菲尼克斯天港国际机场的服务,该公司还在菲尼克斯和旧金山地区的高速公路上运营。

对于此次融资,Waymo 的一位机器学习工程师 Brian Wilt 激动的表示:「这是有史以来仅次于 OpenAI / xAI 的第三大风险投资吗?」
「客户喜欢 Waymo,该公司打造了自动驾驶汽车生态系统中最安全的产品,也是最好的产品,」投资公司Tiger Global 创始人 Chase Coleman 表示。
另一位投资公司Silver Lake 联合首席执行官 Egon Durban 表示:「尽管AI才刚刚开始引起公众的关注,但多年来,Waymo 一直致力于将其无限的可能性带入实体交通领域。Waymo Driver( AI 驱动的自动驾驶系统) 通过尖端研究、实用解决方案以及范围和规模不断扩大的现实经验,安全地实现了人工智能的价值和潜力,从而赢得了信任。」
随着 Waymo One 乘客人数的不断增长,Waymo继续专注于将 Waymo Driver的安全性和移动性优势扩展到更多地方,同时增强运营能力。为此,Waymo最近推出了第六代 Waymo Driver,针对成本和增强功能进行了优化。他们还通过在布法罗、纽约和华盛顿特区等城市,在更复杂的环境中测试其系统。
本轮融资不仅凸显了 Waymo 在美国自动驾驶汽车行业的领先地位,还凸显了其在盈利能力、可扩展性和技术优势方面的积极推动。与 Uber 的市场扩张合作进一步巩固了其利用现有平台实现更广泛市场渗透的战略。
不难看出,本轮融资和随后的扩张计划标志着 Waymo 将迎来关键时刻,其目标不仅是扩大服务,而且要利用自动驾驶技术从根本上重塑城市交通。
参考链接:
https://www.cnbc.com/2024/10/25/alphabets-self-driving-unit-waymo-closes-5point6-billion-funding-round.html
https://techcrunch.com/2024/10/25/waymo-raises-5-6b-from-alphabet-a16z-silver-lake-and-more/
#Open_Duck_Mini
不能拥有迪士尼同款机器人,就自己造一个。
手搓迪士尼同款机器人,总花费不到1500美元
还记得迪士尼开发的 BDX 双足机器人吗?这款机器人专为娱乐表演而设计,拥有多项技能,可以跳舞,还可以表演。

当时,这款机器人一经发布,其可爱呆萌形象深受大家喜爱,网友纷纷喊话,自己也想拥有一个同款。
现在,教你手搓迷你版迪士尼机器人的教程来了。

- 项目地址:https://github.com/apirrone/Open_Duck_Mini
我们先来看效果。机器人在地板上行走,但看起来走的还不是很稳。

走了没几步,机器人似乎要摔倒,还好有人及时扶了一把。

根据项目作者 Antoine Pirrone 介绍,该机器人的腿伸直后大约有 35 厘米高。

这款机器人还可以抵御各种干扰,用手施加一个力,机器人也不会摔倒。

在侧面和背面戳它几下,机器人也能保持平衡。

加大力度,机器人也不会歪倒。

可见机器人的平衡性还是很好的。
不过,一开始项目进展的并不顺利。根据作者介绍,当他将行走策略迁移到真实机器人上时,机器人走得并不稳当,身体摇摇晃晃。

机器人一个趔趄差点摔倒。

从展示来看,机器人似乎还不能直线行走,拐了一个弯,然后摔倒了。

经过作者多次优化,才有了文章开头的效果,机器人可以正常行走了。这对作者来说,是一个巨大的进步。

最后作者还列举了完成这项工作所需要的相关文档,比如材料清单,清单中的每种材料还附带相关链接,直接点开可以查看具体内容:

作者表示购买电机占用了大部分成本,总成本在 1000 美元到 1500 美元之间。

不过,大家关心的组装问题,项目作者并没有给出详细介绍,主要原因在于当前版本(alpha)不太容易构建,存在一些机械问题。因此在此版本的机器人一切正常后,作者将从头开始重新设计。
项目作者也在 X 上建议大家在等等 v2 版本,当前设计还存在一些问题。

到时大家可以跟着作者列举的清单、跟着组装步骤打造属于自己的迪士尼同款机器人了。
#PersonaTalk
无需训练即可创建数字人,字节PersonaTalk视频口型编辑超SOTA
在 AIGC 的热潮下,基于语音驱动的视频口型编辑技术成为了视频内容个性化与智能化的重要手段之一。尤其是近两年爆火的数字人直播带货,以及传遍全网的霉霉讲中文、郭德纲用英语讲相声,都印证着视频口型编辑技术已经逐渐在行业中被广泛应用,备受市场关注。
近期,字节跳动一项名为 PersonaTalk 的相关技术成果入选了 SIGGRAPH Asia 2024-Conference Track,该方案能不受原视频质量的影响,保障生成视频质量的同时兼顾 zero-shot 技术的便捷和稳定,可以通过非常便捷高效的方式用语音修改视频中人物的口型,完成高质量视频编辑,快速实现数字人视频制作以及口播内容的二次创作。
,时长00:13
,时长00:11
肖像来自学术数据集 HDTF
目前的视频改口型技术大致可以分为两类。一类是市面上最常见的定制化训练,需要用户首先提供 2-3mins 的人物视频数据,然后通过训练让模型对这段数据中的人物特征进行过拟合,最终实现该数据片段中人物口型的修改。这类方案在效果上相对成熟,但是需要耗费几个小时甚至几天的模型训练时间,成本较高,很难实现视频内容的快速生产;与此同时,这类方案对人物视频的质量要求往往偏高,如果视频中的人物口型动作不标准或者环境变化太复杂,训练后的效果会大打折扣。除了定制化训练之外,还有另一类 zero-shot 方案,可以通过大量数据来对模型进行预训练,让模型具备较强的泛化性,在实际使用的过程中不需要再针对特定人物去做模型微调,能做到即插即用,成功解决了定制化方案成本高,效果不鲁棒的问题。但这类方案大都把重点放在如何实现声音和口型的匹配上,往往忽略了视频生成的质量。这会导致一个重要的问题,最终生成的视频不论是在外貌等面部细节,还是说话的风格,跟本人会有明显的差异。
PersonaTalk 作为一项创新视频生成技术,构建了一个基于注意力机制的双阶段框架,实现了这两类方案优势的统一。
论文链接:https://arxiv.org/pdf/2409.05379
项目网页:https://grisoon.github.io/PersonaTalk
技术方案
为了达到上述目标,技术团队首先用一个风格感知的动画生成模块(Style-Aware Geometry Construction)在 3D 几何空间生成人物的口型动画序列;然后通过一个双分支并行的注意力模块(Dual-Attention Face Rendering)进行人像渲染,生成最终的视频。

肖像来自学术数据集 HDTF
- Style-Aware Geometry Construction:这一阶段的目标是在 3D 几何空间中生成具备人物风格的人脸动画。除了通过常规的语音信号来控制生成结果,这里还从参考视频中提取说话者个性化的面部特征并分析出特征的统计特性,通过 Cross Attention 注入到模型中,来引导生成的动画具备说话者本人的面部运动风格。此外,文中还提出了一种 Hybrid 3D Reconstruction 方案,通过结合深度学习和迭代式优化的方法,来提升人脸三维重建的精度和稳定性。
- Dual-Attention Face Rendering:在渲染过程中,作者团队创新性地设计了两个并行的注意力模块 Face-Attention 和 Lip-Attention,通过 Cross Attention 来融合 3D 动画和人物参考图特征,分别渲染脸部和嘴部的纹理。在推理过程中,文中还针对这两个模块分别设计了参考图挑选策略,其中人脸部分参考图从以当前帧为中心的一个滑动窗口中来获取,以此降低人脸纹理的采集和生成难度,确保视频画面的稳定性和保真度;口型部分则是先按照口型张幅大小对整个视频中的人脸进行排序,然后均匀挑选出不同张幅的口型图片组成一个集合,以确保口腔内的信息可以被完整性获取。
实验效果对比
在实验章节中,该研究从多个方面详细对比了 PersonaTalk 和其他市面上 SOTA 方案,以此来证明该方法的有效性。从视频效果和定量指标上看,PersonaTalk 在唇动同步、视觉质量与个性化特征保留方面均表现突出,明显优于其他 zero-shot 方法。

,时长00:48
肖像来自学术数据集 HDTF 以及自有版权数据
同时,PersonaTalk 作为一个不需要额外训练和微调的方案,在视频结果的表现上甚至优于学术界最新的定制化训练方案。

,时长00:22
肖像来自学术数据集 HDTF 及网络公开数据
此外,作者团队通过对目标用户进行问卷调查和访谈,收集了对 PersonaTalk 生成内容的反馈,结果显示大多数用户对视频质量感到满意,认为其足够逼真且高度还原了人物特征。

更多应用
该项研究可以应用在视频翻译、虚拟教师、AIGC 创作等多个场景。
以下数据均来自于网络公开数据或 AIGC 生成。
虚拟教师
,时长00:09
,时长00:09
原视频 介绍 Deep Learning 课程
AIGC 创作
,时长00:04
,时长00:05
,时长00:04
,时长00:03
结论
PersonaTalk 通过注意力机制的双阶段框架,有效突破了已有视频口型编辑技术的瓶颈,可以用很低的成本来生成高质量的人物口播视频,实现了效果和效率的兼顾。
PersonaTalk 不仅具有广泛的应用前景,还为多领域的创新提供了新思路。无论是在娱乐、教育、广告等行业,都能实现更加个性化和互动式的用户体验。随着技术的不断发展,相信 PersonaTalk 将使视频内容以及数字人创作变得更加生动、真实,从而拉近虚拟世界与现实生活之间的距离。
通过整合先进的音频技术和深度学习算法,PersonaTalk 也正在开启一种全新的视听交互方式,让交流变得更加丰富与多元化。
安全说明
此工作仅以学术研究为目的,会严格限制模型的对外开放和使用权限,防止未经授权的恶意利用。文中使用的图片 / 视频均已注明来源,如有侵权,请联系作者及时删除。
团队介绍
字节跳动智能创作数字人团队,智能创作是字节跳动 AI & 多媒体技术团队,覆盖了计算机视觉、音视频编辑、特效处理等技术领域,借助公司丰富的业务场景、基础设施资源和技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式为公司内部各业务提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。其中数字人方向专注于建设行业领先的数字人生成和驱动技术,丰富智能创作内容生态。
目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。更多大模型算法相关岗位开放中。