卷积神经网络:卷积层,池化层,全连接层
1.卷积层
1.1.卷积操作(方便理解,以二维码图片展示,忽略了通道数)
这个不难理解,我们知道图像在计算机中是由一个个的像素组成的,可以用矩阵表示,假设一个5x5的输入图像,我们定义一个3x3的矩阵(其中的数值是随机生成的)。
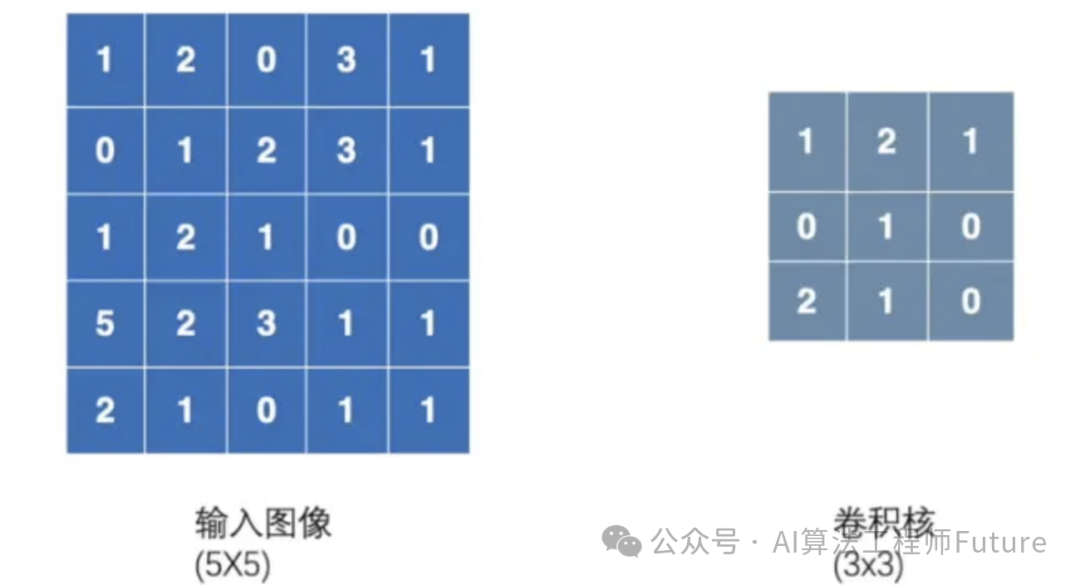
然后我们拿这个卷积核,在输入图像里面,选定左上角那个3x3的矩阵,用卷积核与这个矩阵对应的位置相乘,然后得到的9个数,这9个数再相加,最终得到一个结果。

然后把卷积核往右边挪动一格,继续重复上述计算,再得到一个数字。
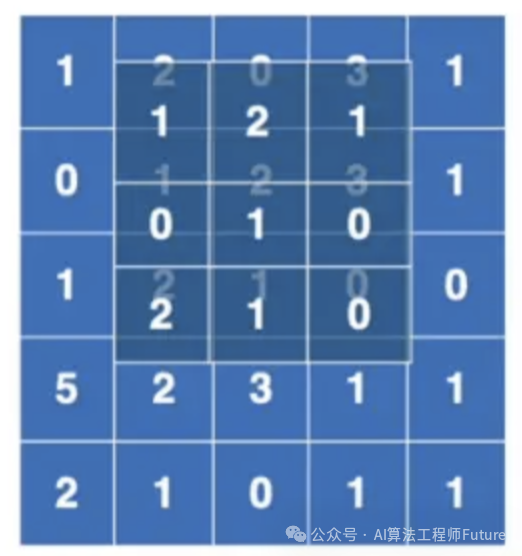
那么算完了,继续往右边挪,再算。
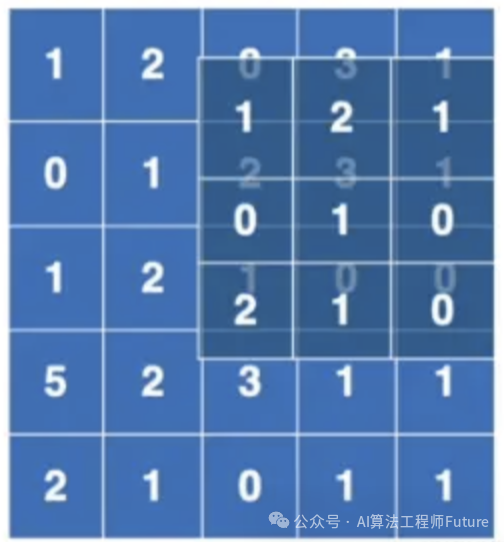
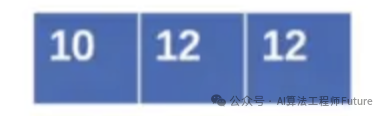
三次计算得到的值是。
然后往下挪一格,继续重复上述操作,直到我们把整个5x5的输入图像全部计算完,得到了9个计算结果。

以上就是我们卷积的结果,这整个操作就是卷积操作。
那么有几个问题:
Q1:每次往右挪动只能是1格吗?A1:不是,挪动1格,就是步长为1,如果我们设置步长为2,那就每次挪动2格,stride步长由我们设置Q2:卷积核里面的数值是怎么设置的?A2:初始是随机生成的(后面会学习更新)Q3:所以经过卷积之后,图像一定变小了?A3:不是的,上面的例子,5x5的输入,卷积之后得到3x3,那么我们如果给5x5的图像填充一圈,就变成了7x7的图像了,再去拿这个卷积核进行卷积,就会得到5x5的输出。实际中,我们也确实是这么做的,有一个参数padding即表示是否填充,我们可以设置填充的范围,以及填充的值,一般填充0。
顺便补充一个公式:
假设输入图片为 W x W 卷积核大小为FxF,步长stride=S,padding设置为P(填充的像素数)则输出图像的大小=(W - F +2P)/S +1
那么,了解了整个卷积的过程,下面这个图就能看懂了,这个图表示的是输入图像为5x5,卷积核为3x3,步长为1,padding=1,所以得到的输出是5x5。
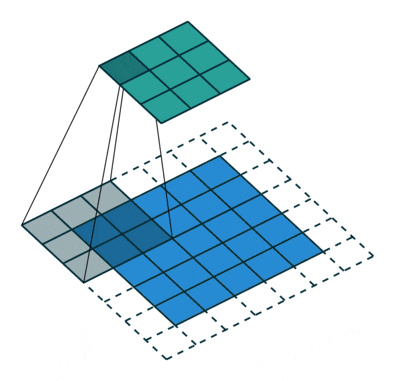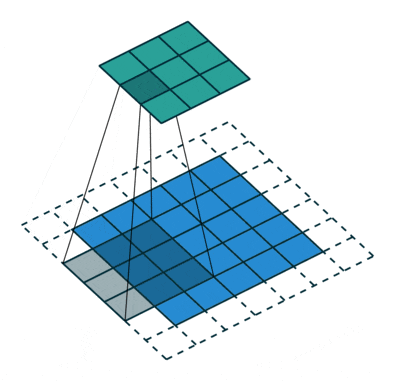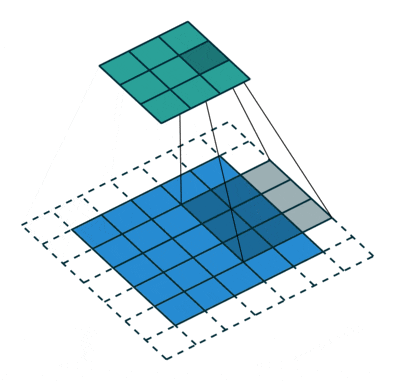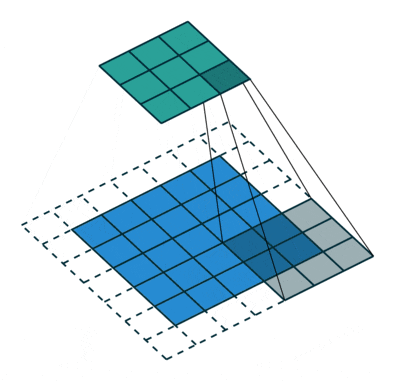
卷积层有很多卷积核,通过做越来越多的卷积,提取到的图像特征会越来越抽象。
1.2.实际操作
卷积的流程是上面讲的那样,实际写代码的时候,我们可以不用那么麻烦,每一步都自己实现。
框架已经帮我们封装好的对应的函数,我们只需要调用函数,传给他相关参数即可。
我们以pytorch框架为例(tensorflow也差不多),Conv2d操作时我们需要设置以下参数:
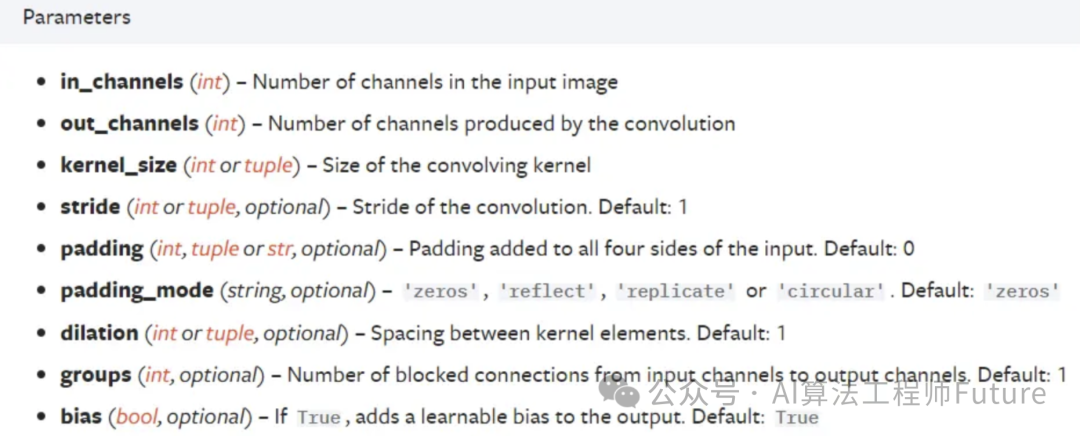
我们解释几个常用的:
-
in_channels:输入的通道数
-
out_channels:输出的通道数
-
kernel_size:卷积核的大小,类型为int 或者元组,当卷积是方形的时候,只需要一个整数边长即可,卷积不是方形,要输入一个元组表示高和宽。(卷积核不需要你设置,只需要给定大小,里面的值是随机生成的)
-
stride:步长(就是每次挪动几个像素,默认是1)
-
padding:填充几圈,默认是0,不填充(填充的值为0)
-
dilation:控制卷积核之间的间距(设置这个可以做空洞卷积)
-
groups:控制输入和输出之间的连接
-
bias:偏置,是否将一个 学习到的 bias 增加输出中,默认是True
-
padding_mode:设置填充的模式
2.池化层
2.1.池化层的作用(降维)
通常会在卷积层之间周期性插入一个池化层,其作用是逐渐降低数据体的空间尺寸,这样就能够减少网络中参数的数量,让池化后的一个像素对应前面图片中的一个区域,减少计算资源耗费,同时也能够有效地控制过拟合。
常见的池化操作有最大池化和平均池化,池化层是由n×n大小的矩阵窗口滑动来进行计算的,类似于卷积层,只不过不是做互相关运算,而是求n×n大小的矩阵中的最大值、平均值等。
如图,对特征图进行最大池化和平均池化操作:
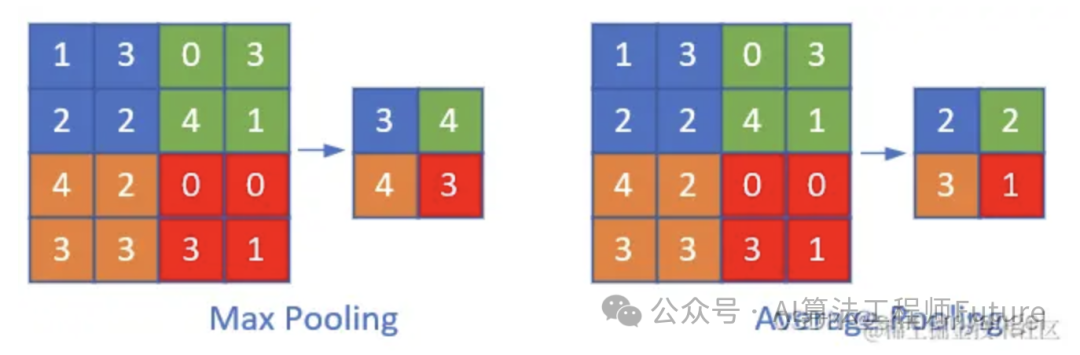
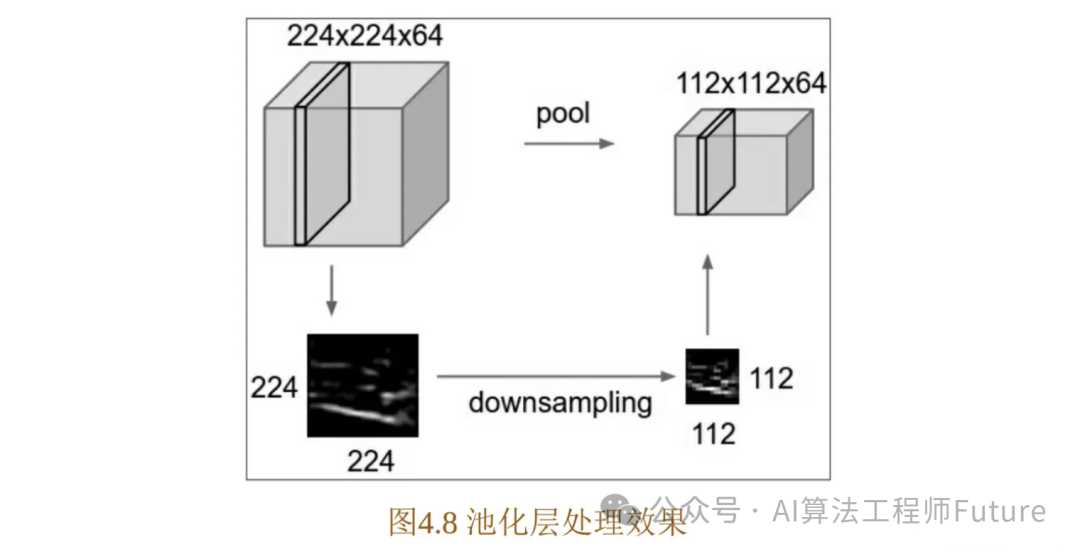
从上图能够看出池化层能够有效降低数据体空间的大小。
池化层之所以有效,是因为之前介绍的图片特征具有不变性,也就是通过下采样不会丢失图片拥有的特征,由于这种特性,我们可以将图片缩小再进行卷积处理,这样能够大大降低卷积运算的时间。最常用的池化层形式是尺寸为2×2的窗口,滑动步长为2,对图像进行下采样,将其中75%的激活信息都丢掉,选择其中最大的保留下来,这其实是因为我们希望能够更加激活里面的数值大的特征,去除一些噪声信息。
3.全连接层
池化层的后面一般接着全连接层,全连接层将池化层的所有特征矩阵转化成一维的特征大向量,全连接层一般放在卷积神经网络结构中的最后,用于对图片进行分类,到了全连接层,我们的神经网络就要准备输出结果了。
如下图所示,倒数第二列的向量就是全连接层的数据。
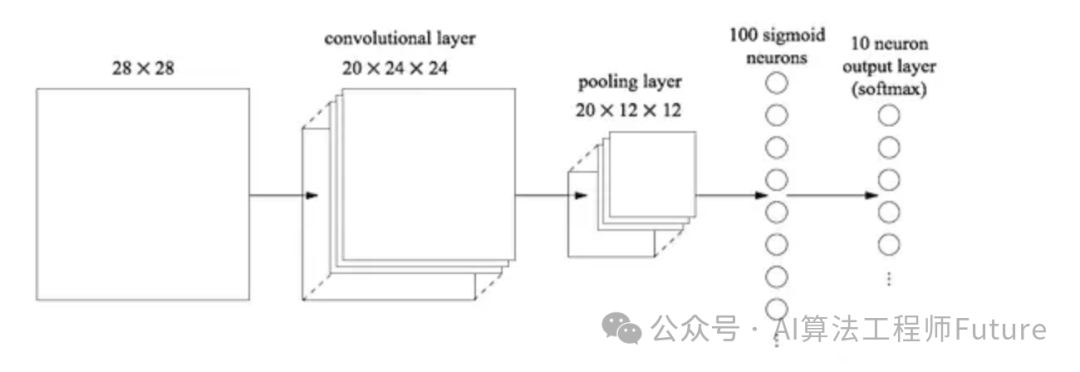
从池化层到全连接层会进行池化操作,数据会进行多到少的映射,进行降维,也就是为什么上图从20×12×12变成100个神经元了,数据在慢慢减少,说明离输出结果越来越近,从全连接层到输出层会再一次减少数据,变成更加低维的向量,这个向量的维度就是需要输出的类别数。然后将这个向量的每个值转换成概率的表示,这个操作一般叫做softmax,softmax使得向量中每个值范围在(0,1)之间,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
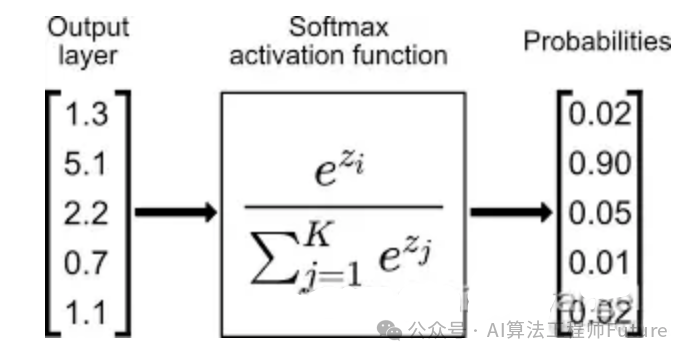
因为从卷积层过来的数据太多了,全连接层的作用主要是对数据进行降维操作,不然数据骤降到输出层,可能会丢失一些图像特征的重要信息。
4.可视化例子
我们可以用一个实际的网络LeNET5来看一下我们刚才的解释。
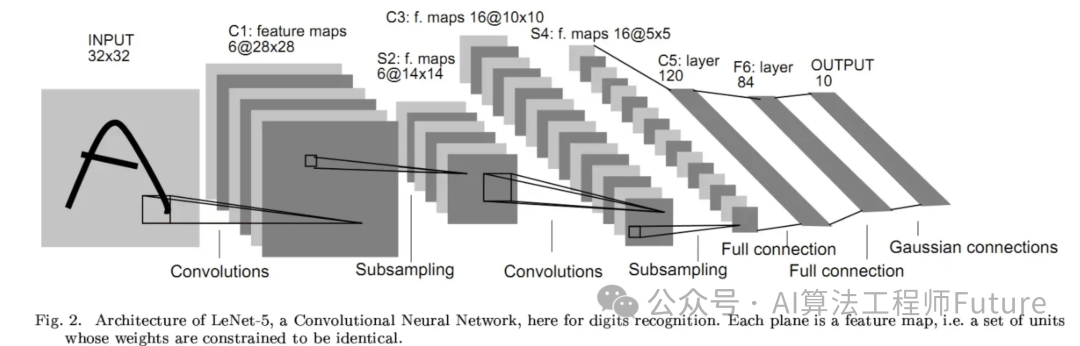
这个输入一张32x32的手写数字图片。6@28x28代表:
-
第一卷积层的输出通道是6,输出大小为28x28;
-
第二个是池化层,通道数不变,还是6,大小减半,变成了14x14;
-
第三个还是卷积层,16通道,大小10x10;
-
然后第四个是池化层,16通道,大小5x5;
-
最后跟两个全连接层;
-
最后是输出结果。
LeNET5第一层是一个卷积层,其输入数据是32x32x1,卷积核大小5x5,步长=1,padding=0,输出为6@28×28;那么,这里输入是单通道的,也就是in_channels=1,那么filter的深度也就是1了,但是输出通道要求是6,也就是out_channels=6,也就是需要6个filter,最终得到6个28x28的图像。
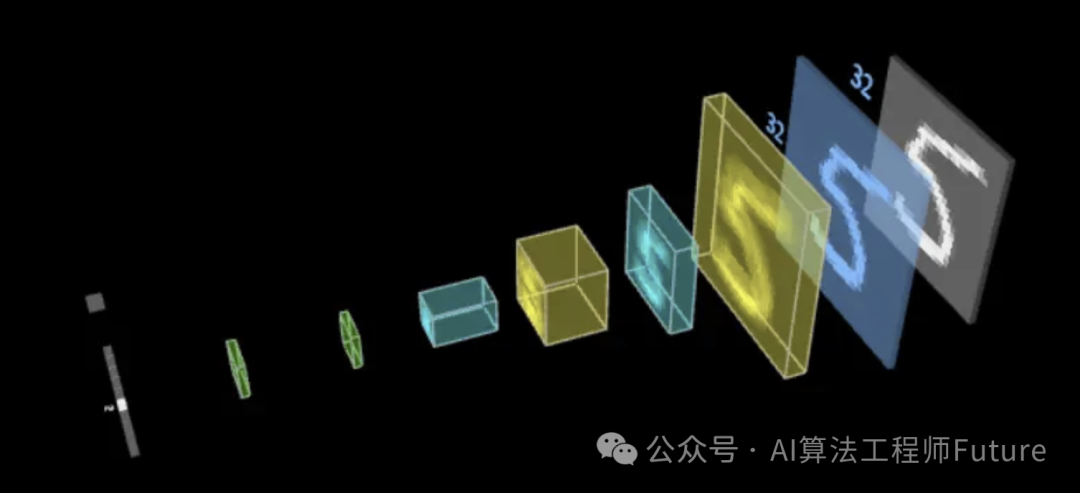
如图:这是整个LeNET5的网络可视化模型,蓝色的那个是32x32的,经过卷积,得到了下一层,也就是黄色的那一层,你可以看到,黄色的那一层是一个立方体,我们可以把他展开看看。
可以看到:展开后确实就是6个28x28的结果
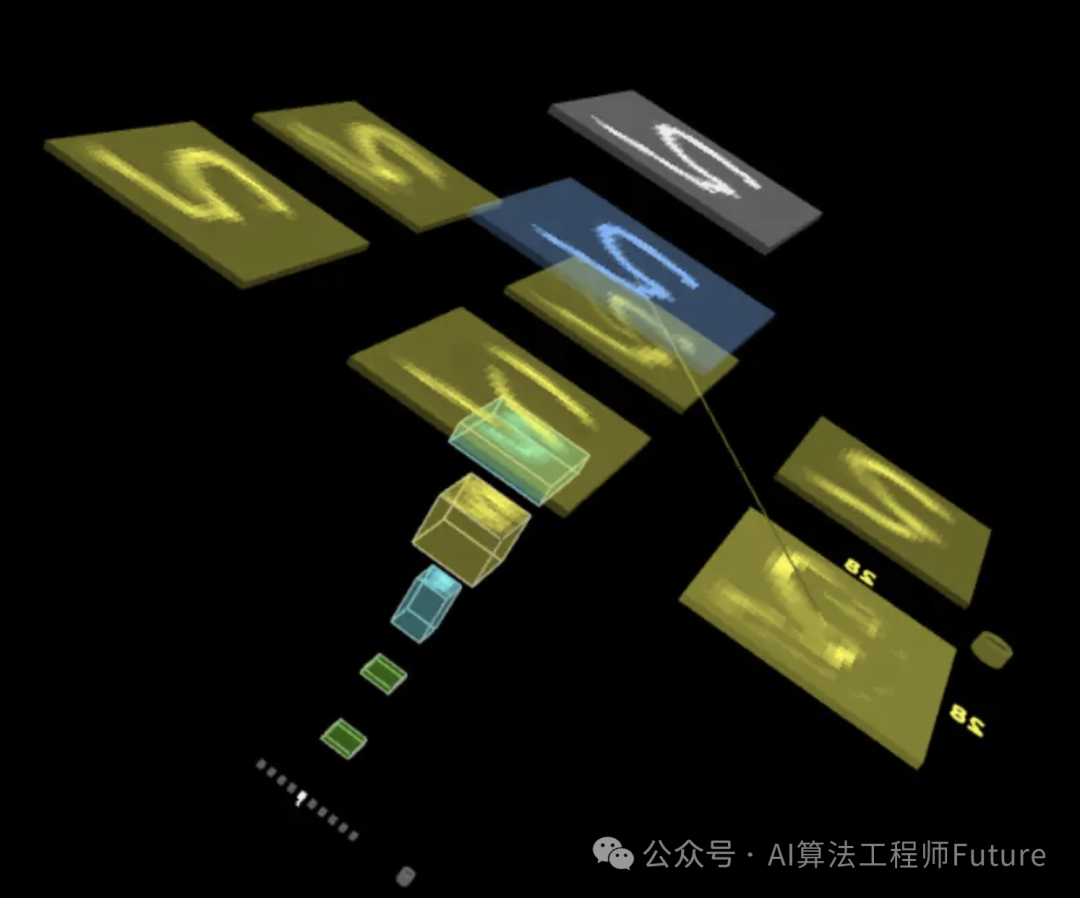
这个可视化的网站地址是:https://tensorspace.org/index.html