GPU的使用寿命可能只有1~3年
在当今高度依赖人工智能(AI)和高性能计算(HPC)的时代,数据中心的图形处理单元(GPU)成为了关键的计算资源。然而,根据Tech Fund援引的一位未具名的Alphabet高级专家的说法,这些昂贵的GPU在数据中心的使用寿命可能只有短短的一到三年时间。

在现代数据中心里,GPU主要负责AI训练和推理等计算密集型任务。由于这些任务要求极高,GPU经常处于高负荷状态,这导致其磨损速度比其他硬件组件更快。尤其是对于云计算服务提供商(CSP)而言,其数据中心中的GPU利用率介于60%至70%之间,这种高利用率会进一步缩短GPU的预期寿命。
根据这位据称来自Alphabet的主要生成式AI架构师的说法,当GPU处于上述的高利用率状态时,其预期寿命一般在一年到两年之间,最长不超过三年。这主要是因为现代数据中心GPU为了支持AI和HPC应用,通常需要功耗达到几百瓦,这对于微小的硅片来说是一种实质性的压力。
据这位发言者所说,延长GPU寿命的一种方法是降低其利用率。然而,这样做会减缓GPU的折旧速度,进而影响资本回报速度,这显然不是商业上的最优选择。因此,大多数云计算服务提供商更倾向于让其GPU维持在一个较高的利用率水平上运作。
今年早些时候,Meta公司发布的一项研究表明,他们使用由16,384块Nvidia H100 80GB GPU组成的集群来训练Llama 3 405B模型。尽管集群的模型浮点运算利用率(MFU)为约38%(使用BF16精度),但在54天的预训练快照期间,总共发生了419次未预见的中断事件,其中有148次(占比30.1%)是由各种GPU故障(包括NVLink故障)引起的,另外72次(17.2%)则是由HBM3内存故障造成的。
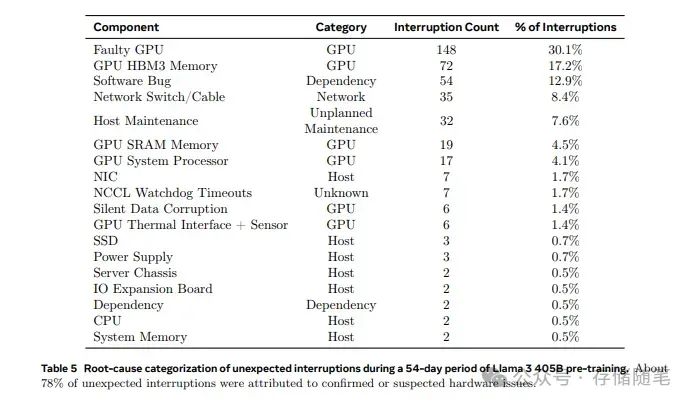
Meta的研究结果显示,H100 GPU在故障率方面似乎表现不错。如果GPU及其内存的故障率与Meta的统计相符,那么这些处理器的年度故障率约为9%,而在三年内的年度故障率则大约为27%。不过,考虑到GPU在服役一年后可能会出现更频繁的故障,这一估计可能过于乐观。
随着AI和HPC应用的不断发展,数据中心对GPU的需求只会越来越大。然而,GPU的短寿命周期给数据中心的运维带来了挑战。未来,寻找有效的方法来管理和延长GPU的使用寿命,以及开发更加耐用的GPU架构,将是业界面临的重要课题。与此同时,数据中心运营商也需要重新评估其硬件更新策略,以应对不断变化的技术需求和日益增长的计算负载。
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
PCIe SSD在温变环境的稳健性技术剖析
-
2024 NAND领域的机遇与挑战
-
SSD在低地球轨道卫星应用中的挑战
-
CXL内存技术:有效提高GPU利用率
-
这可能是最清晰的AI存储数据流动图解
-
DWPD指标:为何不再适用于大容量SSD?
-
突破内存墙:DRAM的过去、现在与未来
-
E1.S接口如何解决SSD过热问题?
-
ZNS SSD是不是持久缓存的理想选择?
-
存储正式迈入超大容量SSD时代!
-
FMS 2024: 带来哪些存储技术亮点?
-
IEEE报告解读:存储技术发展趋势分析
-
什么?陶瓷也可以用来存储数据了?
-
都说固态硬盘寿命短,那么谁把使用寿命用完了吗?
-
内存原生CRAM技术将会颠覆计算存储的未来?
-
浅析SSD性能与NAND速率的关联
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!