利用langchain-ChatGLM、langchain-TigerBot实现基于本地知识库的问答应用
目录
1 原理
2 langchain-ChatGLM的开发部署
2.1 安装环境
2.2 加载本地模型
3 langchain-TigerBot的开发部署
刷B站的时候,无意中看到吴恩达的一个langchain的教程,然后去github上搜了下,发现别人利用langchain和chatGLM做的基于本地知识库的问答应用挺好的,学习下,同时增加了利用langchain-TigerBot实现的本地知识库。
1 原理

基于本地知识库的问答应用原理如上图,首先把本地知识库的文档分割成片段,然后利用embedding模型将文字用向量表示,然后保存到向量库中,然后我们提问的问题也用向量表示,然后将我们的问题和向量库的向量进行匹配,得到相似的结果,然后组装成prompt,送到语言模型中,得到我们想要的答案,

 然后我看刘虔的培训教程中有个这样的代码示例
然后我看刘虔的培训教程中有个这样的代码示例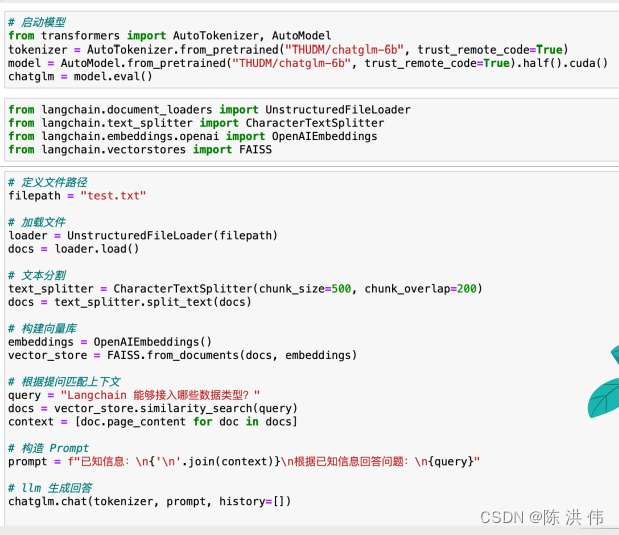
我的理解其实就是从文档中搜索出问题和答案,然后一起送到大模型,让大模型生成回答。
2 langchain-ChatGLM的开发部署
2.1 安装环境
langchain-ChatGLM/docs/INSTALL.md at master · imClumsyPanda/langchain-ChatGLM · GitHub
conda create -n langchain-chatglm-chw python=3.8
conda activate langchain-chatglm-chw
# 拉取仓库
$ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
# 进入目录
$ cd langchain-ChatGLM
# 项目中 pdf 加载由先前的 detectron2 替换为使用 paddleocr,如果之前有安装过 detectron2 需要先完成卸载避免引发 tools 冲突
$ pip uninstall detectron2
# 检查paddleocr依赖,linux环境下paddleocr依赖libX11,libXext
$ yum install libX11 #sudo apt-get install libx11-dev
$ yum install libXext #sudo apt-get install libxext-dev
# 安装依赖
$ pip install -r requirements.txt
# 验证paddleocr是否成功,首次运行会下载约18M模型到~/.paddleocr
$ python loader/image_loader.py然后执行 python loader/image_loader.py会报错
Traceback (most recent call last):
File "loader/image_loader.py", line 8, in <module>
from configs.model_config import NLTK_DATA_PATH
ModuleNotFoundError: No module named 'configs'
在github的issue里面搜索configs这个关键字发现
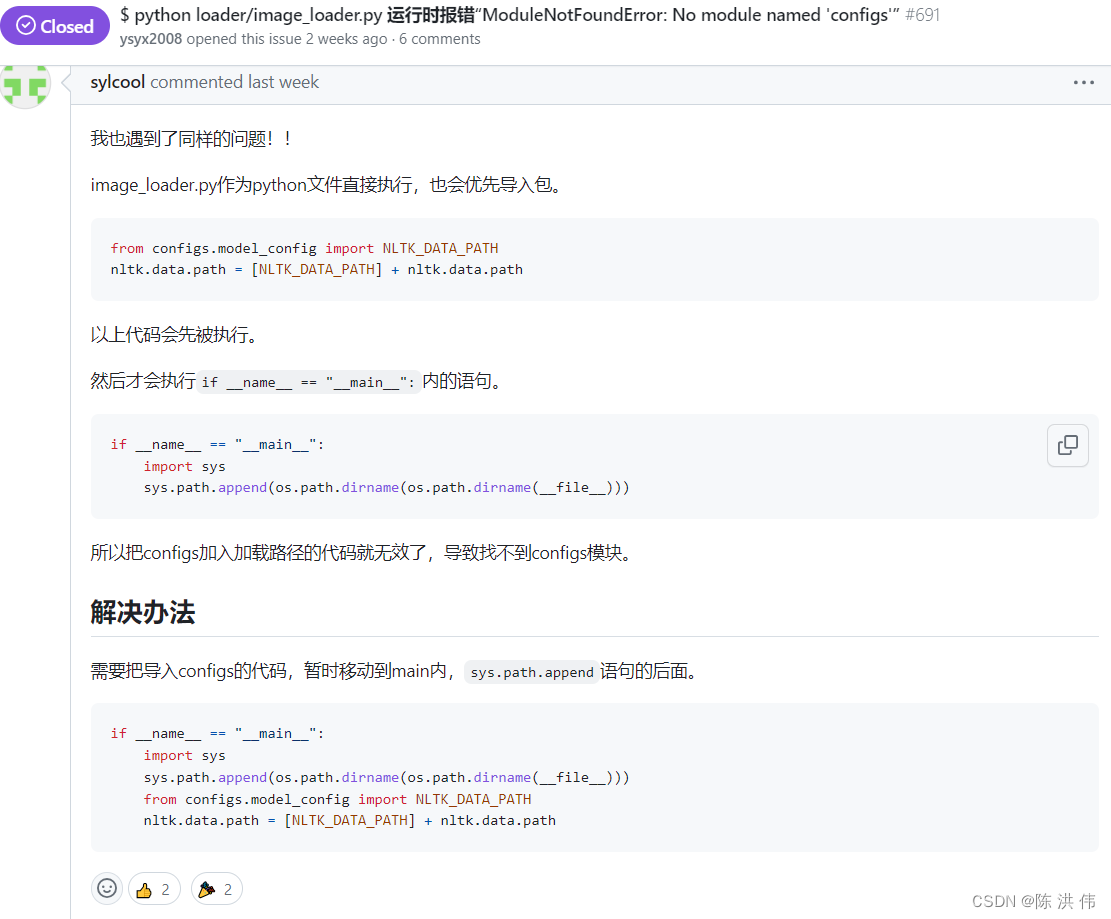
按照这个修改了之后发现,出现了这个报错
Traceback (most recent call last):
File "loader/image_loader.py", line 36, in <module>
from configs.model_config import NLTK_DATA_PATH
ModuleNotFoundError: No module named 'configs.model_config'然后继续在issues中搜索configs.model_config'
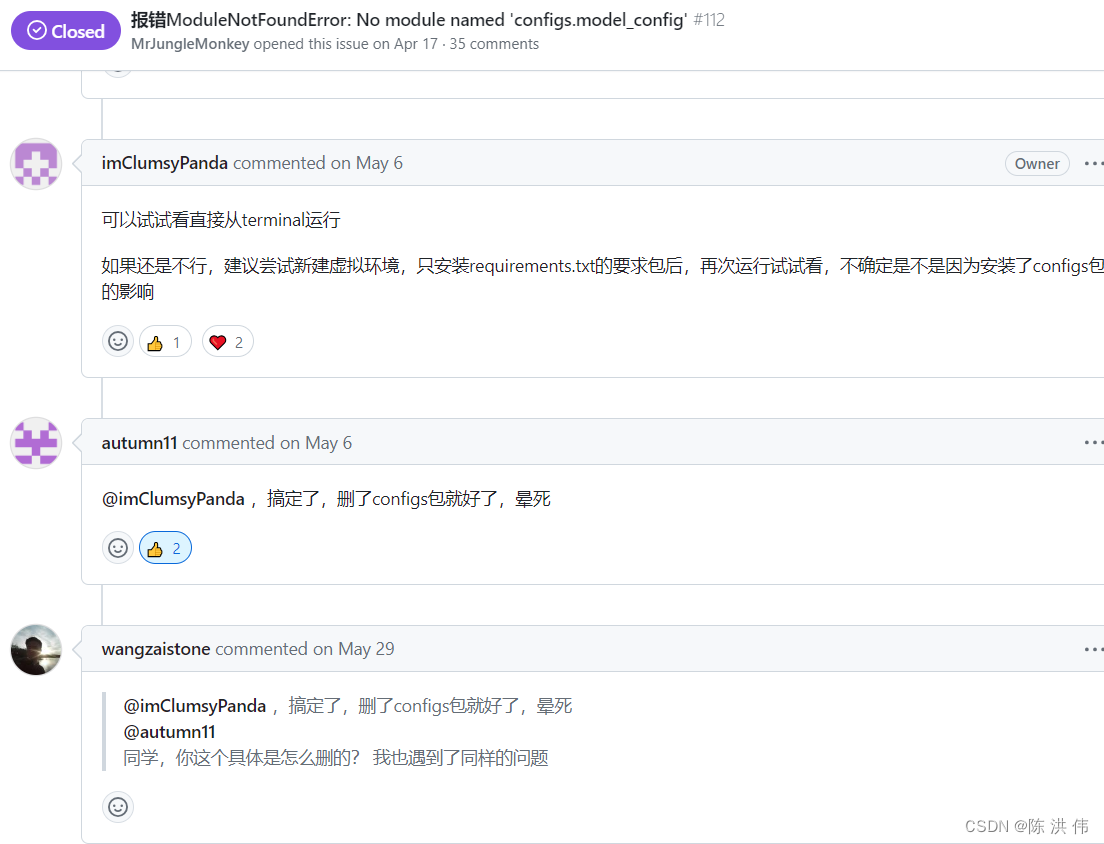
好吧,原因是python库中有个configs包,我们的工程中也有个configs文件夹,我们应该是要去工程文件夹configs中找而不是python的configs库中找,所以用下面命令卸载configs库就好了
pip uninstall configs注:使用 langchain.document_loaders.UnstructuredFileLoader 进行非结构化文件接入时,可能需要依据文档进行其他依赖包的安装,请参考 langchain 文档。
那我去看一下加载非结构化文档需要安装什么:Unstructured File | 🦜️🔗 Langchain
# # Install package
pip install "unstructured[local-inference]"
pip install layoutparser[layoutmodels,tesseract]把模型拷贝过去,并且重命名一下,
2.2 加载本地模型
在我体验chatGLM模型的时候,已经下载过模型里,所以这里我直接用本地模型,我把模型拷贝过来,然后修改python文件,将None修改为我的模型路径,

然后使用如下脚本
python cli_demo.py --model chatglm-6b --no-remote-model得到
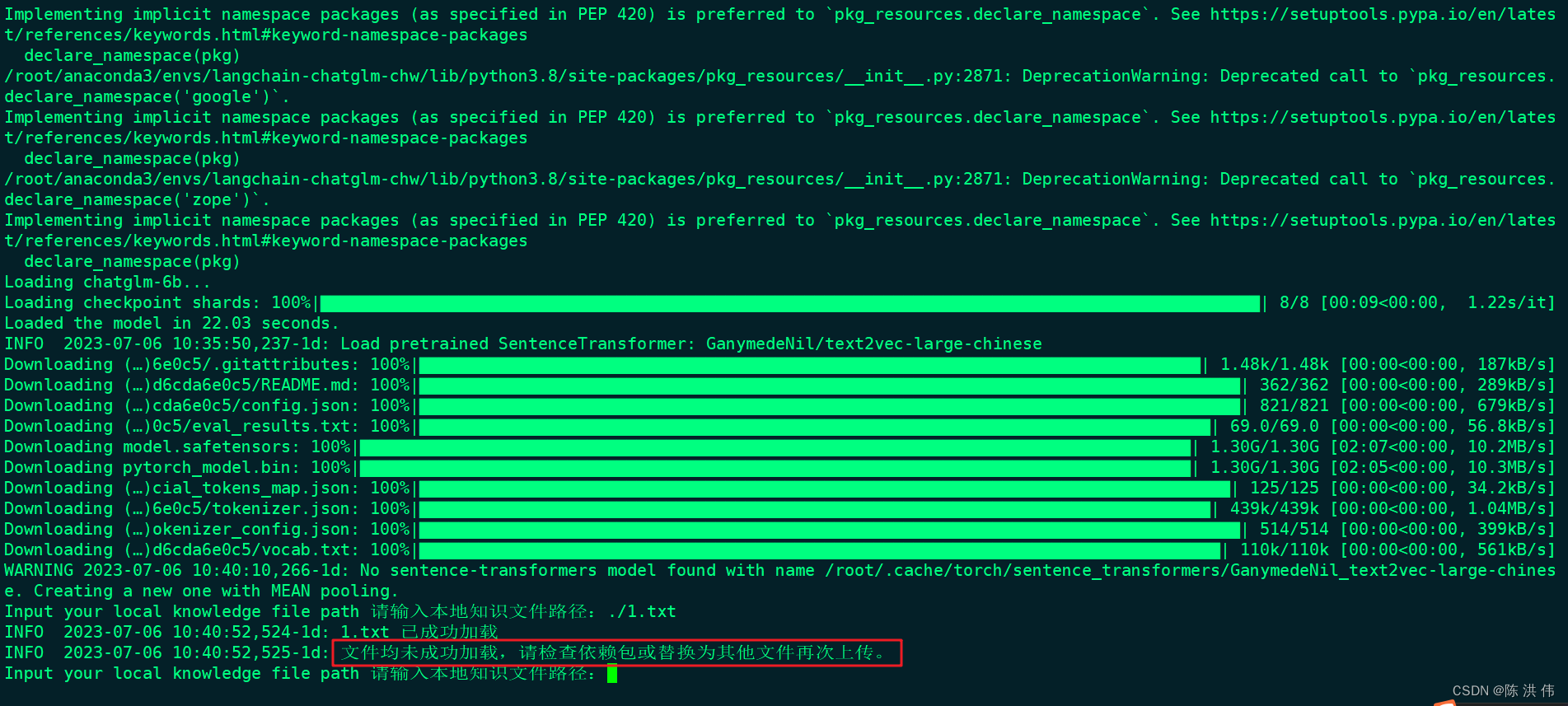
我先用工程自带的README.md试试
然后试一下web版本的,

好吧,报错了,那我把embedding模型下载到本地,我去github上搜GanymedeNil/text2vec-large-chinese没搜到结果,那直接google搜索
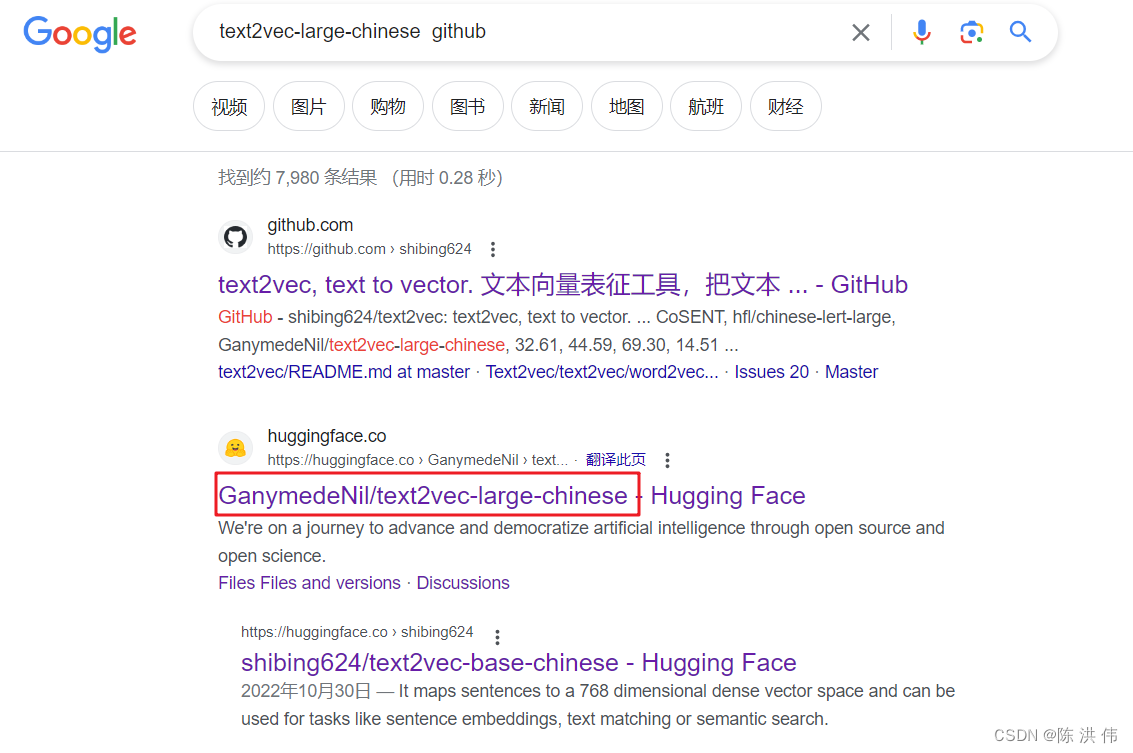
然后找到GanymedeNil/text2vec-large-chinese · Hugging Face
好,开始下载,由于模型文件特别大,因此还是要用lfs
git lfs install
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese然后修改python脚本
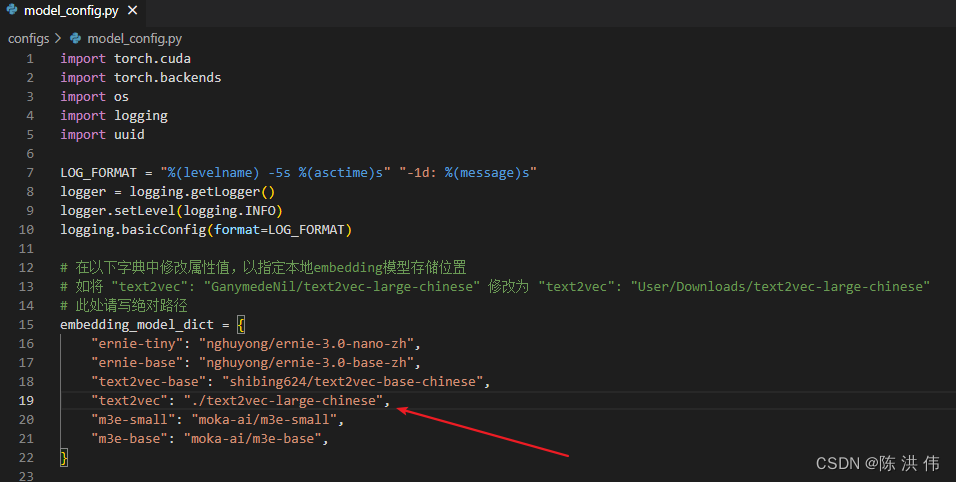
然后再试一下
python webui.py --model chatglm-6b --no-remote-model这次可以了

然后就可以浏览器登录了

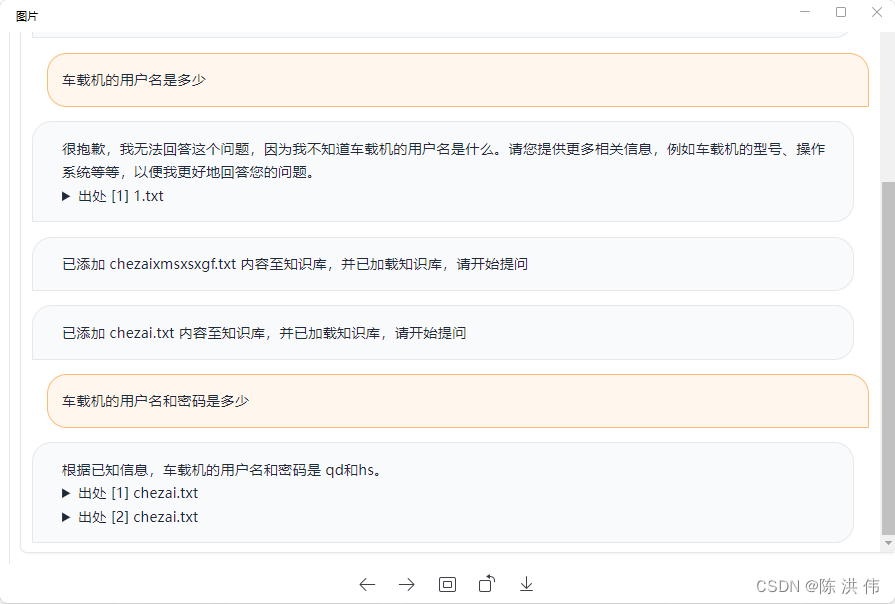
然后我提问问题,他不知道

这时候我在文档中增加如下内容
然后上传,再次提问问题
3 langchain-TigerBot的开发部署
做完上面的ChatGLM的部署,发现github上还有个:GitHub - wordweb/langchain-ChatGLM-and-TigerBot: 从langchain-ChatGLM基础上修改的一个可以加载TigerBot模型的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
于是再部署下TigerBot,首先搭建环境,这里直接把上面的conda环境复制一份。
cp -drf langchain-chatglm-chw langchain-chatglm-and-TigerBot-chw然后把之前下载的模型都拷贝过来

然后修改model_config .py的这几个地方


还有models/init.py修改成这样
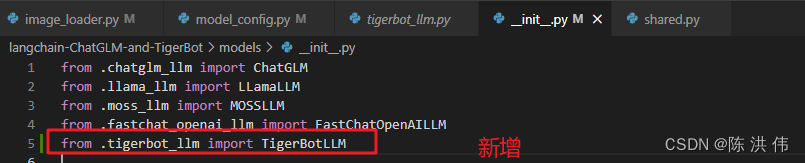
否则会报下面的错误, 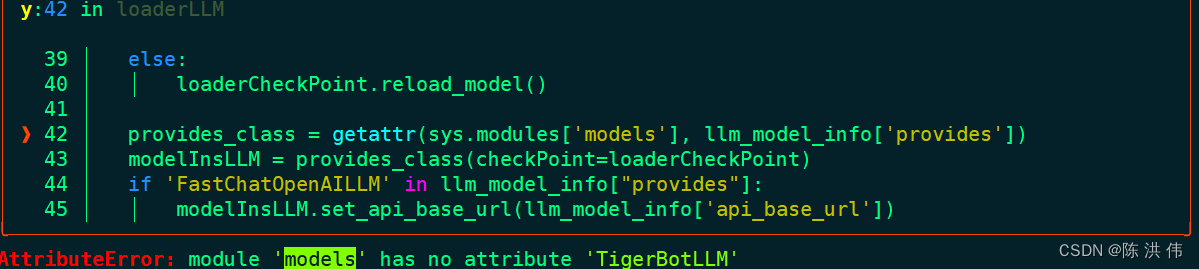
然后用下面的命令启动,
CUDA_VISIBLE_DEVICES=0 python webui.py --no-remote-model得到下面的界面
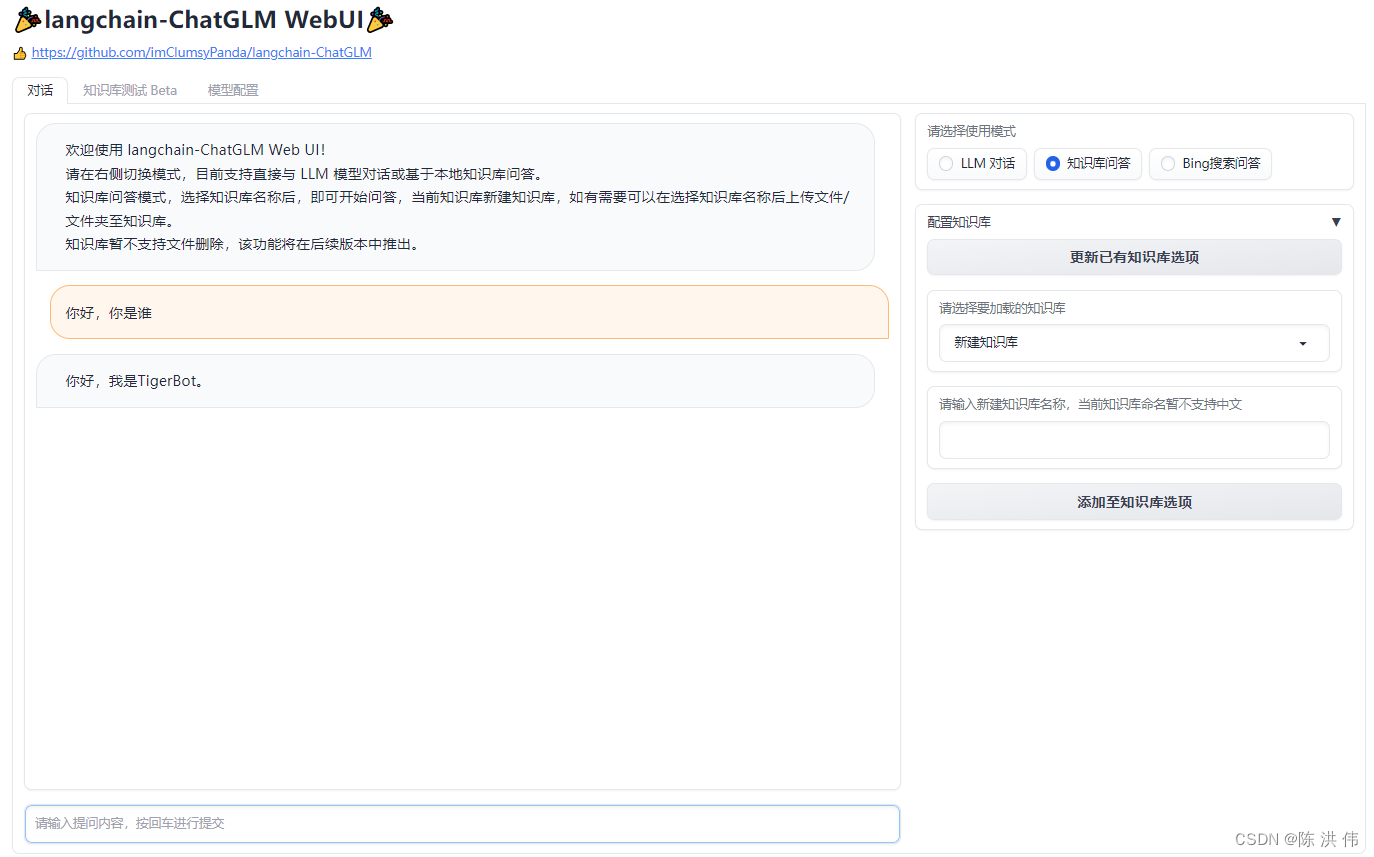
参考文献:
【官方教程】ChatGLM + LangChain 实践培训_哔哩哔哩_bilibili
https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/StartOption.md
GitHub - imClumsyPanda/langchain-ChatGLM: langchain-ChatGLM, local knowledge based ChatGLM with langchain | 基于本地知识库的 ChatGLM 问答