基于PyTorch的大语言模型微调指南:Torchtune完整教程与代码示例
近年来,大型语言模型(Large Language Models, LLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了显著进展。这些模型通过在大规模文本数据上进行预训练,能够习得语言的基本特征和语义,从而在各种NLP任务上取得了突破性的表现。为了将预训练的LLM应用于特定领域或任务,通常需要在领域特定的数据集上对模型进行微调(Fine-tuning)。随着LLM规模和复杂性的不断增长,微调过程面临着诸多挑战,如计算资源的限制、训练效率的瓶颈等。

Torchtune是由PyTorch团队开发的一个专门用于LLM微调的库。它旨在简化LLM的微调流程,提供了一系列高级API和预置的最佳实践,使得研究人员和开发者能够更加便捷地对LLM进行调试、训练和部署。Torchtune基于PyTorch生态系统构建,充分利用了PyTorch的灵活性和可扩展性,同时针对LLM微调的特点进行了优化和改进。
Torchtune的核心设计原则
Torchtune的设计遵循以下四个核心原则:
- 简单性和可扩展性:Torchtune采用原生PyTorch的设计风格,提供模块化的组件和接口。这使得用户能够根据自己的需求,轻松地对现有功能进行修改和扩展,构建定制化的微调流程。同时,Torchtune也提供了一系列开箱即用的工具和模块,降低了用户的使用门槛。
- 正确性:LLM微调对训练数据和算法实现的正确性有着较高的要求。Torchtune中的各个组件和模块都经过了严格的单元测试和验证,确保了其输出结果的可靠性。Torchtune还提供了一系列调试和分析工具,帮助用户快速定位和解决训练过程中遇到的问题。
- 稳定性:Torchtune构建在PyTorch的稳定版本之上,并针对LLM微调场景进行了充分的测试和优化。用户可以在各种硬件环境下稳定地运行Torchtune,不必担心兼容性和稳定性问题。
- 可访问性:Torchtune的一个重要目标是让更多的用户能够参与到LLM的开发和应用中来。因此,Torchtune提供了详细的文档和教程,以及常见问题的解决方案。Torchtune还提供了一系列预训练模型和数据集,降低了用户的入门成本。
Torchtune的主要特性
Torchtune提供了以下主要特性,以支持LLM的微调任务:
- 模块化的PyTorch实现:Torchtune实现了当前主流的LLM架构,如Transformer、GPT、BERT等。用户可以直接使用这些模块,也可以基于它们构建自己的模型。
- 数据集和评测工具的集成:Torchtune与Hugging Face的Datasets库和EleutherAI的Eval Harness无缝集成,提供了丰富的数据集资源和标准化的评测方案。用户可以方便地访问和使用这些资源,也可以将自己的数据集和评测方案集成到Torchtune中。
- 高效的分布式训练:Torchtune支持多种并行训练方式,如数据并行、模型并行、流水线并行等。特别地,Torchtune针对LLM微调实现了Fully Sharded Data Parallel v2 (FSDP2),可以显著地加速大规模模型的训练速度,并减少显存占用。
- 基于配置文件的任务管理:Torchtune使用YAML格式的配置文件来管理微调任务的参数和流程。用户可以通过修改配置文件,灵活地控制训练过程,而无需修改代码。Torchtune还提供了一系列预置的配置文件和脚本,进一步简化了任务的管理和执行。
Torchtune是一个专为LLM微调设计的PyTorch库,其目标是让LLM的开发和应用变得更加简单、高效、可靠。Torchtune提供了模块化的组件、高级的API、丰富的数据资源、先进的并行训练技术,以及基于配置文件的任务管理方式。Torchtune在提高LLM微调效率的同时,也大大降低了用户的使用门槛,使更多的研究人员和开发者能够参与到LLM的开发和应用中来。
在接下来的内容中,我们将介绍Torchtune中的一些关键概念,并通过实例展示如何使用Torchtune进行LLM微调。我们也会探讨一些高阶的主题,如LoRA和QLoRA等参数高效的微调方法。
Torchtune中的关键概念
Torchtune引入了两个关键概念:配置(Config)和方案(Recipe)。这两个概念抽象了LLM微调任务的参数和流程,使得用户能够以更加灵活和高效的方式管理微调任务。
配置(Config)
在Torchtune中,配置以YAML文件的形式存在。每个配置文件定义了一个完整的微调任务,包括:
- 数据集的路径和格式
- 模型的架构和参数
- 优化器的类型和超参数
- 训练的批大小、学习率、迭代次数等
- 评测和日志的设置
通过使用配置文件,用户可以将微调任务的参数与代码实现解耦。这样,用户可以通过修改配置文件来快速地试验不同的设置,而无需修改代码。同时,配置文件也提高了任务的可重复性和可移植性。
下面是一个简单的配置文件示例:
dataset:
path: /path/to/dataset
format: json
fields:
- name: text
type: string
- name: label
type: int
model:
type: transformer
params:
num_layers: 12
hidden_size: 768
num_attention_heads: 12
optimizer:
type: AdamW
params:
lr: 0.001
weight_decay: 0.01
train:
batch_size: 32
num_epochs: 10
log_interval: 100
evaluate:
batch_size: 64
metric:
- accuracy
- f1
方案(Recipe)
方案是Torchtune提供的一系列预置的微调流程。每个方案都针对特定的场景和任务,提供了一套优化的实现和最佳实践。用户可以直接使用这些方案,也可以基于它们进行定制和扩展。
Torchtune内置了多个常用的方案,如:
lora_finetune_single_device:单设备上使用LoRA进行微调lora_finetune_distributed:多设备分布式环境下使用LoRA进行微调qlora_finetune:使用QLoRA进行参数高效微调distill_finetune:使用知识蒸馏技术进行微调
每个方案都定义了一个完整的微调流程,包括数据处理、模型初始化、优化器选择、训练循环、评测和日志等。方案通过组合Torchtune提供的各种模块和工具,实现了端到端的自动化微调。
下面是一个使用
lora_finetune_single_device
方案进行微调的示例:
tune run lora_finetune_single_device \
--config configs/llama2/7B_lora_single_device.yaml \
--train.batch_size 128 \
--optimizer.params.lr 0.0001
在这个例子中,我们使用
lora_finetune_single_device
方案在单个设备上对LLaMA-2-7B模型进行微调。我们指定了配置文件的路径,并通过命令行参数覆盖了原始配置中的
train.batch_size
和
optimizer.params.lr
参数。
Torchtune的配置和方案机制提供了一种灵活、高效、可复用的方式来管理LLM微调任务。通过使用配置文件和预置方案,用户可以快速启动微调任务,并以极低的成本试验不同的优化策略。
小结
Torchtune中的配置和方案是管理LLM微调任务的两个关键抽象。配置以YAML文件的形式存在,定义了微调任务的各种参数;方案则提供了一系列预置的、经过优化的端到端微调流程。通过灵活地组合配置和方案,用户可以以极低的成本开展LLM微调的实验和优化。
在接下来的内容中,我们将通过一个完整的实例,展示如何使用Torchtune进行LLM微调。我们也会介绍一些高阶的微调技术,如LoRA和QLoRA。
使用Torchtune微调LLM
在这一节中,我们将通过一个完整的实例,展示如何使用Torchtune微调LLM。我们会使用Torchtune提供的
lora_finetune_single_device
方案,在单个GPU设备上对LLaMA-2-7B模型进行微调。
准备工作
在开始之前,请确保你已经正确安装了Torchtune,并且可以访问Hugging Face Hub。Hugging Face Hub中托管了许多常用的预训练语言模型,如LLaMA、GPT、BERT等。你需要先注册一个Hugging Face账号,并获取访问Tokens。
下载预训练模型
首先,我们需要下载一个预训练的语言模型。在这个例子中,我们使用Meta发布的LLaMA-2-7B模型,这是一个在Hugging Face Hub上的开源模型。我们可以使用以下命令下载这个模型:
tune download meta-llama/Llama-2-7b-hf \
--output-dir /tmp/Llama-2-7b-hf \
--hf-token <ACCESS TOKEN>
这个命令会将LLaMA-2-7B模型下载到
/tmp/Llama-2-7b-hf
目录下,其中
<ACCESS TOKEN>
需要替换为你自己的Hugging Face访问Token。除了模型的参数,这个命令还会下载对应的Tokenizer和一些其他的文件,如模型卡片、使用许可等。
选择微调方案
Torchtune提供了多个预置的微调方案,适用于不同的场景和任务。你可以通过以下命令查看所有可用的方案:
tune ls
在这个例子中,我们选择
lora_finetune_single_device
方案。这个方案使用LoRA(Low-Rank Adaptation)技术在单个GPU设备上对LLM进行微调。LoRA通过引入低秩的适配器参数,在不改变原始模型参数的情况下,实现对模型的微调。这种方法可以显著减少微调过程中的内存消耗和计算开销,使得在单个GPU上微调大型LLM成为可能。
配置微调任务
每个微调方案都有一个对应的配置文件,定义了微调任务的各种参数。
lora_finetune_single_device
方案的默认配置文件路径为
llama2/7B_lora_single_device.yaml
。我们可以直接使用这个配置文件,也可以在此基础上进行修改。
Torchtune支持两种方式来修改配置文件:
- 通过命令行参数覆盖配置文件中的参数:
tune run lora_finetune_single_device \
--config llama2/7B_lora_single_device.yaml \
train.batch_size=128 \
train.num_epochs=5
- 将配置文件复制到本地,然后直接修改配置文件:
tune cp llama2/7B_lora_single_device.yaml custom_config.yaml
修改
custom_config.yaml
文件,然后运行:
tune run lora_finetune_single_device \
--config custom_config.yaml
通过灵活地使用这两种方式,我们可以方便地控制微调任务的各种参数,如数据集、批大小、学习率、训练轮数等。
启动微调任务
配置文件准备好之后,我们就可以启动微调任务了。使用以下命令启动
lora_finetune_single_device
方案:
tune run lora_finetune_single_device \
--config llama2/7B_lora_single_device.yaml
Torchtune会自动加载预训练模型、Tokenizer、数据集等,并开始微调过程。在微调过程中,Torchtune会实时记录训练损失、评测指标、GPU使用情况等信息,方便用户监控训练进度和调试模型。
结果展示
下面是我用W&B做的示例结果,这张图时训练的表现
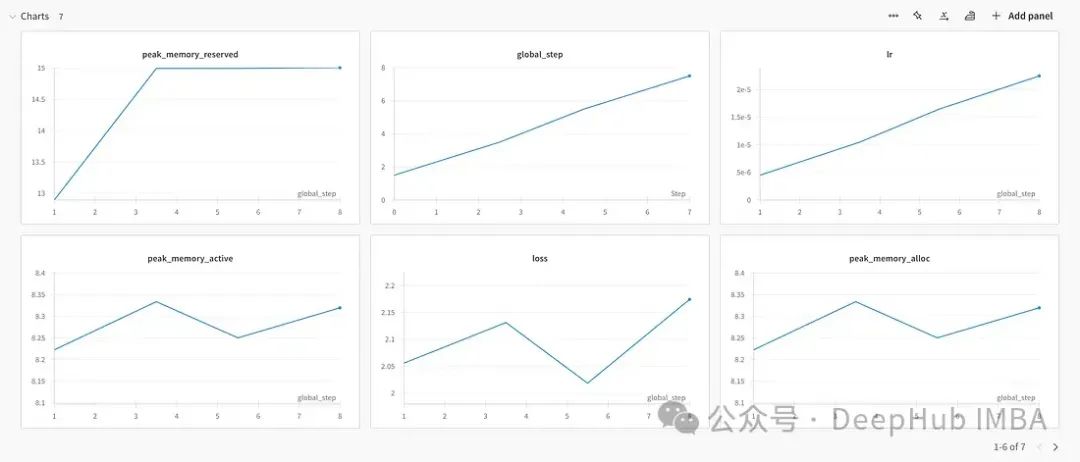
下面是内存的占用
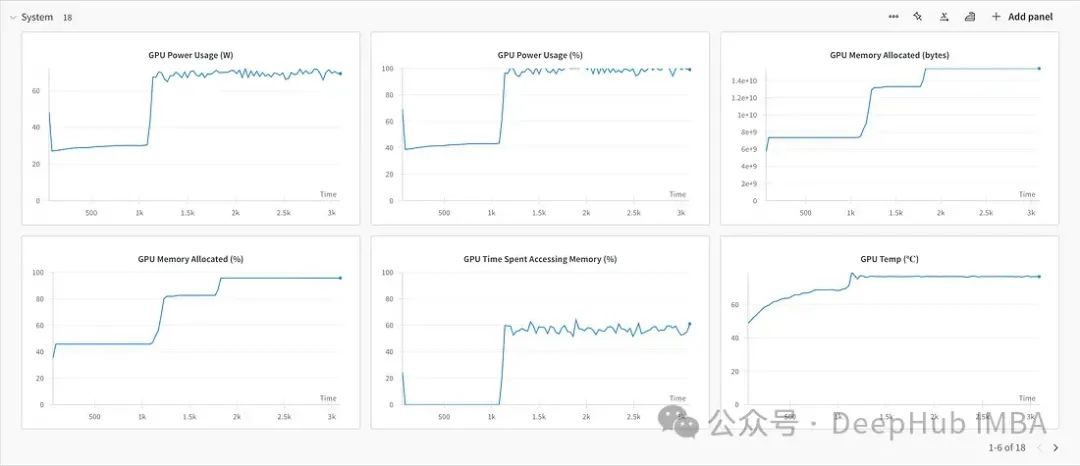
保存和使用微调后的模型
微调完成后,我们可以使用以下命令将微调后的模型导出到指定路径:
tune export lora_finetune_single_device \
--output_dir /path/to/output
导出的模型可以直接用于下游任务的推理和服务。我们也可以将导出的模型上传到Hugging Face Hub,方便其他用户使用。
小结
在这一节中,我们通过一个完整的实例,展示了如何使用Torchtune微调LLM。我们使用了
lora_finetune_single_device
方案在单个GPU上对LLaMA-2-7B模型进行了微调。整个过程包括:
- 准备工作:安装Torchtune,注册Hugging Face账号。
- 下载预训练模型:从Hugging Face Hub下载LLaMA-2-7B模型。
- 选择微调方案:选择
lora_finetune_single_device方案。 - 配置微调任务:修改
lora_finetune_single_device方案的默认配置文件。 - 启动微调任务:使用
tune run命令启动微调任务。 - 保存和使用微调后的模型:使用
tune export命令导出微调后的模型。
可以看到,Torchtune大大简化了LLM微调的流程,使得用户可以通过简单的命令行操作完成端到端的微调任务。同时,Torchtune提供了丰富的日志和可视化工具,方便用户监控和调试训练过程。
在接下来的内容中,我们将详细介绍两种参数高效的微调方法:LoRA和QLoRA。我们也会讨论如何使用Torchtune实现这两种方法。
参数高效的微调方法:LoRA和QLoRA
在前面的内容中,我们介绍了如何使用Torchtune微调LLM。然而,随着LLM规模的不断增长,传统的微调方法面临着越来越大的挑战。以LLaMA-2-7B为例,这个模型有70亿个参数,即使在现代的GPU设备上,也难以支持对所有参数的微调。因此,我们需要探索一些参数高效的微调方法,在保证微调效果的同时,降低计算和存储开销。
LoRA:低秩适配
LoRA(Low-Rank Adaptation)是一种参数高效的微调方法,由微软研究院在2021年提出。LoRA的核心思想是在预训练模型的基础上,引入一组低秩的适配器参数。在微调过程中,我们只更新这些适配器参数,而保持预训练模型的参数不变。这样,我们就可以在不增加模型规模的情况下,实现对模型的微调。
具体来说,对于预训练模型中的每个线性层,LoRA引入两个低秩矩阵A和B,将原始的线性变换y = Wx修改为:
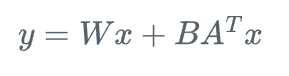
其中
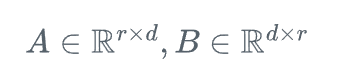
而r是一个远小于d的超参数,称为LoRA秩。在微调过程中,我们只训练和更新矩阵A和B,而保持W不变。由于r远小于d,因此LoRA引入的额外参数数量也远小于原始模型的参数数量。
下面是一个使用Torchtune实现LoRA微调的示例代码:
import torch
from torchtune.models.llama2 import llama2_7b, lora_llama2_7b
from torchtune.modules.peft.peft_utils import get_adapter_params, set_trainable_params
# 加载预训练的LLaMA-2-7B模型
base_model = llama2_7b(weights="/path/to/llama2_7b_weights", tokenizer="/path/to/llama2_tokenizer")
# 在LLaMA-2-7B模型上应用LoRA
lora_model = lora_llama2_7b(
lora_attn_modules=['q_proj', 'v_proj'],
lora_rank=8,
lora_alpha=16
)
# 将预训练权重加载到LoRA模型中
lora_model.load_state_dict(base_model.state_dict(), strict=False)
# 设置只有LoRA参数可训练
lora_params = get_adapter_params(lora_model)
set_trainable_params(lora_model, lora_params)
# 使用torchtune的LoRA微调方案进行训练
tune_command = """
tune run --nnodes 1 --nproc_per_node 2 lora_finetune_distributed --config llama2/7B_lora \
lora_attn_modules=['q_proj', 'k_proj', 'v_proj', 'output_proj'] \
lora_rank=32 lora_alpha=64 output_dir=./lora_experiment_1
"""
在这个例子中,我们首先加载了预训练的LLaMA-2-7B模型,然后在其上应用了LoRA。我们在attention层的query和value投影矩阵上引入了LoRA适配器,适配器的秩为8。接着,我们使用
load_state_dict
函数将预训练权重加载到LoRA模型中,并通过
set_trainable_params
函数设置只有LoRA参数是可训练的。最后,我们使用torchtune的
lora_finetune_distributed
方案在多个GPU上对LoRA模型进行微调。
通过引入LoRA,我们可以将微调过程中需要训练和更新的参数数量减少到原来的1%左右,大大降低了微调的计算和存储开销。同时,研究表明,LoRA微调的效果与全参数微调相当,在某些任务上甚至略有提升。
QLoRA:量化LoRA
QLoRA(Quantized Low-Rank Adaptation)是LoRA的一个扩展,由华盛顿大学与英伟达合作提出。QLoRA在LoRA的基础上,对预训练模型的权重进行量化,进一步减少了模型的存储开销。
具体来说,QLoRA使用4-bit NF4(4-bit Normalized Fixed-Point)格式对预训练模型的权重进行量化。NF4格式使用一个比特表示符号,三个比特表示尾数,动态范围为[-8, 7]。量化后的权重只需要原来的1/8的存储空间,但在实际使用时,需要将其解量化为全精度(FP16或FP32)格式。
下面是一个使用Torchtune实现QLoRA微调的示例代码:
import torch
from torchtune.models.llama2 import qlora_llama2_7b
from torchtune.trainers import LoRAFinetuneTrainer
# 初始化QLoRA LLaMA-2-7B模型
qlora_model = qlora_llama2_7b(lora_attn_modules=["q_proj", "v_proj"])
# 准备QLoRA微调的Trainer
trainer = LoRAFinetuneTrainer(
model=qlora_model,
dataset_path="path_to_dataset",
output_dir="output_dir",
batch_size=2,
max_steps=1000,
logging_steps=100
)
# 开始微调
trainer.train()
# 保存微调后的模型
trainer.save_model("path_to_saved_model")
这个例子与前面的LoRA微调非常类似,主要的区别在于:
- 我们使用
qlora_llama2_7b函数初始化了一个QLoRA LLaMA-2-7B模型,该模型的权重是4-bit量化的。 - 我们使用
LoRAFinetuneTrainer准备了一个专门用于QLoRA微调的Trainer,设置了数据集路径、输出路径、批大小等参数。 - 在微调过程中,QLoRA模型的权重始终保持量化状态,只有LoRA适配器的参数被更新。这进一步减少了微调过程中的内存消耗。
- 微调完成后,我们使用
save_model函数将微调后的模型保存到指定路径。保存的模型中包含了量化的预训练权重和LoRA适配器参数。在实际使用时,我们需要将量化的权重解量化为全精度格式。
通过结合LoRA和量化,QLoRA可以将微调过程中的内存消耗降低到原来的1/8左右,使得在消费级GPU上微调十亿规模的LLM成为可能。同时,研究表明,QLoRA微调的效果与LoRA微调相当,在某些任务上甚至略有提升。
总结
本文介绍了如何使用PyTorch的Torchtune库进行大型语言模型(LLM)的微调。Torchtune提供了一套简单、灵活、高效的工具和框架,使得研究人员和开发者能够轻松地对LLM进行调试、训练和部署。文章详细介绍了Torchtune的设计原则、核心概念和主要特性,并通过一个完整的实例演示了如何使用Torchtune微调LLaMA-2-7B模型。此外,文章还介绍了两种参数高效的微调方法:LoRA和QLoRA。这两种方法通过引入低秩适配器和量化技术,大大减少了微调过程中的计算和存储开销,为LLM的应用开辟了新的可能性。
https://avoid.overfit.cn/post/b2ebc9f27bd64b949110f306ab0365df