向量数据库 PieCloudVector 进阶系列丨打造音乐推荐系统
在上一篇内容中,我们介绍了 PieCloudVector 如何助力构建基于图片数据的商品推荐系统,详细描述从数据集的准备到数据向量化处理,再到向量数据的存储和相似性搜索的完整流程。本文将进一步探讨如何将 PieCloudVector 应用于音频数据,以实现音频内容的识别和分类。
音频数据是一种丰富且动态的非结构化数据形式,PieCloudVector 作为大模型时代的分析型数据库升维,其在音频数据处理上的应用,不仅能够提升音频内容识别的准确性,还能增强音频分类的效率。本文为《PieCloudVector 进阶系列》的第二篇,将以音频数据为例, 详细介绍利用向量数据库助力音频数据的向量化处理、存储以及相似性搜索的过程。 (本文演示数据均来自 Hugging Face)
基于 PieCloudVector 打造音乐推荐系统
音频数据在转化成向量的过程中,其采样率(即每秒采样数量)是控制数据质量和向量大小的关键之一。采样率越大,数据质量越高,但数据大小也随着变大。本文使用的实例数据是来自 Hugging Face 的 MInDS-14 数据集[1],该数据包含了 14 种不同语言的电子银行领域客户音频数据,共 14 个意图种类(intent_class)。
本文将对音频数据向量化,通过音频相似度对比实现音乐推荐系统。下面将从「数据集准备」、「数据降维与存储」、「音频相似性搜索」三个方面进行介绍。完整逻辑如下图所示:
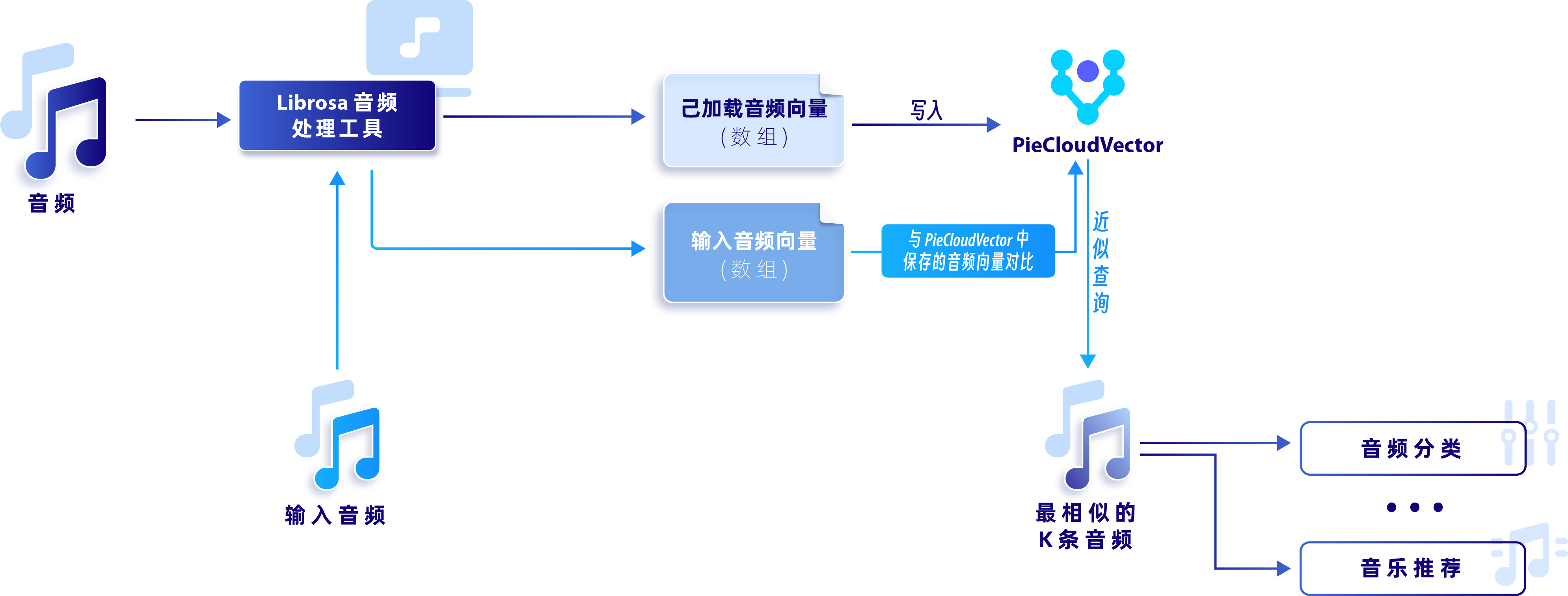
完整逻辑过程
1.数据集准备
首先,我们将对音频数据进行读取和调整,使其转变为向量存入数据库,以便后续的计算。Hugging Face 和后续的步骤需要以下两个 Python 包:
- soundfile
- librosa
从 Hugging Face 下载 MInDS-14 数据。由于该数据集较小,这里我们加载所有共 563 条训练数据。
from datasets import load_dataset
dataset_minds = load_dataset("PolyAI/minds14", "en-US", split="train")
为避免反复下载数据,可将该数据集保存至本地。
dataset_minds.save_to_disk('minds14_dataset')
# 读取本地数据
dataset_minds = load_from_disk('minds14_dataset')
本数据集包括以下特征:路径、音频、转录、英文转录、意图种类和语言,这里我们将重点关注“audio”(音频)、“intent_class”(意图种类)、“lang_id”(语言)这几个特征。
dataset_minds.features
{ 'path': Value(dtype='string', id=None),
'audio': Audio(sampling_rate=8000, mono=True, decode=True, id=None),
'transcription': Value(dtype='string', id=None),
'english_transcription': Value(dtype='string', id=None),
'intent_class': Classlabel(names=['abroad', 'address', 'app_error', 'atm_limit', 'balance', 'business_loan', 'card_issues', 'cash_deposit', 'direct_debit', freeze', 'high_value_payment', 'joint_account', 'latest_transactions', pay_bill'], id=None),
'lang_id': ClassLabel(names=['cs-CZ', 'de-DE', 'en-AU', 'en-GB', 'en-US', 'es-ES', fr-FR', it-IT', 'ko-KR','nl- NL', 'pl-PL', 'pt-PT, 'ru-RU', 'zh-CN'], id=None)}
2.数据降维与存储
由于音频格式在 Hugging Face 数据集中是个较为复杂的数据格式,我们需要先对数据音频部分进行处理。这里我们以数据集中第一条数据为例:
In: dataset_minds.['audio'][0]
Out: {'path': '/Users/arlena.wang/.cache/huggingface/datasets/downloads/extracted/fa6d050e601cf0ccf2c2b01238375a56579232af95e398fcef126ea4224e4185/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414, 0. , 0. ]),
'sampling_rate': 8000}
一条音频数据中,包含音频文件路径、音频波形矩阵,以及波形所对应的采样率。Jupyter Notebook 的 IPython 工具包中提供了 Audio 功能,可以在代码界面生成一个播放器,播放音频文件或音频向量,方便我们了解音频内容。针对数据集中第一条数据,我们使用其对应的音频矩阵和采样率作为输入,播放音频:
from IPython.display import Audio
Audio(data=dataset_minds['audio'][0]['array'], rate=dataset_minds['audio'][0]['sampling_rate'])
该数据集中,波形的采样率为 8000。虽然较高的采样率能够提供更精确的音频数据,但如果音频文件较长,将导致生成的矩阵规模庞大,增加后续计算的负担。第一条数据 8000 的采样率对应的音频向量长度达到了 8 万以上。
print(print(dataset_minds['audio'][0]['sampling_rate']))
# 8000
print(len(dataset_minds['audio'][0]['array']))
# 86699
降低采样率是降低数据维度的办法之一。利用 Python 音频处理库 Librosa,不仅可以加载、处理音频文件,也可用于音频分析。以第一条和第二条数据为例,我们将使用 Librosa 来重新调整音频数据的采样率,以便将数据大小优化至适合向量存储的尺寸。需注意的是,不同音频文件在相同的采样率下,矩阵的长度会有所不同。
In: from librosa import resample
print(len(resample(dataset_minds['audio'][0]['array'], orig_sr=8000, target_sr=2000)))
print(len(resample(dataset_minds['audio'][1]['array'], orig_sr=8000, target_sr=2000)))
Out: 32513
19968
调整过采样率的每条数据对应的向量长度也是不同的。如果想直接将这个阶段的音频向量保存至 PieCloudVector,需要将音频向量的维度进行统一。
以下方程调用了 Librosa 中的 fix_length 工具,可将音频向量调整为统一大小,以最长的向量为基准,未达到该长度的部分由零值来填补。填补的方式不止零值一种,可以根据数据的特质来选择合适的填补方式。
from librosa import resample
from librosa.util import fix_length
max_len = 0
for item in dataset_minds['audio']:
if len(item['array']) > max_len:
max_len = len(item['array'])
def resample_audio_fix(audio):
audio["audio_fix"] = fix_length(resample(audio['audio']['array'], orig_sr=8000, target_sr=2000, fix=True, scale=True), size=max_len)
return audio
updated_fix_dataset = dataset_minds.map(resample_audio_fix)
当前音频向量中存在大量零值,我们可以通过降维技术(例如 PCA 降维算法)来减少向量的维度。这样的处理不仅能降低计算成本,而且通过精简数据,可提升K最近邻(KNN)算法的性能。加入降维处理后的流程如下图所示:
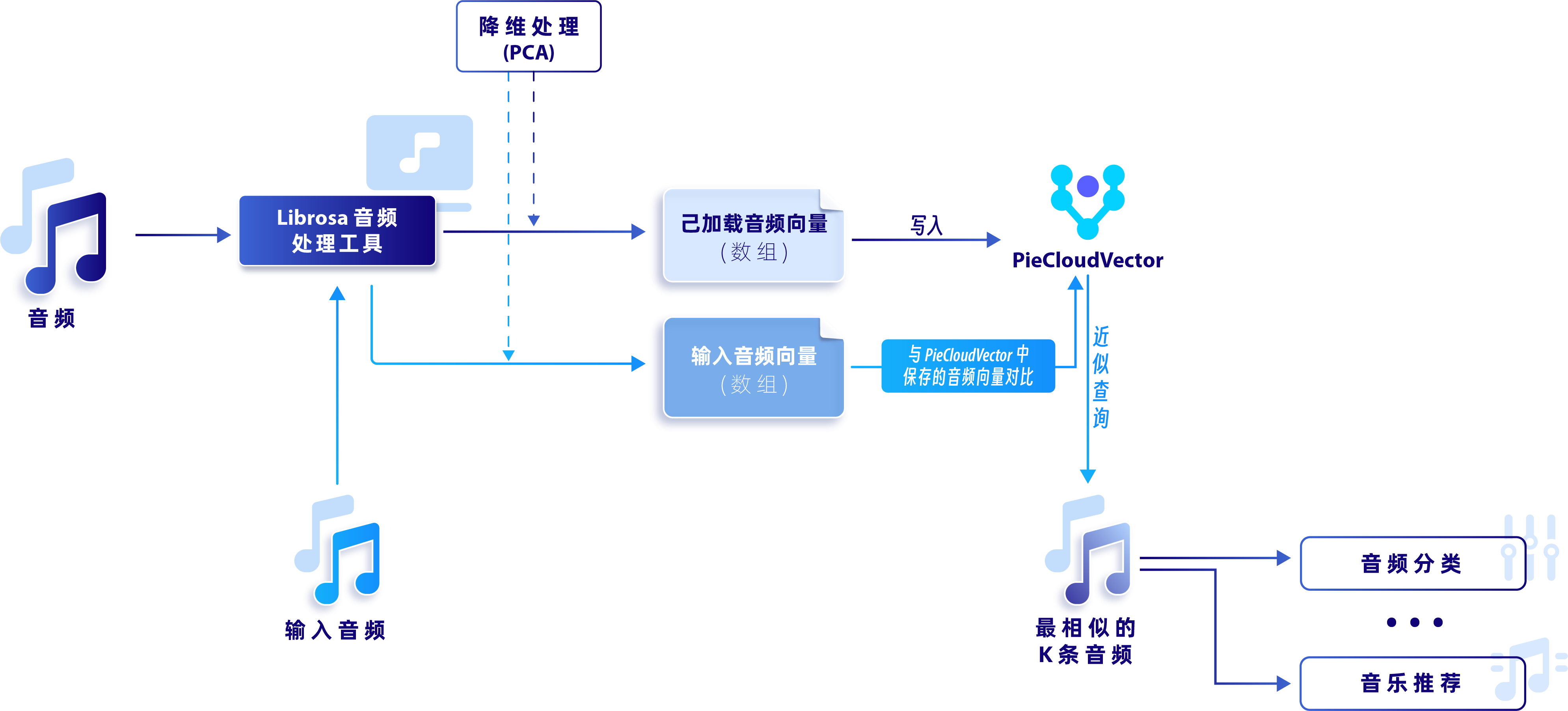
加入降维处理后的流程
尽管将采样率降低到了 2000,音频向量的长度仍然达到了数万级别。这对于数据库中的向量存储以及后续的向量搜索来说,都是一个巨大的挑战。因此,需要采用另一种音频处理方法——梅尔频谱(Mel Spectrogram)。这是一种极为便利、应用广泛音频处理方式,能够将音频数据转换成类似“图片”的形式,从而显著降低数据的维度。
梅尔频谱是一种利用快速傅里叶变换将数据从时间维度转换为频率维度的算法。可通过以下文章来详细了解这种算法:
- Understanding the Mel Spectrogram[2]
- 理解梅尔频谱[3]
使用该方法有两种处理选择:
-
使用 Diffussion 模型,将数据转换为梅尔频谱,通过在数据中加入随机性来提升数据转换的效率和准确性。这种方式更贴近数据的特征,但对算力的消耗较大。
-
直接使用 Librosa 梅尔频谱转换函数。
下面演示如何使用Diffusion模型将数据转换为梅尔频谱。
import torch
from IPython.display import Audio
from diffusers import DiffusionPipeline
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-256").to(device)
output = pipe(
raw_audio=dataset_minds['audio'][0]['array'],
start_step=int(pipe.get_default_steps() / 2),
mask_start_secs=1,
mask_end_secs=1,
)
转换后的梅尔频谱如下图:
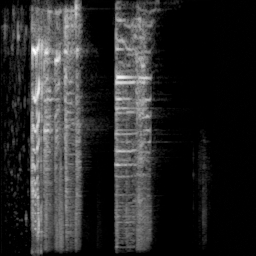
转换后的梅尔频谱
由于 Diffussion 模型比较庞大,消耗算力,我们决定选择 Librosa 库中的梅尔频谱转换函数进行音频处理。以第一条音频数据为例,转换后,我们将得到一个 128 x 170 的矩阵。
In: melspectrogram(y=dataset_minds['audio'][0]['array'], sr=8000).shape
Out: (128, 170)
使用 Huggingface 的 map 工具,转换数据集中的每一条数据。
from librosa.feature import melspectrogram
import PIL
def transform_audio(audio):
audio["audio_image"] = PIL.Image.fromarray(melspectrogram(y=audio['audio']['array'], sr=8000).astype('uint8'))
return audio
updated_dataset = dataset_minds.map(transform_audio)
转换完成后,我们可以使用 PIL 工具来可视化转换后的向量。
display(updated_dataset["audio_image"][0])

这意味着我们可以采用类似于处理图像数据的方法来对音频数据进行建模和计算。具体来说,我们将再次利用之前在图像数据案例中使用的 Embedding 模型,对音频数据进行进一步的数据提炼。
from imgbeddings import imgbeddings
ibed = imgbeddings()
# 第一条音频数据
embedding_0 = ibed.to_embeddings(updated_dataset["audio_image"][0])
可以看到,转换过后的音频数据是一个维度为 768 的向量。
In: embedding_0.shape
Out: (1, 768)
转换数据中的所有梅尔频谱矩阵。
embedding = ibed.to_embeddings(updated_dataset['audio_image'])
转换后,我们将 768 维度的向量、意图类别、语言信息写入 PieCloudVector。首先,我们在 PieCloudVector 中创建相应的表。
CREATE TABLE if not exists vec_test.banking_audio (id bigserial PRIMARY KEY, embedding vector(768), intent_class varchar(50), lang_id varchar(10));
truncate table vec_test.banking_audio;
在 Python 端连接向量数据库 PieCloudVector,写入数据,具体代码如下:
import psycopg2
embeddings_lst = embedding.tolist()
conn = psycopg2.connect('postgresql://user:passwd@192.163.**.**:5432/pgvec_test')
cur = conn.cursor()
for i in range(len(embeddings_lst)):
cur.execute('INSERT INTO vec_test.banking_audio (embedding, intent_class, lang_id) values (%s,%s,%s)', (embeddings_lst[i], updated_dataset["intent_class"][i], updated_dataset["lang_id"][i]))
conn.commit()
conn.close()
3.音频相似性搜索
我们通过 KNN + L2 Distance 查找与第 1 条数据最相近的 10 条语音,进行对比。
from sqlalchemy import create_engine, text as sql_text
import pandas as pd
engine = create_engine('postgresql://user:passwd@192.163.**.**:5432/pgvec_test', echo=False).connect()
audio_id = pd.read_sql_query(sql=sql_text('select id, intent_class, lang_id from vec_test.banking_audio where id != 1 order by embedding <-> ' + "'" + str(embedding_0.tolist()[0]) + "'" + ' limit 10'),
con=engine)
结果如下:
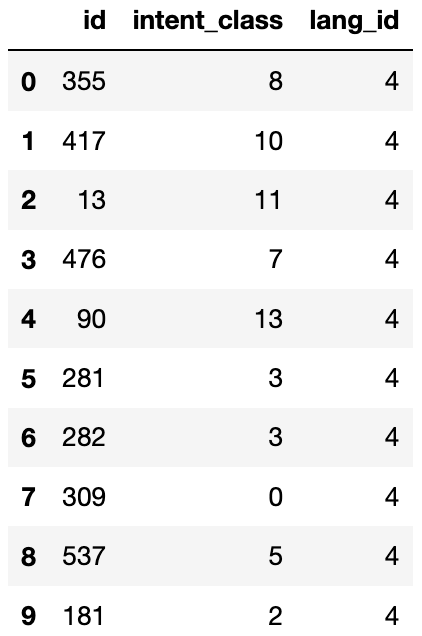
第 1 条数据是关于一位女性询问联合账户相关的事宜,她的意图及语言种类如下:
In: updated_dataset.features["intent_class"].int2str(int(audio_id.loc[0, 'intent_class']))
Out: 'direct_debit'
In: updated_dataset.features["lang_id"].int2str(int(audio_id.loc[0, 'lang_id']))
Out: 'en-US'
在我们查询的最相近的十条记录中,所有音频皆为美式英语,对应编号 4,但意图各不相同。我们可以通过简单计算来查询出现频率最高的意图种类。
audioid_lst = audio_id['id'].to_list()
def most_common(lst):
return max(set(lst), key=lst.count)
label = most_common([updated_dataset['intent_class'][i] for i in audioid_lst])
print(updated_dataset.features["intent_class"].int2str(int(label)))
结果为’atm_limit’。
In: updated_dataset.features["intent_class"].int2str(int(label))
Out: 'atm_limit'
再次使用 Audio 函数播放与第 1 条数据最接近的第 355 条数据。第 355 条数据是一条 11 秒长度的音频,同样是女声,也同样是询问有关’direct_debit’的事宜。
Audio(data=updated_dataset['audio'][354]['array'], rate=dataset_minds['audio'][354]['sampling_rate'])
音频相似搜索在文本内容的识别上能力有限,但它更擅长捕捉声音波形层面的相似性,特别适合用于比较音频的音色和语言特征。如果输入的音频是音乐,可以通过同样的方式有效地为用户推荐相似的音乐,它能够识别出音乐作品中的旋律和节奏等关键元素,并与数据库中的音乐进行匹配,从而推荐风格相近的音乐给用户。这些推荐的音乐在听觉体验上与用户喜欢的音乐相似,有助于提升用户的满意度和体验。
在下篇文章中,我们将探索如何利用 PieCloudVector 的文本数据处理能力,打造 ChatBot。 欢迎关注!