如何使用Python WebDriver爬取ChatGPT内容(完整教程)
大背景
虽然我们能用网页版chatGPT来聊天、写文章,但是我们采集大量的内容,就得不断地手动输入提问来获取答案,并且将结果复制到数据库来保存。如果整个过程能使用程序来做自然要节省很多的人力,精力和时间。
Python webdirver 模拟浏览器的方式来实现,刚好能实现以上功能。
另外之所以不选择API 是因为以下原因:
-
普通开发者(国内)获取API KEY 是有困难的,需要海外手机号 + 信用卡等一系列条件,但是如果只是网页端,我们仅仅需要登录或者未登录的方式就可以直接聊天
-
网页端无需调整各项参数,可以直接交互获取内容,而且内容质量更高!
当然,如果你有条件用API 或者直接通过 wss交互获取内容的,到这儿可以直接结束了。
完整源码在文章末尾哦!
基本环境要求
准备自己的梯子
ChatGpt属于海外项目,国内的小伙伴,翻墙得找好自己的梯子(代理),这里自己有啥用啥即可。
安装Python 环境
Python要求:3.10 +
安装 Python Selenium
pip install selenium其他扩展库说明:取决于自己电脑缺什么就安装什么。后面完整代码会提供完整的 requirements.txt
浏览器
这里以Chrome浏览器为准。也就是你本地必须要安装Chrome浏览器,并且获取其安装路径。
比如:C:\Program Files\Google\Chrome\Application\chrome.exe
操作系统
这里以 windows 作为开发环境。
开发工具
自己什么顺手用什么。
这里讲个程序界的笑话:传说级别的开发者据说用的记事本来开发。
实现过程
这里只介绍主要的代码
浏览器控制
使用程序实现浏览器的控制,这包括浏览器的打开,关闭,以及代理配置。
创建 browser_manage.py
import subprocess, datetime
import os, signal, psutil
def run_cmd(port=9200):
cmd = [
# chrome浏览器路径。 必须为首个参数
'C:/Program Files/Google/Chrome/Application/chrome.exe',
# 【必要】设置浏览器端口
'--remote-debugging-port=%s' % port,
# 【必要】设置浏览器数据存储路径
'--user-data-dir=D:/data',
# 隐藏一些弹窗之类的信息
'--hide-crash-restore-bubble',
# 设置浏览器分辨率。如果要跑多个浏览器可以将每个浏览器设置小一些
'--force-device-scale-factor=1',
# 假设代理地址为 http://127.0.0.1:10809
'--proxy-server=http://127.0.0.1:10809',
# 默认打开一个空白页面
'about:blank'
]
process = subprocess.Popen(cmd)
# 返回pid 用于关闭浏览器杀死进程
return process.pid
def kill_process(parent_pid):
try:
# 获取父进程
parent = psutil.Process(parent_pid)
# 获取父进程的所有子进程(包括孙子进程等)
children = parent.children(recursive=True)
# 创建一个包含父进程PID的列表
pids_to_kill = [parent_pid]
# 将所有子进程的PID添加到列表中
pids_to_kill.extend(child.pid for child in children)
# 遍历列表,对每个PID发送SIGKILL信号
for pid in pids_to_kill:
try:
os.kill(pid, signal.SIGILL)
except PermissionError:
# 忽略权限错误,可能我们没有权限杀死某个进程
print("close browser PermissionError")
pass
except ProcessLookupError:
# 忽略进程查找错误,进程可能已经自然死亡
print("close browser ProcessLookupError")
pass
except (psutil.NoSuchProcess, PermissionError):
# 忽略错误,如果进程不存在或者没有权限
print("close browser PermissionError1")
pass
return True
def open_browser():
"""
打开浏览器
"""
# 打开指定端口的浏览器
pid = run_cmd(9200)
def close_borwser():
"""
关闭浏览器
"""
# pid 为打开浏览器获取到的进程id
kill_process(pid)
# 执行open_browser() 打开浏览器,执行 close_borwser() 关闭浏览器初始化selenium
创建爬虫脚本 spider.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from fake_useragent import UserAgent
import subprocess, datetime
chrome_options = Options()
ua = UserAgent()
# 浏览器端口信息,取决于启动浏览器设置的端口
browser_host = 9200
browser_host= "127.0.0.1"
random_ua = ua.random
chrome_options.add_argument(f'user-agent={random_ua}')
# 设置要连接的浏览器端口信息
chrome_options.add_experimental_option("debuggerAddress","%s:%s" % (browser_host, browser_port))
driver = webdriver.Chrome(options=chrome_options)进入到目标页面
文件:spider.py
# 页面加载等待:最多10s
driver.implicitly_wait(10)
driver.get("https://chat.openai.com/")页面等待除了以上的方案也可以用其他方法:
# 等待某个元素可见
try:
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, "//h1"))
)
print(element.text)
finally:
driver.quit()
# 或者直接
time.sleep(10)发起询问
发起新的提问
每次提问都应该是基于一个新窗口来提问。如果你的问题需要上下文的基础来回答,可以直接跳过这里。

新询问输入框可以根据 button data-testid="create-new-chat-button" 来定位。
# 定位到新聊天元素
new_chat_dom = driver.find_element(By.CSS_SELECTOR, '[data-testid="create-new-chat-button"]')
# 发起点击,进入新界面
new_chat_dom.click()定位到输入框
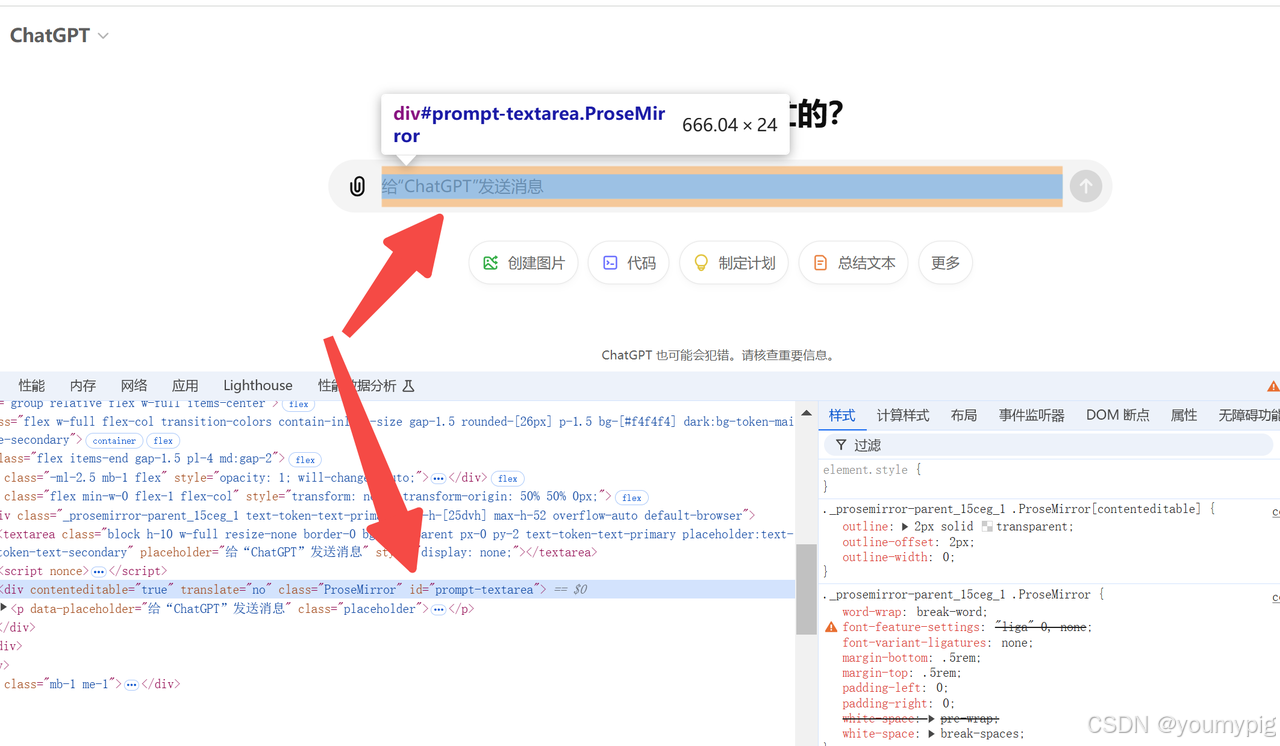
输入框使用的是div contentediable作为文本域。其id为 prompt-textarea
# 因为元素提供了id,则直接通过id获取最方便
textarea_dom = driver.find_element(By.ID, "prompt-textarea")创建询问队列
因为我们的目标是自动化对问题列表发起询问,而不是一次性询问。所以需要创建一个问题队列。问题队列可以来源于数据库或者队列文件。这里为了演示,直接创建一个list
ask_list = [
"请用Python写一个平均等分list的方案",
"请写一个关于小猪佩奇的笑话,要求:小猪佩奇可能不是猪,而是河马, 100字",
"称赞一个女生长得漂亮,如何不直接称赞也能看出来在形容她漂亮"
]输入问题
这里我们按行来输入:一次输入一行。
for msg in ask_list:
# 将字符串按换行分割开
ask_msg_arr = msg.split('\n')
for msg_line in ask_msg_arr:
textarea_dom.send_keys(ask_msg_item)
# 发送
textarea_dom.send_keys(Keys.ENTER)
# TODO 这里是后续获取数据,存储到数据库环节等待数据响应
可以根据回答结束后,出现的交互按钮来确认是否回答完毕
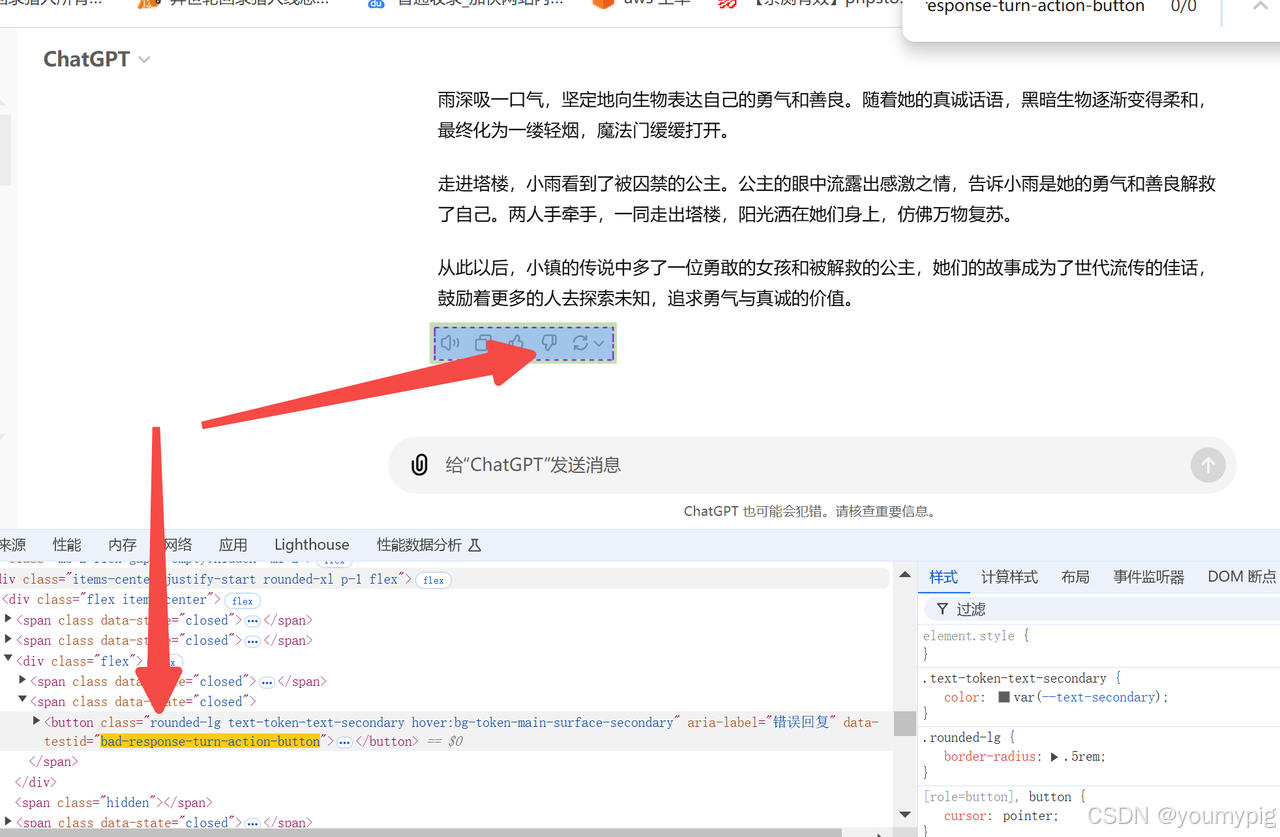
idx = 0
while True:
idx = idx + 1
# 请求超时
if idx > 180:
break
time.sleep(1)
try:
driver.find_element(By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]')
break
except:
continue也可以使用以下方法来校验:
# 设置最大等待时间
wait = WebDriverWait(driver, 180)
# 等待直到元素出现
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]')))获取响应数据
通过 class="markdown" 来获取数据。
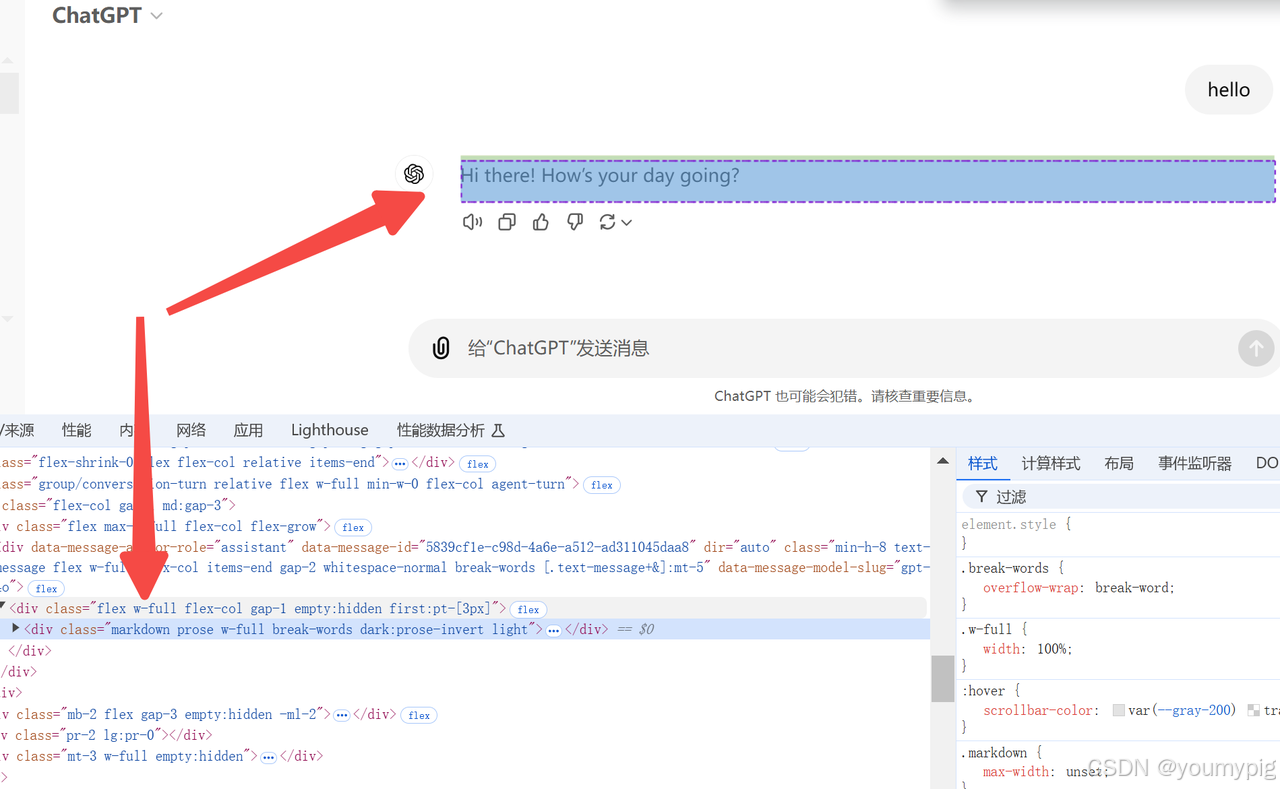
idx = 0
while True:
idx = idx + 1
# 请求超时
if idx > 180:
break
time.sleep(1)
try:
html_dom = driver.find_element(By.CSS_SELECTOR, '.markdown')
break
except:
continue
content = html_dom .get_attribute('innerHTML')数据清洗
具体的清洗规则,看具体的业务需求。大多数清洗,需要将一些总结类的语句删除,不合法的返回内容删除。这里不提供相应的清洗的方案。
至此,一个完整的数据链就已经完结。
完整源码
browser.py
import subprocess, datetime
import os, signal, psutil
def run_cmd(port=9200):
cmd = [
# chrome浏览器路径。
'C:/Program Files/Google/Chrome/Application/chrome.exe',
# 【必要】设置浏览器端口
'--remote-debugging-port=%s' % port,
# 【必要】设置浏览器数据存储路径
'--user-data-dir=E:/browser_data',
# 隐藏一些弹窗之类的信息
'--hide-crash-restore-bubble',
# 设置浏览器分辨率。如果要跑多个浏览器可以将每个浏览器设置小一些
'--force-device-scale-factor=1',
# 假设代理地址为 http://127.0.0.1:10809
'--proxy-server=http://127.0.0.1:10809',
# 默认打开一个空白页面
'about:blank'
]
process = subprocess.Popen(cmd)
# 返回pid 用于关闭浏览器杀死进程
return process.pid
def kill_process(parent_pid):
try:
# 获取父进程
parent = psutil.Process(parent_pid)
# 获取父进程的所有子进程(包括孙子进程等)
children = parent.children(recursive=True)
# 创建一个包含父进程PID的列表
pids_to_kill = [parent_pid]
# 将所有子进程的PID添加到列表中
pids_to_kill.extend(child.pid for child in children)
# 遍历列表,对每个PID发送SIGKILL信号
for pid in pids_to_kill:
try:
os.kill(pid, signal.SIGILL)
except PermissionError:
# 忽略权限错误,可能我们没有权限杀死某个进程
print("close browser PermissionError")
pass
except ProcessLookupError:
# 忽略进程查找错误,进程可能已经自然死亡
print("close browser ProcessLookupError")
pass
except (psutil.NoSuchProcess, PermissionError):
# 忽略错误,如果进程不存在或者没有权限
print("close browser PermissionError1")
pass
return True
def open_browser():
"""
打开浏览器
"""
# 打开指定端口的浏览器
pid = run_cmd(9200)
return pid
def close_browser(pid):
"""
关闭浏览器
"""
# pid 为打开浏览器获取到的进程id
kill_process(pid)
pid = open_browser()
print(pid)
# close_browser(25996)spider.py
import time
import traceback
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from fake_useragent import UserAgent
import subprocess, datetime
import os
chrome_options = Options()
ua = UserAgent()
# 浏览器端口信息,取决于启动浏览器设置的端口
browser_port = 9200
browser_host = "127.0.0.1"
random_ua = ua.random
chrome_options.add_argument(f'user-agent={random_ua}')
# 设置要连接的浏览器端口信息
chrome_options.add_experimental_option("debuggerAddress", "%s:%s" % (browser_host, browser_port))
driver = webdriver.Chrome(options=chrome_options)
def open_gpt_page():
driver.implicitly_wait(10)
driver.get("https://chat.openai.com/")
def new_chat():
"""
该方案当前只适用于已经登录到chatgpt的页面。不适用非的登录页面
"""
# 定位到新聊天元素
new_chat_dom = driver.find_element(By.CSS_SELECTOR, '[data-testid="create-new-chat-button"]')
# 发起点击,进入新界面
new_chat_dom.click()
def get_input_box():
return driver.find_element(By.ID, "prompt-textarea")
def get_ask_list():
return [
"请用Python写一个平均等分list的方案",
"请写一个关于小猪佩奇的笑话,要求:小猪佩奇可能不是猪,而是河马, 100字",
"称赞一个女生长得漂亮,如何不直接称赞也能看出来在形容她漂亮"
]
def get_response():
# 等待响应完成
idx = 0
while True:
idx = idx + 1
# 请求超时
if idx > 180:
break
time.sleep(1)
try:
driver.find_element(By.CSS_SELECTOR, '[data-testid="bad-response-turn-action-button"]')
break
except:
continue
# 获取请求结果
idx = 0
content = None
while True:
idx = idx + 1
# 请求超时
if idx > 180:
break
time.sleep(1)
try:
html_dom = driver.find_element(By.CSS_SELECTOR, '.markdown')
content = html_dom.get_attribute('innerHTML')
break
except:
continue
return content
def simulator(ask_msg):
# 进入输入框并且点击
print("进入输入框并且点击")
textarea_dom = get_input_box()
textarea_dom.click()
# 发送
ask_msg_arr = ask_msg.split('\n')
for msg_line in ask_msg_arr:
textarea_dom.send_keys(msg_line)
textarea_dom.send_keys(Keys.ENTER)
# 获取响应
content = get_response()
# 保存数据到文件
root_path = "./data"
os.makedirs(root_path, exist_ok=True)
full_path = f"{root_path}/%s.text" % int(time.time())
with open(full_path, 'w', encoding='utf-8') as file:
file.write(content)
print("save success")
def start():
open_gpt_page()
print("页面加载完毕")
time.sleep(3)
ask_list = get_ask_list()
for ask_msg in ask_list:
time.sleep(3)
print("进入新的聊天")
new_chat()
print("current msg %s" % ask_msg)
for retry in range(0,3):
try:
simulator(ask_msg)
break
except:
print(traceback.format_exc())
time.sleep(10)
pass
start()requirements.txt
fake_useragent==1.2.1
psutil==5.9.5
selenium==4.26.1获取扩展源码
扩展源码是基于 chatgpt聊天页面,通过多个浏览器并行数据爬取,包含以下功能:
-
基于数据库创建问题队列
-
创建多个浏览器窗口多线程并行运行,提高产量和效率
-
解决人工校验-自动化进行人工校验
-
为多个浏览器配置不同的代理方案
-
代理配置,为浏览器自动化分配代理,
-
通过web端进行浏览器管理,代理管理,代理分配等
需要以上扩展源码,QQ:1186969412