大模型微调
目录
- 1. 大模型与微调基本介绍
- (1)模型参数与数据集规模增长
- (2)模型微调
- 2. 微调技术的区别
- (1)按微调参数规模划分
- (2)按训练的流程来划分
- (3)按训练的方式来划分
- 3. 展开说说lora
- 4. 展开使用P-Tuning v2
- 附录
- 1.PEFT 介绍
- (1)方法分类
- (2)高效 PEFT 设计
- (3)PEFT 的系统设计挑战
- (4)未来研究方向
- 2.生成任务评估指标含义:
- 3.参考资料
- 4.名词记录
1. 大模型与微调基本介绍
(1)模型参数与数据集规模增长
从趋势看大模型参数量只会越来越大,训练更大的模型需要更多的的数据集,随着模型的增长,训练过程必须调整更多的参数。对于AI集群和算力的消耗会更多,也会不断提升成本。模型参数与数据集规模增长:引入微调。
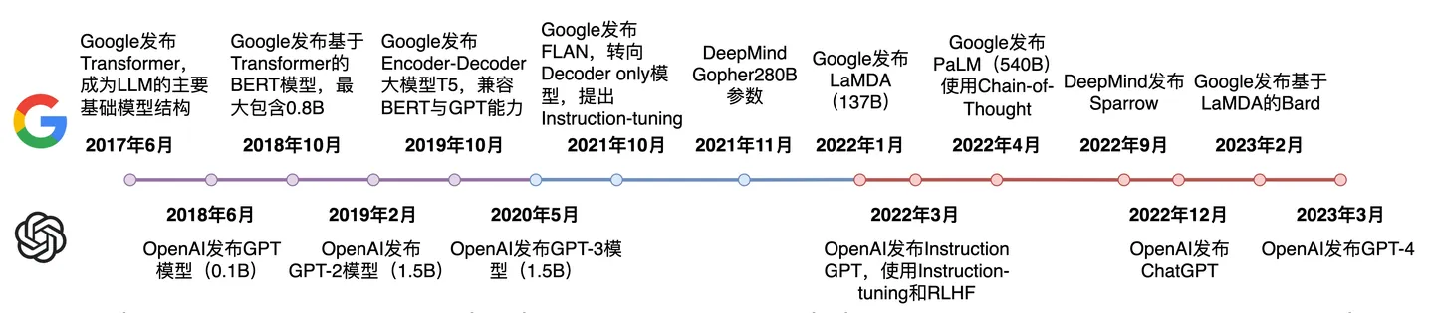
(2)模型微调
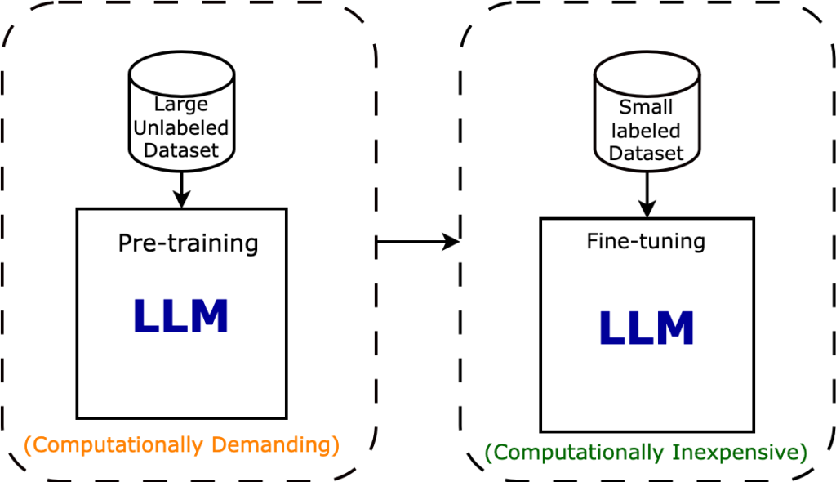
模型微调允许少量地重新调整预训练大模型的权重参数,或者大模型的输入和输出有助于降低训练大模型的复杂性,降低重新进行训练的成本。
2. 微调技术的区别
微调,一般都是指基于问答对形式组织的数据,来对模型进行参数调整;因为数据是问答对,也就是标注后的数据,因此都是SFT;当采用不同的微调方法,更改的模型参数不同,就有了全参微调、低参微调的区分;LoRA、P-Tuning、Prefex-Tuning, Prompt-Tuning都是低参微调。
(1)按微调参数规模划分

FPFT: 用预训练模型作为初始化权重,在特定数据集上继续训练,全部参数都更新的方法。
PEFT: 用更少的计算资源完成模型参数的更新,包括只更新一部分参数,或者通过对参数进行某种结构化约束,例如稀疏化或低秩近似来降低微调的模型参数量。
PEFT举例:
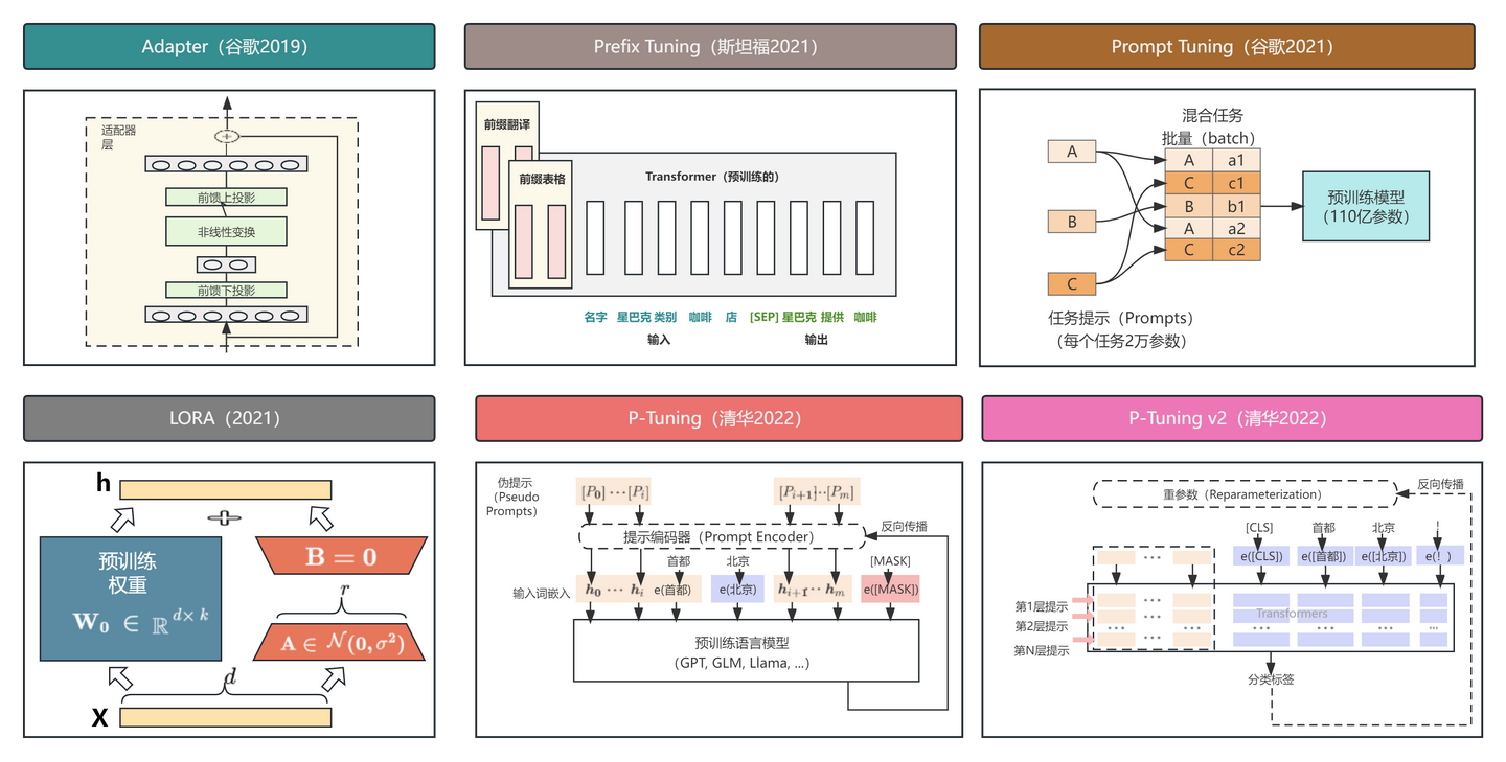
(2)按训练的流程来划分

ICL(In-Context learning)上下文学习:区别于普通微调 Fine-Tuning,不对 LLMs 执行任何的微调,直接将模型的输入输出拼接起来作为一个 prompt,引导模型根据输入的数据结构 demo,给出任务的预测结果。ICL 能够基于无监督学习的基础上取得更好模型效果,并且不需要根据特定的任务重新微调 Fine-Tuning 更新模型参数,避免不同任务要重新进行真正的微调。
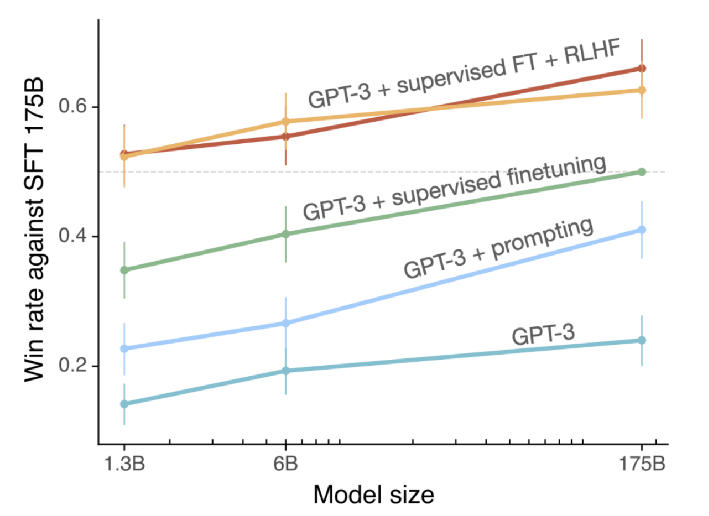
(3)按训练的方式来划分

3. 展开说说lora
- LoRA: Low-Rank Adaption of large language models
- 一个到较小子空间的随机投影
- parameter efficient
- PEFT
- https://arxiv.org/abs/2106.09685
- 实现细节上
- 是一个 adaptor of pretrained model
- adaptor 是小的
- pretrained model 是大的
- large language models
- large vision models
- freezes pre-trained model weights
- injects trainable rank decomposition matrices
- into each layer of transformer Architecture
- 是一个 adaptor of pretrained model
- 基本思想
- 对于 transformer,最为重要的 self attention module
- Wq、Wk、Wv、Wo 表示 learnable query/key/value/output projection matrices
- 将这些记为模型的参数 Φ
- 在 full fine-tune (不进行任何的 freeze)时,model 会初始化为预训练好的权重 Φ,最终 fine-tune 之后,调整为 Φ+ΔΦ(基于反向传播和梯度下降)
- 每一个下游任务都要学习对应的 ΔΦ(|ΔΦ|=|Φ|)
- LoRA 作为一个 parameter efficient 将与下游任务相关的 ΔΦ=ΔΦ(Θ),进一步编码(encode)为规模更小的参数 Θ
- |Θ|≪|ΔΦ|=|Φ|
- LoRA 采用 low-rank representation 来 encode ΔΦ

- 对于 transformer,最为重要的 self attention module
微调例子:
微调前:

微调后:

4. 展开使用P-Tuning v2
基于 P-Tuning v2 对ChatGLM-6B-PT微调。
微调前:

微调后(训飞了):

评估指标:
- predict_bleu-4 = 7.6597
表示生成文本与参考文本的 4-gram 匹配度为 7.66%。这个值越高,表示模型生成的文本与参考文本越接近。 - predict_rouge-1 = 28.833
表示生成文本中与参考文本的 unigram(单个词)匹配度约为 28.83%。这个分数代表生成的文本中有 28.83% 的词与参考文本一致。 - predict_rouge-2 = 6.2194
表示生成文本和参考文本中 bigram(连续两个词)的匹配度为 6.22%。 - predict_rouge-l = 23.136
ROUGE-L 通过最长公共子序列来衡量生成文本与参考文本的相似度。这里的 23.13 表示有 23.13% 的最长子序列在两者中匹配。
附录
1.PEFT 介绍
(1)方法分类

加性微调
通过在预训练模型的特定位置添加可学习的模块或参数,以最小化适配下游任务时模型的可训练的参数量。(Prefix-tuning 通过在每个 Transformer 层的键、值和查询矩阵前面添加可学习的向量,实现对模型表示的微调,其实就是给大语言模型增加一层ebedding,对这层的参数做调整。Prompt Tuning 仅仅在首个词向量层插入可学习向量,以进一步减少训练参数,在里面的参数调整)
选择性微调
在微调过程中只更新模型中的一部分参数,而保持其余参数固定。相较于加性微调,选择性微调无需更改预训练模型的架构。
重参数化微调
通过构建预训练模型参数的(低秩的)表示形式用于训练。在推理时,参数将被等价的转化为预训练模型参数结构,以避免引入额外的推理延迟。
这三者的区分如图所示:
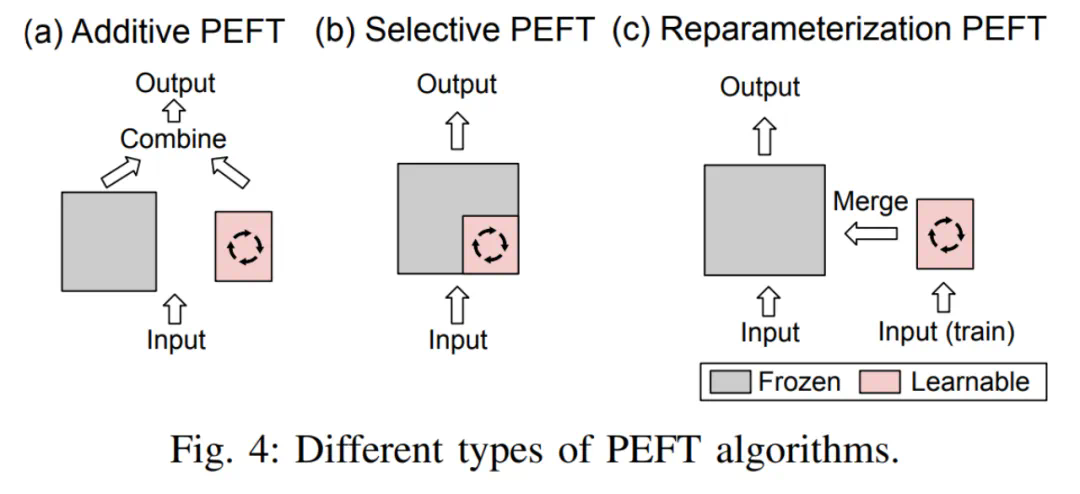
混合微调
结合了各类 PEFT 方法的优势,并通过分析不同方法的相似性以构建一个统一的 PEFT 架构,或寻找最优的 PEFT 超参数
(2)高效 PEFT 设计
关注其训练和推理的延迟和峰值内存开销。

(3)PEFT 的系统设计挑战

(4)未来研究方向

2.生成任务评估指标含义:
BLEU-4 (Bilingual Evaluation Understudy Score):
BLEU 是一种常用于机器翻译的评估指标,衡量生成文本与参考文本的相似度。BLEU-4 主要关注生成文本中连续 4 个词的匹配情况(即 4-gram 匹配)。它是通过计算生成文本与参考文本的 n-gram 共同出现的次数来评估模型输出的质量。
ROUGE Score (Recall-Oriented Understudy for Gisting Evaluation):
ROUGE 也是一种用来评估文本生成任务(如文本摘要、机器翻译等)输出的指标,主要用于比较生成文本与参考文本之间的相似度,尤其注重召回率。常见的 ROUGE 包括:
- ROUGE-1:计算生成文本和参考文本中的单个词(unigram)的重叠情况。
- ROUGE-2:计算生成文本和参考文本中连续两个词(bigram)的重叠情况。
- ROUGE-L:基于最长公共子序列(LCS)的匹配。
3.参考资料
(1) ChatGLM-6B 模型基于 P-Tuning v2 的微调
(2)九天Hector 【入门】大语言模型常用微调框架介绍|LoRA&Prefix-Tuning&Prompt-Tuning&P-Tuning v2&RLHF微调原理简介
(3)五道口纳什 [LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
(4)lora原作者论文:LORA.pdf
4.名词记录
预训练语言模型(Pretrain Language model,PLM)