DolphinScheduler资源中心
DolphinScheduler资源中心
1 简介
资源中心通常用于上传文件、UDF 函数和任务组管理。
-
standalone 环境可选择本地文件目录作为上传文件夹(无需Hadoop部署) -
也可选择上传到 Hadoop 或 MinIO 集群。此时需要有 Hadoop(2.6+)或 MinIO 等相关环境
2 配置详情
-
资源中心可对接分布式文件存储系统,如 Hadoop(2.6+)或 MinIO集群,也可对接远端的对象存储如 AWS S3或者 阿里云 OSS, 华为云 OBS。 -
也可直接对接本地文件系统。单机模式无需依赖 Hadoop或S3一类的外部存储系统,可方便对接本地文件系统体验 -
集群模式部署,可用 S3FS-FUSE将 S3挂载到本地或用 JINDO-FUSE将OSS挂载到本地等,再用资源中心对接本地文件系统方式来操作远端对象存储中的文件
2.1 对接本地文件系统
common.properties
资源中心使用本地系统默认开启,但若你需修改默认配置,请确保同时完成下面修改:
-
如以 集群或伪集群模式部署,需对以下路径的文件配置:api-server/conf/common.properties和worker-server/conf/common.properties -
单机模式部署,只需配置standalone-server/conf/common.properties
可能涉及修改:
-
resource.storage.upload.base.path改为本地存储路径,请确保部署 DolphinScheduler 的用户拥有读写权限,如:resource.storage.upload.base.path=/tmp/dolphinscheduler。当路径不存在时会自动创建文件夹
注意
LOCAL模式不支持分布式模式读写,意味着上传的资源只能在一台机器上使用,除非使用共享文件挂载点 如不想用默认值作为资源中心的基础路径,修改 resource.storage.upload.base.path当配置 resource.storage.type=LOCAL,其实配置了两个配置项resource.storage.type=HDFS和resource.hdfs.fs.defaultFS=file:///,单独配置resource.storage.type=LOCAL这个值是为了 方便用户,并且能使得本地资源中心默认开启
确保在HDFS上有指定的目录并具有读写权限
-
登录到HDFS: 使用具有适当权限的用户账号登录到HDFS集群中的任一节点或者使用Hadoop客户端工具登录。
-
检查目录是否存在: 执行以下命令来检查指定的目录是否已存在于HDFS
hdfs dfs -ls /dolphinscheduler
ls: `/dolphinscheduler': No such file or directory如果目录已存在,将会列出目录下的文件信息。如果不存在,提示找不到该路径。
-
创建目录: 目录不存在,则用命令在HDFS创建:
hdfs dfs -mkdir -p /dolphinscheduler将递归创建所需的目录结构。
-
设置权限: 确保创建的目录具有适当权限,以便DolphinScheduler可以读取和写入该目录。设置权限:
hdfs dfs -chmod -R 777 /dolphinscheduler这将给予目录及其所有子目录和文件读取、写入和执行的权限。
-
验证权限设置: 可以再次运行以下命令来验证目录的权限设置是否正确:
hdfs dfs -ls /dolphinscheduler确保您看到的输出中包含了该目录的详细信息,并且权限设置为读写执行权限。
通过以上步骤,可确保在HDFS上有指定的目录并且具有读写权限,以供DolphinScheduler存储和访问资源文件。
2.2 对接分布式或远端对象存储
当需要使用资源中心进行相关文件的创建或者上传操作时,所有的文件和资源都会被存储在分布式文件系统HDFS或者远端的对象存储,如S3上。需配置:
common.properties
在 3.0.0-alpha 版本之后,如果需要使用到资源中心的 HDFS 或 S3 上传资源,我们需要对以下路径的进行配置:api-server/conf/common.properties 和 worker-server/conf/common.properties。可参考如下:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path=/tmp/dolphinscheduler
# resource storage type: LOCAL, HDFS, S3, OSS, GCS, ABS, OBS
resource.storage.type=LOCAL
# resource store on HDFS/S3/OSS path, resource file will store to this hadoop hdfs path, self configuration,
# please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/tmp/dolphinscheduler
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=minioadmin
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=minioadmin
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=cn-north-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name=dolphinscheduler
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint=http://localhost:9000
# alibaba cloud access key id, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.id=<your-access-key-id>
# alibaba cloud access key secret, required if you set resource.storage.type=OSS
resource.alibaba.cloud.access.key.secret=<your-access-key-secret>
# alibaba cloud region, required if you set resource.storage.type=OSS
resource.alibaba.cloud.region=cn-hangzhou
# oss bucket name, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.bucket.name=dolphinscheduler
# oss bucket endpoint, required if you set resource.storage.type=OSS
resource.alibaba.cloud.oss.endpoint=https://oss-cn-hangzhou.aliyuncs.com
# alibaba cloud access key id, required if you set resource.storage.type=OBS
resource.huawei.cloud.access.key.id=<your-access-key-id>
# alibaba cloud access key secret, required if you set resource.storage.type=OBS
resource.huawei.cloud.access.key.secret=<your-access-key-secret>
# oss bucket name, required if you set resource.storage.type=OBS
resource.huawei.cloud.obs.bucket.name=dolphinscheduler
# oss bucket endpoint, required if you set resource.storage.type=OBS
resource.huawei.cloud.obs.endpoint=obs.cn-southwest-2.huaweicloud.com
# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path
resource.hdfs.root.user=root
# if resource.storage.type=S3, the value like: s3a://dolphinscheduler;
# if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.hdfs.fs.defaultFS=hdfs://localhost:8020
# whether to startup kerberos
hadoop.security.authentication.startup.state=false
# java.security.krb5.conf path
java.security.krb5.conf.path=/opt/krb5.conf
# login user from keytab username
login.user.keytab.username=hdfs-mycluster@ESZ.COM
# login user from keytab path
login.user.keytab.path=/opt/hdfs.headless.keytab
# kerberos expire time, the unit is hour
kerberos.expire.time=2
# resource view suffixs
#resource.view.suffixs=txt,log,sh,bat,conf,cfg,py,java,sql,xml,hql,properties,json,yml,yaml,ini,js
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port=8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value;
# If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address=http://localhost:%s/ds/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address=http://localhost:19888/ds/v1/history/mapreduce/jobs/%s
# datasource encryption enable
datasource.encryption.enable=false
# datasource encryption salt
datasource.encryption.salt=!@#$%^&*
# data quality jar directory path, it would auto discovery data quality jar from this given dir. You should keep it empty if you do not change anything in
# data-quality, it will auto discovery by dolphinscheduler itself. Change it only if you want to use your own data-quality jar and it is not in worker-server
# libs directory(but may sure your jar name start with `dolphinscheduler-data-quality`).
data-quality.jar.dir=
#data-quality.error.output.path=/tmp/data-quality-error-data
# Network IP gets priority, default inner outer
# Whether hive SQL is executed in the same session
support.hive.oneSession=false
# use sudo or not, if set true, executing user is tenant user and deploy user needs sudo permissions;
# if set false, executing user is the deploy user and doesn't need sudo permissions
sudo.enable=true
# network interface preferred like eth0, default: empty
#dolphin.scheduler.network.interface.preferred=
# network IP gets priority, default: inner outer
#dolphin.scheduler.network.priority.strategy=default
# system env path
#dolphinscheduler.env.path=env/dolphinscheduler_env.sh
# development state
development.state=false
# rpc port
alert.rpc.port=50052
# way to collect applicationId: log(original regex match), aop
appId.collect: log
注意:
如果只配置了 api-server/conf/common.properties的文件,则只是开启了资源上传的操作,并不能满足正常使用。如果想要在工作流中执行相关文件则需要额外配置worker-server/conf/common.properties。如果用到资源上传的功能,那么 安装部署中,部署用户需要有这部分的操作权限。 如果 Hadoop 集群的 NameNode 配置了 HA 的话,需要开启 HDFS 类型的资源上传,同时需要将 Hadoop 集群下的 core-site.xml和hdfs-site.xml复制到worker-server/conf以及api-server/conf,非 NameNode HA 跳过次步骤。
3 文件管理
当在调度过程中需要使用到第三方的 jar 或者用户需要自定义脚本的情况,可以通过在该页面完成相关操作。可创建的文件类型包括:txt/log/sh/conf/py/java 等。并且可以对文件进行编辑、重命名、下载和删除等操作。
当您以 admin身份登入并操作文件时,需要先给admin设置租户
基础操作
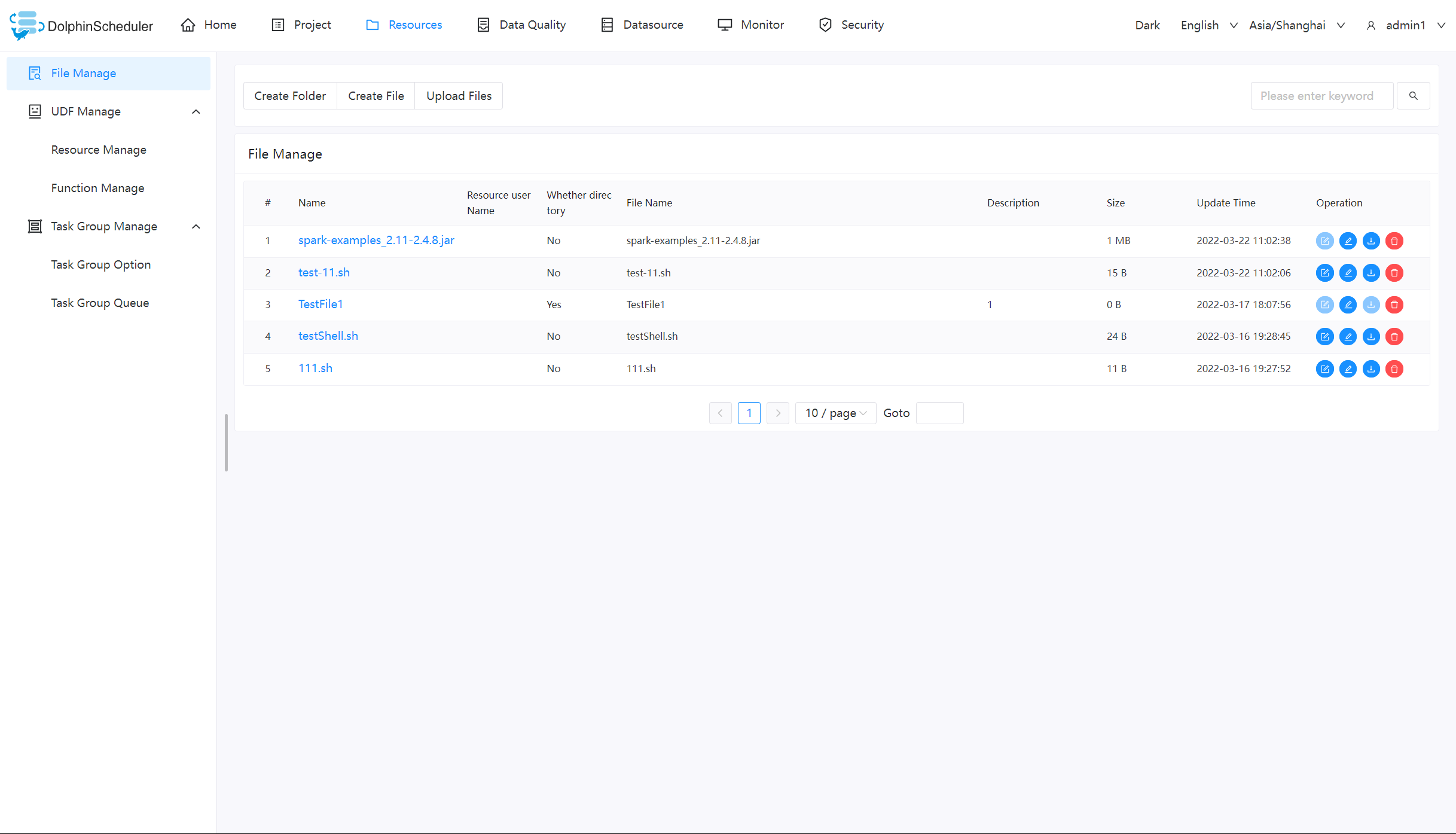
创建文件
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
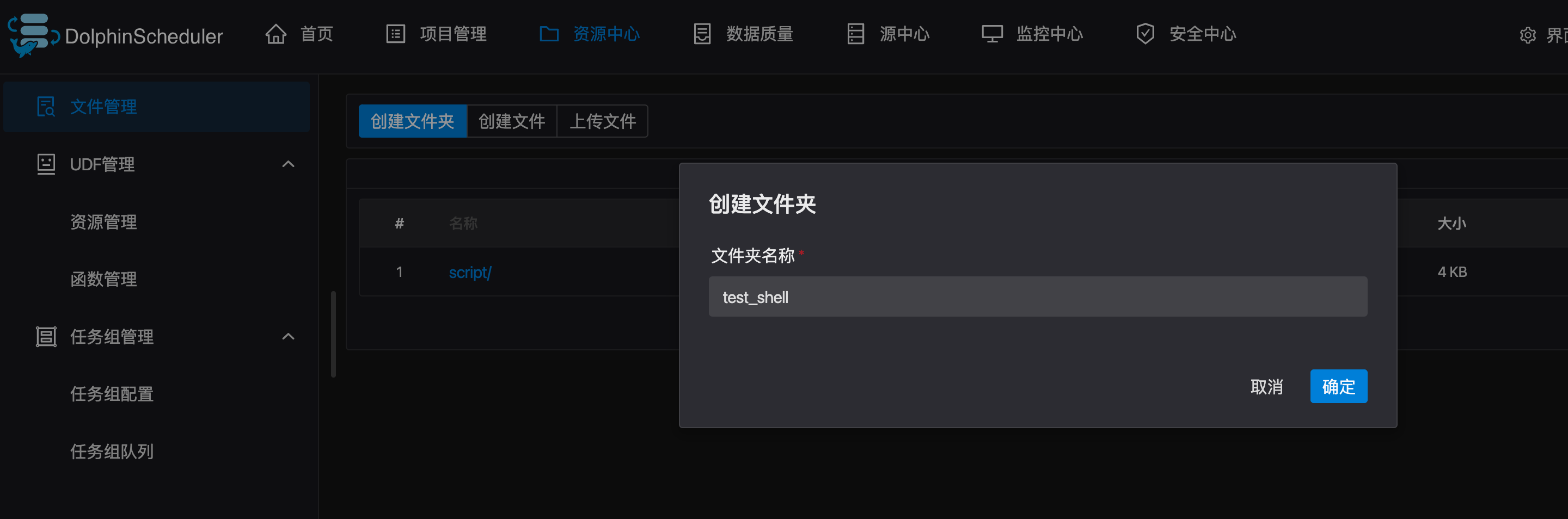
文件夹创建
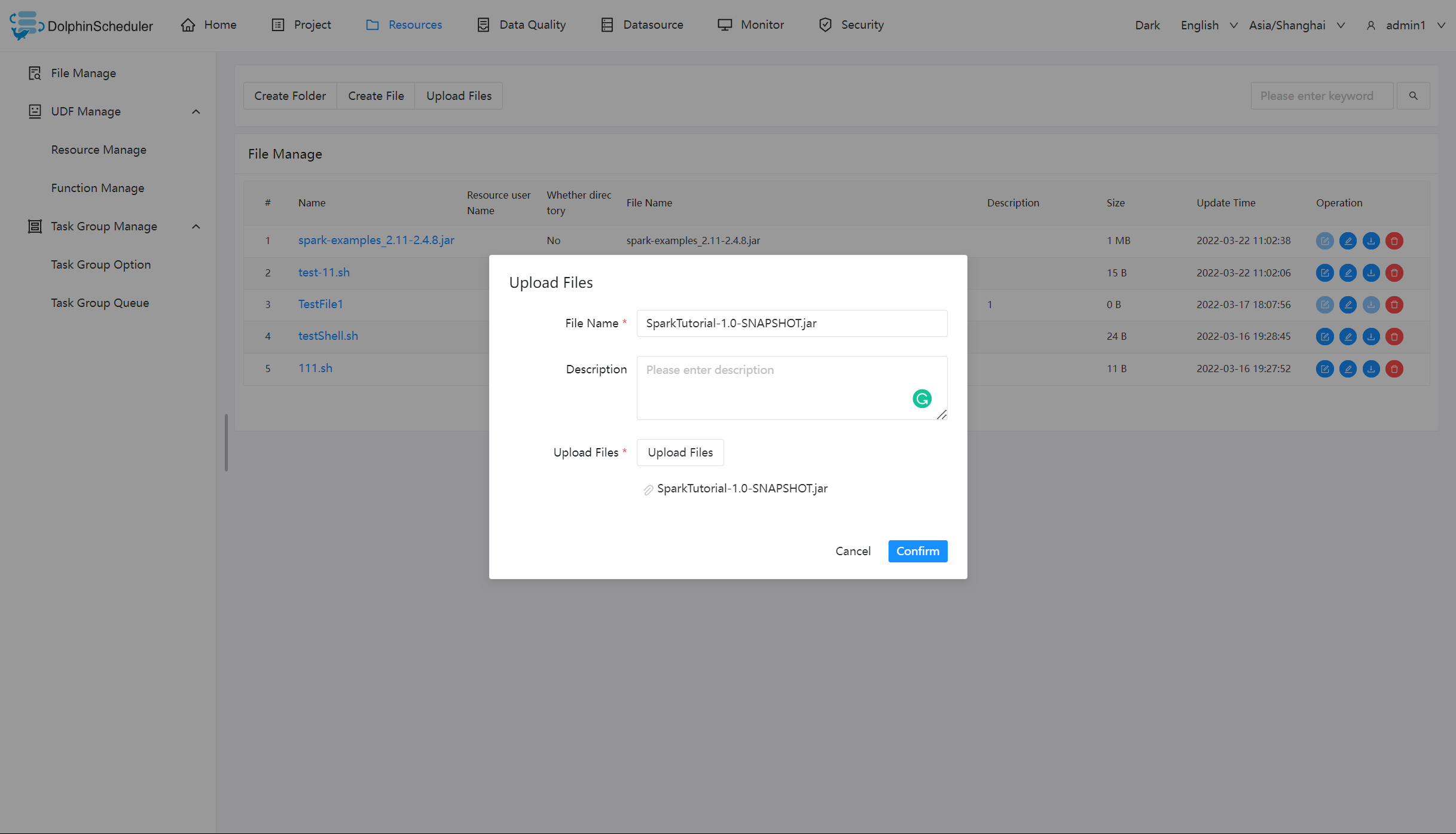
上传文件
上传文件:点击"上传文件"按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
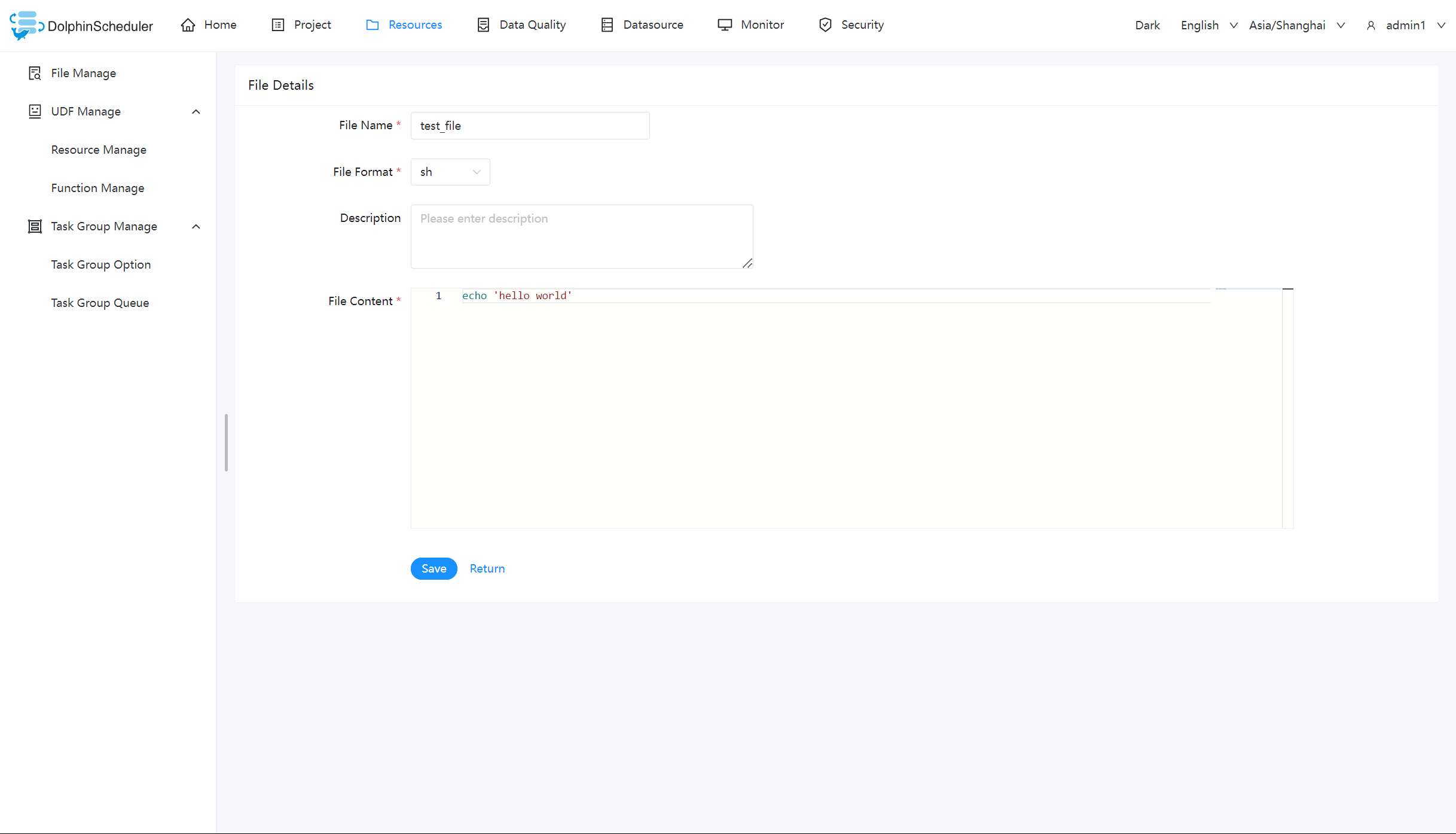
文件查看
对可查看的文件类型,点击文件名称,可查看文件详情
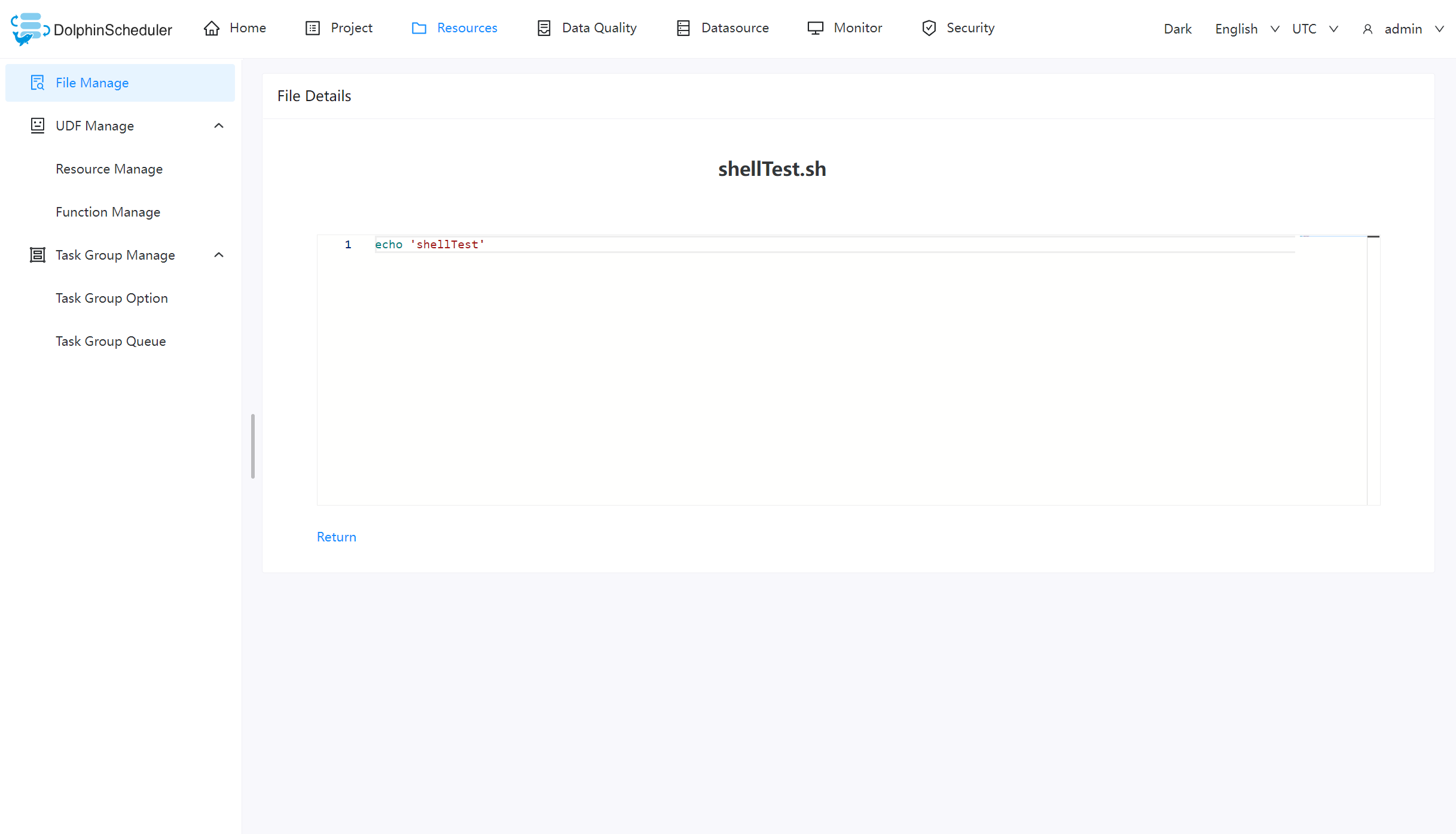
下载文件
点击文件列表的"下载"按钮下载文件或者在文件详情中点击右上角"下载"按钮下载文件
文件重命名
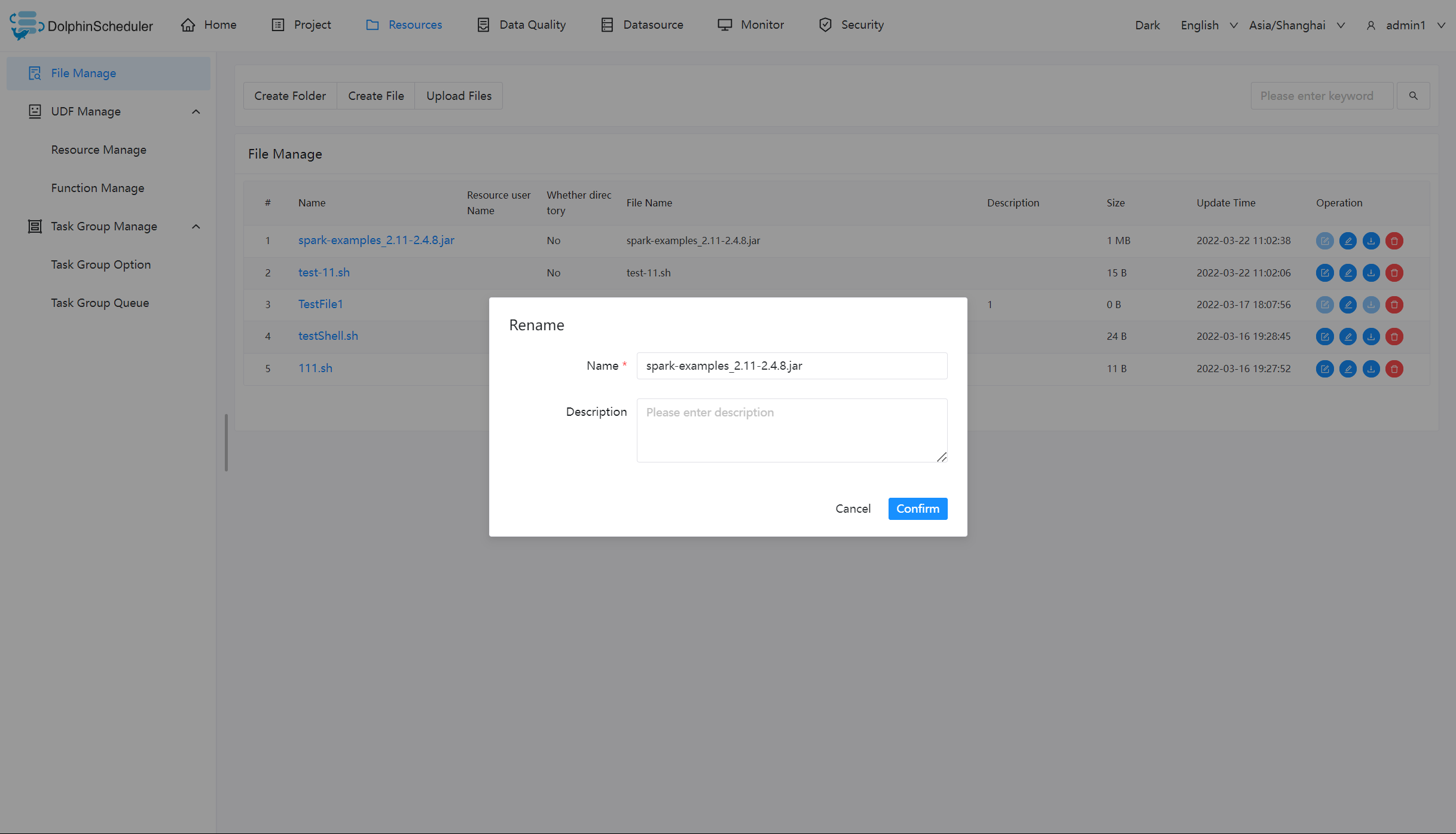
删除文件
文件列表->点击"删除"按钮,删除指定文件
任务样例
该样例主要通过一个简单的 shell 脚本,来演示如何在工作流定义中使用资源中心的文件。像 MR、Spark 等任务需要用到 jar 包,也是同理。
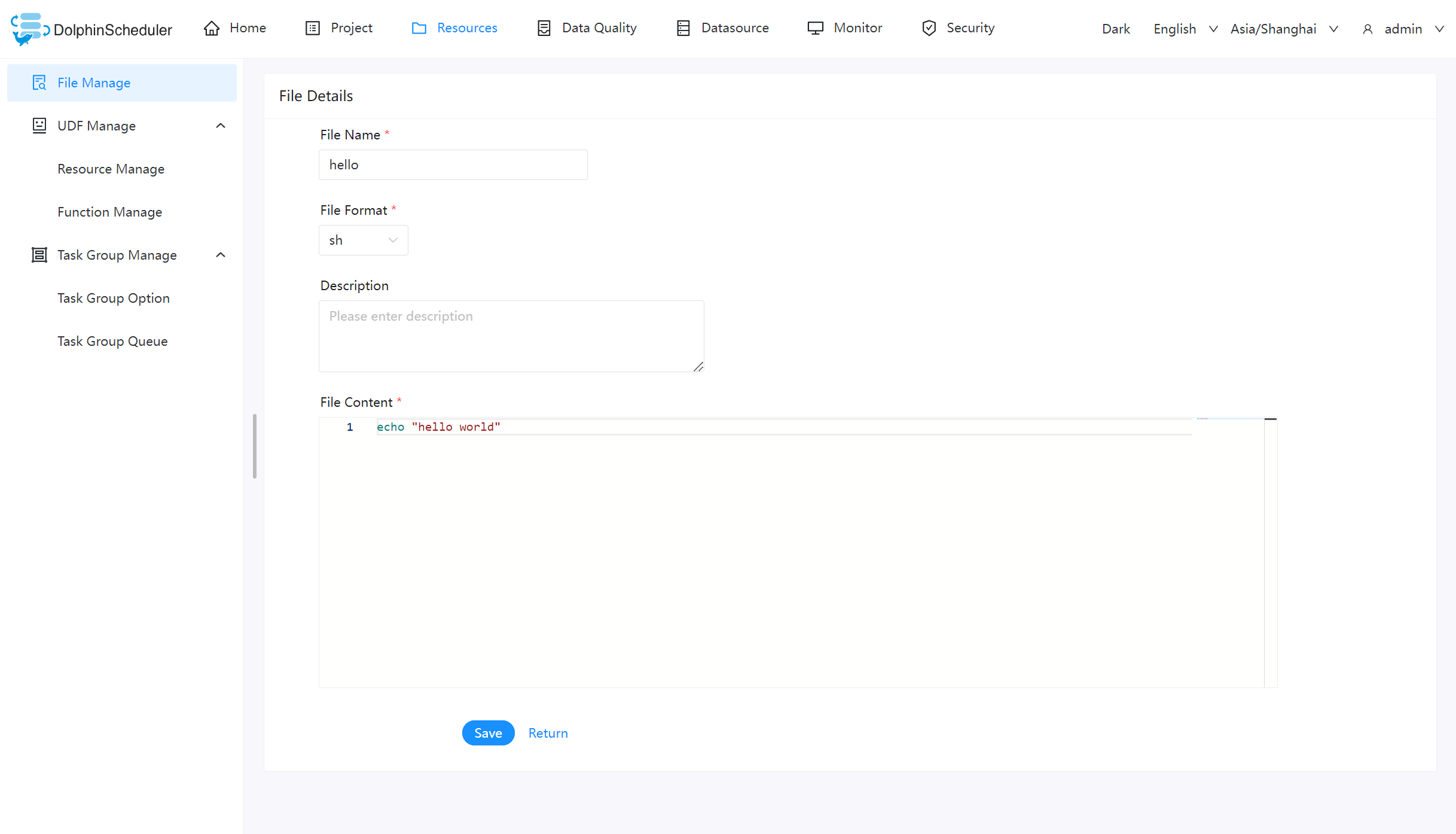
创建 shell 文件
创建一个 shell 文件,输出 “hello world”。
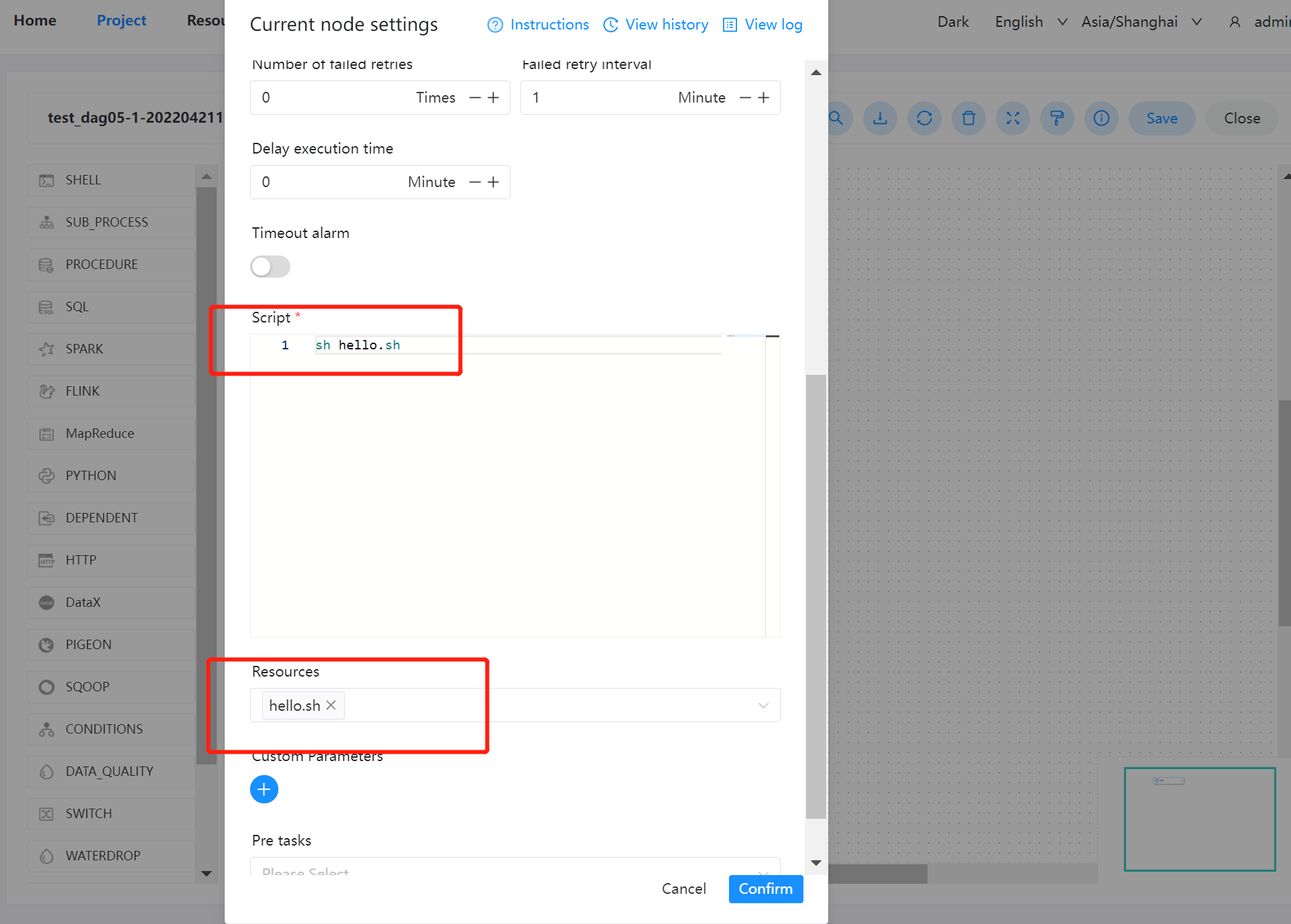
创建工作流执行文件
在项目管理的工作流定义模块,创建一个新的工作流,使用 shell 任务。
-
脚本: sh resource/hello.sh -
资源:选择 resource/hello.sh
注意:脚本中选择资源文件时文件名称需要保持和所选择资源全路径一致: 例如:资源路径为
resource/hello.sh则脚本中调用需要使用resource/hello.sh全路径
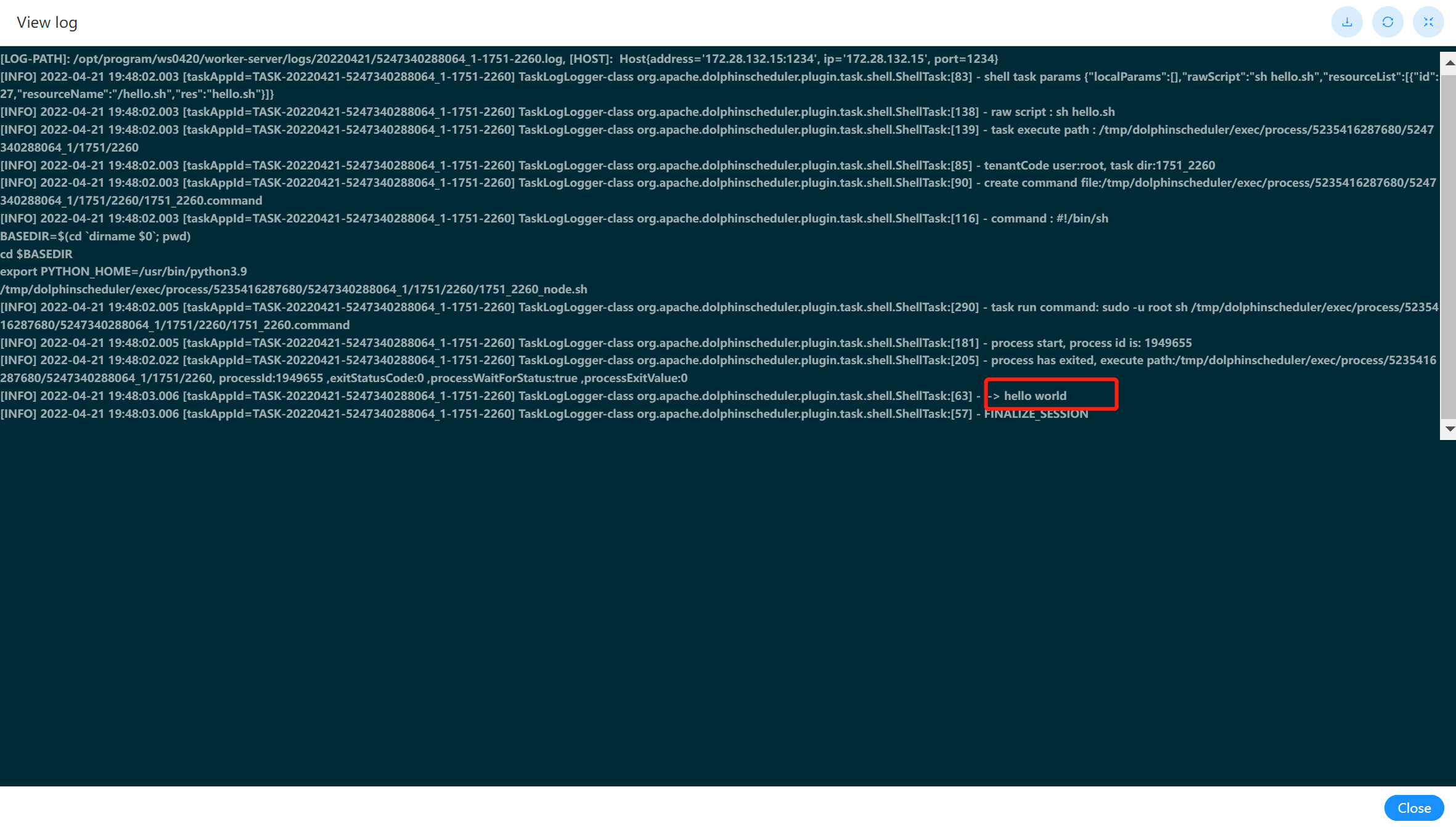
查看结果
可以在工作流实例中,查看该节点运行的日志结果。如下图:
4 工作流实例使用
这样就能在节点里选用之前创建的资源:
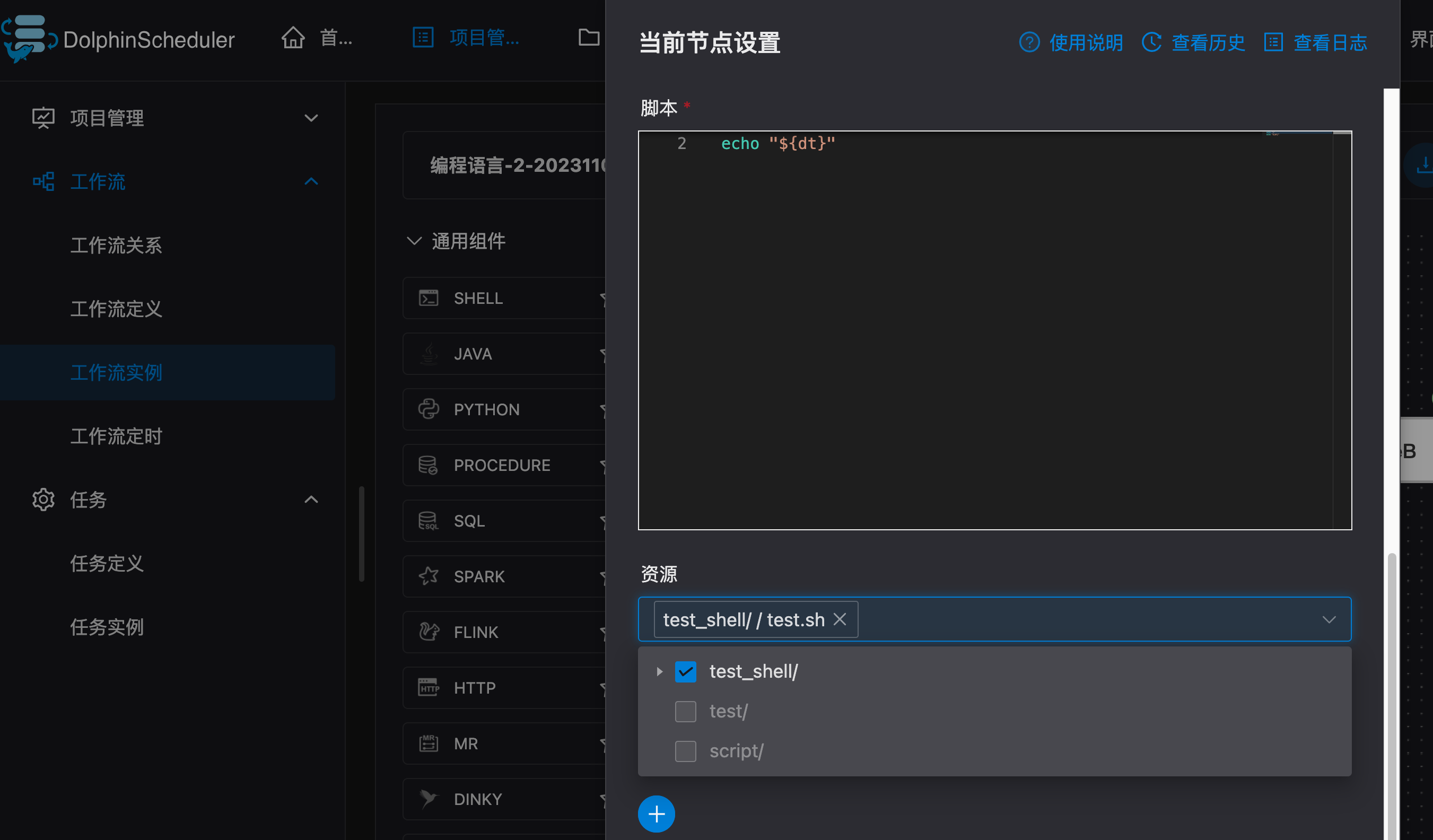
选择完了后,如何调用呢?注意使用相对路径(毕竟一般资源文件都在 HDFS 上,绝对路径不好写)
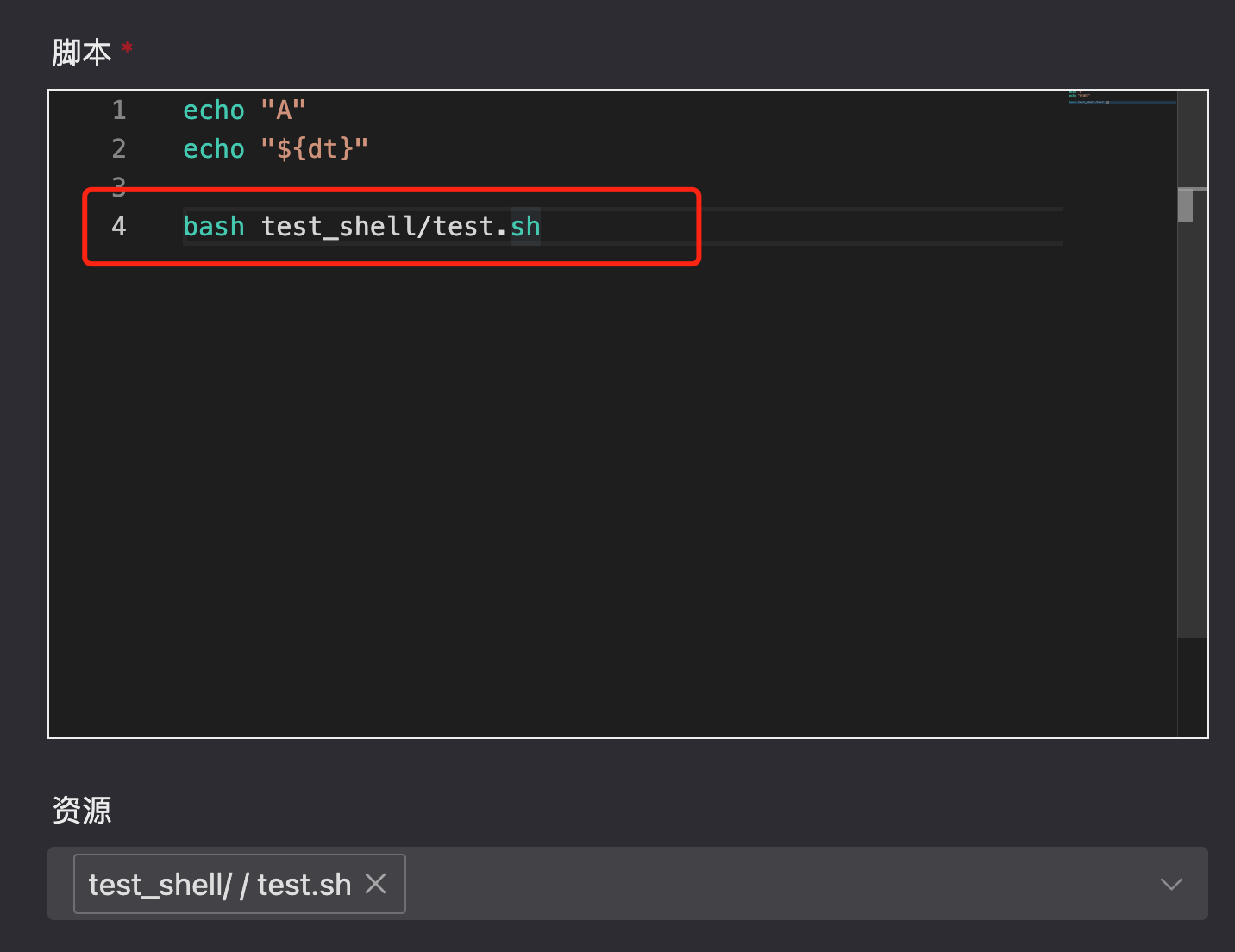
最后观察日志验证即可。
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布