SparkSql读取数据的方式
一、读取普通文件
方式一:给定读取数据源的类型和地址
spark.read.format("json").load(path)
spark.read.format("csv").load(path)
spark.read.format("parquet").load(path)方式二:直接调用对应数据源类型的方法
spark.read.json(path)
spark.read.csv(path)
spark.read.parquet(path)1、代码演示最普通的文件读取方式:
from pyspark.sql import SparkSession
import os
if __name__ == '__main__':
# 构建环境变量
# 配置环境
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 获取sparkSession对象
spark = SparkSession.builder.master("local[2]").appName("第一次构建SparkSession").config(
"spark.sql.shuffle.partitions", 2).getOrCreate()
df01 = spark.read.json("../../datas/resources/people.json")
df01.printSchema()
df02 = spark.read.format("json").load("../../datas/resources/people.json")
df02.printSchema()
df03 = spark.read.parquet("../../datas/resources/users.parquet")
df03.printSchema()
#spark.read.orc("")
df04 = spark.read.format("orc").load("../../datas/resources/users.orc")
df04.printSchema()
df05 = spark.read.format("csv").option("sep",";").load("../../datas/resources/people.csv")
df05.printSchema()
df06 = spark.read.load(
path="../../datas/resources/people.csv",
format="csv",
sep=";"
)
df06.printSchema()
spark.stop()二、 通过jdbc读取数据库数据
先在本地数据库或者linux数据库中插入一张表:
CREATE TABLE `emp` (
`empno` int(11) NULL DEFAULT NULL,
`ename` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`job` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`mgr` int(11) NULL DEFAULT NULL,
`hiredate` date NULL DEFAULT NULL,
`sal` decimal(7, 2) NULL DEFAULT NULL,
`comm` decimal(7, 2) NULL DEFAULT NULL,
`deptno` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800.00, NULL, 20);
INSERT INTO `emp` VALUES (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600.00, 300.00, 30);
INSERT INTO `emp` VALUES (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250.00, 500.00, 30);
INSERT INTO `emp` VALUES (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975.00, NULL, 20);
INSERT INTO `emp` VALUES (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250.00, 1400.00, 30);
INSERT INTO `emp` VALUES (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850.00, NULL, 30);
INSERT INTO `emp` VALUES (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450.00, NULL, 10);
INSERT INTO `emp` VALUES (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000.00, NULL, 20);
INSERT INTO `emp` VALUES (7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000.00, NULL, 10);
INSERT INTO `emp` VALUES (7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500.00, 0.00, 30);
INSERT INTO `emp` VALUES (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100.00, NULL, 20);
INSERT INTO `emp` VALUES (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950.00, NULL, 30);
INSERT INTO `emp` VALUES (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000.00, NULL, 20);
INSERT INTO `emp` VALUES (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300.00, NULL, 10);dept的数据:
CREATE TABLE `dept` (
`deptno` int(11) NULL DEFAULT NULL,
`dname` varchar(14) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`loc` varchar(13) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of dept
-- ----------------------------
INSERT INTO `dept` VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO `dept` VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO `dept` VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO `dept` VALUES (40, 'OPERATIONS', 'BOSTON');查询时会报如下错误:
py4j.protocol.Py4JJavaError: An error occurred while calling o67.load.
: java.lang.ClassNotFoundException: com.mysql.cj.jdbc.Driver
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:46)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1(JDBCOptions.scala:102)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1$adapted(JDBCOptions.scala:102)接着放驱动程序:
Python环境放入MySQL连接驱动
- 找到工程中pyspark库包所在的环境,将驱动包放入环境所在的jars目录中
- 如果是Linux上:注意集群模式所有节点都要放。
第一种情况:
假如你是windows环境:
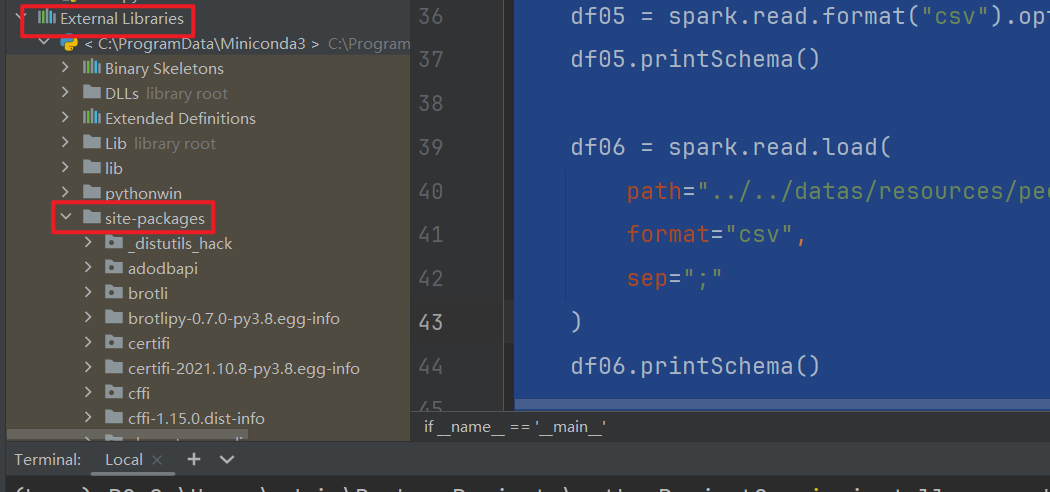
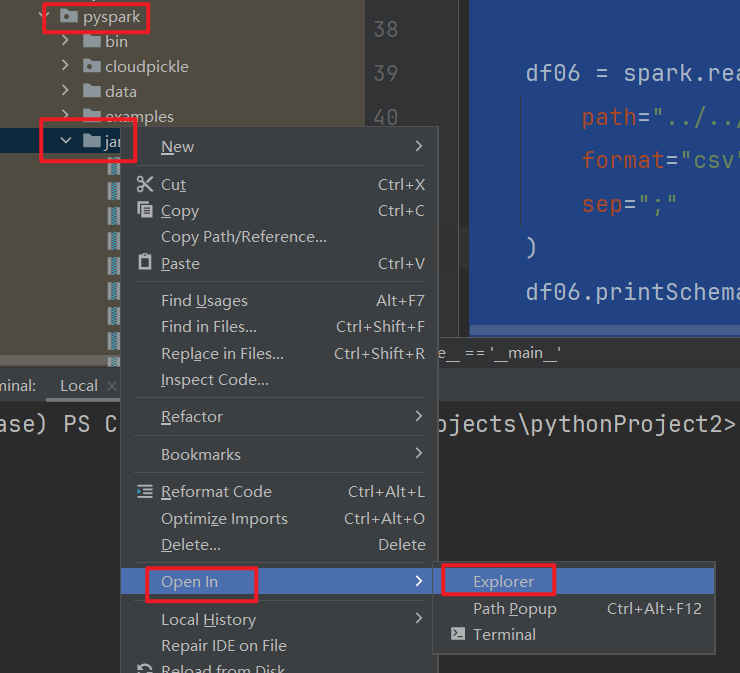
我的最终的路径是在这里:
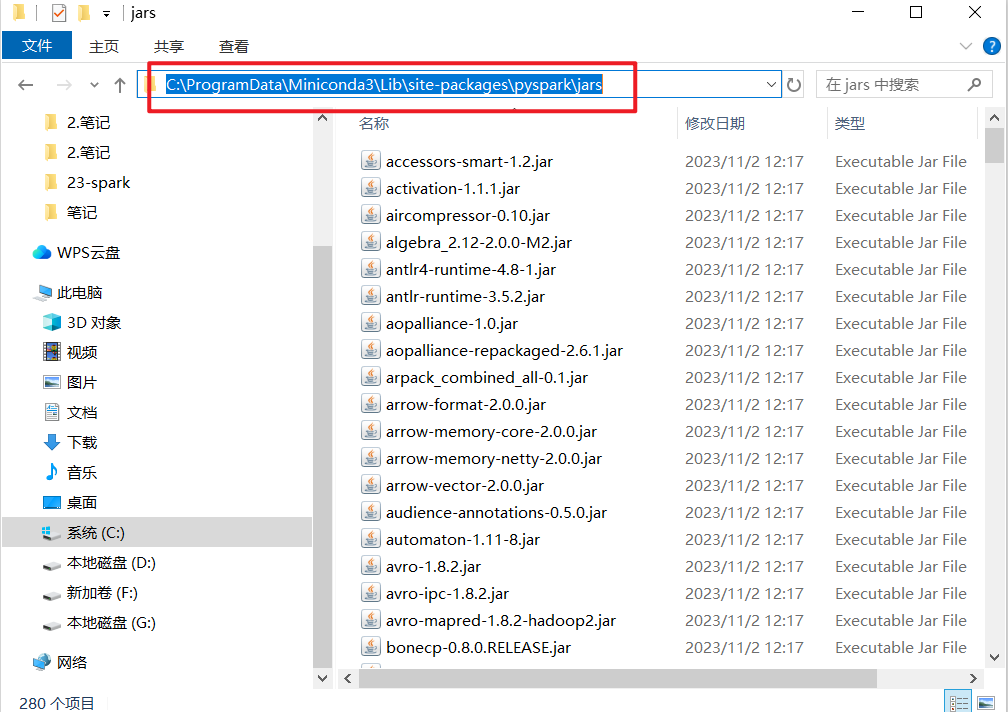

第二种情况:linux环境下,按照如下方式进行
# 进入目录
cd /opt/installs/anaconda3/lib/python3.8/site-packages/pyspark/jars
# 上传jar包:mysql-connector-java-5.1.32.jar代码演示:
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
if __name__ == '__main__':
# 获取sparkSession对象
# 设置 任务的环境变量
os.environ['JAVA_HOME'] = r'C:\Program Files\Java\jdk1.8.0_77'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = r'C:\ProgramData\Miniconda3\python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 得到sparkSession对象
spark = SparkSession.builder.master("local[2]").appName("").config("spark.sql.shuffle.partitions", 2).getOrCreate()
dict = {"user":"root","password":"root"}
jdbcDf = spark.read.jdbc(url="jdbc:mysql://localhost:3306/spark",table="emp",properties=dict)
jdbcDf.show()
# jdbc的另一种写法
jdbcDf2 = spark.read.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://localhost:3306/spark") \
.option("dbtable", "spark.dept") \
.option("user", "root") \
.option("password", "root").load()
jdbcDf2.show()
# 关闭
spark.stop()三、 读取table中的数据【hive】
- 场景:Hive底层默认是MR引擎,计算性能特别差,一般用Hive作为数据仓库,使用SparkSQL对Hive中的数据进行计算
-
- 存储:数据仓库:Hive:将HDFS文件映射成表
- 计算:计算引擎:SparkSQL、Impala、Presto:对Hive中的数据表进行处理
- 问题:SparkSQL怎么能访问到Hive中有哪些表,以及如何知道Hive中表对应的
1)集群环境操作hive
需要启动的服务:
先退出base环境:conda deactivate
启动服务:
启动hdfs: start-dfs.sh 因为hive的数据在那里存储着
启动yarn: start-yarn.sh 因为spark是根据yarn部署的,假如你的spark是standalone模式,不需要启动yarn.
日志服务也需要启动一下:
mapred --daemon start historyserver
# 启动Spark的HistoryServer:18080
/opt/installs/spark/sbin/start-history-server.sh
启动metastore服务: 因为sparkSQL需要知道表结构,和表数据的位置
hive-server-manager.sh start metastore
启动spark服务: 啥服务也没有了,已经启动完了。
查看metastore服务:
hive-server-manager.sh status metastore修改配置:
cd /opt/installs/spark/conf
新增:hive-site.xml
vi hive-site.xml
在这个文件中,编写如下配置:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata01:9083</value>
</property>
</configuration>
接着将该文件进行分发:
xsync.sh hive-site.xml操作sparkSQL:
/opt/installs/spark/bin/pyspark --master local[2] --conf spark.sql.shuffle.partitions=2此处的pyspark更像是一个客户端,里面可以通过python编写spark代码而已。而我们以前安装的pyspark更像是spark的python运行环境。
进入后,通过内置对象spark:
>>> spark.sql("show databases").show()
+---------+
|namespace|
+---------+
| default|
| yhdb|
+---------+
>>> spark.sql("select * from yhdb.student").show()
+---+------+
|sid| sname|
+---+------+
| 1|laoyan|
| 1|廉德枫|
| 2| 刘浩|
| 3| 王鑫|
| 4| 司翔|
+---+------+2)开发环境如何编写代码,操作hive:
代码实战:
from pyspark.sql import SparkSession
import os
if __name__ == '__main__':
# 构建环境变量
# 配置环境
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 防止在本地操作hdfs的时候,出现权限问题
os.environ['HADOOP_USER_NAME'] = 'root'
# 获取sparkSession对象
spark = SparkSession \
.builder \
.appName("HiveAPP") \
.master("local[2]") \
.config("spark.sql.warehouse.dir", 'hdfs://bigdata01:9820/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://bigdata01:9083') \
.config("spark.sql.shuffle.partitions", 2) \
.enableHiveSupport() \
.getOrCreate()
spark.sql("select * from yhdb.student").show()
spark.read.table("yhdb.student").show()
spark.stop()
不要在一个python 文件中,创建两个不同的sparkSession对象,否则对于sparksql获取hive的元数据,有影响。