大模型与搜索引擎结合:智能体、思维链和智谱AI搜索代码案例
随着大模型的不断发展,现在大模型在应用场景中逐渐改变了我们的使用习惯。通过RAG和搜索引擎的集成,大模型能逐步改善幻觉和时效性的问题。
本文将介绍现在行业中,如何将搜索引擎与大模型的集成方法,也将会演示如何调用智谱AI智能搜索功能。
生成式AI 与 搜索引擎
随着生成式AI(如ChatGPT和Perplexity AI)的出现,搜索引擎开始生成、索引和分发由GenAI创建的内容。主要的搜索引擎如You.com、Bing和Google已经开始尝试将GenAI整合到他们的平台中。
大型语言模型(LLMs)是生成式搜索系统的核心,它们通过学习网络数据来预测下一个词。这些模型可能会产生事实上的不一致或编造内容,这种现象被称为“幻觉”。
生成式搜索引擎可能会隐藏信息的来源,这与传统搜索引擎优化相关性和效率不同,因为它们需要对信息的准确性或可验证性负责。
MindSearch(思索)
MindSearch 思·索: Mimicking Human Minds Elicits Deep AI Searcher
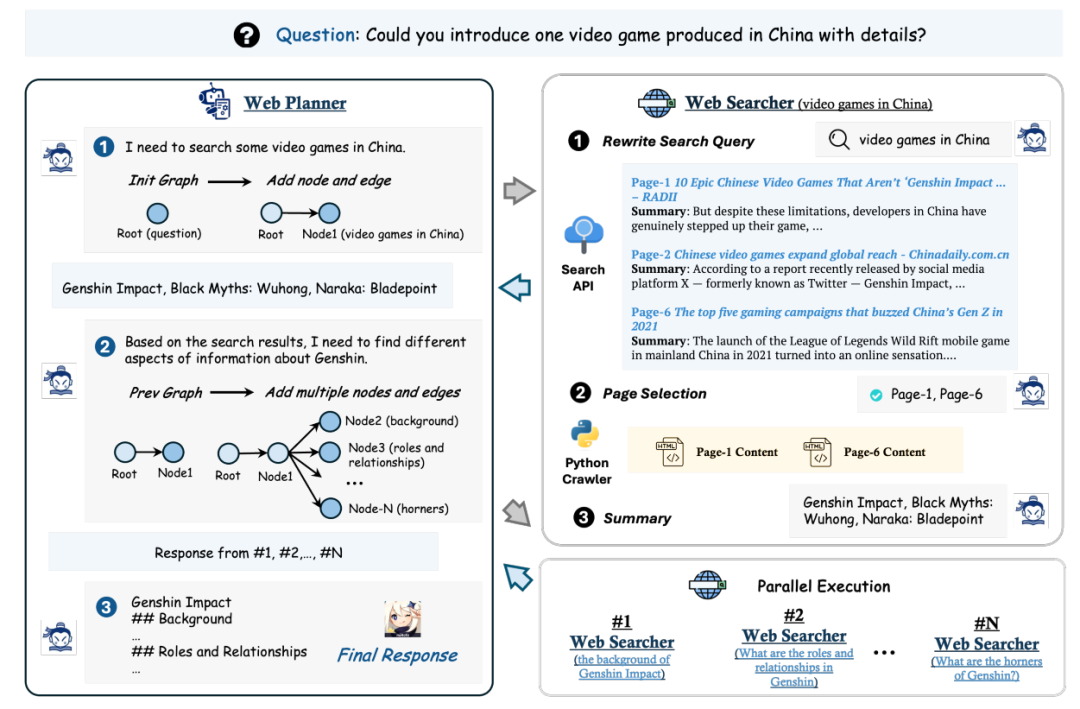
MindSearch(思索),模仿人类在网络信息寻求和整合中的思维,可以通过一个简单但有效的基于LLM的多代理框架实例化,包括WebPlanner和WebSearcher。
-
WebPlanner模拟人类多步信息寻求的心智,作为一个动态图构建过程:它将用户查询分解为图中的原子子问题节点,并基于WebSearcher的搜索结果逐步扩展图。
-
WebSearcher负责每个子问题,执行层次化的信息检索,并为WebPlanner收集有价值的信息。
MindSearch的多代理设计使得整个框架能够从更大规模(例如,300多个)网页中并行寻求和整合信息,仅需3分钟,相当于人类3小时的工作量。
WebPlanner:通过图构建进行规划
WebPlanner充当高级规划者,协调推理步骤和其他代理。然而,我们观察到,仅仅提示LLM规划整个数据工作流程架构并不能产生令人满意的性能。
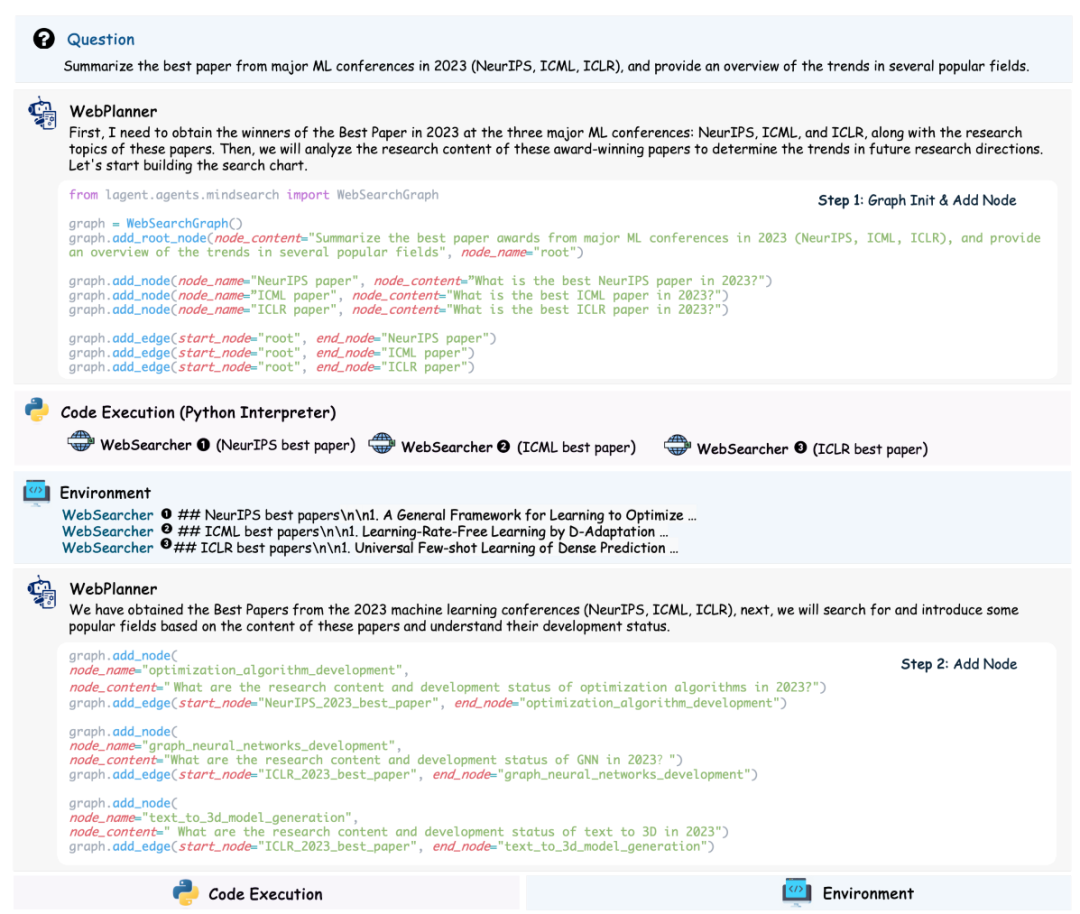
当前的LLMs在分解复杂问题和理解它们的拓扑关系方面存在困难,导致粗粒度的搜索查询。这种方法没有充分利用LLMs作为人类和搜索引擎之间的中介,将人类意图转化为逐步搜索任务并提供准确响应的潜力。
WebSearcher:层次检索的网络浏览
WebSearcher充当复杂的RAG(检索和生成)代理,根据搜索结果总结有价值的响应。由于网络上可用的大量内容,LLMs在有限的上下文长度内处理所有相关页面是具有挑战性的。为了解决这个问题,我们采用了简单的从粗到细的选择策略。

LLM根据WebPlanner分配的问题生成几个类似查询,以扩大搜索内容,从而提高相关信息的召回率。这些查询然后通过各种搜索API(如Google、Bing和DuckDuckGo)执行,返回关键内容,包括网页URL、标题和摘要。搜索结果根据网页URL自动合并,LLM被提示选择最有价值的页面进行详细阅读。然后,所选网页的全部内容被添加到LLM的输入中。
MindSearch中的LLM上下文管理
MindSearch提供了一个简单的多代理解决方案,用于处理搜索引擎的复杂信息寻求和整合任务。这种范式还在不同代理之间自然地实现了长上下文管理,提高了框架的整体效率,特别是在需要模型快速阅读大量网页的情况下。
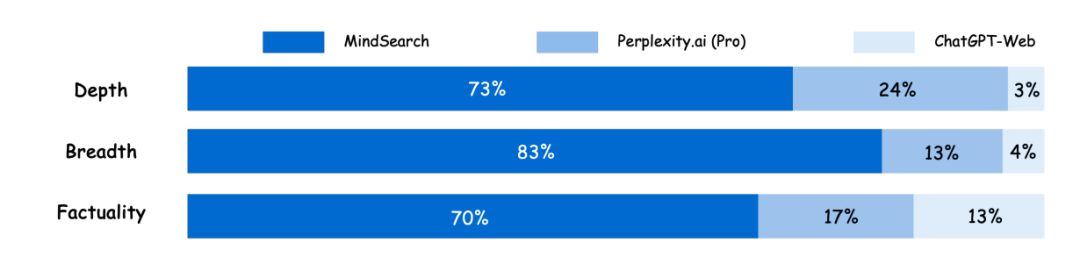
由于WebPlanner将搜索任务分配给单独的搜索代理,并且只依赖于WebSearcher的搜索结果,WebPlanner可以专注于用户问题的分解和分析,而不受过长的网页搜索结果的干扰。
同时,每个WebSearcher只需要搜索其任务子查询的内容,不受其他内容的干扰。由于明确的角色分配,MindSearch在整个过程中大大减少了上下文计算,为LLM的长上下文任务提供了高效的上下文管理解决方案。
搜索思维链
Search-in-the-Chain: Interactively Enhancing Large Language Models with Search for Knowledge-intensive Tasks
以往的工作存在IR检索的错误知识误导LLM和IR与LLM之间的交互打断LLM推理链的问题。在搜索链中提出的SearChain框架通过以下三个步骤解决了这些挑战:
-
LLM生成一个名为“Chain-of-Query(CoQ)”的推理链,其中每个节点由面向IR的查询-答案对组成。
-
IR验证CoQ中每个节点的答案,并在IR有高信心时纠正与检索信息不一致的答案,提高了可信度。
-
LLM可以在CoQ中指示其缺失的知识,并依赖IR提供这些知识给LLM,提高了推理和知识的准确性。
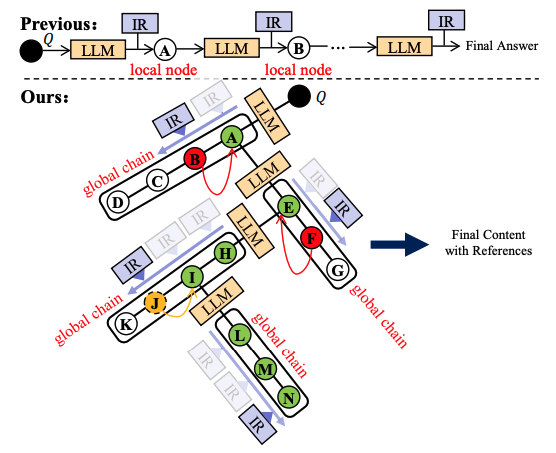
SearChain通过LLM和IR之间的多轮交互来设计。在每一轮中,LLM首先构建一个CoQ,然后IR与CoQ的每个节点进行交互,执行验证和补全。这个过程一直持续到所有查询都不需要更正或补全,或者达到最大交互轮数。SearChain通过追溯正确的推理路径来生成最终内容,并标记每一步推理的支持文档。
用户偏向:搜索引擎 or 大模型?
Large Language Models vs. Search Engines: Evaluating User Preferences Across Varied Information Retrieval Scenarios
为此研究者涉及100名美国互联网用户的样本,覆盖了从查找COVID-19指南到用通俗语言解释复杂概念的20种不同用例。研究发现,在直接、基于事实的查询中,用户更倾向于使用搜索引擎,而在需要细致理解和语言处理的任务中,LLMs更受青睐。
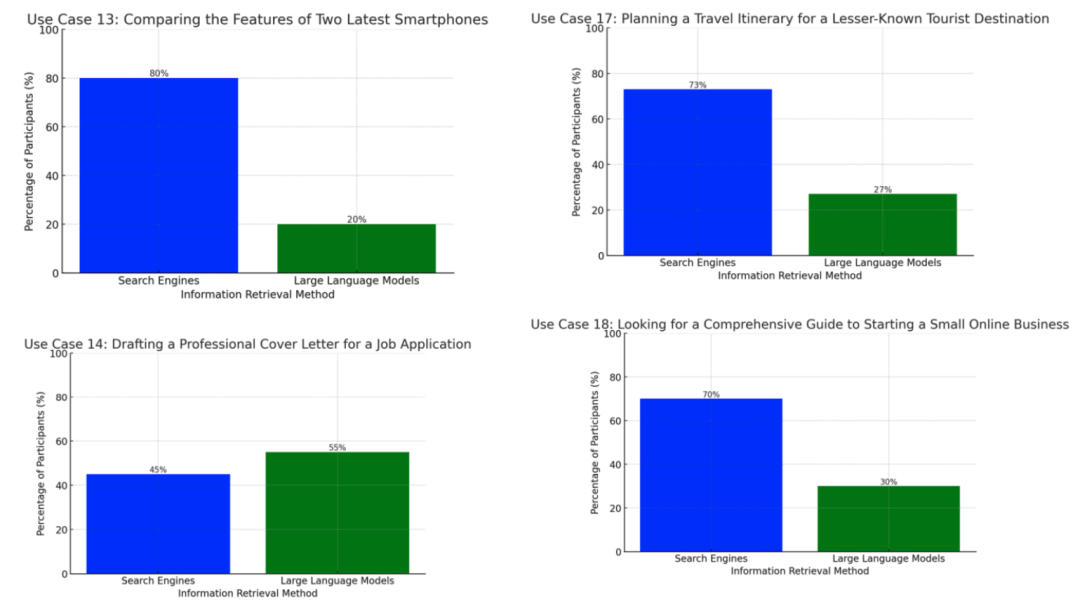
研究采用了定量方法,通过调查100名美国互联网用户,收集了他们在20种不同用例中的偏好数据。这些用例覆盖了健康、技术、金融和教育等多个领域,以确保分析的全面性。
-
搜索引擎在事实信息检索中的主导地位:用户在需要事实数据检索的场景中更倾向于使用搜索引擎。
-
LLMs在主观和语言相关任务中的偏好:LLMs在涉及语言学习和通俗解释的场景中更受青睐。
-
导航便捷性与对话深度:用户偏好搜索引擎的导航便捷性和LLMs的对话深度。
-
LLMs在复杂查询中的增长角色:LLMs在处理复杂查询方面正在缩小与搜索引擎的差距。
-
信息检索工具未来发展的影响:研究结果强调了开发结合搜索引擎和LLMs优势的工具的潜力。
智谱AI智能搜索
智谱AI专业联网搜索工具限时免费中!
专业版联网搜索在传统搜索引擎网页抓取、排序的能力基础上,增强了意图识别,支持搜索结果的流式输出。搜索工具能更有效地结合在大语言模型应用中,提高用户获取信息的效率,并一定程度上解决大语言模型所面临的幻觉问题。
https://bigmodel.cn/dev/api/search-tool/web-search-pro
| 传输方式 | https |
|---|---|
| 请求地址 | https://open.bigmodel.cn/api/paas/v4/tools |
| 调用方式 | 同步调用,等待模型执行完成并返回最终结果或 SSE 调用 |
| 字符编码 | UTF-8 |
| 接口请求格式 | JSON |
| 响应格式 | JSON 或标准 Stream Event |
| 接口请求类型 | POST |
| 开发语言 | 任意可发起 HTTP 请求的开发语言 |
- 启用与禁用 web_search
网络搜索功能默认为关闭状态(False)。当启用搜索(设置为 True)时,系统会自动判断是否需要进行网络检索,并调用搜索引擎获取相关信息。检索成功后,搜索结果将作为背景信息输入给大模型进行进一步处理。每次网络搜索大约会增加1000个 tokens 的消耗。
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="填入你的key")
tools = [{
"type": "web_search",
"web_search": {
"enable": True #默认为关闭状态(False) 禁用:False,启用:True。
}
}]
messages = [{
"role": "user",
"content": "中国 2024 年一季度的GDP是多少 "
}]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
tools=tools
)
print(response.choices[0].message.content)
- 自定义搜索内容
使用 search_query 参数可以自定义搜索内容,提升搜索结果的相关性和精确度。如果不传 search_query 参数,系统将根据用户的消息自动进行网页检索。
tools = [{
"type": "web_search",
"web_search": {
"enable": True,
"search_query": "Datawhale 阿水 北航学长"
}
}]
messages = [{
"role": "user",
"content": "介绍一下Datawhale"
}]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
tools=tools
)
print(response.choices[0].message.content)
- 返回搜索来源
启用 search_result 参数允许用户获取详细的网页搜索来源信息,包括来源网站的图标、标题、链接、来源名称以及引用的文本内容。
tools = [{
"type": "web_search",
"web_search": {
"enable": True,
"search_result": True # 禁用False,启用:True,默认为禁用
}
}]
messages = [{
"role": "user",
"content": "最新的AI发展趋势"
}]
response = client.chat.completions.create(
model="glm-4",
messages=messages,
tools=tools
)
print(response.choices[0].message.content)
实现效果如下:


读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
