化学学习和工作常用网站推荐
化学领域有多个专业学术数据库,这些数据库提供了丰富的化学文献、化合物数据和反应机理等资源。它们覆盖化学各个分支,包含最新研究成果和历史资料,为科研人员提供了全面的学术支持。这些数据库各有特色,有的侧重化学实验数据,有的更注重理论分析,满足不同研究需求。它们还提供高级搜索功能,提高研究效率,并且这些数据库的检索和分析功能也在增强,助力化学领域的创新和发展。
下面为大家详细的盘点一下2024年核心化学数据库
1、CAS SciFindern数据库
【网址】:https://scifinder-n.cas.org
CAS SciFindern由美国化学会旗下的美国化学文摘社(Chemical Abstracts Service, CAS)出品,是一个研发应用平台,提供全球最大、最权威的化学及相关学科文献、物质和反应信息。综合了全球200多个国家和地区的60多种语言的1万多份期刊,内容丰富全面,用户可以通过主题、分子式、结构式和反应式等多种方式进行检索。该平台汇集了180多个国家、50多种语言出版的文献及64家专利授权机构的专利,包含5900万化学及相关学科文献、2.04亿化学物质、1.5亿化学反应、139万来自专利的马库什结构、化学品商业信息及管控信息,最早回溯至1840年。
CAS SciFindern的一大特色是可以提供专利马库什结构的机构。平台从全球64家专利机构的公开专利中提取了超过139万个可检索的马库什结构,一个马库什结构可能涵盖数千甚至数万个化合物,这大大增强了研发和知识产权专业人士在进行化合物结构的新颖性和创造性搜索、发现相似专利以及评估潜在侵权风险的能力。并且其中的CAS PatentPak模块在定位和分析大量专利中的化学结构方面,采用人工标引,检索人员可以快速识别专利中难以发现的物质(例如,表格化合物和图形图像内的化合物)。该平台的另一特色是其含有7.2亿生物序列,可进行FTO检索、侵权检索,可以更好的服务与研发人员及知识产权相关行业人士。CAS SciFindern数据库中还包括一个反应信息数据库CASReact,收集了各种反应与制备信息。
2、Reaxys数据库
【网址】:https://www.reaxys.com
Reaxys数据库是目前最大的化学数据库,其收录的数据范围涵盖有机合成、药物化学、天然产物化学、无机化学和金属有机化学,并将化学反应,化合物物性数据,合成线路设计进行无缝对接,使科技检索工作更加高效、精准,并以其强大的检索功能和深入的核心信息摘录为化学研究注入新的生机。Reaxys 将十多亿个化学数据点与人工智能相结合,为药物发现、化学研发和学术界的创新提供支持。化学家可以快速获取相关的专利、物质和生物活性见解以及屡获殊荣的逆合成工具。
Reaxys在Beilstein基础上整合了盖墨林(Gmelin)和专利化学数据库(PCD)以及化学相关期刊的内容,能帮助科研人员快速全面地查询化合物的理化数据,设计经济、高效的合成路线,最大程度节省时间和资金成本。 其收录的数据范围涵盖有机合成、药物化学、天然产物化学、无机化学和金属有机化学,并将化学反应,化合物物性数据,合成线路设计进行无缝对接,使科技检索工作更加高效、精准,并以其强大的检索功能和深入的核心信息摘录为化学研究注入新的生机。在进行结构式检索时,Reaxys 提供了多种检索模式和工具,以帮助用户精确地找到所需的化合物和反应信息。
3、Web of Science数据库
【网址】:https://www.webofscience.com
Web of Science是一个综合性的学术资源库,由Clarivate Analytics公司开发和维护的信息服务平台。收录了全球2万多种权威的、高影响力的学术期刊,超过20万份会议记录以及10万多种科技图书的题录摘要,内容涵盖自然科学、生物医学、工程技术、社会科学、艺术与人文等领域,其数据来源包括期刊文章、书籍、专利、会议论文集以及网络资源(涵盖开放获取资源)等多种形式。
Web of Science包括了全球范围内的学术期刊、会议论文、专利等丰富的学术资源。Web of Science以其对文献的广泛覆盖和引用分析功能而受到学术界的重视。通过检索和跟踪文献的引用关系,研究人员可以深入理解特定学术领域的学术影响力,探索相关研究领域,并识别可能的合作研究机会。
此外,Web of Science还提供了包括作者分析、机构分析和引文报告等在内的多种功能,这些功能为研究人员在评估自己的研究成果、寻找合作伙伴以及掌握学术界最新趋势方面提供了便利。
wos也提供结构式检索功能,在进入Web of Science 网页可以直接选择“化学结构”,即可进行检索,支持结构式、化合物数据及反应数据检索,支持mol文件的导入及下载。检索结果提供WOS平台上的相关文献,可查看化学反应文献。
4、摩熵化学
【网址】:https://rxn.molaid.com
摩熵化学是由碳氢数科打造的一个功能强大的化合物检索及合成设计平台。拥有海量化合物信息、化学实验数据和化学反应数据等,通过Al+大数据技术从数百万高质量期刊文献中智能分类提取化合物和反应信息。收录全球数以亿计的化学品数据,提供精准数据信息,包括物化性质、毒理性、反应、文献、晶体、谱图、安全等信息数据。支持查询化合物、了解物质性质、寻找购买信息、查询反应条件、设计反应路线、谱图查询、预测性质及谱图等,实现合成实验全场景覆盖。摩熵化学提供多种检索方式可针对不同的用户场景,面对复杂化合物,可以采取绘制结构进行查询。
化合物数据:收录1.6亿个化合物,数据来源权威,数据量全面,实现有效搜索。
反应信息数据:收录2500万个化学反应,支持用户转换物质角色,灵活筛选,快速查询到反应条件高效推进实验进程;一键直达原文链接,加快科研进度。
物化性质数据:全面的收录化合物物化性质信息,可视化设计方便用户掌握化合物基本性质。
谱图数据:约20万个真实实验谱图,来源可溯,全面表征化合物;表格展示峰位数据,界面简洁明晰。
晶体信息数据:收录100万个晶体数据,信息全面;支持查看3D晶体结构。
安全信息数据:约180万个化合物安全信息,提供多版本权威SDS文件精确掌握化合物潜在危害及防护措施,提高研究人员安全。
商品信息数据:约740万个商品信息,一站式搜索,全面清晰了解各个品牌商家的商品信息,包括价格、联系方式、官方网站等,利于科研人员和企业对比价格节约研发成本。
近期还新增了文献检索、1000多人名反应检索和30多保护基团信息及示例。
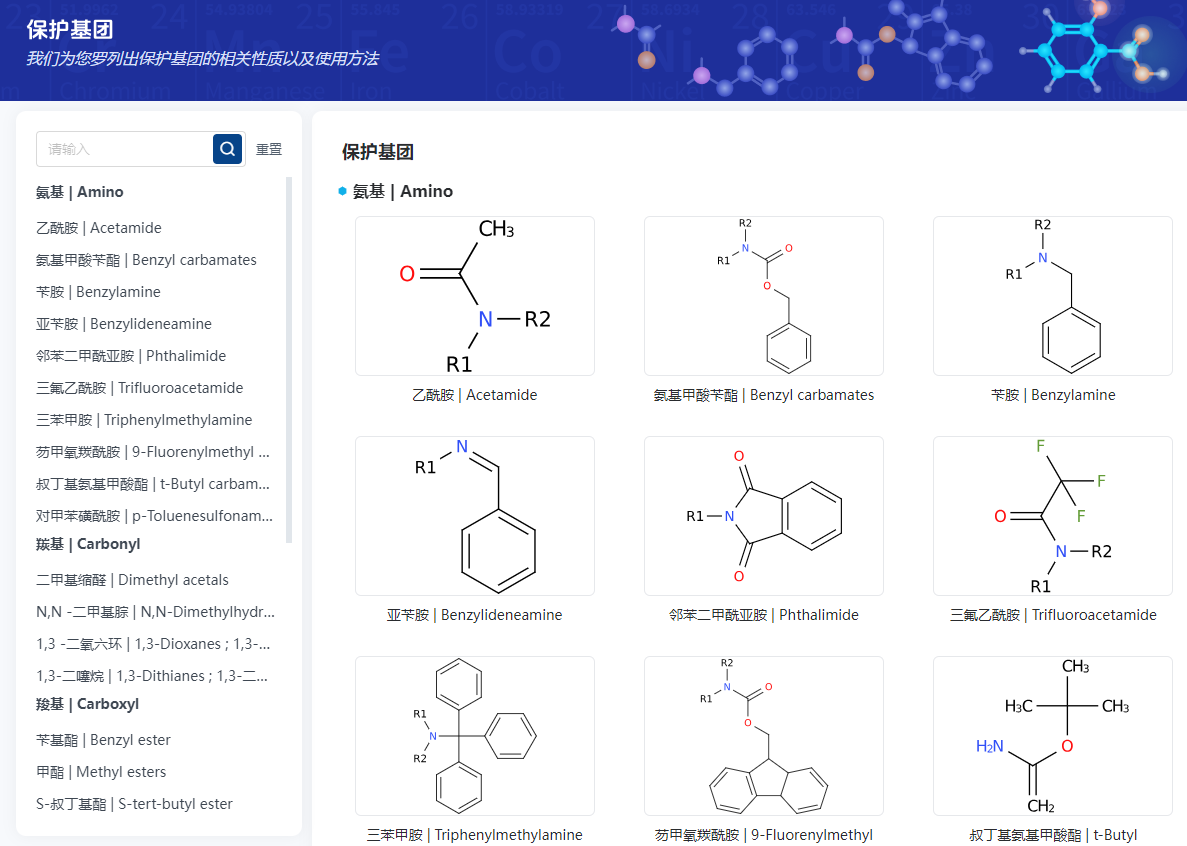
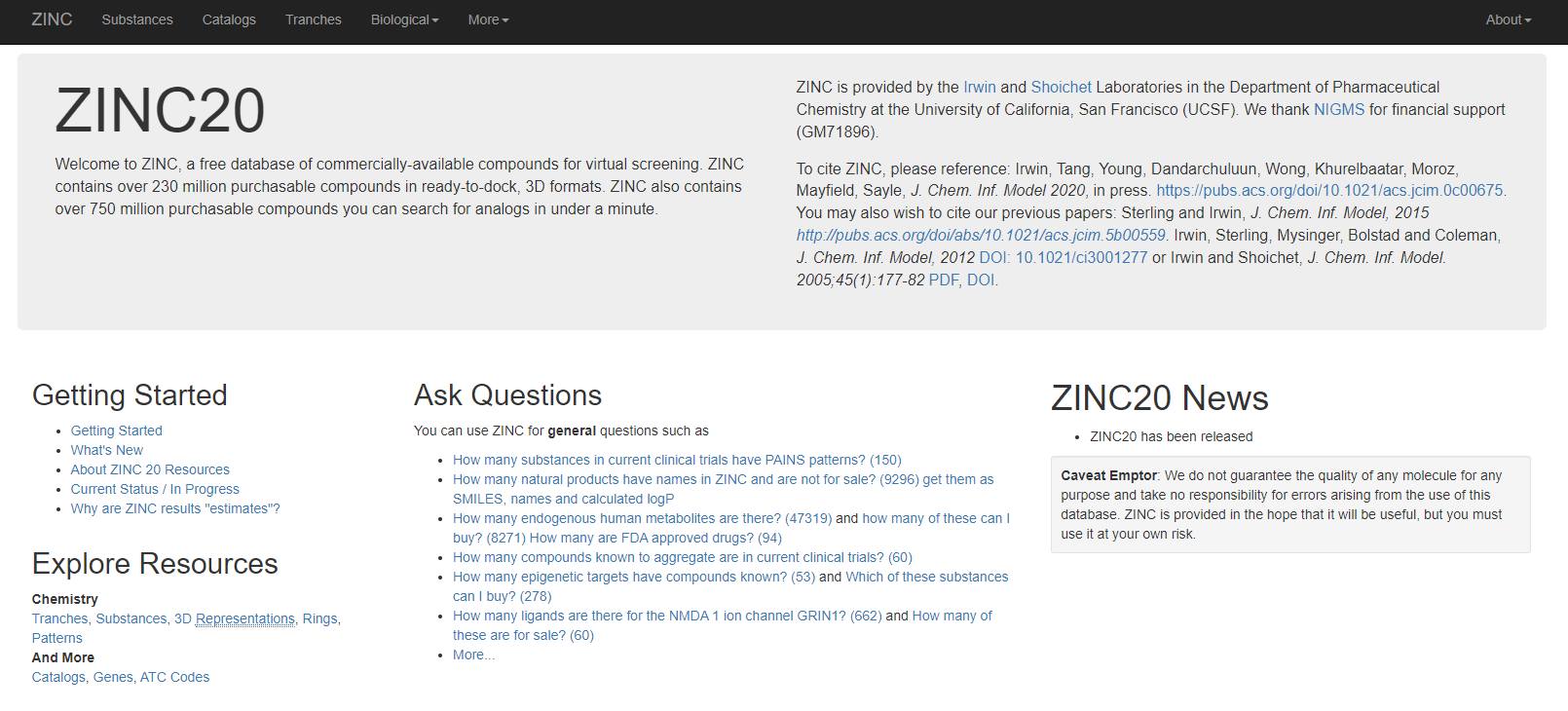
5、ZINC
【网址】:https://zinc.docking.org
ZINC数据库是一个小分子结构数据库,由美国加州大学旧金山分校(UCSF)创建和维护的数据库。最初目的是为了方便访问用于虚拟筛选的化合物数据,这些数据广泛用于虚拟筛选、配体发现、药效团筛选、基准测试、和力场开发。
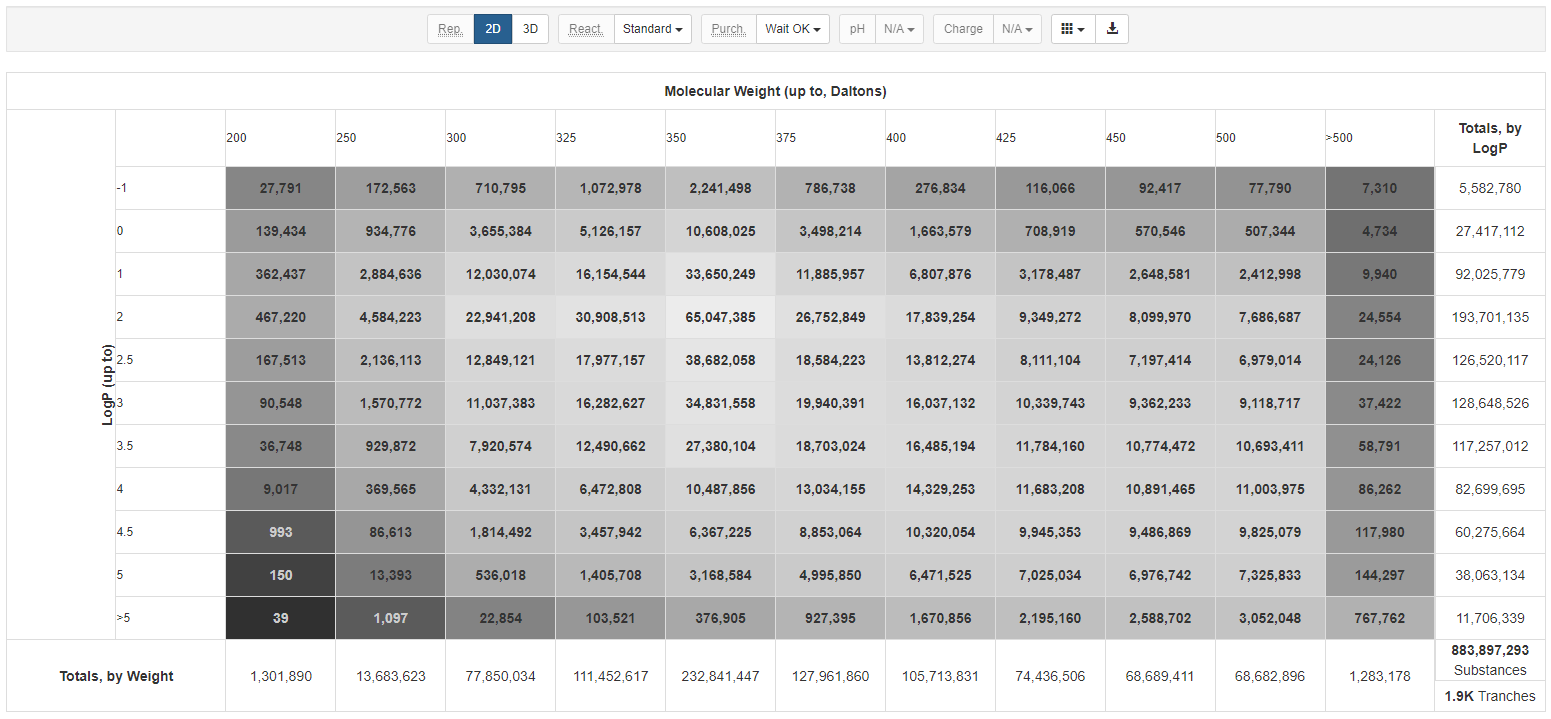
ZINC数据库包含包括片段库、类药性库、药物库、天然产物库等,这些化合物含有供应商、分不量可旋转键数氢键受体及供体等信息。这些化合物的详细信息包括化合物的结构,一些化合物的重要性质,包括xlogP,溶解度,氢键给体和受体数目等,以及二维和三维结构,供应商信息。用户可以免费获取这些化合物数据,支持批量下载,并提供多种数据分类和相关信息,以满足不同用户的兴趣和需求。此外,ZINC数据库支持多种文件格式,如SMILES、mol2、3DSDF和DOCK flexibase,以适应不同的应用场景。用户还可以将化合物的相关信息下载为表格形式,这使得数据的管理和使用更加便捷,特别适合于虚拟筛选和药物设计等研究领域。
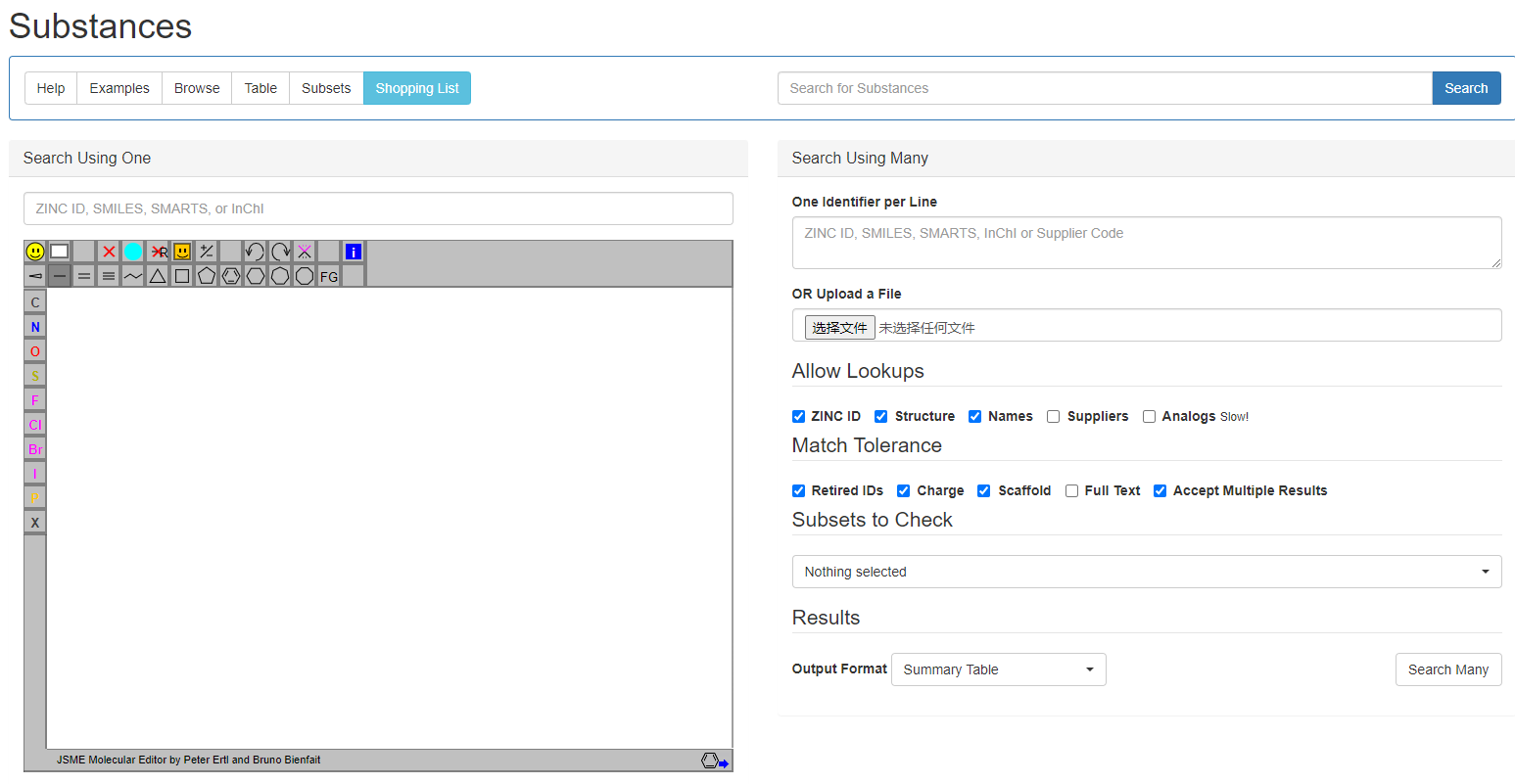
Zinc数据库中的化合物可以通过多种方式进行检索和筛选,包括结构相似性搜索、化学性质过滤、生物活性数据筛选等。进行单个分子搜索时,可以通过化合物名称,SMILES,SMARTS,InCHI,InChIkey,ZINC ID等字符进行搜索,也可以通过化学结构式进行搜索,然后选择进行相似性搜索或子结构搜索。
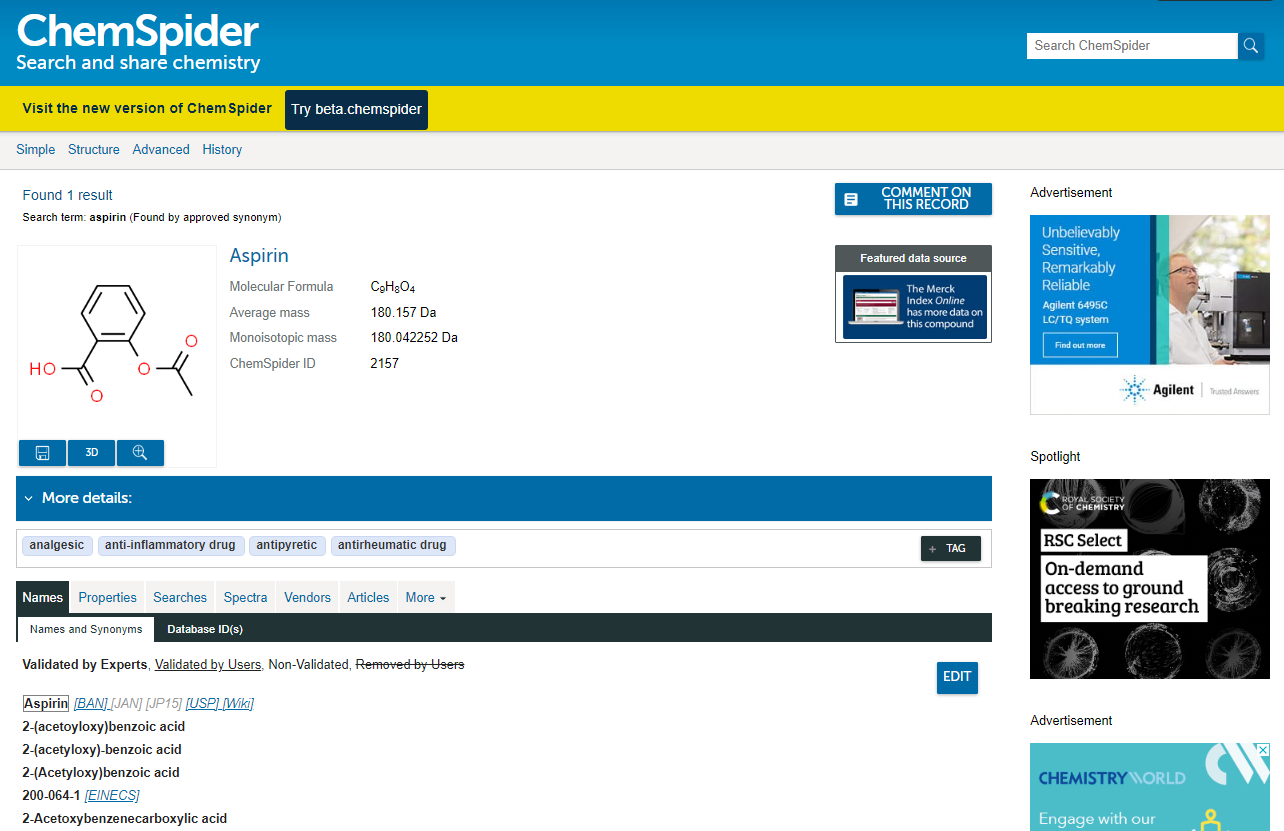
6、ChemSpider
【网址】:http://www.chemspider.com
ChemSpider是一个面向化学界学者和专业人士的在线化合物信息查询平台,提供丰富的化学结构及相关数据。隶属于英国皇家化学会的汇总数据库,于2009年被英国皇家化学学会(Royal Society of Chemistry, RSC) 收购。该网站建立目的是将化学结构及其相关信息进行整合,建立一个以化学结构式为搜索引擎的数据库,该数据库对所有使用者均免费开放。
目前,ChemSpider数据库整合了多种资源,包括海洋天然产物数据、ACD实验室化学数据库、美国环保署(EPA)的DSSTox数据库,以及众多供应商提供的化学物质信息。它提供了多种查询方式:标准查询方式包括系统名称、商业名称和同义词、登记号查询;高级查询方式提供互动式搜索,通过化合物结构、化合物子结构,分子式以及分子量、CAS编号、供应商等进行高级搜索。
7、ChEMBL
【网址】:https://www.ebi.ac.uk/chembl/
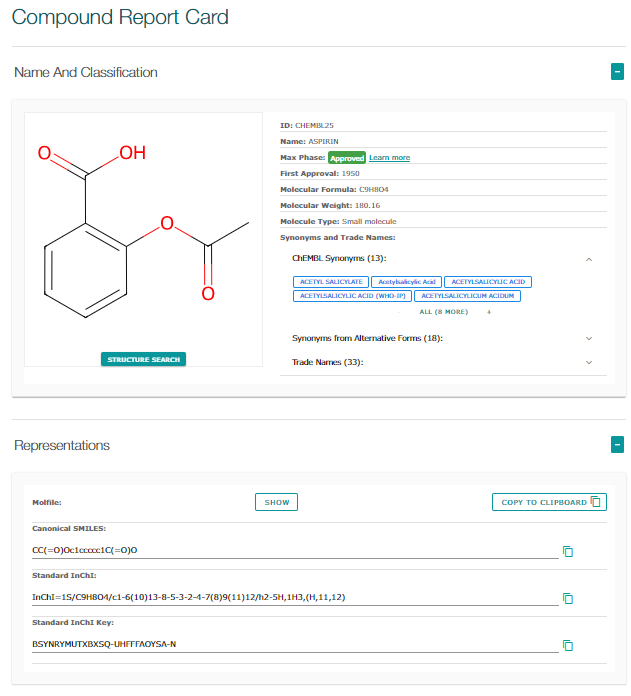
ChEMBL是一个专注于生物活性分子的数据库,主要聚焦于药物发现和药物研究。它汇集了广泛的化合物活性数据,这些数据源自科学文献、专利资料以及药物注册信息。截至目前,ChEMBL已经涵盖了超过15000个生物靶点和240万个化合物,记录了超过2000万条生物活性数据。
该数据库为研究人员提供了全面的药物信息,包括化合物的结构、计算属性、生物活性数据以及与治疗靶点和适应症相关的注释,以及这些化合物与生物分子(如蛋白质、酶、离子通道等)之间的相互作用数据,,还包含分子的2D结构、计算属性(如logP、分子量、Lipinski参数等)和生物活性摘要(如结合常数、药理学和ADMET等数据)。研究人员可以利用ChEMBL数据库探索具有特定生物活性的化合物,分析结构与活性之间的关系,并从中获得有价值的洞见,以推进药物设计和开发过程。
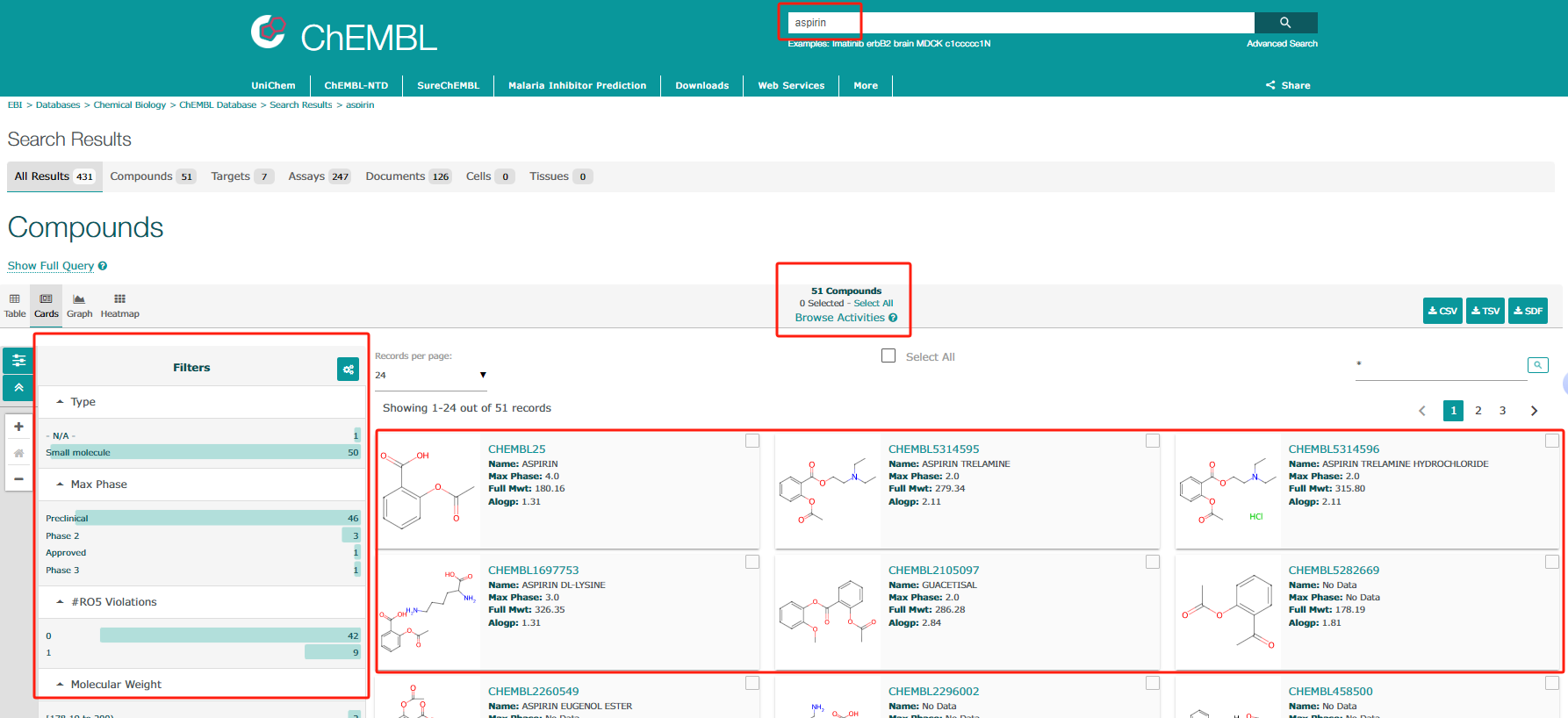
例如输入以“aspirin”为例,在搜索框内输入化合物名称。出现相关的51个化合物,左边有筛选框,罗列了检索到的该化合物各种特性的统计,包括分子类型(Type)、最大临床试验期(Max Phase)、违反五条规则的次数(#RO5 violations)、分子量(Molecular Weight)等内容,并且允许用户通过点击相应的数值浏览给定范围内的原始数据子集。点击某一化合物名字,可查看该化合物的详细内容。
8、DrugBank
【网址】:http://www.drugbank.ca
DrugBank是一个综合性的药物信息数据库,由加拿大阿尔伯塔大学的专业团队开发并维护,它提供了一个免费的在线访问平台,致力于成为研究人员和医疗专业人员的宝贵工具。这个数据库详尽地收录了药物的多方面信息,包括但不限于药物靶点、相互作用、作用机制以及药效学和药动学特性。
DrugBank所包含的药物信息极为广泛,涵盖了药物的CAS登记号、商品名、分子式、分子量、SMILES、2D和3D化学结构、脂溶性(logP)、水溶性(logS)、电离常数(pKa)、熔点、吸收性、Caco-2细胞穿透性等物理化学参数。此外,还包括药物的分类、临床应用、剂型、给药途径、半衰期、体内代谢过程、毒性资料、食物相互作用、与其他药物的相互作用、作用机制、代谢途径、药理学特性、蛋白质结合情况、溶解度、物态、同义词、合成路线的相关文献等。DrugBank的目标是通过提供这些综合信息,促进对药物深层次理解,帮助医疗专业人员和研究人员在药物开发、临床实践和科研工作中做出更明智的决策。

9、PubChem数据库
【网址】:https://pubchem.ncbi.nlm.nih.gov
PubChem数据库即有机小分子生物活性数据,是一种化学模组的数据库,由美国国家健康研究院( US National Institutes of Health,NIH)支持,美国国家生物技术信息中心负责维护。PubChem数据库包括 3个子数据库:PubChem BioAssay 库用于存储生化实验数据,实验数据主要来自高通量筛选实验和科技文献;PubChem Compound 库用于存储整理后的化合物化学结构信息;PubChem Substance 用于存储机构和个人上传的化合物原始数据。
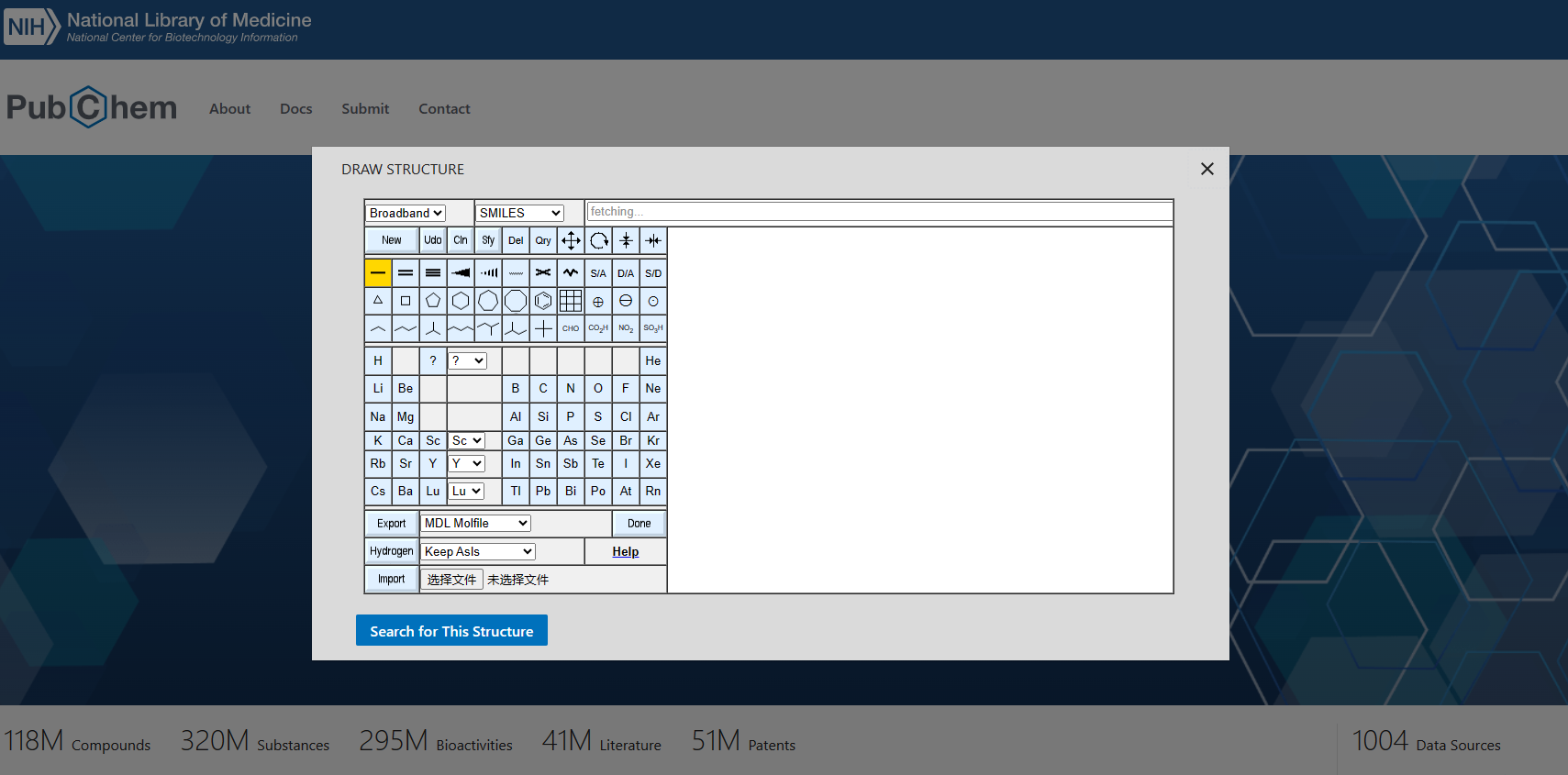
目前收录有化合物11800万种、物质31800万种、生物活性29500万种、相关文献4100万篇、专利5100万篇。可以按名称、分子式、结构和CAS标识符等搜索,结构搜索支持mol等格式文件的导入和导出。PubChem数据库中的化学结构检索提供了方便的化学结构编辑器,用户可手动绘制化学结构或提供结构smiles文件格式检索。PubChem 检索可得到的结果包含了分子式、SMILES、2D和3D结构、InChI和InChIKey、相对分子质量、脂水分配系数、氢键受体和供体数目、可旋转键数目、互变异构体数目等基本的结构信息和物化性质,除此以外,还有该化合物作为药物的剂型和商品信息、药理性质、毒性、生物活性检测等信息,并通过文献分类副标题可以查看相关文献。
10、ChemExper
【网址】:http://www.chemexper.com
Chemexper是一个把化学,计算机科学和电信等领域联系起来的一个公司。 Chemexper在网站上提供了化学物质搜索引擎Finding chemicals。可以通过CAS登记号、目录号和分子式、分子名称等形式进行检索。还提供了一个插件程序,通过这个技术,化学供应商可以在自己的网站上提供超文本链接标识语言,所有的疑问都可以通过Chemexper上的服务器进行解答。 Chemexper在网站上提供了ChemExper Chemical Directory(CCD)数据库,该数据库免费使用,所有人都可以通过Expereact Web提交信息,并在网站浏览器上重新得到信息。CCD包含了11,390,929化学物质结构,16,000材料安全数据表,100,000带有各种信息的产品。ChemExper支持化合物名称、结构式、CAS号、SMILES等检索,检索结果除了提供结构预览,还可下载mol格式的结构源文件,可导入到ChemDraw、ISIS Draw、Sybyl等软件中。此外,还可查看供应商信息。
总的来说,这些平台的共同点在于它们都提供了丰富的结构数据和强大的分析工具,帮助科学家们在分子层面上理解物质的性质和功能。随着计算能力的提升和数据存储技术的不断进步,这些数据库的容量和功能都在持续扩大和优化,极大地增强了科研工作的效率和深度。用户可以根据自己的研究需求,选择最适合的数据库进行信息检索和分析。
以上内容仅为个人观点,如有不足之处,望各位不吝赐教,提出宝贵意见。
创作之路充满挑战,您的点赞和收藏是对我最大的鼓励和支持。